DREAM-Chunk là một ý tưởng rất thực dụng cho VLA robot: thay vì bắt policy sinh một action chunk rồi robot chạy gần như open-loop cho đến lần inference tiếp theo, ta sinh nhiều candidate chunk, dùng một latent world model nhẹ để "dream" tương lai của từng chunk, rồi ở mỗi control step chọn action thuộc chunk có latent state dự đoán khớp nhất với observation thật.
Nói ngắn gọn: DREAM-Chunk không train lại VLA, không yêu cầu robot gọi model lớn ở tần số cao, và không cố tạo kỹ năng mới từ hư không. Nó tận dụng các recovery behavior đã có trong distribution của policy, rồi dùng thêm test-time compute để chọn candidate hợp lý hơn khi dynamics bị stochastic, actuator lệch, vật thể di chuyển, hoặc môi trường bị người chạm vào giữa chunk.
Nguồn chính của bài:
- Paper: DREAM-Chunk: Reactive Action Chunking with Latent World Model
- arXiv HTML: 2606.18589v1
- Project page: wenxichen2746.github.io/DREAM-Chunk
- Code repo: project page hiện trỏ tới
https://github.com/TODO/DREAM-Chunk, đã kiểm tra là 404 tại thời điểm viết bài. Vì vậy phần cài đặt bên dưới tách rõ phần official status và phần reference skeleton để bạn tự tích hợp với SmolVLA hoặc pi0.5 khi code chính thức được mở.
