Bạn đã quen với Imitation Learning — thu thập demo từ con người, rồi dạy robot bắt chước? Cách tiếp cận này hoạt động tốt, nhưng có một giới hạn cố hữu: robot chỉ giỏi bằng dữ liệu demo mà nó được xem. Nếu demo thiếu một tình huống nào đó, robot sẽ "đứng hình" khi gặp phải.
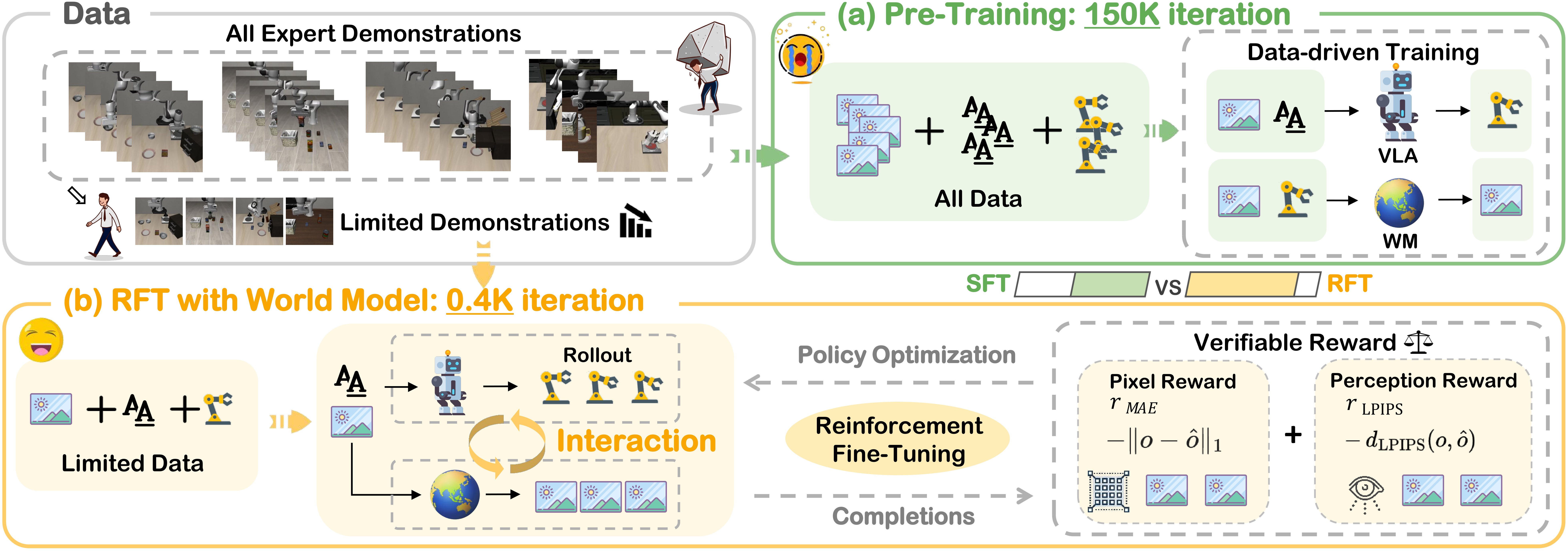
GigaBrain-0 — bộ mô hình VLA open-source từ GigaAI — giải quyết vấn đề này bằng một ý tưởng đột phá: dạy robot "tưởng tượng" tương lai trước khi hành động, rồi dùng Reinforcement Learning để tối ưu dựa trên những "giấc mơ" đó. Trong bài viết này, mình sẽ hướng dẫn bạn từ ý tưởng đến cài đặt, training và inference với code open-source.

Tổng quan: GigaBrain-0 là gì?
GigaBrain-0 thực chất là một gia đình mô hình gồm nhiều phiên bản:
| Phiên bản | Mô tả | Thời điểm |
|---|---|---|
| GigaBrain-0 | Foundation VLA model, Mixture-of-Transformers | 10/2025 |
| GigaBrain-0.1 | Phiên bản nâng cấp, dữ liệu lớn hơn, #1 RoboChallenge | 02/2026 |
| GigaBrain-0.5 | VLA backbone 3.5B params với Embodied CoT | 02/2026 |
| GigaBrain-0.5M* | Bản hoàn chỉnh: VLA + World Model + RL (RAMP) | 02/2026 |
Bài viết này tập trung vào GigaBrain-0.5M* — phiên bản đầy đủ nhất, kết hợp cả ba thành phần: VLA backbone, World Model (GigaWorld), và framework RAMP cho Reinforcement Learning.
