
The Problem: VLAs That Don't Understand Physics
Most current Vision-Language-Action (VLA) models learn through imitation learning — you record robot demonstrations, the model learns to repeat them. Clean, effective in the lab. But in real deployment, they collapse at a fundamental level: the robot doesn't understand the dynamics of the world.
Change the camera angle? The robot panics. Different lighting? Failure. Object shifted a few centimeters? Miss. The reason is that traditional VLAs overfit to pixels — they learn "when the image looks like this, execute this motion," rather than "this object is here, I need to pull it in this direction to achieve my goal."
VLA-JEPA (arxiv 2602.10098) addresses this with a clean idea: teach the robot to predict future states in latent space — not pixels, but abstracted features. The tool enabling this is V-JEPA2, Meta's video world model.
V-JEPA2: Meta's Largest Video World Model
V-JEPA 2 (Video Joint Embedding Predictive Architecture, version 2) is a self-supervised video world model released by Meta AI in 2026. Three key highlights:
- Massive pretraining scale: Trained on over 1 million hours of internet video, no labels needed
- Latent space prediction: No pixel rendering — predicts feature representations of future frames
- 1.2 billion parameter encoder — large enough to learn complex dynamics
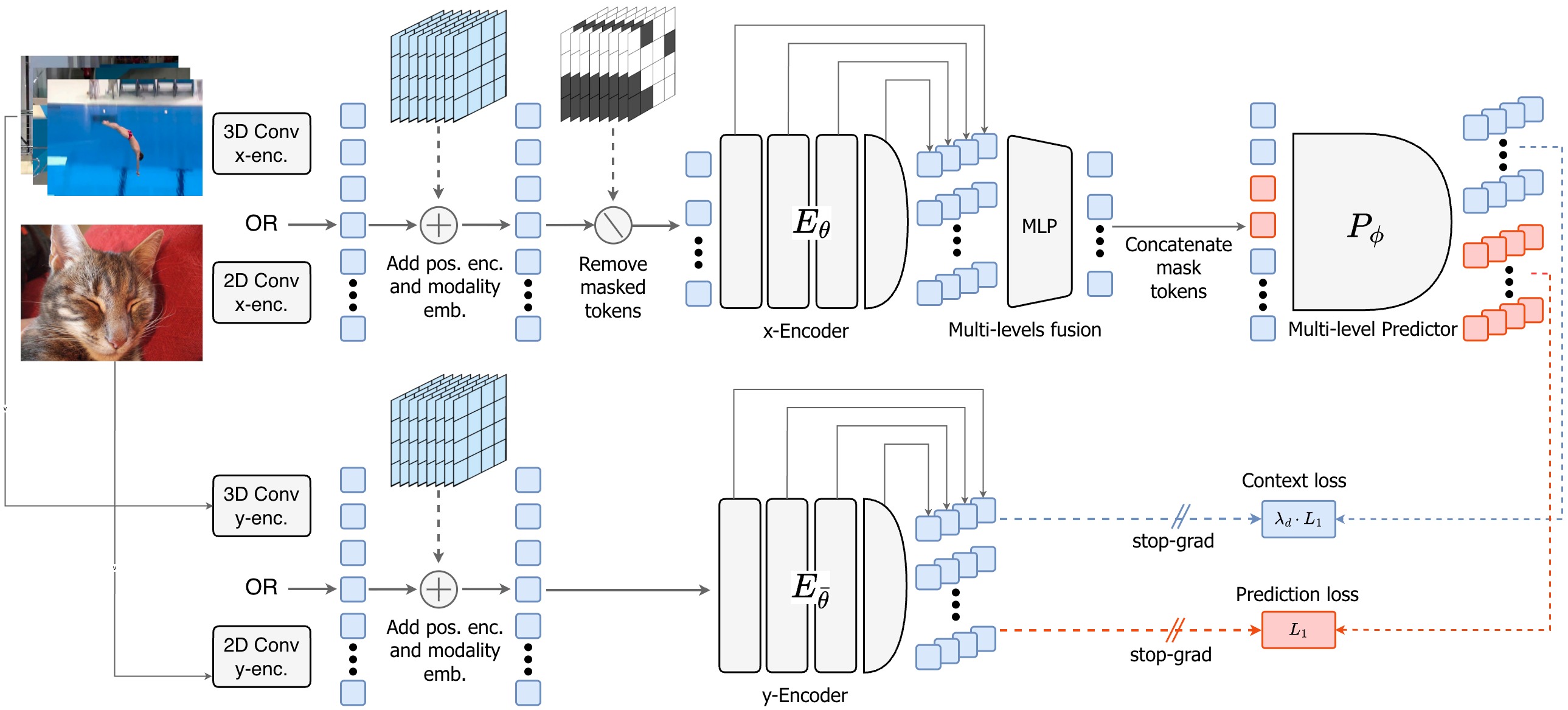
The key difference from video generation models (like Sora, Wan2.1): V-JEPA2 does not generate video. It only learns how the feature space changes over time. This avoids the "pixel curse" — it's not confused by changes in lighting, texture, or background that are irrelevant to physical dynamics.