Nếu bạn mới bắt đầu với VLA, nên đọc thêm SmolVLA training, pi0-FAST training, và world model cho VLA trước khi triển khai trên robot thật.
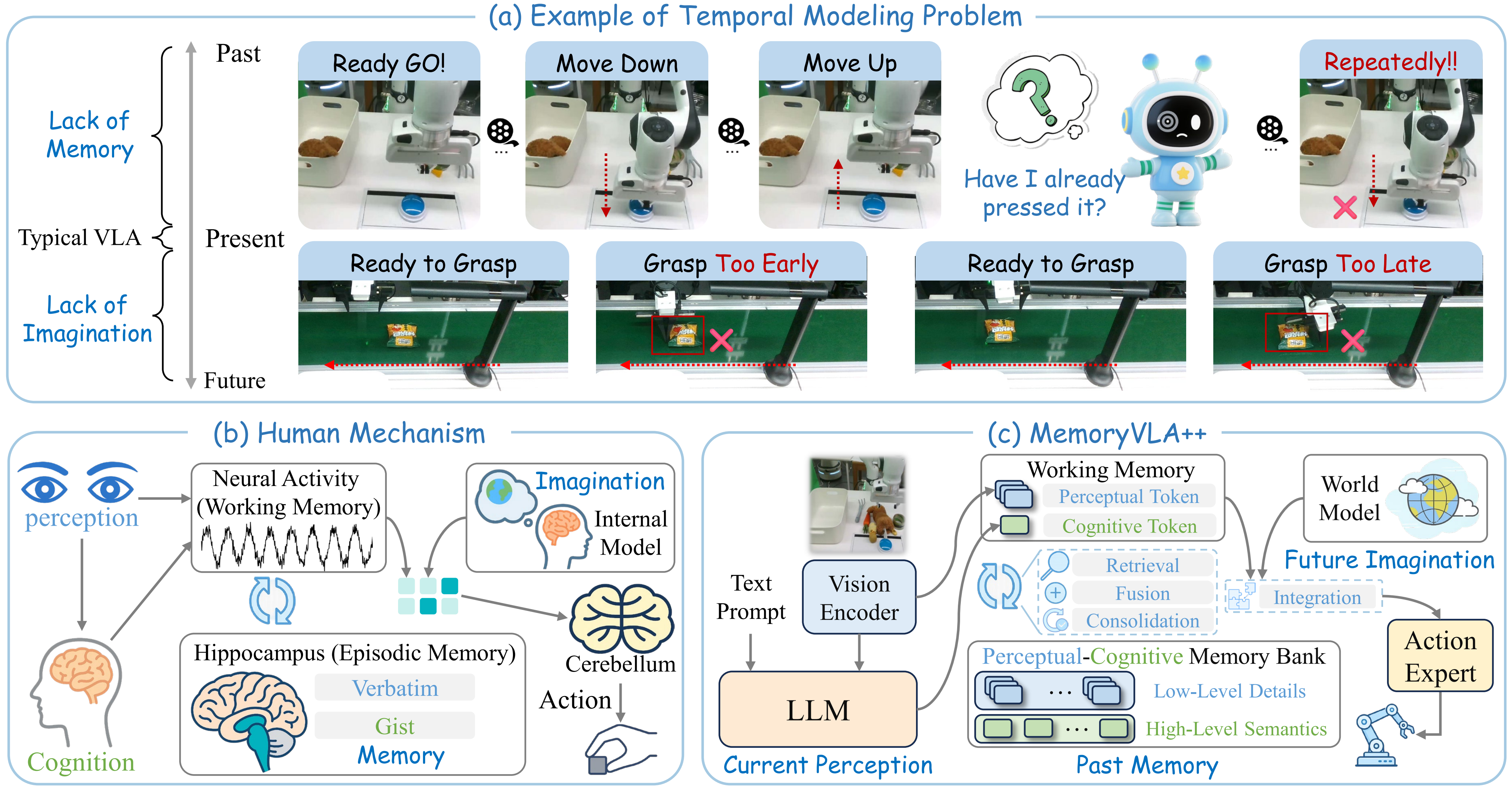
Vấn đề: action chunking mạnh nhưng dễ "mù" giữa chunk
Nhiều VLA hiện đại không output một action đơn lẻ. Chúng output một chuỗi ngắn:
observation_t + language_instruction
|
v
VLA policy
|
v
action chunk A_t = [a_t, a_{t+1}, ..., a_{t+L-1}]
Cách này gọi là action chunking. Nó hữu ích vì VLA lớn thường inference chậm hơn control loop của robot. Ví dụ policy chạy ở 2-10 Hz, trong khi servo cần action ở 30 Hz hoặc cao hơn. Thay vì gọi model lớn liên tục, robot gọi policy một lần, nhận một chunk dài, rồi execute vài step trước khi replan.
Nhưng đây cũng là điểm yếu. Action ở cuối chunk được quyết định từ observation cũ. Nếu tay robot trượt, USB không vào đúng lỗ, vật thể lăn nhanh hơn dự đoán, camera chỉ thấy một frame nên không biết velocity, hoặc con người đẩy target box sang vị trí mới, các action còn lại trong chunk có thể trở thành sai ngữ cảnh.
Open-loop chunking giống như robot nói: "Tôi đã quyết rồi, tôi chạy tiếp." DREAM-Chunk đổi logic thành: "Tôi vẫn giữ chunk dài để tiết kiệm inference, nhưng tôi chuẩn bị nhiều khả năng tương lai và chọn lại trong khi chạy."