Paper: GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning — GigaBrain Team, 02/2026
GitHub: open-gigaai/giga-brain-0 (Apache 2.0)
Ý tưởng cốt lõi: RAMP Framework
Vấn đề với Imitation Learning thuần túy
Hầu hết các VLA model hiện tại (RT-2, Octo, π₀) đều dựa trên Imitation Learning — robot học bắt chước hành động từ dữ liệu demo. Điều này tạo ra hai hạn chế:
- Ceiling hiệu năng bị giới hạn bởi chất lượng demo — robot không thể giỏi hơn người demo
- Thiếu khả năng generalize — gặp tình huống ngoài phân phối dữ liệu là "chết"
Giải pháp: Dạy robot "mơ" rồi học từ giấc mơ
RAMP (Reinforcement leArning via world Model-conditioned Policy) giải quyết bằng cách thêm hai thành phần:
- World Model (GigaWorld): Một mô hình video generative dự đoán "chuyện gì sẽ xảy ra tiếp theo" — giống như robot đang "tưởng tượng" tương lai dựa trên hành động hiện tại
- RL fine-tuning: Dùng advantage function từ World Model để tối ưu policy, thay vì chỉ bắt chước
Công thức toán học cốt lõi:
π*(a|S) ∝ π_ref(a|S) · exp(A(S,a)/β)
Trong đó state được mở rộng: S = (o, z, l) với:
- o = observation hiện tại (ảnh RGB-D từ camera)
- z = latent predictions từ World Model (tương lai được "tưởng tượng")
- l = language instruction (lệnh ngôn ngữ)
RAMP vs RECAP: Tại sao RAMP tốt hơn?
RECAP (từ Physical Intelligence, dùng trong π₀.5) cũng dùng RL, nhưng chỉ dùng tín hiệu binary (thành công/thất bại). Paper chứng minh rằng RECAP thực chất là trường hợp đặc biệt của RAMP khi marginalize bỏ thông tin World Model:
H(a|o,z,l) ≤ H(a|o,l)
Nói đơn giản: khi robot được "nhìn thấy tương lai" (qua z), nó bớt bất định hơn so với khi chỉ nhìn hiện tại. Kết quả là RAMP cải thiện ~30% absolute so với RECAP trên các task khó.
Kiến trúc chi tiết
GigaBrain-0.5M* gồm 3 module chính:
1. VLA Backbone (GigaBrain-0.5) — 3.5B params
- Vision-Language Encoder: PaliGemma-2 (Google) — xử lý ảnh RGB-D + text instruction
- Action Head: Diffusion Transformer (DiT) với flow matching — sinh ra action chunks (50 bước liên tiếp)
- Embodied Chain-of-Thought: Sinh subgoal language + discrete action tokens + 2D manipulation trajectories qua GRU decoder
Điểm đặc biệt: Knowledge Insulation ngăn việc tối ưu action prediction ảnh hưởng đến CoT generation — hai nhánh "cách ly" nhau về gradient.
2. World Model (GigaWorld)
- Kiến trúc: Wan 2.2 (spatiotemporal DiT với self-attention)
- Training: Flow matching với optimal transport path interpolation
- Dual outputs: Dự đoán đồng thời future visual states VÀ value estimates
- Prediction horizons: 12, 24, 36, 48 frames phía trước
GigaWorld hoạt động như "bộ não mơ" — nhận observation hiện tại và action, rồi "tưởng tượng" chuỗi frame tiếp theo sẽ trông như thế nào. Thông tin này được encode thành latent vector z và truyền vào VLA backbone.
3. RAMP — Keo kết dính tất cả
RAMP kết nối World Model vào policy training loop:
- World Model sinh z (latent predictions) cho mỗi observation
- Policy nhận (o, z, l) thay vì chỉ (o, l)
- Advantage function A(S,a) tính từ value predictions của World Model
- KL-regularized RL update giữ policy gần với pretrained reference
Stochastic attention masking (p=0.2): Trong quá trình training, 20% thời gian World Model bị "tắt" (mask). Điều này ngăn policy phụ thuộc quá nhiều vào World Model — tại inference, nếu World Model chậm, policy vẫn hoạt động được.
Cài đặt môi trường
Yêu cầu phần cứng
- GPU: NVIDIA A100/A800 (80GB VRAM) cho training. RTX 4090 (24GB) cho inference
- RAM: 64GB+ cho training, 32GB cho inference
- Storage: ~200GB cho datasets + checkpoints
- CUDA: 12.1+
Bước 1: Tạo environment
# Tạo conda environment
conda create -n giga_brain_0 python=3.11.10 -y
conda activate giga_brain_0
# Cài dependencies chính
pip3 install giga-train giga-datasets lerobot==0.3.2 matplotlib numpydantic
Bước 2: Clone và cài giga-models
# Clone giga-models (model definitions)
git clone https://github.com/open-gigaai/giga-models.git
cd giga-models && pip3 install -e .
cd ..
