ABot-M0: VLA Foundation Model với Action Manifold Learning từ AMAP CVLab
Tháng 3/2026, đội AMAP CVLab thuộc Alibaba Group công bố ABot-M0 — một VLA foundation model cho robotic manipulation, kèm theo trọn bộ code, pretrained weights, và pipeline xử lý dữ liệu. Điểm đáng chú ý nhất không phải ở quy mô (dù tập huấn luyện UniACT của họ với hơn 6 triệu trajectories và 9,500 giờ dữ liệu thực sự là tập mở lớn nhất hiện tại), mà ở một thay đổi tư duy trong cách model học hành động: thay vì học noise như diffusion policy quen thuộc, ABot-M0 học trực tiếp clean action nằm trên một manifold thấp chiều do vật lý và mục tiêu nhiệm vụ định hình.
Bài viết này đi từ ý tưởng cốt lõi, qua kiến trúc, đến cách cài đặt và chạy thử các pretrained weights. Phù hợp cho kỹ sư đang tìm một VLA "đặt vào chạy được" cho robot arm hoặc humanoid của mình.
Tham khảo: ABot-M0 paper trên arXiv, project page chính thức, GitHub repo, và HuggingFace weights.

1. Ý tưởng cốt lõi: Action Manifold Hypothesis
Nếu bạn từng train Diffusion Policy hay π0, công thức quen thuộc là: thêm Gaussian noise vào chuỗi action, rồi để model học denoising — từng bước "đoán noise đã thêm" để ngược lại về action sạch. Cách này rất mạnh, nhưng có hai vấn đề mà ABot-M0 chỉ thẳng ra:
- Tốc độ decode chậm — phải chạy nhiều bước denoising cho mỗi action chunk.
- Bất ổn khi cross-embodiment — noise schedule được set chung cho mọi robot, nhưng cấu hình action space khác nhau giữa Franka, Aloha, UR-5, dual-arm humanoid… khiến quá trình denoising không cùng "tốc độ hội tụ".