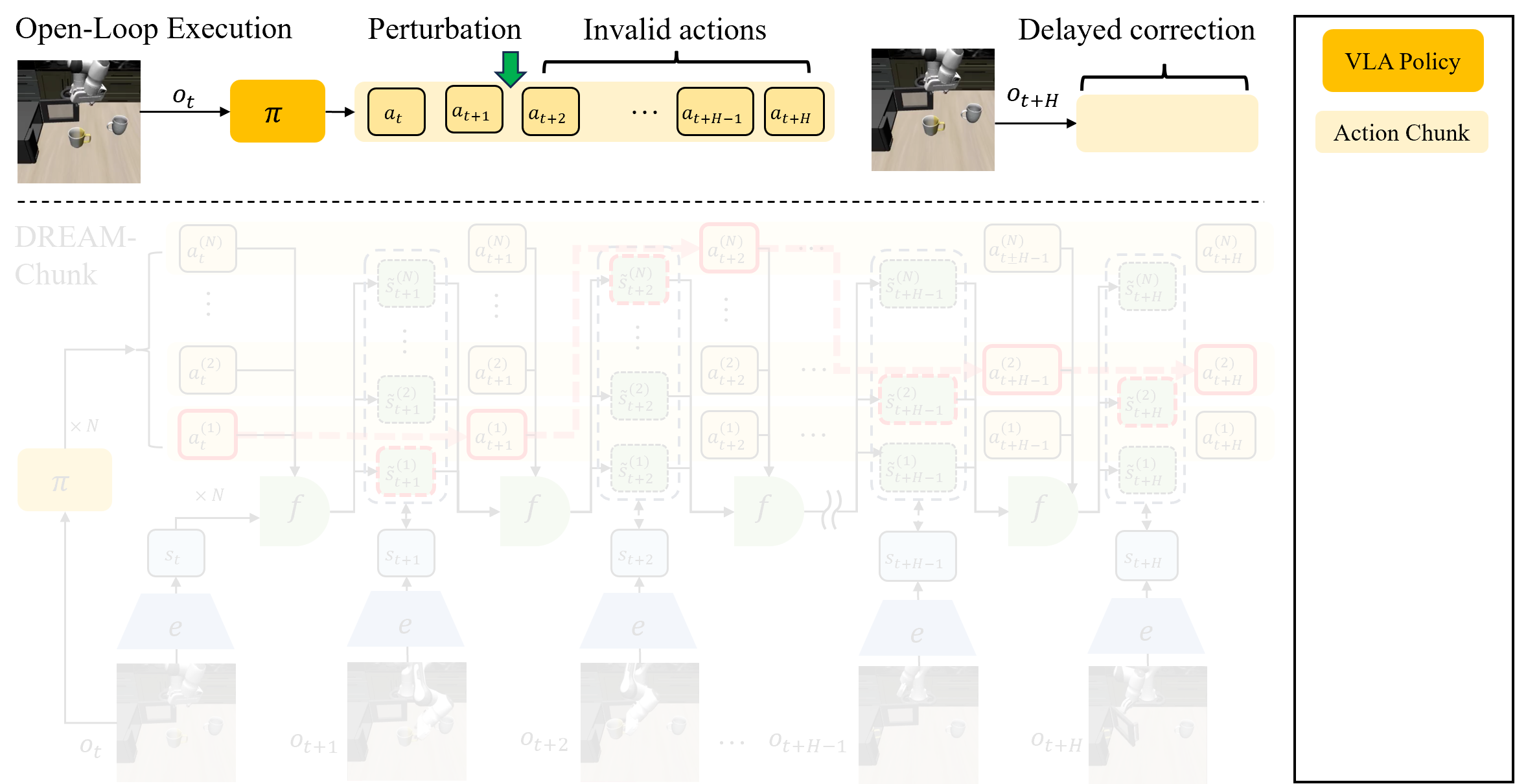
Ý tưởng paper trong 5 bước
DREAM-Chunk là viết tắt của Dreamed-state REactive Action Matching for Action Chunking. Paper đặt bài toán như sau: ta có một chunking policy cố định pi, một encoder E, và một latent dynamics model f. Policy sinh action chunk, encoder biến observation thành latent state, còn dynamics model dự đoán latent state kế tiếp từ latent state hiện tại và action.
Luồng inference cơ bản:
1. Lấy observation hiện tại o_t.
2. Sample N candidate action chunks từ VLA:
A^1, A^2, ..., A^N
3. Encode observation hiện tại:
z_t = E(o_t)
4. Rollout latent tương lai cho từng chunk:
z^i_{t+k+1} = f(z^i_{t+k}, a^i_{t+k})
5. Khi robot chạy tới phase k:
- encode observation thật z_real = E(o_{t+k})
- so z_real với z^1_{t+k}, ..., z^N_{t+k}
- chọn chunk i có latent gần nhất
- execute action a^i_{t+k}
Điểm quan trọng là matching phase-aligned. Robot không nhảy từ phase 8 của chunk này về phase 2 của chunk khác. Ở step thứ k trong execution horizon, nó chỉ so với dreamed latent state ở cùng phase k. Nhờ vậy action vẫn có nhịp thời gian hợp lý, tránh kiểu switch loạn vào một đoạn trajectory chưa đúng giai đoạn.