# Clone giga-brain-0 (training + inference code)
git clone https://github.com/open-gigaai/giga-brain-0.git
cd giga-brain-0
Bước 3: Tải pretrained weights
Weights được host trên HuggingFace (org: open-gigaai):
# Tải VLA backbone (3.5B params, ~7GB)
huggingface-cli download open-gigaai/GigaBrain-0.1-3.5B-Base --local-dir checkpoints/gigabrain-0.1
# Tải World Model
huggingface-cli download open-gigaai/GigaWorld-0-Video-GR1-2b --local-dir checkpoints/gigaworld
# Phiên bản không cần depth camera (dễ deploy hơn)
huggingface-cli download open-gigaai/GigaBrain-0-3.5B-Base --local-dir checkpoints/gigabrain-0-nodepth
Chuẩn bị dữ liệu
GigaBrain-0 sử dụng format LeRobot. Nếu bạn có dữ liệu HDF5, chuyển đổi như sau:
Chuyển HDF5 sang LeRobot format
python scripts/convert_from_hdf5.py \
--data-path /path/to/raw_hdf5_data_path \
--out-dir /path/to/lerobot_dataset \
--task "Pick up the red block and place it in the bin"
Tính normalization statistics
python scripts/compute_norm_stats.py \
--data-paths /path/to/dataset1 /path/to/dataset2 \
--output-path /path/to/norm_stats.json \
--embodiment-id 0 \
--delta-mask True,True,True,True,True,True,False,True,True,True,True,True,True,False \
--sample-rate 1.0 \
--action-chunk 50 \
--action-dim 32
Giải thích delta-mask: Mỗi giá trị True/False tương ứng với một chiều action. True = dùng delta (thay đổi so với bước trước), False = dùng absolute (giá trị tuyệt đối). Thường gripper dùng absolute (True/False mở/đóng), joints dùng delta.
Training Pipeline — 4 giai đoạn

Stage 1: World Model Pre-training
GigaWorld được train trên 10,931 giờ visual experience:
- 61% (6,653 giờ) — dữ liệu synthesized bởi chính World Model (self-play)
- 39% (4,278 giờ) — dữ liệu robot thật từ nhiều platform (UR5, Franka, ARX5, ALOHA, Agibot G1)
Reward function dùng sparse signal:
- 0 khi task thành công
- -C_fail khi thất bại
- -1 mỗi timestep (khuyến khích hoàn thành nhanh)
Stage 2: Policy Fine-tuning với World Model
Đây là bước quan trọng nhất — fine-tune VLA backbone với thông tin từ World Model:
# Fine-tune cho AgileX Cobot Magic
python scripts/train.py --config configs.giga_brain_0_agilex_finetune.config
# Fine-tune cho Agibot G1 humanoid
python scripts/train.py --config configs.giga_brain_0_agibot_finetune.config
# Train từ scratch (nếu muốn)
python scripts/train.py --config configs.giga_brain_0_from_scratch.config
Hyperparameters quan trọng:
- Batch size: 256
- Training steps: 20,000
- Stochastic masking: p=0.2
- Single denoising step (cho efficiency)
- n-step temporal difference cho advantage computation
Stage 3: Human-in-the-Loop Rollout (HILR)
Sau khi policy đã khá tốt, thu thêm dữ liệu bằng cách:
- Robot chạy policy autonomously
- Người điều khiển can thiệp khi robot sắp thất bại
- Tự động phát hiện và loại bỏ temporal discontinuities tại điểm can thiệp
Dữ liệu HILR có phân phối gần với policy thực tế hơn so với teleoperation thuần, giảm distribution shift.
Stage 4: Continual Joint Training
World Model VÀ Policy được train đồng thời trên dữ liệu HILR mới. Tạo vòng lặp tự cải thiện:
Policy tốt hơn → Dữ liệu HILR tốt hơn → World Model chính xác hơn → Policy tốt hơn → ...
