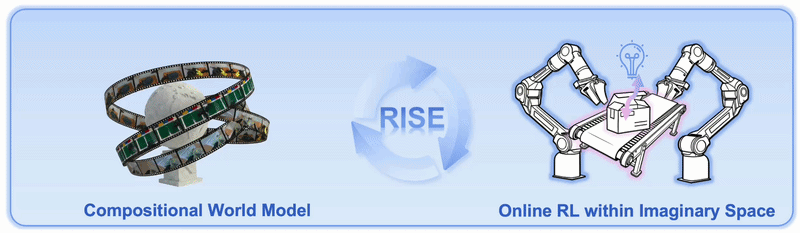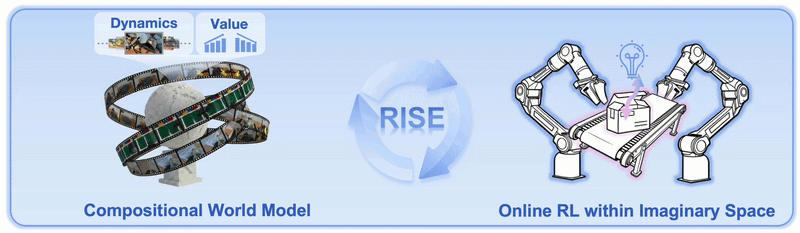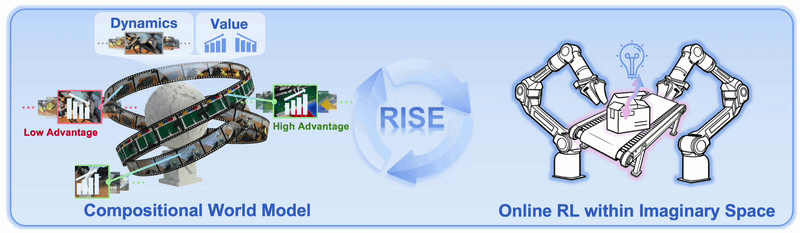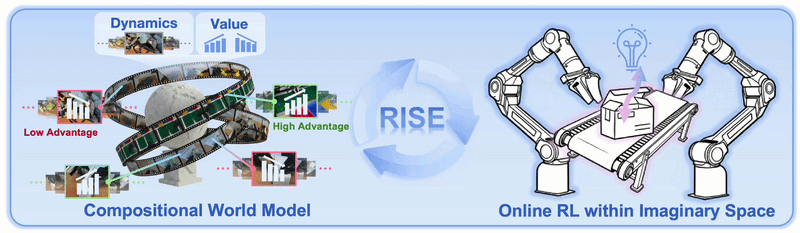
Vì sao RISE đáng chú ý?
RISE, viết đầy đủ là Reinforcement learning via Imagination for SElf-improving robots, là một paper RSS 2026 có tiêu đề RISE: Self-Improving Robot Policy with Compositional World Model. Paper được submit lên arXiv ngày 11/02/2026, bản v2 được revise ngày 28/04/2026, và code chính thức nằm ở OpenDriveLab/RISE. Điểm quan trọng không nằm ở việc nhóm tác giả tạo thêm một VLA model mới, mà ở cách họ biến world model thành một môi trường học RL cho robot.
Nếu bạn đã đọc các bài về VLA models hoặc VLA-RL, bạn sẽ thấy một pattern quen thuộc: imitation learning giúp robot bắt chước demonstration khá tốt, nhưng model dễ gãy khi gặp lỗi nhỏ. Kẹp lệch vài milimet, object bị xoay khác data train, zipper bị kéo quá tay, nắp hộp bị kẹt, conveyor belt làm vật chạy nhanh hơn dự kiến. Với manipulation thật, lỗi nhỏ thường tích lũy thành failure.