Kiến trúc: VLA lớn cố định, world model nhỏ phản ứng nhanh
Paper chia hệ thống thành ba module:
+----------------------+
observation ---> | frozen VLA policy pi | ---> N action chunks
+----------------------+
|
v
+----------------------+
observation ---> | encoder E | ---> latent state z
+----------------------+
|
v
+----------------------+
latent + action -> dynamics f | ---> dreamed latent rollouts
+----------------------+
VLA policy có thể là SmolVLA trong thí nghiệm SO-101 hoặc pi0.5 trong thí nghiệm Franka. DREAM-Chunk không yêu cầu fine-tune policy gốc. Phần được train thêm là auxiliary world model, thường nhỏ hơn policy rất nhiều. Paper nhấn mạnh một ví dụ đáng chú ý: JEPA world model có thể chỉ khoảng 15 triệu tham số, trong khi SmolVLA khoảng 450 triệu tham số, và các VLA lớn hơn có thể vượt 2 tỷ tham số. Trong hardware experiments, VLA inference mất hơn 100 ms, còn encoding/prediction/matching của world model ở mức mili-giây.
Có hai dạng latent world model được paper thảo luận:
| Dạng world model | Cách hiểu | Khi nào phù hợp |
|---|---|---|
| RSSM kiểu Dreamer/R2-Dreamer | Latent state có phần deterministic và stochastic | Tốt khi dữ liệu có bất định và cần rollout ổn định |
| JEPA/LEWM decoder-free | Học latent predictive representation, không cần reconstruct ảnh đầy đủ | Nhẹ, nhanh, phù hợp làm matcher cho control |
DREAM-Chunk không bắt buộc một kiến trúc world model duy nhất. Yêu cầu cốt lõi là latent space phải đủ predictive để phân biệt "nếu chạy chunk này thì robot sẽ ở trạng thái nào" và dynamics model phải đủ ổn định trong execution horizon.
Cài đặt: trạng thái official và skeleton thực hành
Tại thời điểm viết bài, project page đã public paper, asset, video và kết quả, nhưng link Code đang là placeholder 404. Vì vậy bạn chưa nên copy-paste một command kiểu git clone và kỳ vọng có repo chính thức. Cách thực dụng là chuẩn bị môi trường tương thích với VLA stack hiện tại, rồi gắn DREAM-Chunk như một inference wrapper khi code hoặc implementation nội bộ đã sẵn sàng.
Môi trường tham khảo:
conda create -n dreamchunk python=3.10 -y
conda activate dreamchunk
pip install torch torchvision torchaudio
pip install transformers accelerate einops opencv-python
pip install lerobot
pip install numpy scipy tqdm h5py zarr
Với SO-101/LeRobot, bạn sẽ cần thêm phần camera, robot bus, calibration và dataset theo stack đang dùng. Với Franka, bạn cần bridge riêng cho controller, camera capture và safety stop. DREAM-Chunk không thay thế controller thấp tầng; nó chỉ quyết định action nào trong các candidate chunk nên execute ở phase hiện tại.
Skeleton inference nên được tổ chức thành bốn interface:
class ChunkPolicy:
def sample_chunks(self, observation, instruction, num_samples: int):
"""Return tensor [N, H, action_dim]."""
class WorldEncoder:
def encode(self, observation):
"""Return latent vector z."""
class LatentDynamics:
def rollout(self, z0, chunks):
"""Return dreamed latents [N, H, latent_dim]."""
class DreamChunkExecutor:
def select_action(self, observation, dreamed_latents, chunks, phase: int):
z_real = self.encoder.encode(observation)
z_phase = dreamed_latents[:, phase]
idx = nearest_neighbor(z_real, z_phase)
return chunks[idx, phase]
Trong implementation thật, nearest_neighbor thường là cosine distance hoặc L2 distance trong latent space đã normalize. Nếu latent có stochastic component, bạn có thể match trên deterministic hidden state hoặc trên mean của latent distribution, miễn là cách train và cách inference nhất quán.
Training: train policy như cũ, train thêm world model
Pipeline training của DREAM-Chunk nên tách thành hai nhánh.
