VLA là gì và tại sao nó quan trọng?
Vision-Language-Action (VLA) models là thế hệ mới nhất trong robot learning — kết hợp khả năng nhìn (vision), hiểu ngôn ngữ (language), và ra quyết định hành động (action) trong một model thống nhất. Nếu LLM là "bộ não" cho text, VLA là "bộ não" cho robot.
LLM: Text → Text (ChatGPT, Claude)
VLM: Image + Text → Text (GPT-4V, LLaVA)
VLA: Image + Text → Robot Actions (RT-2, OpenVLA, π0)
Từ 2023 đến 2025, VLA đã trải qua evolution ngoạn mục — từ model 55B parameters closed-source chỉ chạy trên 1 robot, đến model open-source chạy đa robot với open-world generalization. Bài viết này trace toàn bộ evolution đó.

Timeline: VLA Evolution 2023-2026
2023 Jul ──── RT-2 (Google DeepMind)
55B params, closed-source, emergent reasoning
↓
2024 May ──── Octo (UC Berkeley)
93M params, open-source, cross-embodiment, diffusion head
↓
2024 Jun ──── OpenVLA (Stanford)
7B params, open-source, beats RT-2-X
↓
2024 Oct ──── π0 (Physical Intelligence)
Flow matching, 50Hz, dexterous manipulation
↓
2025 Apr ──── π0.5 (Physical Intelligence)
Open-world generalization, clean kitchens & bedrooms
↓
2025-26 ──── DexVLA, ChatVLA-2, π0-FAST...
Community explosion, specialization
Mỗi model trong timeline này giải quyết một vấn đề cụ thể mà model trước để lại. Hãy deep-dive từng cái.
RT-2: Model đầu tiên chứng minh VLA khả thi
Bối cảnh
Trước RT-2, Google đã có RT-1 (2022) — một robot transformer policy mạnh nhưng chỉ hiểu được tasks nó đã thấy trong training data. Hỏi RT-1 "pick up something to clean a spill" — nó không biết khăn giấy dùng để lau.
RT-2 (Brohan et al., 2023) giải quyết bằng cách: tận dụng web-scale knowledge từ pre-trained VLM.
Architecture: VLM + tokenized actions
Ý tưởng cốt lõi cực kỳ elegant: biến robot actions thành text tokens, rồi fine-tune VLM để output actions giống hệt output text.
Input:
[Image] Camera observation
[Text] "Pick up the red cup and place it on the plate"
PaLI-X 55B (Pre-trained Vision-Language Model)
- Đã thấy hàng tỷ image-text pairs trên Internet
- Hiểu objects, spatial relationships, common sense
↓
Output tokens: "1 128 91 241 1 128 91"
↓
De-tokenize: [x=0.12, y=0.50, z=0.36, rx=0.94, ry=0.01, rz=0.50, gripper=0.36]
Mỗi action dimension được discretize thành 256 bins (0-255) và biểu diễn dưới dạng integer text. Model xử lý actions giống hệt text tokens — không cần thay đổi architecture hay training pipeline. Đây là điểm genius: tái sử dụng toàn bộ VLM infrastructure.
Emergent reasoning — Điểm breakthrough
Kết quả đáng kinh ngạc nhất không phải performance trên seen tasks (tương đương RT-1), mà là emergent capabilities:
| Capability | RT-1 | RT-2 (PaLI-X 55B) |
|---|---|---|
| Seen tasks | 95% | 95% |
| Unseen objects | 32% | 62% |
| Unseen backgrounds | 36% | 52% |
| Semantic reasoning | 0% | 48% |
"Semantic reasoning" nghĩa là: model hiểu "pick up something you can use to clean a spill" → chọn khăn giấy, mặc dù chưa bao giờ thấy instruction này trong robot training data. Knowledge từ web pre-training (biết khăn giấy dùng để lau) transfer sang robot control.