RL về lý thuyết giải quyết đúng vấn đề này: robot thử, sai, nhận reward, rồi cải thiện policy. Nhưng RL trên robot thật rất đắt. Mỗi rollout cần hardware thật, reset environment, có nguy cơ va chạm, có thể làm hỏng object, và throughput thường thấp hơn rất nhiều so với RL trong simulator. RISE hỏi một câu rất trực tiếp: nếu không thể cho robot thử hàng nghìn lần trong thế giới thật, liệu ta có thể cho nó thử trong imagination của một world model đủ tốt không?
Ý tưởng cốt lõi
RISE thay môi trường RL vật lý bằng một Compositional World Model. Thay vì policy đưa action ra robot thật rồi chờ camera quan sát kết quả, RISE làm vòng lặp sau trong lúc training:
Current observation + language instruction
|
v
VLA policy proposes an action chunk
|
v
Controllable Dynamics Model imagines future multi-view frames
|
v
Progress Value Model scores imagined progress
|
v
Advantage is computed for the proposed action
|
v
Policy is updated in imagination
Điểm then chốt là RISE không dùng một model khổng lồ để vừa mô phỏng tương lai vừa chấm reward. Nhóm tác giả tách bài toán thành hai module chuyên biệt:
| Module | Nhiệm vụ | Vì sao cần tách riêng? |
|---|---|---|
| Controllable Dynamics Model | Sinh future observations đa góc nhìn, conditioned on action chunks | Cần nhanh, ổn định hình ảnh, và bám sát action |
| Progress Value Model | Chấm mức tiến triển của imagined outcome | Cần nhạy với lỗi nhỏ và tạo learning signal dày hơn success/failure |
| VLA Policy | Sinh action từ image + language + advantage condition | Sau training, chỉ policy chạy trên robot thật |
Thiết kế này thực dụng. Dynamics model tập trung trả lời câu hỏi "nếu làm action này thì camera sẽ thấy gì sau vài bước?". Value model tập trung trả lời "tương lai đó tốt hay xấu đối với task?". Policy chỉ cần học rằng action nào tương ứng với advantage cao.
Kiến trúc RISE
RISE có ba phần trong repo chính thức:
OpenDriveLab/RISE
├── policy_and_value/
│ ├── policy_offline_and_value/ # offline policy + value training dựa trên OpenPI
│ └── policy_online/ # online RL trong imagination
├── dynamics/
│ └── dynamics_model/ # action-conditioned dynamics model
└── deploy/ # deploy OpenPI policy trên AgileX/Piper
1. VLA policy nền
Policy trong paper được khởi tạo từ π0.5, một VLA pre-trained. Bạn có thể hiểu nó như một robot foundation policy: nhận multi-view RGB observations và language instruction, rồi sinh action. RISE không bắt đầu từ một policy rỗng, vì RL từ zero trên robot manipulation là quá khó. Thay vào đó, policy được warm-up bằng offline data: expert demonstrations, policy rollouts có cả success/failure, và một phần human correction kiểu DAgger.
Điểm khác với imitation learning thuần là RISE thêm advantage-conditioning. Policy không chỉ học "observation này đi với action này", mà học "trong trạng thái này, action này có advantage như thế nào". Điều này cho phép model học cả từ hành động tốt và hành động xấu.
2. Controllable Dynamics Model
Dynamics model là "môi trường tưởng tượng" của RISE. Nó nhận:
Input:
- multi-view images hiện tại
- language/task context
- action chunk do policy đề xuất
Output:
- predicted future multi-view observations
Theo paper, module này được khởi tạo từ Genie Envisioner GE-base, thừa hưởng kiến trúc từ LTX-Video. Lý do chọn hướng video generation là robot manipulation rất thị giác: nếu model tưởng tượng được object trượt, nắp hộp lệch, zipper căng, hoặc viên gạch chạy trên conveyor, policy có learning signal tốt hơn.
