Tại sao Imitation Learning cho Manipulation?
Trong Part 1 của series này, mình đã nói về grasping -- bài toán nhặt một vật thể. Nhưng manipulation thực tế phức tạp hơn nhiều: gắp đồ ăn cho vào hộp, xếp bolt vào lỗ, mở nắp chai... Các task này có long-horizon, nhiều bước, và khó code bằng tay (hard-coding).
Imitation Learning (IL) giải quyết bài toán này bằng cách: thay vì code từng bước, hãy cho robot xem người làm và học từ đó. Con người teleoperate robot làm task 50-100 lần, thu data, rồi train policy bằng supervised learning.
Nghe đơn giản, nhưng các vấn đề như distribution shift, multimodal actions, và compounding errors khiến IL không dễ như tưởng tượng. Bài này sẽ đi từ cơ bản (Behavioral Cloning) đến state-of-the-art (ACT), với code và tips thực tế.
Nếu bạn chưa đọc bài tổng quan về IL, xem Imitation Learning 101 trong AI for Robotics series.

Data Collection: Teleoperation
Vì sao data là tất cả
Trong IL, chất lượng data quyết định 80% thành công. Một policy train trên 50 demonstrations tốt sẽ outperform policy train trên 500 demonstrations khó. "Tốt" ở đây nghĩa là:
- Nhất quán (consistent): cùng một task, người demo làm tương tự nhau giữa các episodes
- Đa dạng vừa đủ (diverse enough): cover các initial conditions khác nhau (vị trí vật thể, góc đặt...)
- Mượt (smooth): không giật, không pause giữa, tốc độ đều
Các phương pháp teleoperation
| Phương pháp | Chi phí | Chất lượng data | Độ khó setup |
|---|---|---|---|
| Keyboard/joystick | Thấp | Thấp (giật, chậm) | Dễ |
| VR controller (Quest 3) | ~500 USD | Trung bình | Trung bình |
| Leader-follower (ALOHA-style) | ~5,000-32,000 USD | Cao (tự nhiên nhất) | Khó |
| Kinesthetic teaching | 0 (chỉ cần cobot) | Cao | Dễ (nhưng mệt) |
Leader-follower là gold standard hiện nay: bạn điều khiển một robot arm (leader), robot thứ hai (follower) copy chính xác chuyển động. Đây là cách ALOHA và Mobile ALOHA thu data -- tự nhiên, chính xác, và scale được.
Nếu bạn không có ALOHA hardware, LeRobot SO-100 của Hugging Face (~300 USD) hỗ trợ leader-follower với 2 robot arms giá rẻ.
Data format
Một demonstration episode gồm:
# Mỗi timestep t trong episode
{
"observation": {
"images": {
"cam_high": np.array([480, 640, 3]), # RGB top camera
"cam_wrist": np.array([480, 640, 3]), # RGB wrist camera
},
"qpos": np.array([6]), # joint positions (6-DoF arm)
"qvel": np.array([6]), # joint velocities
"gripper": float, # gripper opening (0-1)
},
"action": np.array([7]), # target joint positions + gripper
}
Lưu ý: action space có thể là joint positions, joint velocities, hoặc end-effector pose (cartesian). Joint position là phổ biến nhất vì ổn định và dễ reproduce.
Behavioral Cloning (BC): Supervised Learning cơ bản
Ý tưởng
BC là phương pháp đơn giản nhất: coi IL như supervised learning -- input là observation, output là action, loss là MSE giữa predicted action và expert action.
import torch
import torch.nn as nn
class BCPolicy(nn.Module):
def __init__(self, obs_dim, action_dim, hidden=256):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, hidden),
nn.ReLU(),
nn.Linear(hidden, action_dim),
)
def forward(self, obs):
return self.net(obs)
# Training loop
policy = BCPolicy(obs_dim=18, action_dim=7)
optimizer = torch.optim.Adam(policy.parameters(), lr=1e-4)
for epoch in range(100):
for obs, action in dataloader:
pred_action = policy(obs)
loss = nn.MSELoss()(pred_action, action)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Vấn đề: Distribution Shift
BC có một vấn đề nghiêm trọng gọi là distribution shift (hoặc compounding error):
- Khi train, policy thấy states từ expert trajectory (on-policy data)
- Khi deploy, policy dự đoán action hơi sai -> robot đi vào state chưa từng thấy trong training data
- Tại state lạ này, policy dự đoán càng sai hơn -> sai lệch càng lớn theo thời gian
- Sau vài bước, robot ở trạng thái hoàn toàn khác expert -> task thất bại
Lỗi nhỏ ở bước 1 tích lũy thành lỗi lớn ở bước T. Với task dài 100 bước, chỉ cần error 1% mỗi bước, xác suất thành công chỉ còn ~36%.