Nhóm AMAP đưa ra giả thuyết: trong không gian action high-dimensional, các action thành công không rải đều — chúng nằm trên một manifold thấp chiều, được hình thành bởi các ràng buộc vật lý (kinematics, dynamics, contact), mục tiêu nhiệm vụ, và môi trường. Đường đi của một cánh tay khi pick-and-place không phải bất kỳ chuỗi nào trong $\mathbb{R}^{T \times 7}$, mà là một dải mỏng nằm trong đó.
Nếu manifold thật sự tồn tại, ta nên học projection lên manifold đó thay vì học noise. Trong code, hàm mất mát đổi từ:
# Diffusion policy
noise_pred = model(noisy_action, t, obs)
loss = mse(noise_pred, true_noise)
sang:
# Action Manifold Learning (AML)
action_pred = model(latent, obs)
loss = mse(action_pred, clean_action)
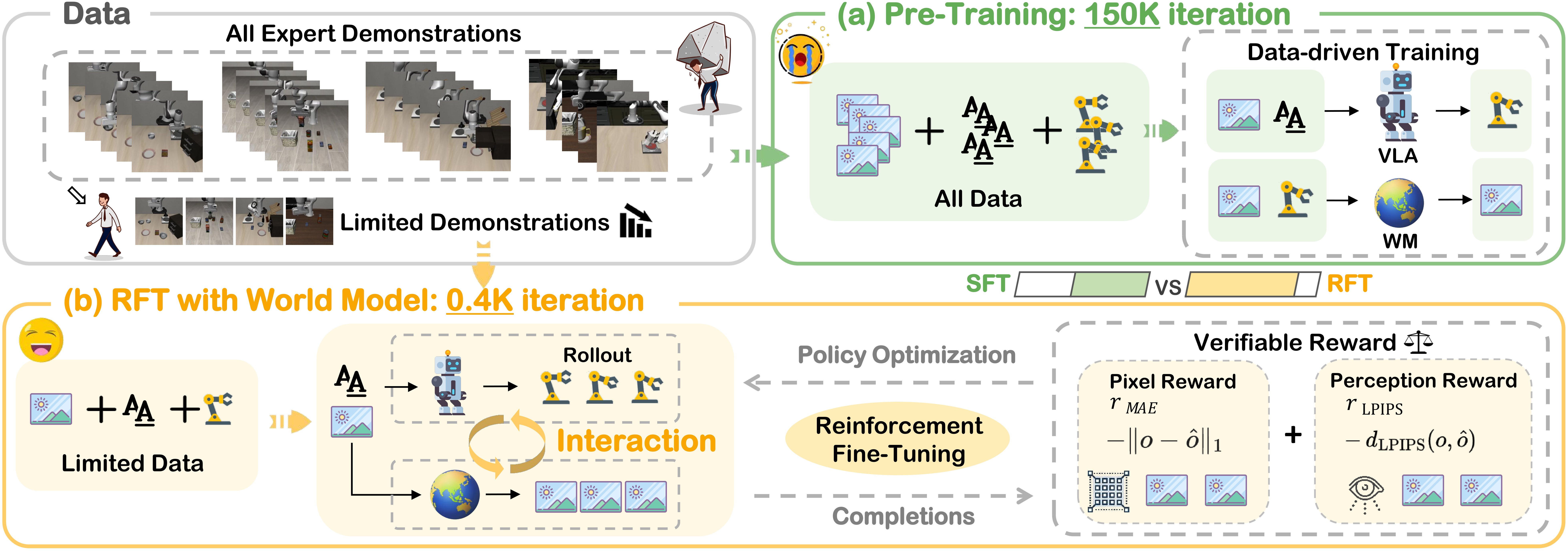
Đơn giản hơn nhiều, nhưng để model không sụp đổ về mean action, AML thêm vài cơ chế: latent prior có cấu trúc, regularization theo độ trơn (smoothness) của chuỗi action, và residual head để bắt detail nhỏ. Ablation trong paper cho thấy AML vừa giảm số bước decode, vừa tăng stability khi train trên dữ liệu cross-embodiment hỗn tạp.
Nếu bạn muốn so sánh hai paradigm này trong cùng một codebase, bài Diffusion Policy đã giải thích chi tiết phần denoising — đọc trước sẽ thấy AML "đảo ngược" ở chỗ nào.
2. Kiến trúc tổng thể
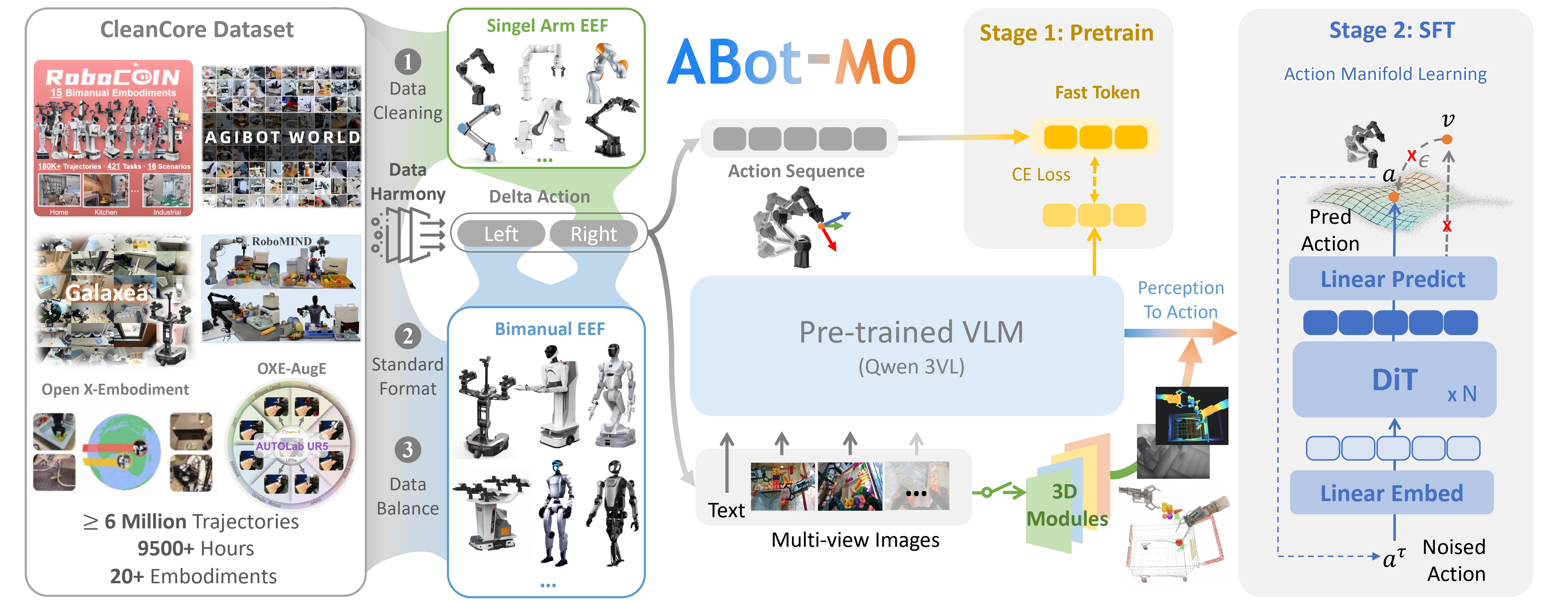
ABot-M0 dùng backbone DiT (Diffusion Transformer) quen thuộc, nhưng thay đổi đầu ra để output trực tiếp action thay vì noise. Hệ thống có ba khối chính:
(a) VLM encoder — Nhận RGB từ nhiều camera + instruction text. Output là chuỗi token semantic mô tả "muốn làm gì, thấy gì".
(b) 3D perception adapter (plug-and-play) — Đây là điểm thiết kế hay: ABot-M0 không bắt buộc dùng module 3D nào cụ thể. Bạn có thể plug VGGT (Visual Geometry Grounded Transformer) để có point map dense, hoặc Qwen-Image-Edit cho geometric prior, mà không phải đụng vào backbone. Token 3D được concat song song với token VLM.