Nhánh 1 là chunking policy. Bạn train SmolVLA/pi0.5/OpenVLA-style policy bằng demonstration dataset như bình thường: observation, instruction, robot state, action sequence. Policy học sinh action chunk từ observation hiện tại. Nếu bạn đang dùng LeRobot, phần này giống các bài LeRobot cho VLA và pi0-FAST: chuẩn hóa action, đồng bộ camera/state/action, split train/val, rồi train policy theo objective của model.
Nhánh 2 là auxiliary world model. Nó dùng cùng trajectory dataset, nhưng target không phải action. Target là latent transition:
input:
observation o_t
action a_t
target:
representation của observation o_{t+1}
loss:
prediction loss trong latent space
+ representation regularization
+ optional contrastive/redundancy-reduction loss
Paper dùng các biến thể như R2-Dreamer, LeWorldModel và EB-JEPA. Trong Kinetix, cấu hình mặc định được mô tả là RSSM-based world model với one-step prediction loss và Barlow Twins regularization. Với LEWM/EB-JEPA, paper dùng latent regularization như SigReg hoặc VICReg. Nếu bạn triển khai từ đầu, hãy bắt đầu bằng one-step latent prediction trước khi thêm loss phức tạp.
Một chi tiết dễ bị bỏ qua: DREAM-Chunk hiệu quả nhất khi demonstration có corrective behaviors. Nếu dataset chỉ chứa trajectory sạch, robot luôn đi đúng đường, không có ví dụ sửa lỗi khi lệch, thì sampling thêm N chunk chỉ tạo các biến thể rất gần nominal path. Khi robot thật bị lệch, candidate pool có thể không chứa action sửa lỗi nào. Vì vậy khi thu data, nên cố ý thêm episode có nhiễu nhẹ, vật thể lệch, grasp chưa hoàn hảo, insertion bị cấn rồi sửa lại, hoặc target bị di chuyển trong giới hạn an toàn.
Checklist dataset cho beginner:
| Thành phần | Cần lưu | Lý do |
|---|---|---|
| RGB hoặc RGB-D frames | camera chính, wrist camera nếu có | encoder cần observation để tạo latent |
| Robot proprioception | joint, gripper, TCP pose nếu có | giúp latent phân biệt trạng thái tay |
| Action | delta pose, joint target, gripper command | dynamics model cần action để predict |
| Instruction | câu lệnh task | policy cần condition language |
| Failure/correction tags | optional nhưng hữu ích | debug xem DREAM-Chunk có chọn recovery không |
Inference: chọn N, horizon H, overlap như thế nào?
Ba hyperparameter quan trọng nhất là N, H, và control rate.
N là số candidate chunks. N càng lớn thì coverage càng tốt, nhưng policy inference tốn hơn. Paper cho thấy trong Kinetix, performance tăng khi sample size tăng, đặc biệt dưới action noise cao. Tuy nhiên trên hardware, nếu tăng N làm inference hoặc network round-trip quá chậm, lợi ích có thể giảm. Franka remote inference trong paper là ví dụ rõ: remote DREAM-Chunk vẫn hơn local open-loop baseline, nhưng tăng N quá cao không tiếp tục cải thiện vì delay tăng.
H là số step execute trước khi replan. Nếu H quá ngắn, bạn gần như đang high-frequency replanning, ít tận dụng DREAM-Chunk. Nếu H quá dài, rollout error của world model tích lũy và candidate chunk dễ lỗi thời. Paper dùng các execution horizon khác nhau theo task hardware: SO-101 ở 30 Hz hoặc Franka ở 10 Hz, với horizon được chọn theo task.
Một vòng inference tối giản:
while not done:
obs0 = robot.observe()
chunks = policy.sample_chunks(obs0, instruction, num_samples=N)
z0 = encoder.encode(obs0)
dreamed = dynamics.rollout(z0, chunks)
for phase in range(H):
obs = robot.observe()
z = encoder.encode(obs)
idx = argmin_distance(z, dreamed[:, phase])
action = chunks[idx, phase]
robot.step(action)
Trong production, bạn sẽ thêm asynchronous inference: khi robot đang execute phase cuối của chunk hiện tại, process khác bắt đầu sample batch chunk mới. Cần log ba thứ: chunk index được chọn qua từng phase, latent distance giữa observation thật và từng dreamed state, và action executed. Log này giúp phát hiện trường hợp world model match sai hoặc policy không sample được recovery.