Hạn chế nghiêm trọng
Nhưng RT-2 có 3 vấn đề lớn:
- 55B parameters — không thể deploy trên edge, cần cluster GPU
- Closed-source — không ai ngoài Google reproduce được
- Single robot — chỉ test trên Google's RT robot, không có cross-embodiment
- Inference chậm (~3 Hz) — quá chậm cho reactive manipulation
- Deterministic actions — tokenized output là single mode, không capture multimodal distributions
Những hạn chế này tạo ra cơ hội cho models tiếp theo.
Octo: Open-source generalist policy đầu tiên
Vấn đề Octo giải quyết
Octo (Ghosh, Dibya et al., 2024) từ UC Berkeley giải quyết 3 vấn đề lớn nhất của RT-2:
- Closed-source → Fully open-source (weights + code + data)
- Single robot → Cross-embodiment (22 robot platforms)
- Deterministic → Multi-modal action output (diffusion head)
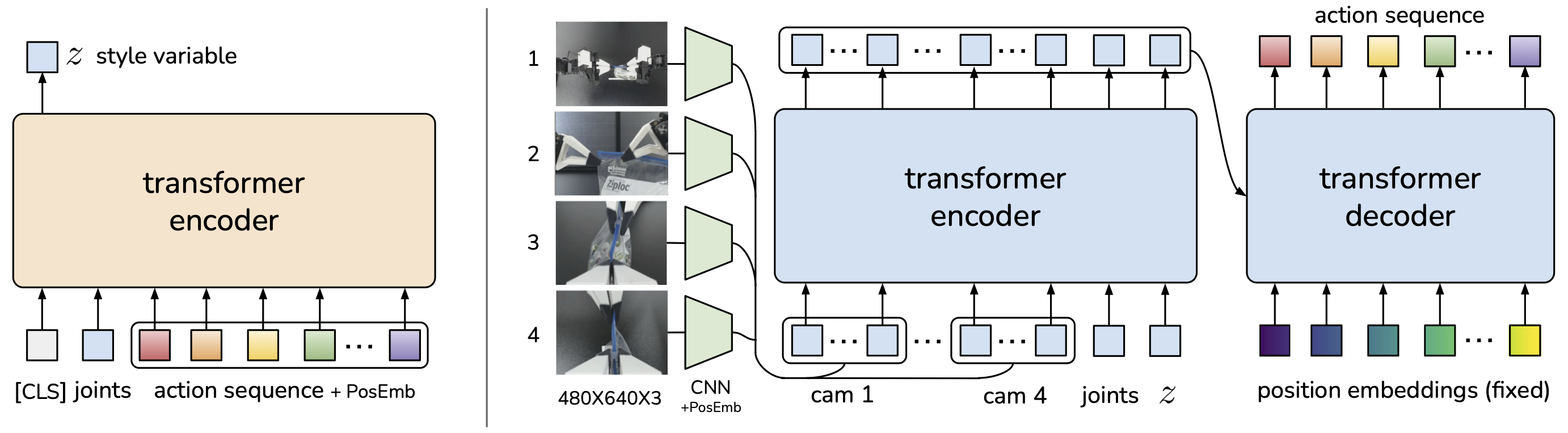
Architecture: Custom transformer + diffusion head
Thay vì build trên VLM khổng lồ, Octo thiết kế transformer architecture chuyên biệt cho robotics:
Input tokens:
[Language] "Pick up the blue block" → Language encoder
[Image] Observation history (t-2, t-1, t) → ViT patches
[Proprio] Joint positions / EE pose → Linear projection
↓
Transformer Backbone (with readout tokens)
- Readout tokens: learnable tokens attend to all inputs
- Capture cross-modal information
↓
Diffusion Action Head
- DDPM-based head thay vì simple regression
- Output: multi-modal action distribution
↓
Action: [a_t, a_{t+1}, ..., a_{t+H}] (action chunk)
Diffusion action head là key innovation — lấy cảm hứng từ Diffusion Policy (Chi et al., RSS 2023). Thay vì predict mean action (single mode), Octo sample từ learned distribution, tự nhiên capture được multimodal actions.