(c) Action manifold decoder — Một transformer học mapping từ (semantic tokens, 3D tokens, robot state) sang chunk action trong manifold space. Phần cuối có un-projection head đưa từ manifold latent về delta-action thực ở end-effector coordinate.
Một chi tiết kỹ thuật quan trọng cho cross-embodiment: action được chuẩn hóa thành delta end-effector với rotation vector representation (3D rotation chứ không phải quaternion 4D hay matrix 9D). Lý do: rotation vector liên tục hơn quaternion (không có double-cover), gọn hơn matrix, và biên độ delta dễ chuẩn hóa giữa các robot. Đối với single-arm, dual-arm khác nhau, họ dùng chiến lược pad-to-dual: luôn pad lên 2 cánh tay (14 DoF action), single-arm thì cánh thứ hai giữ zero — nhờ vậy một model duy nhất phục vụ cả single-arm và dual-arm.

3. UniACT Dataset — 6M+ trajectories
Phần data engineering của ABot-M0 đáng tiền hơn cả model. Họ trộn 6 dataset công khai lớn nhất (Open X-Embodiment, DROID, AgiBot-Beta, RoboMIND, RH20T, BridgeData V2…) thành UniACT-dataset với:
- 6,000,000+ trajectories
- 9,500+ giờ tương tác
- 20+ embodiments (Franka Panda, UR-5, Aloha, Kuka, Galaxea, AgiBot, humanoid GR1/GR2…)
Pipeline xử lý dữ liệu gồm bốn bước:
- Lọc invalid — bỏ trajectory có instruction trống, visual blur, hoặc action NaN.
- Chuẩn hóa action — đưa về delta end-effector (rotation vector), normalize theo statistics per-embodiment.
- Pad-to-dual — như mục 2.
- Re-balance — over/under-sampling theo embodiment để tránh dataset lớn (như OXE) nuốt hết signal.