Nhưng video model gốc thường conditioned on text, không đủ để điều khiển bằng action robot. RISE thêm một light-weight action encoder và fine-tune trên dữ liệu robot có action label, gồm Galaxea Open World và AgiBot World Alpha. Repo chính thức cũng ghi rõ dynamics model dùng LeRobot-format data, resize ảnh/video về 256x192, với ba camera: một head/top view và hai wrist views.
Một chi tiết kỹ thuật hay là Task-Centric Batching. Khi train world model trên dữ liệu nhiều task, batch quá đa dạng dễ làm model học không ổn: trong cùng một update, scene, object, action, camera đều thay đổi. RISE ưu tiên batch gồm ít task hơn nhưng nhiều action khác nhau trong cùng bối cảnh. Nói đơn giản: thay vì ép model hiểu mọi thứ cùng lúc, hãy cho nó học rõ "cùng cảnh này, action khác nhau tạo tương lai khác nhau như thế nào".
3. Progress Value Model
Robot manipulation thường có sparse reward: cuối episode mới biết success/failure. Nhưng task như backpack packing hoặc box closing có nhiều trạng thái trung gian: mở miệng balo đúng, đưa vật vào đúng hướng, không kéo dây quá tay, nắp hộp chạm đúng mép. RISE dùng Progress Value Model để gán scalar value cho observation hoặc imagined observation.
Value model cũng được parameterize từ VLA backbone π0.5. Đây là lựa chọn hợp lý vì backbone này đã có hiểu biết robot-centric và hỗ trợ multi-view inputs. Paper train value model khoảng 50k steps: 10k steps đầu dùng progress estimate loss, 40k steps sau thêm Temporal Difference learning loss. Discount factor được báo cáo là 0.995.
4. Self-improving loop
Sau warm-up, RISE chạy vòng tự cải thiện:
for update in range(num_updates):
obs = sample_offline_or_recent_state()
action_chunk = rollout_policy(obs, instruction, target_advantage=1.0)
imagined_future = dynamics_model.predict(
current_images=obs.images,
action_tokens=action_chunk,
language=instruction,
)
value_now = value_model(obs)
value_future = value_model(imagined_future)
advantage = value_future - value_now
train_policy(
observation=obs,
action=action_chunk,
advantage=advantage,
)
Pseudo-code trên đơn giản hóa paper, nhưng giúp beginner nắm được luồng. RISE không cần rollout đến terminal state trong world model để nhận reward cuối cùng. Nó tạo chunk-wise advantage cho action chunk đang xét. Đây là điểm quan trọng vì video world model càng rollout xa càng dễ drift.
Cài đặt repo
Repo chính thức hiện đã release training code và pre-trained dynamics model. README ngày 03/06/2026 còn nhắc nên pull latest code vì có bug fixes quan trọng. Cài đặt cơ bản theo docs:
conda create -n rise python=3.11.14 -y
conda activate rise
cd /path/to/RISE
bash install.sh
Data cần ở dạng LeRobot format. Nếu bạn thu data raw bằng Piper ở dạng HDF5, repo cung cấp script convert:
cd /path/to/RISE/policy_and_value/policy_offline_and_value
python examples/aloha_real/convert_to_lerobot.py \
--data-dir /path/to/raw_dataset \
--repo-ids aloha_mobile_dummy \
--prompt "Pick and sort bricks on the conveyor." \
--save-dir /path/to/lerobot_output_root \
--save_repoid brick_sorting
Layout output cần giống:
brick_sorting/
├── data/chunk-000/episode_*.parquet
├── meta/
│ ├── info.json
│ ├── episodes.jsonl
│ ├── episodes_stats.jsonl
│ └── tasks.jsonl
└── videos/chunk-000/*.mp4
Với dynamics model, docs khuyến nghị resize video từng view về 256x192:
cd RISE/dynamics/dynamics_model
./preprocess.sh brick_sorting
Training từng phần
Offline policy và value model
Từ thư mục policy_and_value/policy_offline_and_value, repo release ba config: Policy_offline_release, value_release, và Compute_norm.
python scripts/compute_norm_stats_fast.py --config-name Compute_norm
bash train.sh Policy_offline_release 8
bash train.sh value_release 8
Sau khi có value model, bạn cần label value/advantage cho LeRobot datasets:
bash label_value.sh vis_value_release_joint_T \
/path/to/checkpoints/value_release_joint/<exp>/<step>
Đây là bước quan trọng vì policy improvement trong RISE dùng advantage-conditioning. Nếu không có label value tốt, policy không biết action nào là "đáng bắt chước" hơn trong imagined rollouts.
