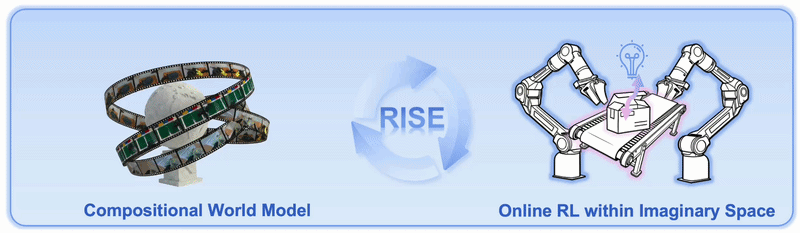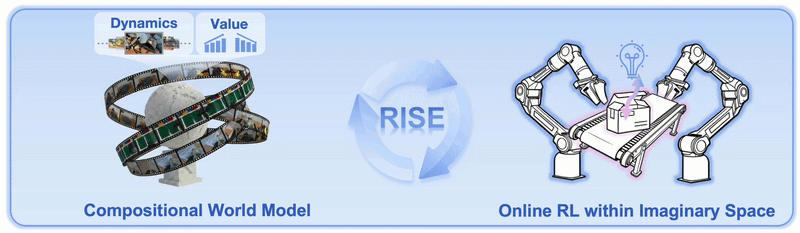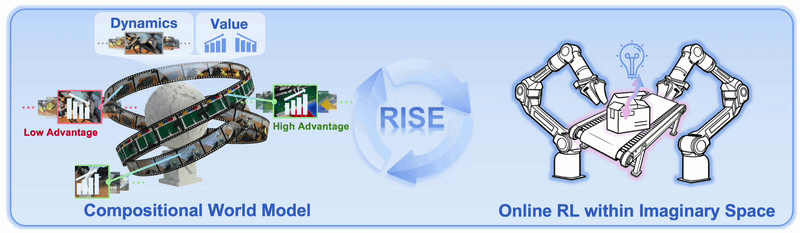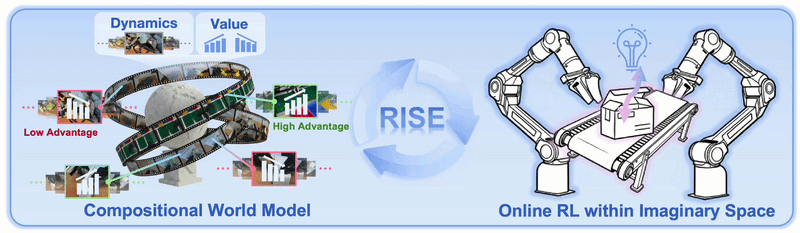
Why RISE matters
RISE, short for Reinforcement learning via Imagination for SElf-improving robots, is an RSS 2026 paper titled RISE: Self-Improving Robot Policy with Compositional World Model. It was submitted to arXiv on February 11, 2026, revised on April 28, 2026, and the official code is available at OpenDriveLab/RISE. The important idea is not simply "another VLA model." RISE shows how to turn a learned world model into a practical RL environment for real-world robot manipulation.
If you have read our posts on VLA models or VLA-RL, the motivation will feel familiar. Imitation learning gives robots a strong starting point, but the resulting policy can be brittle. A gripper can miss by a few millimeters. A soft object can deform. A zipper can be over-pulled. A box lid can jam. A brick on a conveyor can move faster than expected. In manipulation, small errors often compound into full task failure.
Reinforcement learning is the natural answer in theory: let the robot try actions, observe outcomes, receive rewards, and improve. In practice, real-world robot RL is expensive and slow. Every rollout requires physical hardware, environment resets, safety monitoring, and sometimes replacement of objects. RISE asks a very direct question: if we cannot afford thousands of real robot trials, can the policy practice inside the imagination of a sufficiently controllable world model?
The core idea
RISE moves the RL environment from the physical world into a Compositional World Model. Instead of executing every candidate action on the real robot, the system runs the following loop during training:
Current observation + language instruction
|
v
VLA policy proposes an action chunk
|
v
Controllable Dynamics Model imagines future multi-view frames
|
v
Progress Value Model scores imagined progress
|
v
Advantage is computed for the proposed action
|
v
Policy is updated in imagination
The key design decision is modularity. RISE does not ask one huge model to both simulate future video and judge task success. It splits the world model into two specialized modules:
| Module | Job | Why separate it? |
|---|---|---|
| Controllable Dynamics Model | Generate future multi-view observations conditioned on action chunks | Must be fast, visually coherent, and action-controllable |
| Progress Value Model | Score imagined outcomes as task progress | Must be dense and sensitive to subtle manipulation failures |
| VLA Policy | Produce actions from images, language, and advantage conditioning | Only this policy runs on the real robot at deployment |
This is a pragmatic architecture. The dynamics model answers "what would the cameras see if the robot executed this action chunk?" The value model answers "is that imagined future good for the task?" The policy learns which actions correspond to high advantage.