Training data: Open X-Embodiment
Octo train trên Open X-Embodiment dataset — 800K+ robot episodes từ 22 robot platforms:
| Dataset | Robot | Tasks | Episodes |
|---|---|---|---|
| Bridge V2 | WidowX | Manipulation | 60K |
| RT-1 | Google RT | Pick/Place | 130K |
| Taco Play | Franka | Language-conditioned | 6K |
| Kuka | Kuka iiwa | Stacking, insertion | 516K |
| Total | 22 robots | Diverse | 800K+ |
Diversity này cho phép Octo học embodiment-agnostic features — hiểu "pick up" nghĩa là gì bất kể robot có 6 hay 7 joints.
Hai phiên bản
| Octo-Small | Octo-Base | |
|---|---|---|
| Parameters | 27M | 93M |
| Fine-tune time | ~2 hours (1x RTX 3090) | ~4 hours (1x A100) |
| Zero-shot cross-embodiment | Weak | Moderate |
| After fine-tuning (50 demos) | Good | Strong |
Trade-offs
Ưu điểm: Open-source, nhẹ (93M params), cross-embodiment, diffusion head cho multimodal actions, fine-tune dễ với consumer GPU.
Nhược điểm: Không có web-scale VLM knowledge (thiếu common sense reasoning), semantic understanding yếu hơn RT-2, cần fine-tune cho mỗi task mới.
OpenVLA: Best of both worlds
Vấn đề OpenVLA giải quyết
OpenVLA (Kim et al., 2024) từ Stanford kết hợp ưu điểm của cả RT-2 và Octo:
- Từ RT-2: Build trên pre-trained VLM → có web-scale knowledge
- Từ Octo: Open-source, cross-embodiment training
- Cải tiến: 7B params (vs RT-2's 55B) → chạy được trên consumer GPU
Architecture: Prismatic VLM + robot fine-tuning
Visual Encoder (dual):
SigLIP → vision-language alignment features
DINOv2 → spatial/geometric features
↓
Projector (MLP) — fuse visual features
↓
Llama 2 7B backbone
- Pre-trained language model
- Fine-tuned on 970K robot demos
↓
Output: Tokenized actions (256 bins per dimension)
Dual visual encoder là key insight: SigLIP mang semantic understanding (biết "cup" là gì), DINOv2 mang spatial understanding (biết cup ở đâu trong 3D space). Kết hợp cả hai cho robot "vừa hiểu vừa thấy".
Kết quả: Beats RT-2-X với 7x ít parameters hơn
| Benchmark (29 tasks) | RT-2-X (55B) | Octo-Base (93M) | OpenVLA (7B) |
|---|---|---|---|
| Average success rate | Baseline | -2.1% | +16.5% |
| BridgeData V2 tasks | 43.2% | 41.8% | 55.7% |
| RT-1 tasks | 72.1% | 70.5% | 78.3% |
OpenVLA đạt +16.5% improvement so với RT-2-X baseline, trong khi chỉ dùng 7B parameters (7x nhỏ hơn RT-2's 55B). Điều này cho thấy: VLM backbone quality + good robot fine-tuning > raw parameter count.
Fine-tune với LoRA trên consumer GPU
"""
Fine-tune OpenVLA 7B với LoRA
Yêu cầu: 1x RTX 3090/4090 (24GB VRAM)
"""
from transformers import AutoModelForVision2Seq, AutoProcessor
from peft import LoraConfig, get_peft_model
model_id = "openvla/openvla-7b"
model = AutoModelForVision2Seq.from_pretrained(
model_id, torch_dtype=torch.bfloat16, trust_remote_code=True
)
# LoRA: chỉ fine-tune 0.17% parameters
lora_config = LoraConfig(
r=32, lora_alpha=32,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.05,
)
model = get_peft_model(model, lora_config)
# trainable: 13.1M / 7.6B = 0.17%
Trade-offs
Ưu điểm: Open-source, strong VLM backbone, cross-embodiment, LoRA fine-tuning trên consumer GPU, beats RT-2-X.
Nhược điểm: Vẫn deterministic output (tokenized, single mode), inference ~6 Hz (nhanh hơn RT-2 nhưng chưa real-time), 7B vẫn lớn cho edge devices.

