Từ Image Generation đến Robot Control
Diffusion models đã cách mạng image generation (Stable Diffusion, DALL-E 3). Ý tưởng cốt lõi: bắt đầu từ noise, dần dần denoise để tạo ra output có cấu trúc. Nhưng tại sao lại dùng nó cho robot?
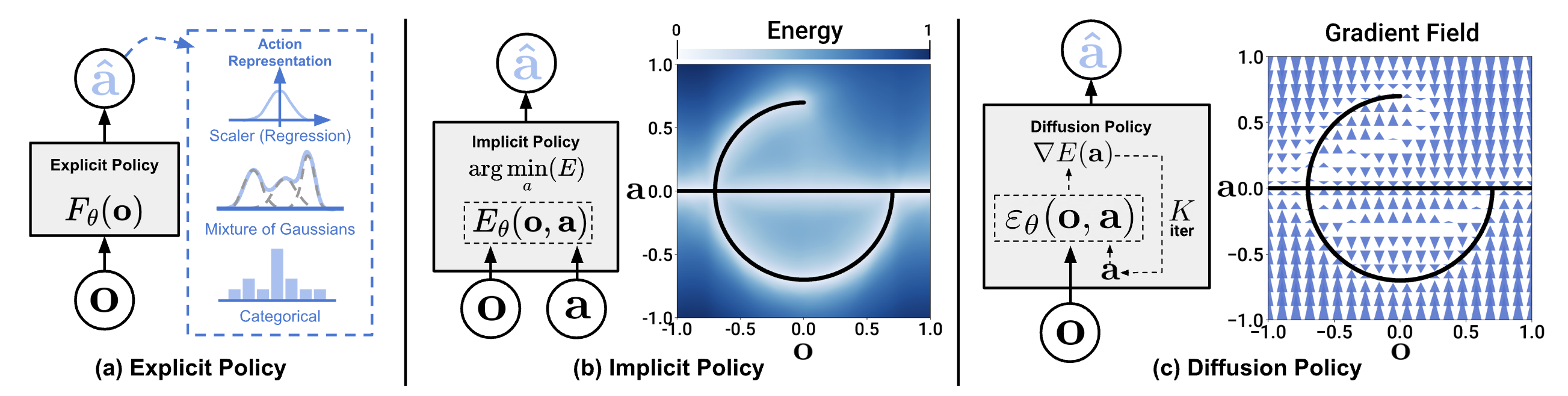
Trong Part 2, mình đã nói về vấn đề multimodal actions -- khi cùng một observation có nhiều cách làm đúng. BC với MSE loss sẽ average các modes, cho ra action "trung bình" vô nghĩa. ACT dùng CVAE để xử lý, nhưng Diffusion Policy (Chi et al., 2023) có cách tiếp cận mạnh hơn: model toàn bộ action distribution bằng diffusion process.
Kết quả? Outperform tất cả baselines trên 12 tasks từ 4 benchmarks, với average improvement 46.9%. Đây là state-of-the-art cho manipulation policy learning.
Nếu bạn chưa đọc bài tổng quan Diffusion Policy, xem Diffusion Policy deep dive trong AI for Robotics series.

DDPM Recap: Denoising Diffusion Probabilistic Models
Forward Process (Thêm noise)
Bắt đầu từ data x_0, thêm Gaussian noise dần dần qua T bước:
q(x_t | x_{t-1}) = N(x_t; sqrt(1-beta_t) * x_{t-1}, beta_t * I)
Sau T bước, x_T ~ N(0, I) -- pure noise. Beta_t là noise schedule, tăng dần từ ~0.0001 đến ~0.02.
Reverse Process (Denoise)
Học một neural network epsilon_theta để predict noise tại mỗi bước:
p_theta(x_{t-1} | x_t) = N(x_{t-1}; mu_theta(x_t, t), sigma_t^2 * I)
Training objective: predict noise đã thêm vào:
# DDPM training step (simplified)
def train_step(model, x_0):
# 1. Sample random timestep
t = torch.randint(0, T, (batch_size,))
# 2. Sample noise
epsilon = torch.randn_like(x_0)
# 3. Add noise theo schedule
x_t = sqrt_alpha_cumprod[t] * x_0 + sqrt_one_minus_alpha_cumprod[t] * epsilon
# 4. Predict noise
epsilon_pred = model(x_t, t)
# 5. MSE loss
loss = F.mse_loss(epsilon_pred, epsilon)
return loss
Từ Images sang Actions
Trong image generation, x_0 là pixel values. Trong Diffusion Policy, x_0 là action sequence [a_t, a_{t+1}, ..., a_{t+H}] với H là prediction horizon. Conditioning là observation (images + joint positions) thay vì text prompt.