V-JEPA 2-AC: The Robot Variant
V-JEPA 2-AC is the action-conditioned variant, further post-trained for robotics:
- Fine-tuned with only 62 hours of unlabeled robot video (from the Droid dataset)
- Deployed zero-shot on Franka arms in two different labs without any robot-specific data
- Performs pick-and-place and drawer opening through planning with image goals in an MPC loop
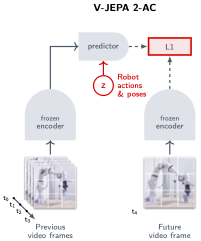
This demonstrates that a world model pretrained on internet video — not robot data — can still generalize to robot manipulation.
VLA-JEPA: Integrating V-JEPA2 into VLA Training
VLA-JEPA incorporates V-JEPA2 as an auxiliary supervision signal during training — not as an inference component. The core insight: use V-JEPA2 as a "teacher" that helps the VLA understand dynamics, then the teacher leaves at inference time.
Detailed Architecture
VLA-JEPA (3B total parameters) has three main components working together in a specific way:
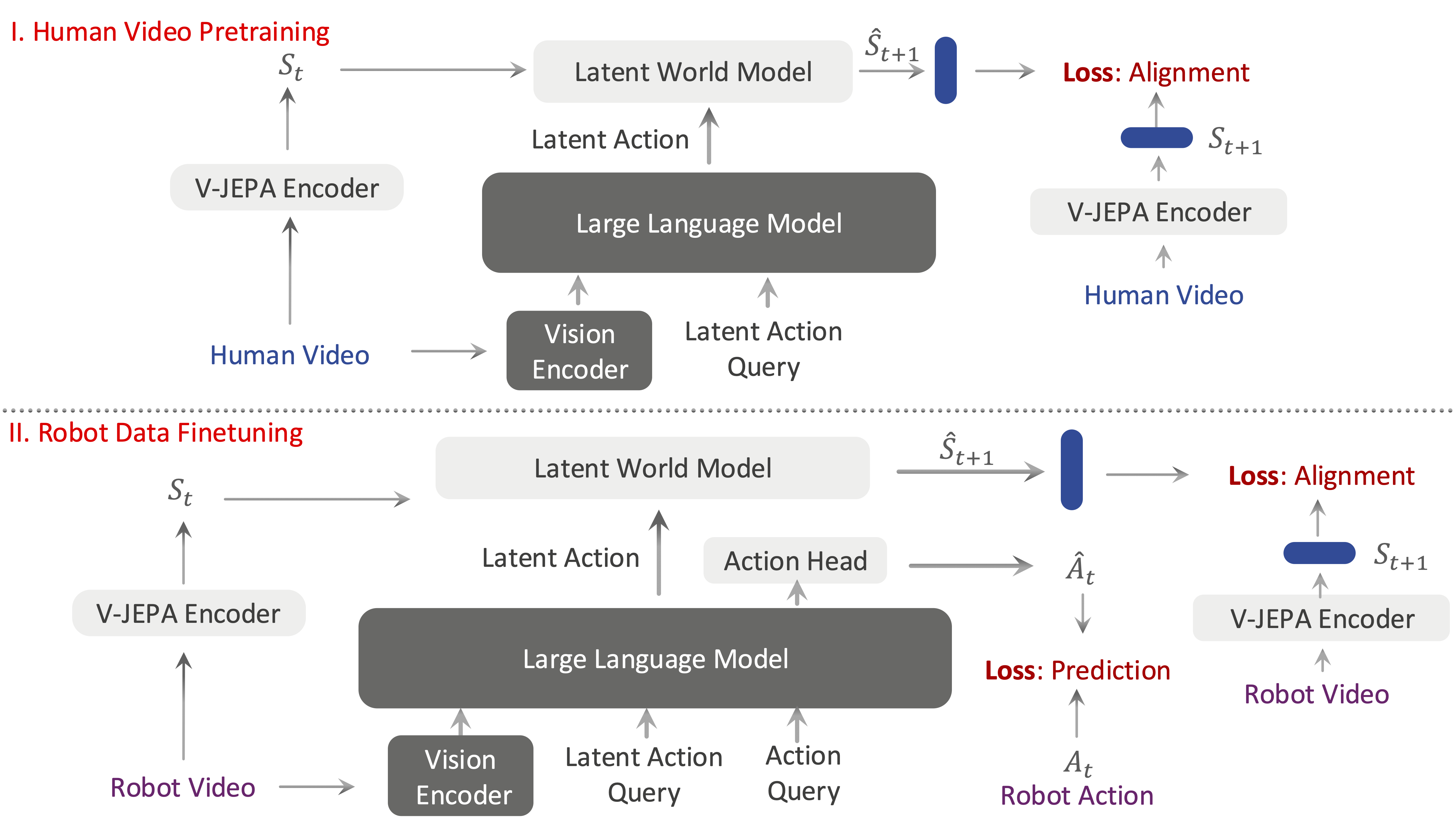
1. Student pathway (standard VLA):
- Backbone: Qwen3-VL-2B-Instruct — processes multi-view images + task instruction
- Output: context tokens (including special action tokens and embodied tokens)
- Only sees the current frame, no information about the future
2. Target encoder (V-JEPA2):
- Receives the full video clip (multiple frames including future frames)
- Produces latent targets of future frames
- Gradient stop: the target encoder is not trained end-to-end, only updated via EMA (exponential moving average) — this is the "leakage-free" mechanism
3. Action head (Flow-matching DiT):
- Receives context tokens from Qwen as cross-attention keys/values
- Predicts an action chunk using flow matching (similar to diffusion but faster)
- At inference: only Qwen + action head are needed — V-JEPA2 is entirely discarded
Leakage-Free State Prediction — The Heart of VLA-JEPA
This is the most critical mechanism. Normally, if you give a model access to both current and future frames during training, it "cheats" — learning to copy information from future frames instead of actually learning dynamics.
