Tại sao Single-Step Prediction thất bại?
Ở Phần 2, mình đã giới thiệu Behavioral Cloning — train policy predict 1 action cho mỗi observation. Phương pháp đơn giản này hoạt động cho nhiều tasks, nhưng thất bại thảm hại với manipulation tasks phức tạp. Tại sao?
Vấn đề 1: Temporal Correlation
Robot actions không độc lập — action ở timestep t phụ thuộc mạnh vào actions ở t-1, t-2, t-3... Khi predict từng action riêng lẻ, policy mất đi temporal coherence:
Single-step prediction:
t=0: di chuyển trái (đúng)
t=1: di chuyển phải (noise → sai hướng)
t=2: di chuyển trái (sửa lại)
→ Robot rung lắc, không smooth
Action chunking:
t=0: predict [trái, trái, trái, trái] (cả chunk)
t=4: predict [xuống, xuống, xuống, xuống]
→ Robot di chuyển mượt mà
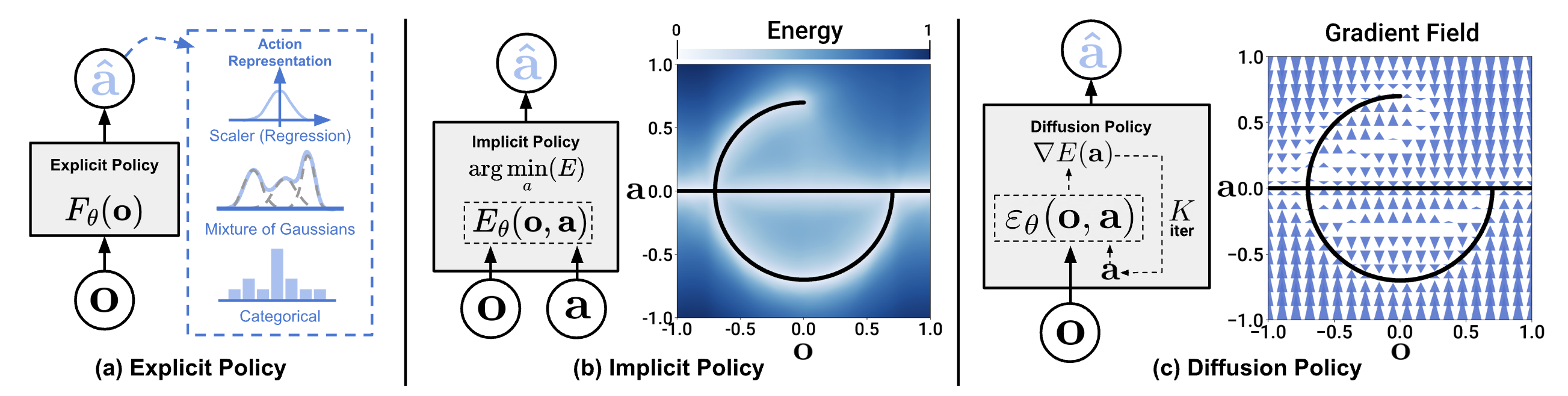
Vấn đề 2: Multimodality
Cùng 1 observation, expert có thể thực hiện nhiều cách khác nhau. Ví dụ: gắp vật từ trái hoặc từ phải đều được. Single-step BC với MSE loss sẽ average 2 modes → tay robot đâm thẳng vào giữa (không đúng mode nào).
Action Chunking with Transformers (ACT) giải quyết cả 2 vấn đề. Paper gốc: Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (Zhao et al., RSS 2023).

ACT Architecture: Tổng quan
ACT gồm 2 thành phần chính:
Training time:
Observations (images + proprio) ──┐
Action sequence (ground truth) ───┤
▼
CVAE Encoder
│
style variable z
│
▼
Observations ─────────────→ Transformer Decoder ──→ Action chunk (k actions)
▲
z (style conditioning)
Inference time:
Observations ─────────────→ Transformer Decoder ──→ Action chunk
▲
z = 0 (mean of prior)
Tại sao kiến trúc này?