Diffusion Policy Architecture
CNN-based (Diffusion Policy - C)
Architecture gốc dùng 1D temporal CNN (giống WaveNet) để process action sequences:
Input: noisy action chunk x_t (B, H, action_dim) + timestep t
Condition: observation features (B, obs_dim) from ResNet18
Architecture:
1. FiLM conditioning: inject obs features vào mỗi conv layer
2. 1D Conv blocks: [Conv1D -> GroupNorm -> Mish -> Conv1D] x N
3. Residual connections
4. Output: predicted noise epsilon (B, H, action_dim)
Ưu điểm: nhanh (inference ~10ms), nhẹ (~5M parameters), dễ train.
Transformer-based (Diffusion Policy - T)
Thay CNN bằng Transformer decoder:
Input tokens:
- Noisy action tokens: x_t -> Linear -> (H, d_model)
- Observation tokens: obs -> ResNet18 -> (N_obs, d_model)
- Timestep token: t -> sinusoidal embedding -> (1, d_model)
Transformer Decoder:
- Self-attention trên action tokens
- Cross-attention từ action tokens đến observation tokens
- L layers, d_model=256, 4 heads
Output: predicted noise epsilon (H, action_dim)
Ưu điểm: capture long-range dependencies tốt hơn, scale tốt với data.
CNN vs Transformer: Khi nào dùng gì?
| Tiêu chí | Diffusion Policy - C | Diffusion Policy - T |
|---|---|---|
| Tốc độ inference | ~10ms | ~50ms |
| Parameters | ~5M | ~20M |
| Data efficiency | Tốt hơn với ít data (<100 demos) | Cần nhiều data hơn (>200 demos) |
| Long-horizon | Kém hơn | Tốt hơn |
| Training time | Nhanh (2-4h trên 1 GPU) | Chậm hơn (6-12h) |
| Recommendation | Default choice | Khi task phức tạp, đủ data |
Lời khuyên: bắt đầu với CNN variant. Chỉ chuyển sang Transformer khi CNN plateau và bạn có đủ data.
Diffusion Policy trong LeRobot: Hands-on
Setup
# Cài LeRobot
pip install lerobot
# Kiểm tra GPU
python -c "import torch; print(torch.cuda.is_available())"
Train Diffusion Policy trên PushT (2D benchmark)
PushT là benchmark kinh điển: robot đẩy chữ T vào target pose. Đơn giản nhưng demonstrate được sức mạnh của Diffusion Policy với multimodal actions.
# Download PushT dataset
python -m lerobot.scripts.download_dataset \
--repo-id lerobot/pusht
# Train Diffusion Policy (CNN variant)
python -m lerobot.scripts.train \
--policy.type=diffusion \
--env.type=pusht \
--dataset.repo_id=lerobot/pusht \
--training.num_epochs=5000 \
--training.batch_size=64 \
--policy.n_action_steps=8 \
--policy.n_obs_steps=2 \
--policy.num_inference_steps=100
Các hyperparameters quan trọng
# Config giải thích
policy:
n_obs_steps: 2 # Số observation frames làm input (2 = current + previous)
n_action_steps: 8 # Số actions execute trước khi re-plan (action chunking)
horizon: 16 # Prediction horizon (predict 16 actions, execute 8)
num_inference_steps: 100 # Số DDPM denoising steps (nhiều = chính xác hơn, chậm hơn)
# Noise schedule
noise_scheduler:
type: "ddpm" # Hoặc "ddim" (nhanh hơn, ít steps hơn)
beta_start: 0.0001
beta_end: 0.02
beta_schedule: "squaredcos_cap_v2" # Cosine schedule (tốt hơn linear)
DDIM: Tăng tốc inference
DDPM cần 100 denoising steps -> chậm cho real-time robot control. DDIM (Denoising Diffusion Implicit Models) giảm xuống còn 10-20 steps mà giữ gần như nguyên chất lượng:
# Đổi từ DDPM sang DDIM trong LeRobot config
policy:
noise_scheduler:
type: "ddim"
num_inference_steps: 10 # Giảm từ 100 xuống 10
Trên thực tế, DDIM với 10 steps cho inference ~15ms -- đủ nhanh cho 50Hz control loop.