VLA-JEPA prevents this by completely separating:
- Student pathway: Only sees the current frame → must predict the future
- Target encoder: Sees future frames, creates targets → but never feeds into the student as input
The JEPA alignment loss is computed between the student's prediction and the target representations:
# Pseudo-code for JEPA loss principle
pred_latent = student_predictor(context_tokens, action_tokens) # predict future latent
target_latent = target_encoder(future_frames) # actual future latent
jepa_loss = F.smooth_l1_loss(pred_latent, target_latent.detach())
By learning to minimize this distance, the VLA backbone is forced to encode physical dynamics information into its context tokens — something traditional VLAs completely lack.
Three Training Phases
VLA-JEPA trains through a 3-step pipeline, leveraging data from broad to specific:
Phase 1: Pretrain on Human Videos
# No robot data needed — just human activity videos
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--dataset.repo_id=<human-video-dataset> \
--policy.use_vjepa2=true \
--steps=100000
This phase is critical because human videos are vastly cheaper and more abundant than robot data. V-JEPA2 was already pretrained on 1M+ hours of internet video, so its embeddings already understand dynamics of human hands grasping objects, things being pushed, gravity effects, etc.
Phase 2: Train on Robot Videos
# Train with both VLA loss + JEPA alignment loss
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--policy.repo_id=your_org/vla-jepa-robot \
--dataset.repo_id=HuggingFaceVLA/libero \
--steps=30000 \
--policy.use_vjepa2=true \
--policy.jepa_loss_weight=0.1
Phase 3: Fine-tune on Specific Tasks
# Fine-tune, V-JEPA2 still active as regularizer
lerobot-train \
--policy.path=your_org/vla-jepa-robot \
--dataset.repo_id=your_org/your-robot-demos \
--steps=10000 \
--policy.use_vjepa2=true
The secret of VLA-JEPA: even during fine-tuning with sparse data, V-JEPA2 acts as a regularizer preventing the model from overfitting to pixel patterns of those specific demonstrations.