DAgger: Fix Distribution Shift
Ý tưởng cốt lõi
DAgger (Dataset Aggregation, Ross et al., 2011) fix distribution shift bằng cách thu thêm data tại những states mà policy gặp khi deploy:
- Train policy ban đầu trên expert data (như BC)
- Chạy policy trên robot thật -> robot đi vào states mới
- Expert label actions cho những states mới này
- Gộp data mới vào dataset, re-train policy
- Lặp lại từ bước 2
Vòng lặp DAgger:
D0 = expert demonstrations
pi_0 = BC(D0)
for i = 1, 2, ..., N:
Chạy pi_{i-1} trên robot -> thu states S_i
Expert label actions cho S_i -> data mới D_i
D = D0 union D1 union ... union D_i
pi_i = BC(D)
Hạn chế thực tế
- Cần expert có mặt liên tục để label -- mất thời gian và công sức
- Robot chạy policy xấu có thể nguy hiểm (va chạm, làm hỏng đồ)
- Mỗi iteration cần deploy trên robot thật -> chậm
Các biến thể như HG-DAgger (arXiv:1810.02890) và LazyDAgger giảm số lần cần expert intervention, nhưng vẫn cần người trong loop.

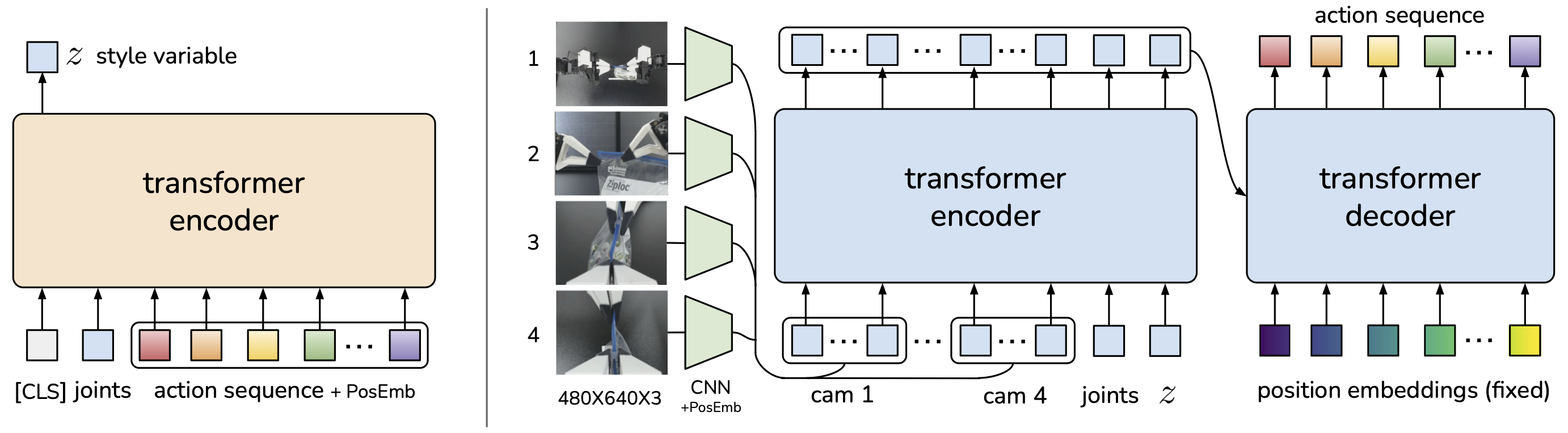
ACT: Action Chunking with Transformers
Đột phá của ACT
ACT (Zhao et al., 2023) từ Stanford là bước ngoặt lớn cho IL trong manipulation. Hai ý tưởng chính:
1. Action Chunking: thay vì predict 1 action tại mỗi timestep, predict một chuỗi k actions (vd: k=100, tương ứng ~2 giây). Điều này giảm effective horizon từ T xuống T/k, giảm compounding error tương ứng.
2. CVAE (Conditional Variational Autoencoder): xử lý multimodal actions -- khi cùng một observation có thể có nhiều cách làm đúng (vd: cầm cốc bằng tay trái hoặc tay phải). CVAE encode style variable z để capture sự đa dạng này.