Benchmark Results
PushT (2D)
| Method | Success Rate |
|---|---|
| BC (MLP) | 58.7% |
| BC (Transformer) | 63.2% |
| IBC (Implicit BC) | 62.4% |
| BET (BeT) | 65.8% |
| Diffusion Policy - C | 88.7% |
| Diffusion Policy - T | 85.3% |
RobomiMic (Simulated Manipulation)
| Task | BC-RNN | IBC | Diffusion-C | Diffusion-T |
|---|---|---|---|---|
| Lift | 100% | 96% | 100% | 100% |
| Can | 92% | 84% | 96% | 95% |
| Square | 82% | 68% | 92% | 92% |
| Transport | 46% | 32% | 78% | 74% |
| Tool Hang | 18% | 12% | 56% | 52% |
Diffusion Policy vượt trội hoàn toàn, đặc biệt trên tasks khó (Transport, Tool Hang) -- chính là nơi multimodal actions quan trọng.
Tại sao Diffusion Policy mạnh?
1. Xử lý multimodal actions tự nhiên
Khi có nhiều cách làm đúng (đẩy T từ trái hoặc từ phải), BC average hai cách -> action vô nghĩa. Diffusion model học toàn bộ distribution, khi sample sẽ chọn một mode cụ thể và thực hiện nhất quán.
2. Expressiveness cao
Diffusion process có thể model bất kỳ distribution nào, không bị giới hạn bởi parametric assumptions (như Gaussian trong VAE). Điều này quan trọng cho complex manipulation trajectories.
3. Training stability
Không có mode collapse như GAN, không có posterior collapse như VAE. Training objective (predict noise) đơn giản và ổn định.
4. Action chunking built-in
Predict cả chunk actions một lúc, giảm compounding error tương tự ACT nhưng với phương pháp generate mạnh hơn.
Tips thực tế
Training
- Cosine noise schedule tốt hơn linear cho action sequences
- EMA (Exponential Moving Average) của model weights: bắt buộc, dùng decay=0.995
- Gradient clipping: max_norm=1.0, tránh explosion khi train
- Learning rate: 1e-4 với AdamW, cosine decay
Inference trên robot thật
- Dùng DDIM với 10 steps để đạt real-time
- Temporal ensembling (như ACT): average các overlapping chunks
- Action clipping: giới hạn action trong safe range trước khi gửi xuống robot
- Latency compensation: tính toán trước 1-2 steps để bù latency
Debug
- Visualize denoising process: plot action trajectory tại mỗi denoising step -- nếu không converge, tăng num_inference_steps
- Check action distribution: histogram actions từ dataset vs predicted -- nên match
- Overfit trên 1 episode trước: nếu không overfit được, có bug trong code
Diffusion Policy vs ACT: Chọn gì?
| Tiêu chí | ACT | Diffusion Policy |
|---|---|---|
| Multimodal | CVAE (limited modes) | Full distribution |
| Speed | Nhanh (~5ms) | Chậm hơn (~15ms DDIM) |
| Data efficiency | Rất tốt (50 demos) | Tốt (50-100 demos) |
| Long-horizon | Tốt | Tốt hơn |
| Implementation | Phức tạp (CVAE) | Trung bình |
| Best for | Bimanual, ít data | Complex tasks, nhiều data |
Chọn ACT khi: ít data (<50 demos), cần inference nhanh, bimanual tasks. Chọn Diffusion Policy khi: task phức tạp, multimodal, đủ data, và 50Hz là đủ.
Tiếp theo trong series
- Part 4: VLA cho Manipulation: RT-2, Octo, pi0 trong thực tế -- Foundation models cho manipulation
- Part 5: Dexterous Manipulation: Thao tác bàn tay robot -- Khi 2 ngón tay không đủ
Bài viết liên quan
- Imitation Learning cho Manipulation: BC, DAgger, ACT -- Part 2 series này
- Diffusion Policy deep dive -- Phân tích lý thuyết chi tiết hơn
- VLA Models: RT-2, Octo, OpenVLA -- Foundation models dùng Diffusion Policy
- Xây dựng hệ thống manipulation với LeRobot -- Deploy Diffusion Policy lên robot thật