Installation
Requirements
- Python 3.10+
- CUDA 12.1+
- GPU: At minimum RTX 3080 (10GB VRAM) for inference; training requires 40GB+ (A100/H100)
- RAM: 32GB+
Install from GitHub (original repo)
# Clone repo
git clone https://github.com/ginwind/VLA-JEPA
cd VLA-JEPA
# Create conda environment
conda create -n vla_jepa python=3.10
conda activate vla_jepa
# Install dependencies
pip install -r requirements.txt
# Install FlashAttention2 (IMPORTANT — required for Qwen3-VL)
pip install flash-attn==2.7.4 --no-build-isolation
# Install project
pip install -e .
Download Weights
# Download Qwen3-VL-2B-Instruct (backbone)
huggingface-cli download Qwen/Qwen3-VL-2B-Instruct \
--local-dir ./checkpoints/Qwen3-VL-2B-Instruct
# Download V-JEPA2 encoder
huggingface-cli download ginwind/VLA-JEPA \
vjepa2_encoder.pth --local-dir ./checkpoints/
# Download VLA-JEPA pretrained weights
huggingface-cli download ginwind/VLA-JEPA \
vla_jepa_pretrain.pth --local-dir ./checkpoints/
Install via LeRobot (simpler approach)
# Install LeRobot with all extras
pip install 'lerobot[all]'
# Or minimal for VLA training
pip install 'lerobot[vla]'
Dataset Preparation
VLA-JEPA uses modality.json to describe the data format. This file tells the model which camera channels and joints to use.
{
"observation.images.front": {
"type": "visual",
"shape": [3, 224, 224],
"normalize": true
},
"observation.images.wrist": {
"type": "visual",
"shape": [3, 224, 224],
"normalize": true
},
"observation.state": {
"type": "proprio",
"shape": [14],
"normalize": true
},
"action": {
"type": "action",
"shape": [14]
}
}
With the LIBERO dataset on HuggingFace:
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
dataset = LeRobotDataset(
repo_id="HuggingFaceVLA/libero",
split="train",
video_backend="pyav",
)
# Check format
print(dataset[0].keys())
print(f"Dataset size: {len(dataset)}")
Training on LIBERO
Fine-tune on LIBERO-Spatial
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--policy.repo_id=your_org/vla-jepa-libero-spatial \
--dataset.repo_id=HuggingFaceVLA/libero \
--dataset.split=libero_spatial \
--steps=30000 \
--batch_size=8 \
--learning_rate=1e-4 \
--policy.use_vjepa2=true \
--policy.num_video_frames=8 \
--policy.chunk_size=16 \
--wandb.project=vla-jepa-experiments
Estimated time: ~8 hours on 1x A100 80GB.
Fine-tune with Sparse Data (13 Demos)
# This is VLA-JEPA's most impressive result
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--policy.repo_id=your_org/vla-jepa-real-13demos \
--dataset.repo_id=your_org/13-robot-demos \
--steps=5000 \
--batch_size=4 \
--learning_rate=5e-5 \
--policy.use_vjepa2=true \
--policy.jepa_loss_weight=0.2 # higher JEPA weight with sparse data
Note: Higher JEPA loss weight helps the model "anchor" to world model knowledge from pretraining when fine-tune data is scarce — preventing catastrophic forgetting.
Inference
At inference, the V-JEPA2 encoder is completely dropped. Only Qwen3-VL + action head run:
from lerobot.policies.vla_jepa import VLAJEPAPolicy
import torch
# Load model (VLA only, no V-JEPA2)
policy = VLAJEPAPolicy.from_pretrained("your_org/vla-jepa-real-13demos")
policy.eval()
# Prepare observation
obs = {
"observation.images.front": torch.from_numpy(front_cam_frame).float(),
"observation.images.wrist": torch.from_numpy(wrist_cam_frame).float(),
"observation.state": torch.from_numpy(joint_positions).float(),
}
# Inference
with torch.no_grad():
action_chunk = policy.select_action(obs, task="pick up the red cube")
# action_chunk: tensor shape [16, 14] — 16 timesteps, 14 DOF
Real-world performance:
- Speed: 10Hz on RTX 3080 (consumer GPU!)