Architecture
Input:
- Images: [cam_high, cam_wrist] -> ResNet18 -> visual tokens
- Joint positions: qpos -> MLP -> proprioception token
- Style variable: z ~ N(0, I) (during inference)
Encoder (training only):
- [action_sequence, obs_tokens] -> Transformer Encoder -> z (mean, var)
Decoder:
- [z, obs_tokens] -> Transformer Decoder -> action_chunk [a_t, a_{t+1}, ..., a_{t+k}]
Temporal Ensembling
Khi thực hiện action chunking, tại mỗi timestep t, robot có nhiều predicted actions từ các chunks trước đó (chunk bắt đầu từ t-1, t-2, ...). ACT dùng temporal ensembling -- lấy weighted average của các predictions, với exponential weight giảm dần cho predictions cũ hơn:
# Temporal ensembling
def temporal_ensemble(all_predictions, current_step, decay=0.01):
"""
all_predictions: dict {start_step: action_chunk}
Trả về action cho current_step
"""
weights = []
actions = []
for start_step, chunk in all_predictions.items():
idx = current_step - start_step
if 0 <= idx < len(chunk):
w = np.exp(-decay * idx)
weights.append(w)
actions.append(chunk[idx])
weights = np.array(weights) / sum(weights)
return sum(w * a for w, a in zip(weights, actions))
Kết quả
ACT đạt 80-90% success rate trên 6 manipulation tasks khó (mở nắp chai, xếp battery, gắp đồ ăn) với chỉ 10 phút demonstrations (~50 episodes). Đây là kết quả ấn tượng so với BC thuần túy (~30-50% trên cùng tasks).
So sánh BC vs DAgger vs ACT
| Tiêu chí | BC | DAgger | ACT |
|---|---|---|---|
| Distribution shift | Nghiêm trọng | Giảm (nhưng cần expert) | Giảm (action chunking) |
| Multimodal actions | Không xử lý | Không xử lý | Có (CVAE) |
| Số demos cần | 100-500+ | 50-100 + iterations | 50 (10 phút) |
| Cần expert trong loop | Không | Có (mỗi iteration) | Không |
| Architecture | MLP/CNN | MLP/CNN | Transformer + CVAE |
| Long-horizon tasks | Kém | Khá | Tốt |
| Implementation | Dễ | Trung bình | Trung bình |
| Real robot risk | Thấp | Cao (chạy policy xấu) | Thấp |
Hands-on: Train ACT với LeRobot
LeRobot của Hugging Face tích hợp sẵn ACT. Đây là cách train nhanh nhất:
# 1. Cài LeRobot
pip install lerobot
# 2. Download sample dataset (ALOHA sim transfer cube)
python -m lerobot.scripts.download_dataset \
--repo-id lerobot/aloha_sim_transfer_cube_human
# 3. Train ACT policy
python -m lerobot.scripts.train \
--policy.type=act \
--env.type=aloha \
--env.task=AlohaTransferCube-v0 \
--dataset.repo_id=lerobot/aloha_sim_transfer_cube_human \
--training.num_epochs=2000 \
--training.batch_size=8
# 4. Evaluate
python -m lerobot.scripts.eval \
--policy.path=outputs/train/act_aloha_transfer_cube/checkpoints/last/pretrained_model \
--env.type=aloha \
--env.task=AlohaTransferCube-v0 \
--eval.n_episodes=50
Tips thu data tốt
- Làm chậm, đều tay: teleoperate ở 50-70% tốc độ tối đa, tránh giật
- Đặt vật thể ở nhiều vị trí: cover variation trong initial conditions
- 50 demos là đủ cho một task đơn giản với ACT
- Kiểm tra data trước khi train: replay từng episode, loại những cái xấu
- Camera angle quan trọng: đặt camera để nhìn rõ contact area
Tiếp theo trong series
Đây là Part 2 của series Robot Manipulation Masterclass. Tiếp theo:
- Part 3: Diffusion Policy thực hành: Từ lý thuyết đến code -- Khi ACT chưa đủ, Diffusion Policy là bước tiếp theo
- Part 4: VLA cho Manipulation: RT-2, Octo, pi0 -- Foundation models cho manipulation
Bài viết liên quan
- Robot Grasping 101: Analytical đến learning-based -- Part 1 series này
- Imitation Learning 101: BC, IRL, và những gì bạn cần biết -- Tổng quan IL rộng hơn
- ACT: Action Chunking with Transformers deep dive -- Phân tích chi tiết architecture ACT
- Diffusion Policy thực hành -- Part 3 series này
- Xây dựng hệ thống manipulation với LeRobot -- End-to-end deployment