Dynamics model
Dynamics model có hai phase:
| Phase | Data | Compute trong paper | Mục tiêu |
|---|---|---|---|
| Pre-training | Galaxea + AgiBot World Alpha | 16 NVIDIA H100, batch 512, khoảng 7 ngày | Học robot dynamics prior |
| Task fine-tuning | Task-specific LeRobot data | 8 NVIDIA H100, batch 64, khoảng 3 ngày | Bám domain, camera, object, action của task |
Lệnh chính trong repo:
cd RISE/dynamics/dynamics_model
# tải LTX backbone components và checkpoint liên quan
./download.sh
# pre-train, nếu bạn có data và compute đủ lớn
bash train_task_centric.sh
# fine-tune cho task cụ thể
python norm.py --datasets brick_sorting --save-config data/utils/action_norm.json
bash task_finetune.sh
Với người mới, điều cần hiểu là: đây không phải pipeline "chạy trên laptop". RISE là research system cho cụm GPU lớn. Bạn vẫn có thể học kiến trúc, format data, inference của dynamics model, hoặc fine-tune nhỏ hơn; nhưng tái tạo full result cần hardware tương đương paper.
Online RL trong imagination
Phần online training dùng policy_and_value/policy_online. Docs dùng một embodiment script:
bash policy_and_value/policy_online/examples/embodiment/run_embodiment.sh rl_release
Config quan trọng gồm:
| Config | Ý nghĩa |
|---|---|
rollout.model_dir |
checkpoint IL policy dùng để khởi tạo |
dynamics_model_config |
config dynamics model |
reward_model_config |
config value/reward model |
reward_model_ckpt |
checkpoint value model |
algorithm.num_group_envs |
số environment song song cho rollout |
chunk_reward |
dùng reward frame cuối của predicted chunk |
advantage_scale |
hệ số scale advantage |
Repo hỗ trợ placement GPU cho ba thành phần: env, rollout, actor. Ví dụ default partial sharing:
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout: 4-7
actor: 0-7
Inference trên robot thật
Một điểm rất đáng nhớ: world model không chạy khi robot deploy thật. Dynamics model và value model chỉ dùng trong policy learning phase. Khi inference, robot chỉ chạy policy đã được cải thiện.
Deploy docs dành cho AgileX Piper dual-arm, Ubuntu 20.04, ROS Noetic, RealSense cameras:
# Terminal 1: cameras
roslaunch realsense2_camera multi_camera.launch
# Terminal 2: robot arms
bash deploy/Piper_ros_private-ros-noetic/can_config.sh
roslaunch piper start_ms_piper.launch mode:=1 auto_enable:=true
# Terminal 3: inference
conda activate deploy
python deploy/piper_deploy.py \
--host 172.16.99.11 \
--port 8000 \
--ctrl_type joint \
--use_temporal_smoothing \
--chunk_size 50 \
--lang_embeddings "Pick and sort bricks on the conveyor."
Trước deploy, checkpoint distributed .dcp cần convert sang PyTorch state dict:
python toolkits/ckpt_convertor/convert_dcp_to_state_dict.py \
--dcp_path <YOUR_DCP_CKPT_DIR> \
--output_path <YOUR_EXPECTED_PT_CKPT_DIR>
Trong setup paper, robot là dual 7-DoF AgileX, điều khiển absolute joint control. Appendix mô tả mỗi arm có 6 DoF + gripper 1 DoF, có wrist camera, thêm top-down camera cao khoảng 0.75 m, control frequency 30 Hz.