Nếu bạn từng làm imitation learning, bạn biết bước 4 quan trọng tới mức nào. Một dataset có 70% là Franka pick-and-place thì model sẽ chỉ giỏi Franka pick-and-place, dù bạn nói đang "train cross-embodiment".
4. Benchmark results
ABot-M0 đứng top hoặc gần top trên các benchmark chính:
| Benchmark | ABot-M0 | GR00T-N1.6 | X-VLA | π0-FAST |
|---|---|---|---|---|
| LIBERO (avg 4 suites) | 98.6% | 97.0% | 98.1% | 96.4% |
| LIBERO-Plus (zero-shot, 7 shifts) | 80.5% | — | — | — |
| RoboCasa-GR1 (24 tasks) | 58.3% | 47.6% | — | — |
| RoboTwin2.0 Clean | 80.4% | — | — | — |
| RoboTwin2.0 Randomized | 81.2% | — | — | — |
Số đáng để ý nhất không phải LIBERO (đã saturate) mà là LIBERO-Plus zero-shot 80.5% — đây là benchmark stress-test với 7 distribution shift (lighting, camera pose, distractor, language paraphrase…). Việc đứng đầu ở đây là dấu hiệu manifold thực sự đang generalize, không chỉ memorize.
5. Cài đặt
Yêu cầu hardware tối thiểu cho inference: 1× GPU 24GB (RTX 4090, A5000), 32GB RAM. Cho training fine-tune: 4× A100 80GB hoặc tương đương.
# Clone repo
git clone https://github.com/amap-cvlab/ABot-Manipulation.git
cd ABot-Manipulation
# Conda env
conda create -n ABot python=3.10 -y
conda activate ABot
# Core deps
pip install -r requirements.txt
# FlashAttention2 (bắt buộc cho DiT backbone)
pip install flash-attn --no-build-isolation
# VGGT cho 3D perception (optional, plug-and-play)
pip install vggt
# Install ABot package
pip install -e .
Lỗi phổ biến lần đầu chạy:
flash-attnbuild fail → CUDA toolkit version không khớp. Phải có CUDA 12.x vànvcc --versiontrả về cùng version với PyTorch.ModuleNotFoundError: vggt→ chưa chạypip install vggt, hoặc bạn dùng variant không cần 3D adapter (bỏ qua được).
6. Inference với pretrained weights
Có 4 variant trên HuggingFace acvlab/:
| Variant | Dùng cho |
|---|---|
ABot-Pretrain |
Backbone đa nhiệm, fine-tune tiếp được |
ABot-LIBERO |
Đã fine-tune trên LIBERO, eval ngay |
ABot-RoboCasa-GR1 |
Tabletop manipulation với humanoid GR1 |
ABot-RoboTwin2 |
Dual-arm Clean + Randomized |
Inference cơ bản với weights LIBERO:
from abot import ABotPolicy
from abot.envs import LiberoEnv
# Load policy
policy = ABotPolicy.from_pretrained("acvlab/ABot-LIBERO", device="cuda")
# Env LIBERO Spatial
env = LiberoEnv(suite="libero_spatial", task_id=0)
obs = env.reset()
for step in range(200):
# ABot-M0 predict clean action chunk (H=16 steps)
action_chunk = policy.predict(
rgb_images=obs["images"], # multi-view RGB
instruction=obs["language"], # text
robot_state=obs["state"], # joint + gripper
)
# Execute first action of chunk, rồi predict lại (open-loop chunking)
obs, reward, done, info = env.step(action_chunk[0])
if done:
break
Trên 1× RTX 4090, decode 1 action chunk mất khoảng 80ms — nhanh hơn diffusion policy điển hình (200-400ms cho 50 denoising steps) vì AML chỉ cần 1 forward pass.
7. Fine-tune trên robot của bạn
Khuyến nghị workflow:
- Thu data teleop — tối thiểu 50-100 demo cho task đơn giản, 200-500 cho task có nhiều object/phase.
