VLA: Bước nhảy từ Task-Specific đến General-Purpose
Trong Part 2 và Part 3, mình đã nói về ACT và Diffusion Policy -- các methods train một policy cho một task. Muốn làm task mới? Thu data mới, train lại từ đầu.
Vision-Language-Action (VLA) models thay đổi cục diện này: train một model duy nhất trên data từ nhiều robot, nhiều task, rồi fine-tune hoặc zero-shot cho task cụ thể. Giống như GPT-4 hiểu nhiều ngôn ngữ, VLA models hiểu nhiều robot tasks.
Bài này phân tích 3 VLA models quan trọng nhất cho manipulation: RT-2 (Google DeepMind), Octo (UC Berkeley), và pi0 (Physical Intelligence) -- với góc nhìn thực tế về khi nào nên dùng, khi nào không.
Xem VLA Models deep dive để hiểu lý thuyết VLA chi tiết hơn.

RT-2: Vision-Language-Action từ Google DeepMind
Ý tưởng
RT-2 (Brohan et al., 2023) là VLA model đầu tiên chứng minh rằng web-scale knowledge chuyển được sang robot control. Ý tưởng đơn giản nhưng mạnh: lấy một Vision-Language Model (VLM) đã pre-train trên billions of images + text từ Internet, rồi co-fine-tune thêm với robot trajectory data.
Architecture
Input:
- Image: camera observation -> Vision encoder (ViT)
- Language: task instruction "Pick up the red cup"
- History: previous observations + actions
VLM backbone: PaLM-E (12B) hoặc PaLI-X (55B)
Output:
- Action tokens: được generate như text tokens
- Decode: token -> [dx, dy, dz, droll, dpitch, dyaw, gripper]
Điểm đặc biệt: RT-2 không thay đổi architecture của VLM. Nó chỉ thêm robot action tokens vào vocabulary và co-fine-tune. VLM vẫn hiểu ngôn ngữ và hình ảnh như bình thường, nhưng giờ còn output được robot actions.
Emergent capabilities
Điều gây ấn tượng nhất của RT-2 là emergent capabilities -- những khả năng chưa từng được train trực tiếp:
- Reasoning về vật thể: "Pick up the object that is NOT a fruit" -> robot chọn chai nước, không chọn táo
- Symbol grounding: "Move to the number 3" -> robot hiểu ký tự trên bàn
- Zero-shot generalization: gặp vật thể chưa từng thấy trong robot data, nhưng đã thấy trong web data
Kết quả (6,000 evaluation trials):
- Seen objects: 73% (baseline RT-1: 75% -- tương đương)
- Unseen objects: 62% (RT-1: 32% -- gấp đôi!)
- Semantic reasoning: 36% (RT-1: 0% -- không thể)
Hạn chế
- Model cực lớn: 12B-55B parameters, cần TPU cluster để train và inference
- Chậm: ~1-3Hz action frequency (robot arm cần 10-50Hz)
- Closed-source: Google không release weights
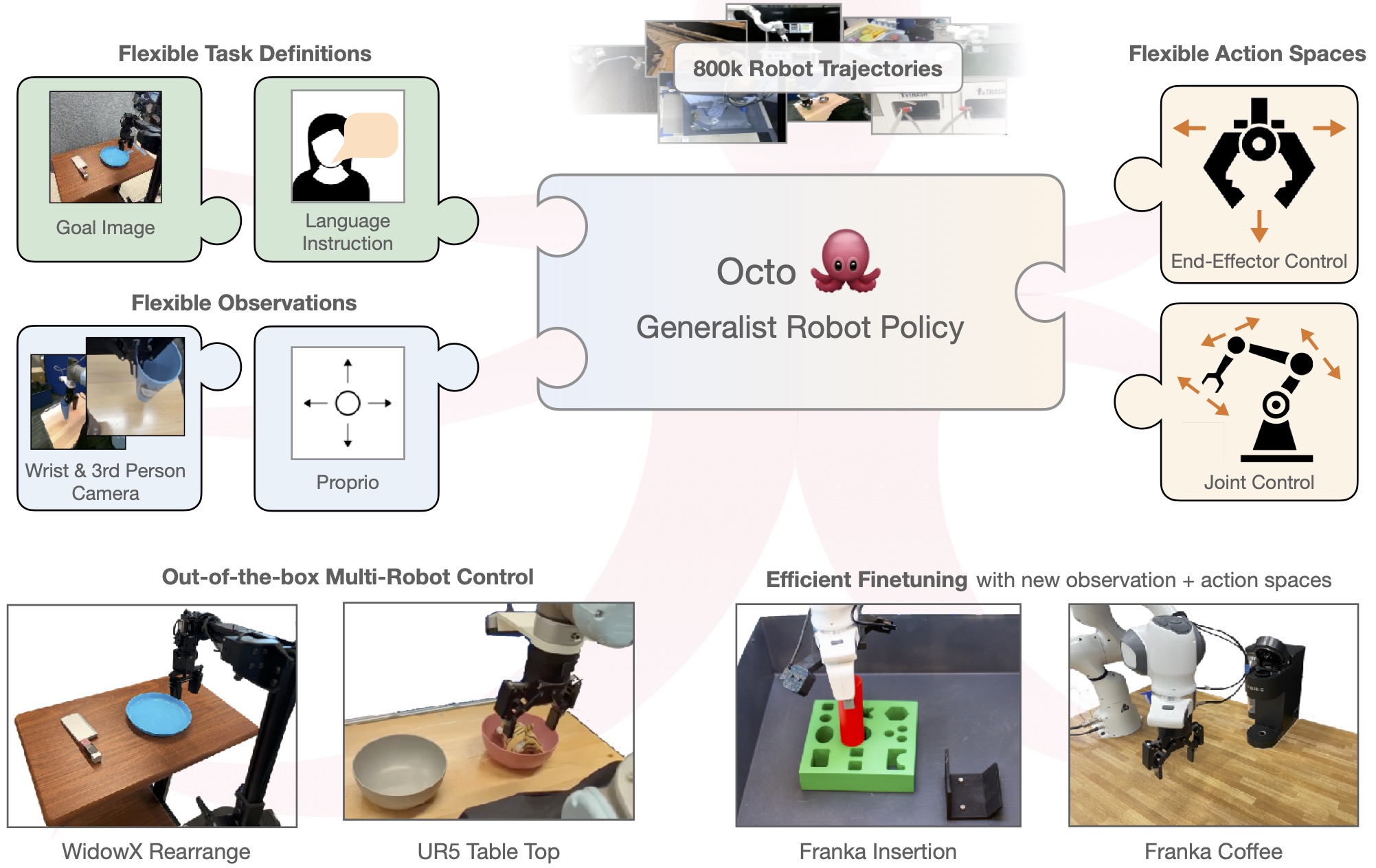
Octo: Open-Source Generalist Policy
Vì sao Octo quan trọng