- Action chunking: Predict k actions cùng lúc (thường k=100) thay vì 1 → giải quyết temporal correlation
- CVAE encoder: Capture multimodality — style variable z encode "cách làm" (trái vs phải)
- Transformer decoder: Powerful sequence model, attention giữa observations và action tokens
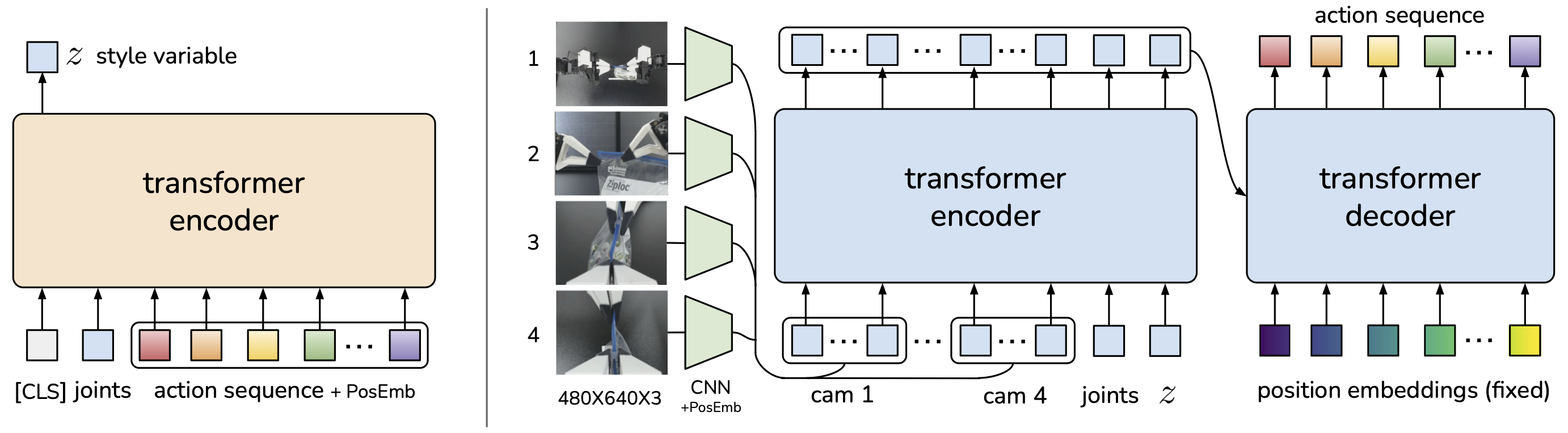
CVAE Encoder: Capture Style
CVAE (Conditional Variational Autoencoder) là thành phần xử lý multimodality. Ý tưởng: có nhiều cách thực hiện 1 task, mỗi cách là 1 "style". CVAE encode style vào latent variable z.
Training phase
Input:
- Observation: camera images + joint positions
- Action sequence: ground truth actions (k steps)
CVAE Encoder:
1. Concatenate [CLS token, action tokens] (k+1 tokens)
2. Cross-attend với observation features
3. CLS token output → MLP → μ, σ (Gaussian parameters)
4. Sample z ~ N(μ, σ²)
Loss:
L = L_reconstruction + β × KL(q(z|o,a) || p(z))
L_reconstruction = ||predicted_actions - ground_truth_actions||²
KL regularization: ép z distribution gần N(0, I)
β = 10 (trong paper gốc, khá lớn → ép z meaningful)
Inference phase
Khi deploy, không có ground truth actions → không chạy encoder. Thay vào đó, dùng z = 0 (mean của prior distribution N(0, I)). Điều này hoạt động vì:
- KL regularization ép posterior gần prior
- z = 0 cho "average style" — hành vi phổ biến nhất trong demos
- Nếu muốn diverse behavior, có thể sample z ~ N(0, I)
Tại sao không chỉ dùng Gaussian Mixture Model?
GMM cũng capture multimodality, nhưng:
- Phải chọn trước số modes (K) — không biết có bao nhiêu cách
- Không scale tốt với action dimension cao (7D × 100 steps = 700D)
- CVAE học continuous latent space — smooth interpolation giữa styles
Transformer Decoder: Sinh Action Chunk
Transformer decoder nhận observation features và style variable z, sinh ra k actions liên tiếp.
