Tại sao VLA models cần hiểu 3D?
Trong bài trước về Foundation Models cho Robot, chúng ta đã phân tích RT-2, Octo và OpenVLA — những model VLA (Vision-Language-Action) mạnh mẽ có thể nhận camera image + language instruction và output robot actions. Tuy nhiên, tất cả đều có một hạn chế chung: chúng xử lý thế giới như ảnh 2D phẳng.
Hãy tưởng tượng bạn yêu cầu robot "đặt cốc lên kệ trên cùng". Robot nhìn thấy cốc và kệ qua camera — nhưng từ ảnh 2D, nó không biết kệ cách bao xa, cốc nặng bao nhiêu so với khoảng cách cần di chuyển, hay gripper cần nghiêng bao nhiêu độ để không va vào kệ dưới.
Vấn đề cốt lõi: Depth ambiguity. Một vật ở gần camera nhưng nhỏ trông giống hệt vật ở xa nhưng lớn trong ảnh 2D. Không có depth information, robot phải "đoán" — và trong manipulation, đoán sai 2cm có thể khiến task fail hoàn toàn.

Bằng chứng thực nghiệm
Các thí nghiệm trên benchmark cho thấy khi thay đổi spatial layout (di chuyển vật thể sang vị trí mới, thay đổi độ cao kệ), success rate của OpenVLA và các policy không có depth information giảm dưới 50% — trong khi con người thực hiện cùng task gần như không bị ảnh hưởng. Điều này cho thấy 2D VLA models đang thiếu một thành phần quan trọng: spatial reasoning.
Các tình huống mà 2D VLA gặp khó:
| Tình huống | Vấn đề 2D | Yêu cầu 3D |
|---|---|---|
| Stack objects | Không biết chiều cao chính xác | Depth estimation cho từng object |
| Place on shelf | Không biết khoảng cách tới shelf | 3D position của target |
| Avoid obstacles | Không biết obstacle ở trước hay sau | Spatial reasoning toàn cảnh |
| Precise insertion | Sai lệch mm-level từ 2D projection | 3D alignment |
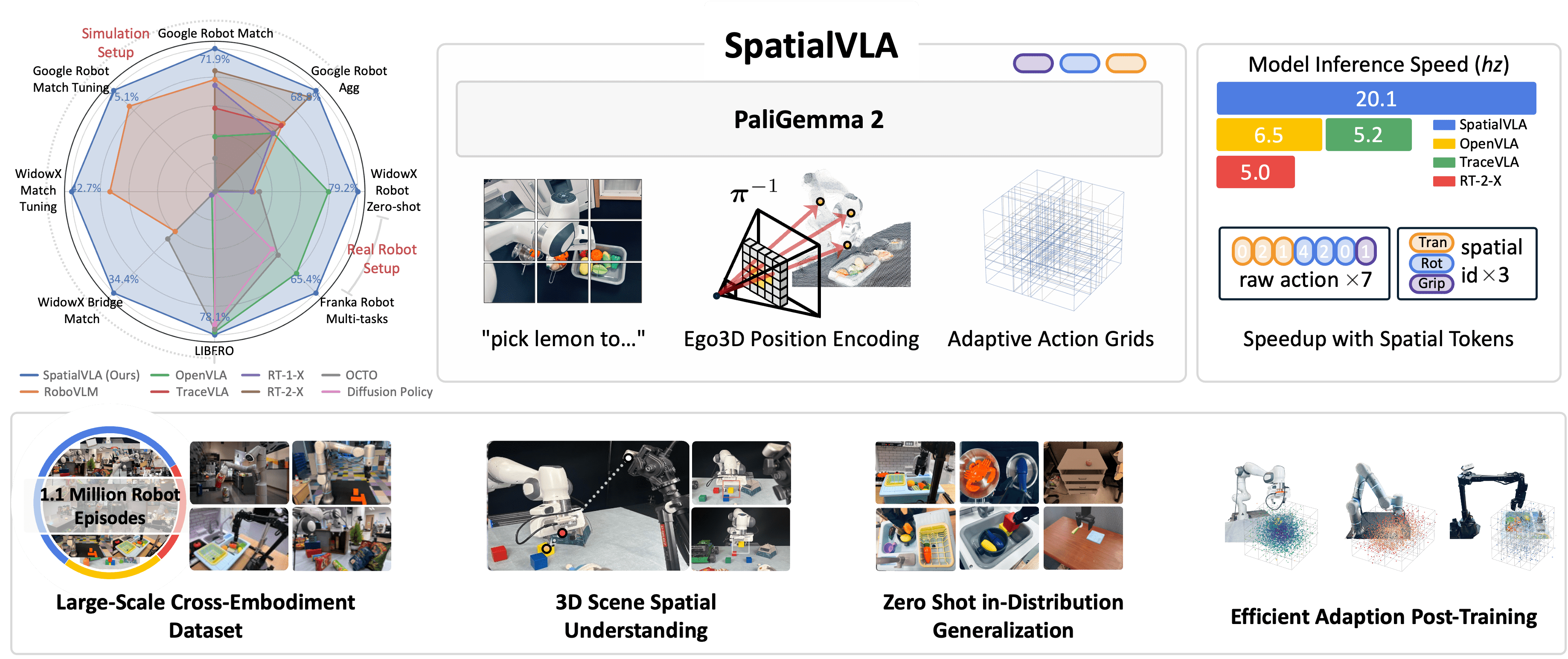
SpatialVLA: Kiến trúc và đổi mới