pi0: Flow matching cho dexterous manipulation
Vấn đề pi0 giải quyết
pi0 (Black, Janner et al., 2024) từ Physical Intelligence giải quyết vấn đề mà tất cả VLA trước đó đều gặp: dexterous manipulation cần smooth, high-frequency actions.
RT-2 và OpenVLA output tokenized (discrete) actions ở 3-6 Hz — đủ cho pick-and-place nhưng hoàn toàn không đủ cho:
- Gấp quần áo (cần smooth bimanual coordination)
- Rót nước (cần precise force control)
- Lau bàn (cần adaptive trajectories)
Architecture: VLM + flow matching action expert
pi0 dùng flow matching thay vì DDPM diffusion — key innovation:
Block 1 (VLM Expert):
[Image tokens] + [Language tokens]
→ Pre-trained 3B VLM (PaliGemma-based)
→ Semantic understanding + task specification
↓
Block 2 (Action Expert):
[Proprioception] + [Noisy action chunk]
→ Flow matching network
→ Smooth denoising in continuous space
↓
Cross-attention: Action expert attends to VLM features
↓
Output: 50-action chunk (1 second at 50Hz)
Flow matching vs DDPM:
| DDPM (Diffusion Policy) | Flow Matching (pi0) | |
|---|---|---|
| Transport | Stochastic SDE | Deterministic ODE |
| Inference steps | 50-100 | 10-20 |
| Action quality | High | Comparable/higher |
| Speed | Slower | 2-5x faster |
| Training | Noise scheduling complex | Simpler objective |
Flow matching learn straight-line paths từ noise tới data trong latent space, thay vì curved stochastic paths của DDPM. Kết quả: ít inference steps hơn, nhanh hơn, smooth hơn.
Training data: 10,000 giờ robot experience
pi0 train trên dataset khổng lồ:
- 903 million timesteps từ Physical Intelligence's robot fleet
- 90 million timesteps từ open-source (OXE, BridgeData V2, DROID)
- Multiple robots: Single-arm, bimanual, dexterous hands
- Diverse tasks: Folding laundry, packing boxes, clearing tables
Inference: 73ms cho 50-action chunk
Trên GeForce RTX GPU, pi0 inference 73ms để generate 50 actions = 1 giây at 50Hz. Đây là breakthrough — lần đầu tiên VLA model chạy đủ nhanh cho smooth dexterous manipulation.
Inference: 73ms → 50 actions at 50Hz
= 1 giây robot trajectory per inference
= Smooth enough cho folding, pouring, wiping
Trade-offs
Ưu điểm: Smooth continuous actions (flow matching), 50Hz control, dexterous manipulation, massive training data.
Nhược điểm: Closed-source (weights not public cho full model), cần large compute for training, dataset not open.
pi0.5: Open-world generalization
Bước nhảy tiếp theo
pi0.5 (Physical Intelligence, 2025) mở rộng pi0 với khả năng open-world generalization — robot hoạt động trong môi trường chưa bao giờ thấy.
Knowledge insulation
Key innovation: co-training trên heterogeneous data sources mà không bị interference:
Data sources:
1. Robot manipulation data (Physical Intelligence fleet)
2. Navigation data (mobile bases)
3. Web data (image-text pairs)
4. High-level semantic prediction data
↓
Knowledge insulation training
- Mỗi data source train separate "expert" modules
- Shared backbone learns general representations
- Không bị catastrophic forgetting
↓
Result: Model hiểu cả low-level manipulation + high-level planning
Kết quả: Clean kitchens trong nhà chưa thấy
Physical Intelligence test pi0.5 tại 3 rental homes ở San Francisco — môi trường hoàn toàn mới, layout khác nhau, đồ đạc khác nhau. Robot (mobile manipulator) thực hiện:
- Dọn bếp: Thu gom đĩa, bỏ vào dishwasher, lau countertop
- Dọn phòng ngủ: Gấp chăn, sắp xếp gối, nhặt đồ trên sàn
Lần đầu tiên, end-to-end learned robotic system hoàn thành long-horizon manipulation tasks trong unseen homes. Không hard-coded behaviors, không per-home fine-tuning.