Kết quả thực nghiệm
RISE được benchmark trên ba task thật:
| Task | Vì sao khó? |
|---|---|
| Dynamic Brick Sorting | Conveyor belt tạo dynamics, robot phải grasp và sort theo màu |
| Backpack Packing | Object mềm/compliant, dễ kẹt, dễ lệch |
| Box Closing | Cần bimanual coordination và precision |
Bảng chính trong paper:
| Method | Brick success | Brick score | Backpack success | Backpack score | Box success | Box score |
|---|---|---|---|---|---|---|
| π0.5 | 35% | 8.28 | 30% | 4.25 | 35% | 7.50 |
| π0.5 + DAgger | 15% | 6.10 | 50% | 7.00 | 40% | 7.50 |
| π0.5 + PPO | 10% | 7.68 | 35% | 5.88 | 10% | 4.75 |
| π0.5 + DSRL | 10% | 6.65 | 10% | 3.50 | 10% | 7.63 |
| RECAP | 50% | 9.00 | 40% | 6.13 | 60% | 8.13 |
| RISE | 85% | 9.78 | 85% | 9.50 | 95% | 9.88 |
Nhìn vào bảng, điều thú vị là các baseline RL trực tiếp như PPO hoặc DSRL không tự động thắng. Trên Dynamic Brick Sorting, π0.5 ban đầu đạt 35%, nhưng π0.5 + PPO rơi xuống 10%. Điều này phản ánh vấn đề quen thuộc của RL thật: exploration có thể làm policy mất ổn định nếu reward, data và action distribution không được kiểm soát tốt.
RISE thắng vì nó kết hợp ba thứ: policy nền đủ mạnh, world model đủ nhanh để tạo nhiều imagined rollouts, và value model đủ nhạy để biến outcome tưởng tượng thành advantage. So với RECAP, RISE không chỉ học từ offline advantage label; nó tiếp tục tạo data online trong imagination.
Hạn chế và cách đọc paper cho đúng
RISE không có nghĩa là world model đã thay simulator vật lý hoàn toàn. Video world model vẫn có thể sai trong contact dynamics hiếm, object deformation phức tạp, hoặc tình huống ngoài distribution. Nếu dynamics model tưởng tượng sai nhưng value model vẫn chấm cao, policy có thể học hành vi không tốt. Vì vậy paper dùng rollout ngắn theo action chunk, offline data mixing, EMA rollout policy, task-specific fine-tuning, và không dùng world model lúc deploy.
Một điểm nữa là compute rất lớn. Full pre-training dynamics model cần 16 H100 trong khoảng một tuần; value model và fine-tuning cũng cần nhiều GPU. Với lab nhỏ, bài học thực tế không nhất thiết là "copy nguyên RISE", mà là:
- Dùng VLA/IL để có policy nền an toàn.
- Thu cả success và failure rollouts, không chỉ expert demos.
- Học một value/progress model thay vì chỉ success/failure cuối episode.
- Dùng world model có action conditioning để tạo candidate futures.
- Chỉ deploy policy cuối cùng, không kéo toàn bộ world model lên robot nếu latency không cần thiết.
Nếu bạn đang làm với LeRobot hoặc OpenPI, RISE là một blueprint tốt để nghĩ về bước sau imitation learning. Nó nằm giữa fine-tune VLA với real robot RL và sim-to-real pipeline: không phải simulator vật lý cổ điển, cũng không phải RL thật thuần túy, mà là RL trong một learned imagination environment.
Nguồn tham khảo
- Paper: RISE: Self-Improving Robot Policy with Compositional World Model
- Project page: opendrivelab.com/RISE
- Code: github.com/OpenDriveLab/RISE
- Dynamics docs: RISE dynamics_model.md
- Deployment docs: RISE deploy.md