SpatialVLA (Qu et al., 2025, accepted tại RSS 2025) giải quyết vấn đề trên bằng hai đổi mới kỹ thuật: Ego3D Position Encoding và Adaptive Action Grids. Model được train trên 1.1 triệu real-world robot episodes — lớn hơn đáng kể so với Open X-Embodiment dataset (970K) mà OpenVLA sử dụng.
Ego3D Position Encoding — Nhìn thế giới qua chiều sâu
Ý tưởng cốt lõi: thay vì chỉ dùng 2D positional encoding cho image patches (như ViT truyền thống), SpatialVLA bổ sung 3D position information được estimate từ monocular depth.
Pipeline:
RGB Image (từ camera robot)
↓
Monocular Depth Estimator (e.g., DPT/Depth Anything)
↓
Depth Map → 3D Point Cloud (trong egocentric frame)
↓
Ego3D Position Encoding
↓
Fused với Visual Tokens trong VLM backbone
Tại sao "Egocentric"? Thay vì dùng world coordinate frame (cần calibration camera-robot chính xác), SpatialVLA biểu diễn mọi thứ trong camera frame — egocentric. Điều này có 2 lợi ích quan trọng:
- Không cần camera-robot calibration — triển khai trên robot mới không cần biết extrinsic parameters chính xác
- Universally applicable — hoạt động với bất kỳ robot embodiment nào, miễn có camera
Cụ thể, mỗi image patch tại vị trí pixel (u, v) với depth d được map sang 3D coordinate:
X = (u - cx) * d / fx
Y = (v - cy) * d / fy
Z = d
Ego3D_pos = MLP([X, Y, Z]) → positional embedding
Trong đó (fx, fy, cx, cy) là camera intrinsics. Embedding này được cộng vào visual tokens trước khi đưa vào transformer backbone, cho phép model "nhìn" chiều sâu mà không thay đổi architecture.
Adaptive Action Grids — Thống nhất action space
Vấn đề thứ hai: mỗi robot có action space khác nhau — Franka dùng 7D joint positions, WidowX dùng 6D end-effector velocity, ALOHA dùng 14D bimanual actions. OpenVLA xử lý bằng cách tokenize mỗi dimension thành 256 bins — nhưng phân bổ bins đều cho mọi range, lãng phí resolution ở vùng ít sử dụng.