Octo (Ghosh et al., 2024) từ UC Berkeley giải quyết vấn đề lớn nhất của RT-2: accessibility. Octo là open-source, train trên Open X-Embodiment dataset (800K trajectories từ 22 robot platforms), và có thể fine-tune trên consumer GPU trong vài giờ.
Architecture
Input tokens:
- Task: language instruction OR goal image -> tokenizer
- Observations: images + proprio -> patchify + linear projection
- Readout tokens: learnable tokens để decode actions
Transformer backbone:
- 27M (Octo-Small) hoặc 93M (Octo-Base) parameters
- Block-wise attention: obs tokens attend to task tokens,
readout tokens attend to all
Action head:
- Diffusion head (default) hoặc MSE head
- Output: action chunk [a_t, ..., a_{t+H}]
Fine-tuning workflow
Đây là sức mạnh thật sự của Octo -- fine-tune cho robot của bạn với minimal data:
# Fine-tune Octo cho custom robot (simplified)
from octo.model.octo_model import OctoModel
from octo.data.dataset import make_single_dataset
# 1. Load pre-trained Octo
model = OctoModel.load_pretrained("hf://rail-berkeley/octo-base-1.5")
# 2. Load custom dataset (chỉ cần 50-100 demos)
dataset = make_single_dataset(
dataset_kwargs={
"name": "my_robot_data",
"data_dir": "/path/to/my/data",
},
train=True,
)
# 3. Fine-tune (2-4 giờ trên RTX 4090)
model.finetune(
dataset,
steps=50000,
batch_size=128,
learning_rate=3e-5,
# Freeze vision encoder, chỉ train action head + readout
frozen_keys=["octo_transformer/BlockTransformer_0/*"],
)
# 4. Save và deploy
model.save_pretrained("my_finetuned_octo")
Kết quả fine-tuning
Trên 9 robot platforms, Octo fine-tuned với 50-100 demos:
- Vượt BC from scratch trên 7/9 platforms
- Tương đương task-specific training trên hầu hết tasks
- Fine-tune chỉ mất 2-4 giờ trên 1 GPU (vs days cho RT-2)
pi0: Flow Matching cho General Robot Control
Bước tiến từ Physical Intelligence
pi0 (Black et al., 2024) từ Physical Intelligence là VLA model mới nhất và arguably mạnh nhất. Thay vì autoregressive token generation (như RT-2), pi0 dùng flow matching -- một dạng generalization của diffusion models -- để generate actions.
Architecture
Pre-trained VLM backbone: PaliGemma (3B vision-language model)
Flow matching action expert:
- Separate action generation module
- Trained với flow matching objective
- Output: continuous action trajectories (không cần discretize)
Training:
- Pre-train trên diverse multi-robot dataset (7 robot platforms)
- Fine-tune cho specific tasks với 50-100 demos
Tại sao flow matching?
RT-2 discretize actions thành tokens -> mất precision. pi0 dùng flow matching để generate continuous actions trực tiếp, giữ được độ chính xác cao cho fine-grained manipulation.