Chi tiết kiến trúc
# Simplified ACT decoder architecture
class ACTDecoder(nn.Module):
def __init__(
self,
action_dim=14, # 7 per arm × 2 arms (bimanual)
chunk_size=100, # Predict 100 future actions
hidden_dim=512,
n_heads=8,
n_layers=4,
latent_dim=32, # CVAE latent dimension
):
# Observation processing
self.image_encoder = ResNet18() # Visual features
self.proprio_proj = nn.Linear(14, hidden_dim)
# Style conditioning
self.style_proj = nn.Linear(latent_dim, hidden_dim)
# Learnable action queries (giống DETR object queries)
self.action_queries = nn.Embedding(chunk_size, hidden_dim)
# Transformer decoder layers
self.decoder = nn.TransformerDecoder(
nn.TransformerDecoderLayer(
d_model=hidden_dim,
nhead=n_heads,
dim_feedforward=2048,
batch_first=True,
),
num_layers=n_layers,
)
# Action prediction head
self.action_head = nn.Linear(hidden_dim, action_dim)
Forward pass
1. Process observations:
- Images → ResNet18 → flatten → visual tokens (49 tokens, mỗi token = 1 patch)
- Joint positions → linear projection → 1 proprio token
- Style z → linear projection → 1 style token
2. Memory = [visual_tokens, proprio_token, style_token] (51 tokens)
3. Queries = learnable action_queries (100 tokens)
4. Transformer Decoder:
- Self-attention: action queries attend lẫn nhau
- Cross-attention: action queries attend vào memory (observations + style)
- 4 layers
5. Output: 100 action predictions, mỗi cái là 14D vector
(7D per arm: x, y, z, rx, ry, rz, gripper)
Điểm quan trọng: action queries là learnable — model tự học position encoding cho từng timestep trong chunk. Query thứ 0 "biết" nó cần predict action ngay lập tức, query thứ 99 "biết" nó predict action xa trong tương lai.
Temporal Ensembling: Smooth Execution
Action chunking giải quyết temporal correlation, nhưng tạo ra vấn đề mới: chunk transitions. Khi kết thúc 1 chunk và bắt đầu chunk mới, có thể bị "giật" (discontinuity).
Cách hoạt động
Thay vì chạy hết 1 chunk rồi predict chunk mới, ACT predict chunk mới mỗi timestep và dùng exponential weighting để blend:
Timestep t:
Chunk predict ở t-2: [_, _, a_t^(t-2), a_{t+1}^(t-2), ...]
Chunk predict ở t-1: [_, a_t^(t-1), a_{t+1}^(t-1), ...]
Chunk predict ở t: [a_t^(t), a_{t+1}^(t), ...]
Action thực thi = weighted_average(a_t^(t-2), a_t^(t-1), a_t^(t))
Weights: w_i = exp(-m × i) với m > 0
→ Chunk mới nhất có weight cao nhất
→ Chunks cũ giảm dần ảnh hưởng
Tại sao exponential weighting?
- Chunk mới nhất có observation mới nhất → thông tin chính xác nhất → weight cao
- Chunks cũ dựa trên observation cũ → less relevant nhưng đã committed → giữ 1 phần để smooth
- m (temporal weight) là hyperparameter: m lớn = reactive (chỉ dùng chunk mới), m nhỏ = smooth (blend nhiều chunks)
Trong paper gốc, temporal ensembling tăng success rate 5-10% cho các tasks khó — đặc biệt quan trọng cho contact-rich manipulation.