Adaptive Action Grids giải quyết bằng cách:
- Phân tích statistical distribution của actions trên toàn bộ dataset cho mỗi robot
- Discretize actions thành grids thích ứng — nhiều bins hơn ở vùng action hay xuất hiện, ít bins hơn ở vùng hiếm
- Align action tokens với 3D spatial structure — action grids được thiết kế để phản ánh spatial meaning
# Ví dụ đơn giản hóa: Adaptive binning
import numpy as np
def adaptive_grid(actions, n_bins=256):
"""
Tạo adaptive bins dựa trên distribution thực tế
thay vì uniform bins
"""
# actions: shape (N, 7) — N episodes, 7 action dimensions
bins_per_dim = []
for dim in range(actions.shape[1]):
# Dùng quantiles thay vì linspace
percentiles = np.linspace(0, 100, n_bins + 1)
bins = np.percentile(actions[:, dim], percentiles)
bins_per_dim.append(bins)
return bins_per_dim
# Uniform: bins cách đều từ -1 đến 1
# Adaptive: bins dày ở vùng action phổ biến (gần workspace center)
# và thưa ở vùng hiếm (biên workspace)
Kết quả: action resolution cao hơn ở vùng quan trọng mà không tăng tổng số tokens.

Kết quả: SpatialVLA vs OpenVLA
SpatialVLA được evaluate trên 7 robot learning scenarios, 16 real-robot tasks, và 48 simulation setups. Kết quả cho thấy ưu thế rõ rệt, đặc biệt trong các task yêu cầu spatial reasoning.
Real-world Franka manipulation
| Task | OpenVLA | Octo | SpatialVLA |
|---|---|---|---|
| Pick spatial prompt (trái/phải/trước/sau) | < 50% | < 50% | 73% |
| Stack with height awareness | ~40% | ~35% | 68% |
| Place at specific location | ~45% | ~42% | 71% |
Zero-shot WidowX (out-of-distribution)
Đây là test khắc nghiệt nhất — SpatialVLA chưa bao giờ thấy WidowX robot layout cụ thể này:
- OpenVLA và Octo: consistently dưới 50% khi spatial layout thay đổi
- SpatialVLA: duy trì 60-70% success rate nhờ 3D understanding
Inference speed
SpatialVLA cũng cải thiện inference speed nhờ compact action representation:
| Model | Tokens per action | Inference (Hz) |
|---|---|---|
| OpenVLA | 7 tokens (7D) | ~6 Hz |
| Octo-Base | Diffusion steps | ~10 Hz |
| SpatialVLA | Fewer spatial tokens | ~8 Hz |
3D Representations trong Robotics: Bức tranh toàn cảnh
SpatialVLA sử dụng monocular depth — phương pháp đơn giản nhất để có 3D information. Nhưng đây chỉ là một phần trong landscape rộng hơn của 3D representations cho robot perception.
Point Clouds
Cách hoạt động: LiDAR hoặc stereo camera tạo ra tập hợp điểm 3D (x, y, z) cho mỗi surface trong scene.
Ưu điểm: Chính xác, explicit geometry, xử lý nhanh với PointNet/PointNet++.
Nhược điểm: Sparse (không có thông tin về surface liên tục), không có appearance/texture.
Ứng dụng: Grasping (Contact-GraspNet), navigation, bin picking trong công nghiệp.
Neural Radiance Fields (NeRF)
Cách hoạt động: Train neural network để biểu diễn scene dưới dạng continuous volumetric function — cho bất kỳ point (x, y, z) và viewing direction, output color và density.
Ưu điểm: Photo-realistic novel view synthesis, smooth surfaces, compact representation.
Nhược điểm: Training chậm (phút-giờ), inference chậm (seconds per render), khó update real-time.
Ứng dụng trong robotics: Scene understanding, sim-to-real transfer — dùng NeRF để tạo photorealistic training environments.
3D Gaussian Splatting (3DGS)
Cách hoạt động: Biểu diễn scene bằng tập hợp 3D Gaussians, mỗi Gaussian có position, covariance, opacity và spherical harmonics coefficients cho color. Render bằng differentiable rasterization thay vì ray marching.
Ưu điểm: Real-time rendering (100+ FPS), training nhanh hơn NeRF (phút thay vì giờ), explicit representation dễ manipulate.