So sánh:
- RT-2: output "token 47" -> decode thành dx=0.03 (quantization error)
- pi0: output dx=0.0312 trực tiếp (continuous, chính xác hơn)
Kết quả
pi0 đạt kết quả ấn tượng trên các tasks đòi hỏi dexterous manipulation:
- Laundry folding: 80% success (human-level difficulty)
- Table bussing: 85% success
- Box assembly: 70% success
- Zero-shot transfer giữa các robot platforms khác nhau

So sánh 3 VLA Models
| Tiêu chí | RT-2 | Octo | pi0 |
|---|---|---|---|
| Team | Google DeepMind | UC Berkeley | Physical Intelligence |
| Size | 12B-55B | 27M-93M | ~3B |
| Open-source | Không | Có | Không (weights closed) |
| Training data | Google internal | Open X-Embodiment (800K) | Multi-robot (proprietary) |
| Action generation | Autoregressive tokens | Diffusion head | Flow matching |
| Action precision | Thấp (discrete) | Trung bình | Cao (continuous) |
| Inference speed | 1-3 Hz | 5-10 Hz | 5-15 Hz |
| Fine-tune cost | TPU days | GPU hours | GPU hours |
| Zero-shot | Tốt (web knowledge) | Hạn chế | Tốt |
| Dexterous tasks | Trung bình | Trung bình | Tốt nhất |
| Best for | Semantic reasoning | Open-source research | Production deployment |
Fine-Tuning VLA cho Custom Tasks
Khi nào nên fine-tune VLA?
Nên fine-tune khi:
- Bạn có robot setup mới (camera angles, action space khác)
- Task cần language conditioning (nhiều tasks, instruction-following)
- Muốn leverage pre-trained representations thay vì train từ đầu
- Có 50-100 demos và muốn kết quả nhanh
KHÔNG nên dùng VLA khi:
- Chỉ có 1 task đơn giản (dùng ACT hoặc Diffusion Policy -- đơn giản hơn, nhanh hơn)
- Cần real-time (<5ms inference) -- VLA quá chậm
- Không có GPU (Octo-Base cần ít nhất RTX 3080)
- Task không cần language understanding
Fine-tuning best practices
-
Freeze vision encoder: chỉ train action head và readout tokens. Vision encoder đã học tốt từ pre-training, fine-tune sẽ overfit.
-
Low learning rate: 3e-5 cho Octo, thấp hơn cho pi0. VLA pre-trained weights quý giá, không muốn xóa.
-
Data diversity > quantity: 50 demos đa dạng (initial conditions khác nhau) tốt hơn 200 demos giống nhau.
-
Evaluate thường xuyên: mỗi 5,000 steps, chạy 20 eval episodes. VLA có thể overfit nhanh trên small datasets.
-
Gradient checkpointing: tiết kiệm VRAM, cho phép fine-tune 3B model trên 24GB GPU.
Hạn chế của VLA Models (2026)
1. Tốc độ vẫn là bottleneck
5-15 Hz không đủ cho nhiều manipulation tasks (contact-rich, force-sensitive). Các nhóm như Stanford đang nghiên cứu asynchronous VLA -- high-level VLA output subgoals, low-level policy execute nhanh.
2. Sim-to-real gap
VLA models train trên real data là chính, nhưng real data đắt và chậm thu. Kết hợp sim data vào VLA pre-training vẫn là open challenge.
3. Safety
VLA model là black box -- không có guarantees về hành vi. Trong industry, điều này là deal-breaker cho safety-critical applications. Cần thiết kế safeguards riêng (force limits, workspace bounds, human detection).
4. Data ownership
RT-2 train trên Google proprietary data. pi0 train trên Physical Intelligence data. Chỉ Octo dùng public dataset. Khi fine-tune, data của bạn có thể bị leak thông qua model weights -- cần lưu ý IP issues.
Tương lai: VLA + Manipulation
pi0.5 và beyond
pi0.5 (Physical Intelligence, 2025) mở rộng pi0 với open-world generalization -- robot có thể làm tasks chưa từng thấy trong training data, chỉ cần language instruction. Đây là bước tiến gần nhất đến "general-purpose robot".
Open-source catching up
Octo team đang làm việc trên versions mới với larger datasets và better fine-tuning. Cộng đồng LeRobot của Hugging Face cũng đang integrate VLA models. Khoảng cách giữa open-source và proprietary đang thu hẹp.
VLA + Diffusion Policy
Kết hợp mạnh nhất hiện nay: VLA cho high-level understanding (hiểu task từ language), Diffusion Policy cho low-level execution (smooth, precise trajectories). pi0 đã làm điều này với flow matching, và các labs khác đang follow.
Tiếp theo trong series
- Part 5: Dexterous Manipulation: Thao tác bàn tay robot -- Khi parallel-jaw gripper không đủ
- Part 6: Bimanual Manipulation: Dạy robot dùng 2 tay -- Coordination giữa 2 arms
Bài viết liên quan
- Diffusion Policy thực hành: Từ lý thuyết đến code -- Part 3 series này
- VLA Models: RT-2, Octo, OpenVLA -- Phân tích lý thuyết VLA chi tiết
- Spatial VLA và tương lai robot AI -- 3D-aware VLA models
- Foundation Models cho Robot -- Tổng quan foundation models