- Convert sang định dạng UniACT — script
data_process/convert_to_uniact.pytrong repo lo phần này. Bạn cần cung cấp: RGB từ camera (≥2 view khuyến nghị), language instruction, robot state, delta end-effector action. - Fine-tune từ
ABot-Pretrain:
python examples/finetune.py \
--pretrained acvlab/ABot-Pretrain \
--dataset /path/to/your_dataset \
--output_dir ./checkpoints/my_robot \
--batch_size 32 \
--learning_rate 1e-4 \
--num_epochs 30 \
--enable_3d_adapter vggt # optional
- Eval — chạy 10-20 rollout trên robot thật, log success rate. Nếu thấy <50% trên task đơn giản → kiểm tra data quality trước, đừng vội tăng epoch.
Nếu bạn đang fine-tune trên humanoid full-body, bài Whole-Body VLA mới nhất có phần data recipe tương thích với cấu trúc dual-arm của ABot.
8. So sánh với VLA khác
| Model | Param | Predict | Cross-embodiment data | Open weights |
|---|---|---|---|---|
| RT-2 | ~55B | Action token | Hạn chế | ❌ |
| OpenVLA | 7B | Action token | OXE | ✅ |
| π0 / π0-FAST | 3B | Noise (flow) | DROID + custom | Partial |
| GR00T-N1.6 | 2-3B | Noise (diffusion) | Mixed | ✅ |
| ABot-M0 | 2-3B | Clean action (AML) | UniACT 6M | ✅ full |
ABot-M0 không phải lớn nhất, không phải SOTA tuyệt đối ở mọi benchmark, nhưng là gói open-source đầy đủ nhất ở thời điểm 2026: code, pretrained, data pipeline, eval scripts đều public, và license cho phép thương mại (kiểm tra lại trên repo trước khi deploy production).
Để hiểu sâu hơn về landscape VLA hiện tại, đọc tổng quan VLA models và VLA-0: action as text — VLA-0 đi hướng ngược lại với ABot-M0 (text token thay vì continuous manifold), so sánh hai approach rất khai sáng.
9. Pitfalls khi triển khai
- Đừng skip 3D adapter quá sớm — chạy chỉ với RGB token vẫn được, nhưng ở task spatial reasoning (LIBERO-Spatial, stacking) thì VGGT/Qwen-Image-Edit cải thiện đáng kể (≥5% success rate).
- Chunking horizon H — mặc định H=16 step. Nếu robot bạn chạy 10Hz, chunk 16 = 1.6s open-loop, có thể quá dài cho task contact-rich. Giảm xuống H=8 nếu thấy gripper lệch.
- Calibration camera — ABot-M0 expect intrinsics gần với DROID/OXE setup. Camera quá rộng (FOV >120°) hoặc quá hẹp (FOV <40°) làm 3D adapter sai. Calibrate trước khi blame model.
- Don't overfit pad-to-dual — single-arm robot khi pad-to-dual có cánh thứ hai = zero, nhưng nếu data fine-tune của bạn để dummy action không zero thì model học nhầm pattern.
10. Roads not taken
Có ba hướng AMAP đã thử rồi bỏ, đáng để biết:
- Score matching trên manifold — phức tạp hơn AML mà không hơn về success rate, training instability cao.
- Token-based action như RT-2/VLA-0 — đơn giản code, nhưng độ chính xác kém trên task continuous control (cầm cốc nước, đẩy nhẹ).
- End-to-end 3D backbone — thay vì plug-and-play 3D adapter. Tốn compute, khó scale, mất tính module hóa.
Quyết định giữ modular 3D + AML head là lý do repo dễ dùng cho R&D — bạn swap module rất dễ.
Bài viết liên quan
- VLA-Adapter từ OpenHelix: Tiny-Scale VLA chỉ 9.6GB VRAM — tiếp cận opposite về scale.
- Manipulation Series #4: Vision-Language-Action Models — nền tảng VLA trước khi vào ABot.
- GigaBrain-0: VLA + World Model + RL — cách thêm world model song song với VLA backbone.