Open-source: openpi
Physical Intelligence release openpi — framework cho fine-tuning pi0 models. Mặc dù full pi0.5 weights chưa public, community có thể fine-tune smaller versions cho custom tasks.
Bảng so sánh tổng hợp
| RT-2 | Octo | OpenVLA | pi0 | pi0.5 | |
|---|---|---|---|---|---|
| Năm | 2023 | 2024 | 2024 | 2024 | 2025 |
| Tổ chức | UC Berkeley | Stanford | Physical Intelligence | Physical Intelligence | |
| Parameters | 55B | 27M / 93M | 7B | ~3B+ | ~3B+ |
| Open-source | Closed | Full open | Full open | Partial (openpi) | Partial (openpi) |
| Action output | Discrete tokens | Diffusion (continuous) | Discrete tokens | Flow matching (continuous) | Flow matching (continuous) |
| Inference speed | ~3 Hz | ~10 Hz | ~6 Hz | ~14 Hz (50-action chunks) | ~14 Hz |
| Cross-embodiment | 1 robot | 22 robots | Multi-robot | Multi-robot | Multi-robot + mobile |
| Fine-tune cost | N/A | 1x RTX 3090 | 1x RTX 3090 (LoRA) | Large GPU cluster | Large GPU cluster |
| Semantic reasoning | Strong (55B VLM) | Weak | Good (7B VLM) | Good (3B VLM) | Strong (+ web data) |
| Dexterous manip. | Limited | Limited | Limited | Strong | Strong |
| Open-world | Partial | No | Partial | No | Yes |
| arXiv | 2307.15818 | 2405.12213 | 2406.09246 | 2410.24164 | 2504.16054 |
Chọn model nào cho project của bạn?
Decision tree
Bạn cần gì?
│
├── Research / học tập → OpenVLA hoặc Octo
│ ├── Có RTX 3090+ → OpenVLA (LoRA fine-tune)
│ └── GPU yếu hơn → Octo-Small (27M, nhẹ)
│
├── Production manipulation → Tùy task complexity
│ ├── Simple pick-place → Octo fine-tuned
│ ├── Dexterous tasks → pi0 (nếu budget cho compute)
│ └── Multi-modal actions → Diffusion Policy (xem Part 4)
│
├── Cross-embodiment (nhiều loại robot) → Octo
│
└── Open-world / unseen environments → pi0.5 (SOTA)
Xu hướng sắp tới
- Smaller, faster VLAs: Distillation và quantization để VLA chạy trên edge (Jetson, Raspberry Pi)
- Diffusion + VLA fusion: DexVLA, Diffusion Transformer Policy — kết hợp ưu điểm continuous actions với VLM reasoning
- World models: VLA không chỉ predict actions mà predict cả future states — better planning
- Sim-to-real pre-training: Massive simulation data + real data fine-tuning
- Multi-modal inputs: Thêm tactile, force/torque, audio ngoài vision
VLA models đang ở giai đoạn tương đương GPT-3 cho NLP — đủ mạnh để thấy tiềm năng, nhưng chưa đủ reliable cho mọi use case. Evolution từ RT-2 đến pi0.5 cho thấy tốc độ phát triển cực nhanh — mỗi 6 tháng có một bước nhảy lớn.
Nếu bạn đang bắt đầu: OpenVLA + LoRA fine-tuning là entry point tốt nhất — open-source, documentation đầy đủ, chạy trên consumer GPU, community support mạnh.
Bài viết liên quan
- Diffusion Policy: Cách mạng robot manipulation — Deep-dive vào diffusion models cho robot actions
- Foundation Models cho Robot: RT-2, Octo, OpenVLA thực tế — Hướng dẫn fine-tune chi tiết
- Xu hướng nghiên cứu robotics 2025 — Research landscape tổng quan
- Sim-to-Real Transfer: Train simulation, chạy thực tế — Kỹ thuật sim-to-real cho VLA models
- AI và Robotics 2025: Xu hướng và ứng dụng thực tế — Ứng dụng thực tế trong industry