Nhược điểm: Memory-intensive (millions of Gaussians), không smooth bằng NeRF.
Ứng dụng mới nhất trong robotics:
- RoboSplat (RSS 2025): dùng 3DGS để generate novel demonstrations cho policy learning — tạo diverse training data từ ít demonstrations thực
- POGS (ICRA 2025): tracking và manipulation vật thể bất quy tắc bằng Persistent Object Gaussian Splat
- SplatSim: zero-shot sim-to-real transfer cho RGB manipulation policies
So sánh tổng quan
| Representation | Training | Rendering | Explicit? | Real-time? | Robot-friendly? |
|---|---|---|---|---|---|
| Point Cloud | N/A | N/A | Yes | Yes | High |
| NeRF | Slow (hours) | Slow (sec) | No | No | Medium |
| 3DGS | Fast (min) | Real-time | Yes | Yes | High |
| Monocular Depth | Pre-trained | Real-time | Yes | Yes | Highest |
SpatialVLA chọn monocular depth vì nó không cần hardware bổ sung (LiDAR, stereo camera) và chạy real-time — phù hợp nhất cho general-purpose VLA model.
Tương lai: VLA + 3D Scene Understanding
SpatialVLA mở ra hướng nghiên cứu kết hợp VLA với 3D understanding sâu hơn:
Short-term (2026-2027)
- Multi-view VLA: Thay vì 1 camera, dùng nhiều cameras hoặc wrist + head camera để xây dựng richer 3D representation. Một số lab đã bắt đầu thử nghiệm stereo VLA.
- Depth foundation models tốt hơn: Depth Anything V2 và các model metric depth đang improve nhanh — SpatialVLA sẽ benefit trực tiếp.
- Tactile + 3D: Kết hợp touch sensing với 3D vision cho manipulation tinh vi (lắp ráp, handling soft objects).
Medium-term (2027-2028)
- VLA + 3DGS real-time: Dùng Gaussian Splatting làm world model cho VLA — robot "tưởng tượng" kết quả action trước khi thực hiện.
- 4D understanding: Không chỉ 3D tĩnh mà hiểu dynamics — vật sẽ di chuyển thế nào khi bị đẩy, chất lỏng sẽ chảy ra sao.
Long-term vision
- Embodied 3D foundation model: Một model duy nhất hiểu 3D world ở level sâu — có thể plan, manipulate, navigate, và reason về physics — không chỉ map pixel sang action.
Đây là một trong những hướng nghiên cứu exciting nhất trong robot learning hiện tại. SpatialVLA là bước đầu tiên quan trọng — chứng minh rằng 3D spatial information cải thiện VLA models một cách measurable trên real robots.
Takeaway cho practitioners
Nếu bạn đang build robot manipulation system:
- Nếu dùng OpenVLA/Octo: Cân nhắc thêm depth estimation vào input pipeline — ngay cả simple monocular depth đã giúp nhiều.
- Nếu task cần spatial precision: SpatialVLA hoặc approach tương tự nên là first choice. Fine-tune trên your robot data sẽ cho kết quả tốt nhất.
- Hardware: Không cần LiDAR hay stereo camera — monocular depth từ pre-trained model đủ cho hầu hết manipulation tasks.
- Next step: Theo dõi SpatialVLA GitHub để cập nhật weights và fine-tuning code khi released.
Trong bài tiếp theo, chúng ta sẽ đi vào thực hành: fine-tune OpenVLA với LeRobot — từ record data đến deploy trên robot thật.
Bài viết liên quan
- Foundation Models cho Robot: RT-2, Octo, OpenVLA thực tế -- Tổng quan foundation models cho robotics
- Hands-on: Fine-tune OpenVLA với LeRobot -- Tutorial thực hành fine-tune VLA model
- Sim-to-Real Transfer: Train simulation, chạy thực tế -- Kỹ thuật chuyển model từ simulation sang robot thật
- Xu hướng nghiên cứu robotics 2025 -- Tổng quan research landscape