Training Pipeline
Data format (ALOHA)
ACT được thiết kế cho hệ thống ALOHA — 2 robot arms, mỗi arm 6-DoF + 1 gripper:
# Mỗi episode trong dataset
episode = {
"observations": {
"images": {
"cam_high": np.array((T, 480, 640, 3)), # Camera trên cao
"cam_left_wrist": np.array((T, 480, 640, 3)), # Camera tay trái
"cam_right_wrist": np.array((T, 480, 640, 3)), # Camera tay phải
},
"qpos": np.array((T, 14)), # Joint positions: 7 left + 7 right
"qvel": np.array((T, 14)), # Joint velocities
},
"actions": np.array((T, 14)), # Target joint positions
}
Training configuration
# Hyperparameters từ paper
config = {
"chunk_size": 100, # Predict 100 future actions
"hidden_dim": 512,
"n_heads": 8,
"n_encoder_layers": 4, # CVAE encoder
"n_decoder_layers": 7, # Transformer decoder
"latent_dim": 32, # CVAE latent dimension
"kl_weight": 10, # β cho KL loss
"lr": 1e-5,
"batch_size": 8,
"epochs": 2000,
"backbone": "resnet18",
"temporal_agg": True, # Temporal ensembling
"temporal_agg_m": 0.01, # Exponential decay factor
}
Loss function
def compute_loss(model, batch, kl_weight=10):
"""ACT training loss = reconstruction + KL divergence."""
observations = batch["observations"]
gt_actions = batch["actions"] # (B, chunk_size, action_dim)
# Forward pass — encoder nhận cả observations và gt_actions
pred_actions, mu, logvar = model(observations, gt_actions)
# Reconstruction loss: L1 thay vì MSE (robust hơn với outliers)
l1_loss = F.l1_loss(pred_actions, gt_actions)
# KL divergence: ép posterior gần prior N(0, I)
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
kl_loss = kl_loss / (mu.shape[0] * mu.shape[1]) # normalize
total_loss = l1_loss + kl_weight * kl_loss
return total_loss, {
"l1_loss": l1_loss.item(),
"kl_loss": kl_loss.item(),
"total_loss": total_loss.item(),
}
Thực hành: Train ACT với LeRobot
LeRobot (Hugging Face) là framework open-source tốt nhất hiện nay để train và deploy ACT. Nó wrap toàn bộ pipeline thành CLI commands đơn giản.
Cài đặt
pip install lerobot
# Hoặc từ source cho latest features
git clone https://github.com/huggingface/lerobot.git
cd lerobot && pip install -e ".[all]"
Train ACT trên ALOHA dataset
# Download dataset và train ACT — 1 command duy nhất
lerobot-train \
--policy.type=act \
--dataset.repo_id=lerobot/aloha_sim_insertion_human \
--training.num_epochs=2000 \
--training.batch_size=8 \
--policy.chunk_size=100 \
--policy.n_action_steps=100 \
--policy.kl_weight=10 \
--output_dir=outputs/act_insertion
Train trên custom dataset
"""
Train ACT trên dataset tự thu thập với LeRobot.
Yêu cầu: pip install lerobot torch
"""
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
from lerobot.common.policies.act.modeling_act import ACTPolicy
from lerobot.common.policies.act.configuration_act import ACTConfig
# 1. Load dataset (format LeRobot trên HuggingFace Hub)
dataset = LeRobotDataset(
repo_id="your-username/your-robot-dataset",
split="train",
)
print(f"Dataset: {len(dataset)} frames, {dataset.num_episodes} episodes")
# 2. Configure ACT policy
config = ACTConfig(
input_shapes={
"observation.images.top": [3, 480, 640],
"observation.state": [14], # Joint positions
},
output_shapes={
"action": [14], # Target joint positions
},
input_normalization_modes={
"observation.images.top": "mean_std",
"observation.state": "mean_std",
},
output_normalization_modes={
"action": "mean_std",
},
chunk_size=100,
n_action_steps=100,
dim_model=512,
n_heads=8,
n_encoder_layers=4,
n_decoder_layers=7,
dim_feedforward=2048,
latent_dim=32,
use_vae=True, # Bật CVAE encoder
kl_weight=10.0,
temporal_ensemble_coeff=0.01, # Temporal ensembling
)
# 3. Create policy
policy = ACTPolicy(config=config, dataset_stats=dataset.stats)
# 4. Training loop
import torch
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
policy = policy.to(device)
optimizer = torch.optim.AdamW(policy.parameters(), lr=1e-5, weight_decay=1e-4)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=4)
for epoch in range(2000):
epoch_loss = 0
for batch in dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
output = policy.forward(batch)
loss = output["loss"]
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(policy.parameters(), 10.0)
optimizer.step()
epoch_loss += loss.item()
if epoch % 100 == 0:
avg_loss = epoch_loss / len(dataloader)
print(f"Epoch {epoch}: loss={avg_loss:.6f}")
# 5. Save policy
policy.save_pretrained("outputs/act_custom/")
print("Training complete!")