Kết quả trong paper
Kinetix là benchmark simulation 2D có locomotion, manipulation và các task kiểu Atari-like physics control. Paper thêm Gaussian noise vào executed action để tạo stochastic dynamics, rồi so DREAM-Chunk với naive asynchronous execution, RTC, BID và Adaptive Chunking.
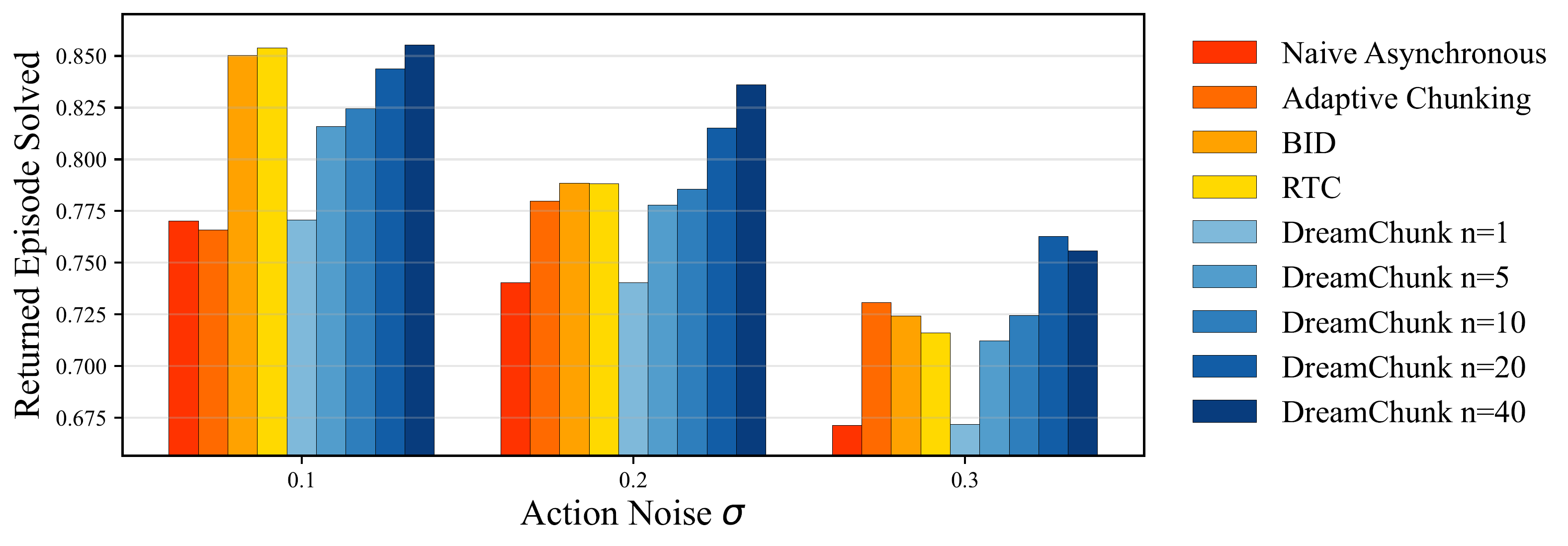
Kết luận từ Kinetix có ba lớp:
- Khi action noise thấp, nhiều method test-time chunking đều có thể cải thiện so với naive open-loop.
- Khi noise tăng, within-chunk reactivity của DREAM-Chunk bắt đầu quan trọng hơn vì robot cần sửa ngay trong chunk, không chỉ làm transition giữa các chunk mượt hơn.
- Sample nhiều chunk chỉ có ích nếu policy distribution chứa corrective behaviors và world model latent đủ reliable để chọn đúng.