- VRAM: only <6GB — runnable on gaming laptops
- Comparison: OpenVLA-OFT needs 24GB+ VRAM for equivalent inference
This is a major advantage: because V-JEPA2 is only used during training, the inference model is significantly more compact.
Benchmark Results
VLA-JEPA was evaluated on four main benchmarks:
| Benchmark | VLA-JEPA | OpenVLA | π0 (Pi-Zero) |
|---|---|---|---|
| LIBERO-Spatial | 94.2% | 84.7% | 89.1% |
| LIBERO-Object | 92.8% | 83.2% | 87.6% |
| LIBERO-Goal | 91.5% | 81.9% | 86.3% |
| LIBERO-Plus (perturbation) | 78.4% | 51.2% | 63.8% |
| SimplerEnv | 67.3% | 55.1% | 61.2% |
The LIBERO-Plus column is the most telling: this dataset adds visual perturbations (lighting changes, texture variations, different backgrounds). VLA-JEPA clearly dominates here, confirming that JEPA training produces more robust models under domain shift.
Why Latent Prediction Beats Pixel Prediction
Imagine learning to play table tennis. Pixel learning approach: you try to memorize every pixel in every video — the color of the table, the pattern on your opponent's shirt, the shadows on the floor. Play in a different room with different lighting? Failure.
Latent learning approach (JEPA): you learn the physical trajectory of the ball — where it is, how fast it's moving, its spin. New room? Different lighting? Doesn't matter, because you understand physics, not pixels.
V-JEPA2 has already learned the "physics" of the world from 1 million hours of video. VLA-JEPA inherits that knowledge and teaches the robot to use it when planning actions.
Comparison with Other World Model VLAs
| Method | World model | Used at inference? | Inference VRAM | Speed |
|---|---|---|---|---|
| VLA-JEPA | V-JEPA2 (latent) | No | <6GB | 10Hz |
| Weaver | Video diffusion | No | ~12GB | 3-5Hz |
| GigaBrain-0 | MPC + world model | Yes | ~20GB | 1-2Hz |
| DREAM-Chunk | Latent chunk predict | Yes | ~15GB | 2-4Hz |
VLA-JEPA has a clear trade-off: no world model at inference → faster, lighter. But no multi-step planning or lookahead capability like GigaBrain-0.
Common Pitfalls
1. Forgetting to install FlashAttention2: Qwen3-VL runs extremely slowly without FA2, especially with multi-view images. Common mistake: installing FA2 with the wrong CUDA version.
# Check CUDA version first
nvcc --version
# Must match PyTorch's CUDA version
python -c "import torch; print(torch.version.cuda)"
2. modality.json not matching the dataset: If camera channels in modality.json differ from names in LeRobotDataset, training will crash or train on wrong features.
3. JEPA loss weight too high: If jepa_loss_weight > 0.5, action quality drops because the model focuses on predicting latents rather than actions. Recommended: 0.05–0.2.
4. Loading V-JEPA2 at inference: Some people mistakenly think they need to load the V-JEPA2 encoder for deployment. Not needed — inference only requires Qwen + action head.
Community Tips
- Fine-tuning with 13 demos genuinely works if you use ginwind's pretrained checkpoint — they verified this with Franka G-1. Don't worry about having a small dataset.
- Camera placement matters more than number of demos: Wrist camera + front camera is the minimum. Adding an overhead camera significantly helps for tasks requiring spatial reasoning.
- Use
num_video_frames=8as sweet spot: 4 frames lacks temporal context, 16 frames doubles training VRAM with minimal gain. - For Jetson Orin deployment: Export Qwen + action head separately, use TensorRT. V-JEPA2 doesn't need to be exported since it doesn't run on edge devices.
Conclusion
VLA-JEPA is a beautiful example of "train-time compute, inference-time efficiency" — using a large world model (V-JEPA2) as a teacher during training, without needing to carry it at deployment. The result is a VLA that runs on consumer GPUs with significantly better generalization than the baselines.
With just 13 demos and an RTX 3080, you can have a working manipulation policy in real-world environments — a major step forward in data efficiency.
Source code: ginwind/VLA-JEPA | Paper: arxiv 2602.10098 | LeRobot docs: lerobot/vla_jepa