Evaluate và deploy
"""Chạy ACT policy trên robot hoặc simulation."""
from lerobot.common.policies.act.modeling_act import ACTPolicy
# Load trained policy
policy = ACTPolicy.from_pretrained("outputs/act_custom/")
policy.eval()
# Inference loop với temporal ensembling
action_queue = [] # Buffer cho temporal ensembling
for step in range(max_steps):
observation = robot.get_observation()
# Policy predict chunk of actions
with torch.no_grad():
action_chunk = policy.select_action(observation)
# action_chunk shape: (chunk_size, action_dim)
# Temporal ensembling
action_queue.append(action_chunk)
if len(action_queue) > max_queue_len:
action_queue.pop(0)
# Weighted average
weights = [
np.exp(-0.01 * i)
for i in range(len(action_queue) - 1, -1, -1)
]
weights = np.array(weights) / sum(weights)
action = sum(w * q[len(action_queue) - 1 - i]
for i, (w, q) in enumerate(zip(weights, action_queue)))
robot.execute_action(action)
Kết quả và so sánh
ACT đạt kết quả ấn tượng trên ALOHA bimanual tasks — các task mà BC thông thường gần như không thể solve:
| Task | BC (single-step) | ACT (no temporal agg) | ACT (full) |
|---|---|---|---|
| Slot insertion | 10% | 80% | 96% |
| Transfer cube | 2% | 72% | 90% |
| Thread zip tie | 0% | 40% | 52% |
| Open cup | 0% | 55% | 68% |
Lưu ý:
- BC single-step gần như hoàn toàn thất bại cho bimanual tasks — distribution shift quá nặng
- Action chunking alone (không temporal ensembling) đã tăng performance đáng kể
- Temporal ensembling thêm 5-16% success rate tùy task
So sánh với methods khác
| Method | Demos cần | Train time | Bimanual | Fine-grained |
|---|---|---|---|---|
| BC (MLP) | 50 | 10 phút | Kém | Kém |
| BC (Transformer) | 50 | 30 phút | Trung bình | Trung bình |
| Diffusion Policy | 50 | 2 giờ | Tốt | Tốt |
| ACT | 50 | 1 giờ | Rất tốt | Rất tốt |
| ACT + Diffusion | 50 | 3 giờ | Rất tốt | Rất tốt |
ACT cân bằng tốt giữa performance và training cost. Diffusion Policy có thể tốt hơn cho một số tasks, nhưng train lâu hơn và inference chậm hơn.
Key Takeaways
- Action chunking giải quyết temporal correlation — predict k actions cùng lúc giữ coherence
- CVAE encoder capture multimodality — style variable z encode "cách làm"
- Temporal ensembling cho smooth execution — blend nhiều chunks bằng exponential weighting
- 50 demonstrations đủ cho nhiều manipulation tasks — không cần hàng nghìn demos
- LeRobot là cách nhanh nhất để bắt đầu — download dataset, train, deploy trong 1 ngày
Bước tiếp theo
ACT là state-of-the-art cho imitation learning từ demonstrations. Nhưng nếu bạn muốn robot hiểu language instructions ("pick up the red cup"), bạn cần foundation models — xem bài Foundation Models cho Robot: RT-2, Octo, OpenVLA thực tế để hiểu cách kết hợp vision, language, và action trong 1 model.
Bài viết liên quan
- RL cho Robotics: PPO, SAC và cách chọn algorithm — Phần 1: Nền tảng RL cho robot
- Imitation Learning: BC, DAgger và DAPG cho robot — Phần 2: Cơ sở imitation learning
- Foundation Models cho Robot: RT-2, Octo, OpenVLA thực tế — Bước tiếp theo: vision-language-action models
- Sim-to-Real Transfer: Train simulation, chạy thực tế — Chuyển ACT policy từ sim sang real