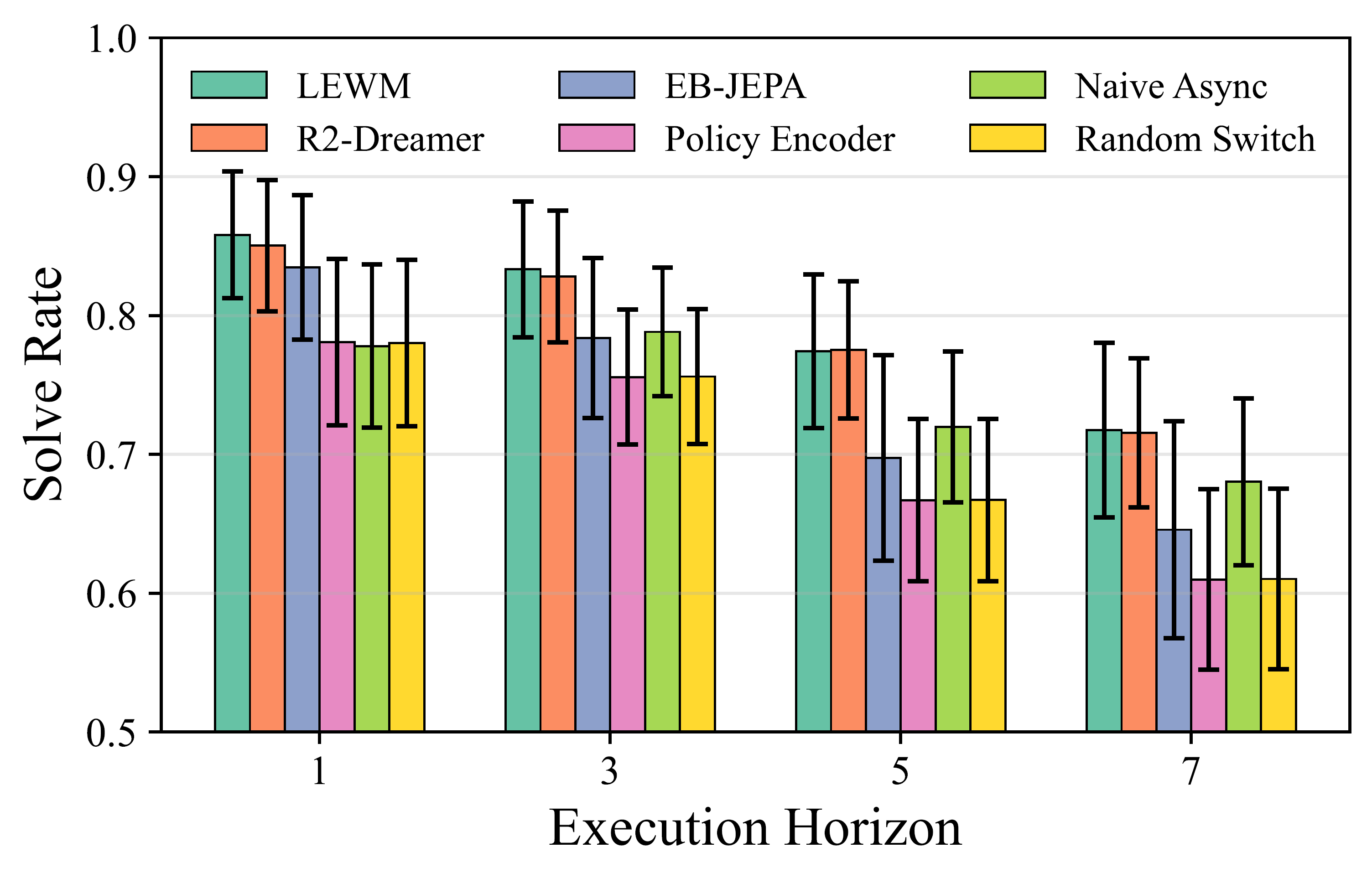
Paper cũng so sánh latent world model architecture. LEWM và R2-Dreamer hoạt động cạnh tranh; EB-JEPA yếu hơn ở horizon dài do rollout error; còn dùng frozen policy encoder rồi train một dynamics predictor đơn giản có xu hướng gần Random Switch. Đây là cảnh báo quan trọng: không phải cứ lấy feature của policy là đủ. Latent representation phải được train cho predictive dynamics, không chỉ cho perception hoặc action decoding.