Inference và Deploy
Chạy inference offline (test trên dataset)
python scripts/inference.py \
--model-path checkpoints/gigabrain-0.1 \
--data-path /path/to/lerobot_dataset \
--norm-stats-path /path/to/norm_stats.json \
--output-path /tmp/vis_path \
--delta-mask True,True,True,True,True,True,False,True,True,True,True,True,True,False \
--embodiment-id 0 \
--action-chunk 50 \
--original-action-dim 14 \
--tokenizer-model-path google/paligemma2-3b-pt-224 \
--fast-tokenizer-path physical-intelligence/fast \
--device cuda
Deploy Server-Client (cho robot thật)
Trên GPU machine (server):
python scripts/inference_server.py \
--model-path checkpoints/gigabrain-0.1 \
--tokenizer-model-path google/paligemma2-3b-pt-224 \
--fast-tokenizer-path physical-intelligence/fast \
--delta-mask True,True,True,True,True,True,False,True,True,True,True,True,True,False \
--embodiment-id 0 \
--norm-stats-path /path/to/norm_stats.json \
--original-action-dim 14
Trên robot machine (client):
# Client gửi sensor data, nhận action predictions
python scripts/inference_client.py
# Hoặc client chuyên dụng cho AgileX robot
python scripts/inference_agilex_client.py
Hai chế độ inference:
- Efficient Mode: Bypass World Model (nhanh nhất, dùng attention masking), phù hợp task đơn giản
- Standard Mode: World Model active, dùng cho task phức tạp cần planning xa
Edge deployment
GigaBrain-0-Small — phiên bản nhỏ hơn, tối ưu cho NVIDIA Jetson AGX Orin, phù hợp khi cần chạy trực tiếp trên robot mà không có GPU server riêng.
Kết quả benchmark
RoboChallenge Leaderboard (02/2026)
| Model | Average Success Rate | Hạng |
|---|---|---|
| GigaBrain-0.1 | 51.67% | #1 |
| π₀.5 (Physical Intelligence) | 42.67% | #2 |
Đánh giá trên 30 manipulation tasks, 20 loại robot khác nhau (UR5, Franka, ARX5, ALOHA).
RAMP vs RECAP — So sánh trực tiếp
| Task | RAMP | RECAP | Cải thiện |
|---|---|---|---|
| Box Packing | ~95% | ~65% | +30% |
| Espresso Preparation | ~95% | ~65% | +30% |
| Laundry Folding | ~90% | ~60% | +30% |
Cải thiện lớn nhất ở các task dài và phức tạp — nơi mà "tưởng tượng tương lai" cho advantage lớn nhất. Với task đơn giản (pick-and-place), gap nhỏ hơn.
Value Prediction Quality
| Phương pháp | Thời gian inference | MAE | Kendall τ |
|---|---|---|---|
| VLM-based | 0.32s | 0.0683 | 0.7972 |
| WM value-only | 0.11s | 0.0838 | 0.7288 |
| WM state+value | 0.25s | 0.0621 | 0.8018 |
World Model dự đoán state+value đồng thời cho kết quả tốt nhất, với latency chấp nhận được (0.25s trên A800).
Tips thực hành
1. Bắt đầu từ pretrained weights
Đừng train từ scratch trừ khi bạn có cluster GPU lớn. Dùng GigaBrain-0.1-3.5B-Base hoặc GigaBrain-0-3.5B-Base (không cần depth camera) làm checkpoint khởi đầu.
2. Chọn đúng delta-mask
Delta-mask sai sẽ khiến robot "run away" — joints tăng vô hạn. Quy tắc:
- Joints (góc/vị trí):
True(delta) - Gripper:
False(absolute — mở/đóng)
3. Action chunk size
Default là 50 steps. Nếu task của bạn có tần số control cao hơn (>30Hz), giảm chunk size. Nếu task chậm (pha chế cà phê), 50 là hợp lý.
4. Stochastic masking khi deploy
Giữ p=0.2 masking cả khi inference. Điều này tạo "dropout-like" regularization, giúp policy robust hơn với noise từ World Model.
Kết luận
GigaBrain-0.5M* đánh dấu một bước tiến lớn: VLA không chỉ bắt chước, mà còn biết "mơ" và học từ giấc mơ. Framework RAMP cho phép kết hợp world model vào RL training một cách có hệ thống, và kết quả thực nghiệm cho thấy cải thiện đáng kể so với các phương pháp trước đó.
Với code open-source (Apache 2.0), pretrained weights trên HuggingFace, và hỗ trợ nhiều platform robot, đây là một trong những framework VLA dễ tiếp cận nhất hiện nay cho cộng đồng robotics.
Links quan trọng:
- Paper: arxiv.org/abs/2602.12099
- GitHub: github.com/open-gigaai/giga-brain-0
- Project page: gigabrain05m.github.io
- HuggingFace: huggingface.co/open-gigaai
Bài viết liên quan
- VLA Models: Từ ngôn ngữ đến hành động robot — Tổng quan về Vision-Language-Action models
- Reinforcement Learning cơ bản cho Robotics — Nền tảng RL trước khi đọc về RAMP
- Diffusion Policy cho Robot Manipulation — Hiểu Diffusion Transformer — backbone của GigaBrain