Hardware experiments gồm bốn task trên hai platform:
| Platform | Policy | Task | Nguồn stochasticity | Kết quả nổi bật |
|---|---|---|---|---|
| SO-101 | SmolVLA | USB insert | servo precision, insertion error | open-loop 75% lên DREAM-Chunk 95% |
| SO-101 | SmolVLA | grasp moving object | velocity bị partial observable | open-loop 60% lên 80% |
| SO-101 | SmolVLA | stack/pick toy | hardware imprecision | open-loop 35% lên 45% |
| Franka Panda | pi0.5 | pick and insert can | external perturbation target box | local open-loop 10% lên DREAM-Chunk local N=5 đạt 65% |
Các con số này không có nghĩa DREAM-Chunk "giải quyết xong" manipulation. Nó chủ yếu tạo correction cục bộ quanh behavior mode hiện tại, không tự phát minh strategy hoàn toàn mới. Nếu policy chưa từng học cách sửa insertion bị kẹt, DREAM-Chunk không thể chọn một behavior không tồn tại trong candidate pool.
Khi nào nên dùng DREAM-Chunk?
DREAM-Chunk đáng thử khi bạn có bốn điều kiện:
- Policy của bạn đã là chunking policy và inference đủ chậm để open-loop chunking là vấn đề thực tế.
- Robot gặp stochasticity vừa phải: actuator không hoàn hảo, object di chuyển, observation thiếu velocity, hoặc môi trường có perturbation nhỏ.
- Dataset có một lượng correction behavior, không chỉ trajectory sạch.
- Bạn có thể train một latent world model đủ nhẹ để chạy gần control loop.
Không nên kỳ vọng DREAM-Chunk thay thế safety controller, force control, impedance control hoặc collision checking. Với robot thật, action được chọn vẫn phải đi qua limit, workspace guard, emergency stop, và controller thấp tầng. DREAM-Chunk là policy execution strategy, không phải lớp safety cuối cùng.
Công thức triển khai tối thiểu cho lab
Nếu triển khai trong lab robotics, tôi sẽ bắt đầu bằng scope nhỏ:
Task: SO-101 pick-and-place hoặc insert đơn giản
Dataset: 100-200 demos, trong đó 20-30% có correction nhẹ
Policy: SmolVLA fine-tune
World model: encoder nhỏ + RSSM/MLP latent dynamics
N: 5 trước, sau đó 10 nếu latency còn đủ
H: 10-30 step tùy control rate
Metric: success rate, intervention count, latent match distance
Sau khi baseline chạy, hãy làm ablation bắt buộc:
| Ablation | Câu hỏi |
|---|---|
| Open-loop chunking | DREAM-Chunk có thật sự hơn policy gốc không? |
| Random Switch | Latent matching có giá trị hay chỉ do sample nhiều? |
| N = 1, 5, 10 | Có scaling theo sample size không? |
| Horizon ngắn/dài | World model còn reliable đến đâu? |
| Clean demos vs correction demos | Dataset có recovery behavior không? |
Phần quan trọng nhất là debug latent matching. Nếu distance giữa observation thật và tất cả dreamed states đều tăng dần theo phase, horizon quá dài hoặc world model yếu. Nếu model luôn chọn cùng một chunk, candidate diversity thấp. Nếu chọn nhảy liên tục nhưng success không tăng, latent space có thể đang match perceptual similarity thay vì action-relevant state.
Bài học chính
DREAM-Chunk là một bước thú vị vì nó nối hai hướng đang phát triển mạnh: VLA action chunking và latent world model. Thay vì dùng world model để generate video đẹp hoặc plan từ đầu, paper dùng nó như một matcher rẻ, chạy tại test time, để làm action chunking phản ứng hơn mà không đụng vào VLA gốc.
Với đội đang build robot manipulation, takeaway thực tế là: đừng chỉ hỏi "policy nào mạnh hơn?". Hãy hỏi thêm "execution strategy nào tận dụng policy tốt hơn khi robot thật không chạy đúng như simulation?". DREAM-Chunk cho thấy đôi khi một world model nhỏ, nếu được train đúng latent dynamics và có dữ liệu correction đủ tốt, có thể biến một chunking policy open-loop thành hệ phản ứng hơn đáng kể.