RISE architecture
The official repository is organized into three main parts:
OpenDriveLab/RISE
├── policy_and_value/
│ ├── policy_offline_and_value/ # OpenPI-based offline policy + value training
│ └── policy_online/ # online RL in imagination
├── dynamics/
│ └── dynamics_model/ # action-conditioned dynamics model
└── deploy/ # OpenPI policy deployment on AgileX/Piper
1. The base VLA policy
The paper initializes the robot policy from π0.5, a pretrained VLA. You can think of it as a robot foundation policy: it consumes multi-view RGB observations plus a language instruction, then generates robot actions. RISE does not start from a blank policy because manipulation RL from scratch is usually too hard and too unsafe. Instead, the policy is first warmed up on offline data: expert demonstrations, policy rollouts with successes and failures, and a portion of human correction data in the style of DAgger.
The important twist is advantage conditioning. The policy is not only trained on pairs like "observation goes with action." It is trained on "in this observation, this action has this advantage." That lets the policy learn from both good and bad actions.
2. Controllable Dynamics Model
The dynamics model is the imagined environment. It receives:
Input:
- current multi-view images
- language/task context
- action chunk proposed by the policy
Output:
- predicted future multi-view observations
According to the paper, the dynamics model is initialized from Genie Envisioner GE-base, which inherits architectural advantages from LTX-Video. The video generation direction makes sense for manipulation: the robot needs to reason about sliding objects, soft backpack deformation, box lids, gripper contacts, and moving bricks.
However, a generic video world model is usually text-conditioned, not robot-action-conditioned. RISE adds a lightweight action encoder and fine-tunes the model on large robot datasets with action labels, including Galaxea Open World and AgiBot World Alpha. The official docs state that the dynamics model expects LeRobot-format data, recommends resizing each view to 256x192, and uses three views: one head or top view and two wrist views.
One useful training trick is Task-Centric Batching. When training a world model on many robot tasks, a highly diverse batch can be unstable: scenes, objects, camera poses, and actions all change at once. RISE samples a batch from a smaller fraction of tasks while covering more action diversity within the same scene context. In plain terms, the model gets a clearer signal about how different actions change the same situation.
3. Progress Value Model
Manipulation tasks often have sparse rewards: at the end of the episode you know success or failure, but you do not know which earlier action caused the problem. Backpack packing and box closing contain many intermediate milestones: orienting the object correctly, placing it into the backpack, avoiding over-pulling, aligning a lid, or keeping an object stable.
RISE trains a Progress Value Model to assign a scalar value to observations or imagined observations. The value model is also parameterized from the π0.5 VLA backbone. This is a sensible choice because the backbone already has robot-centric visual knowledge and supports multi-view inputs. The paper reports about 50k value-model training steps: the first 10k use only progress estimation loss, then the remaining 40k add Temporal Difference learning. The reported discount factor is 0.995.
4. The self-improving loop
After warm-up, RISE repeatedly generates imagined rollouts and updates the policy:
for update in range(num_updates):
obs = sample_offline_or_recent_state()
action_chunk = rollout_policy(obs, instruction, target_advantage=1.0)
imagined_future = dynamics_model.predict(
current_images=obs.images,
action_tokens=action_chunk,
language=instruction,
)
value_now = value_model(obs)
value_future = value_model(imagined_future)
advantage = value_future - value_now
train_policy(
observation=obs,
action=action_chunk,
advantage=advantage,
)
This pseudo-code simplifies the full method, but it captures the useful mental model. RISE does not need to simulate all the way to a terminal state. It produces chunk-wise advantages for proposed action chunks. That matters because video world models become less reliable as rollout horizon increases.
Installing the repository
The official repository has released training code and a pretrained dynamics model. The README also notes a June 3, 2026 bug-fix update, so users should rely on the latest code. The base installation follows the docs:
conda create -n rise python=3.11.14 -y
conda activate rise
cd /path/to/RISE
bash install.sh
The training pipeline expects LeRobot-format data. If you collect raw Piper data as HDF5, the repo provides a converter:
cd /path/to/RISE/policy_and_value/policy_offline_and_value
python examples/aloha_real/convert_to_lerobot.py \
--data-dir /path/to/raw_dataset \
--repo-ids aloha_mobile_dummy \
--prompt "Pick and sort bricks on the conveyor." \
--save-dir /path/to/lerobot_output_root \
--save_repoid brick_sorting
The expected converted layout is:
brick_sorting/
├── data/chunk-000/episode_*.parquet
├── meta/
│ ├── info.json
│ ├── episodes.jsonl
│ ├── episodes_stats.jsonl
│ └── tasks.jsonl
└── videos/chunk-000/*.mp4
For the dynamics model, the docs recommend preprocessing videos to 256x192:
cd RISE/dynamics/dynamics_model
./preprocess.sh brick_sorting
Training the components
Offline policy and value model
From policy_and_value/policy_offline_and_value, the release registers Policy_offline_release, value_release, and Compute_norm.
python scripts/compute_norm_stats_fast.py --config-name Compute_norm
bash train.sh Policy_offline_release 8
bash train.sh value_release 8
After training the value model, you label value and advantage for LeRobot datasets:
bash label_value.sh vis_value_release_joint_T \
/path/to/checkpoints/value_release_joint/<exp>/<step>
This is not a cosmetic step. RISE uses advantage conditioning for both offline and online policy improvement. If the value labels are poor, the policy receives a weak or misleading signal about which actions are worth imitating.
Dynamics model
The dynamics model has two training phases:
| Phase | Data | Compute reported in the paper | Goal |
|---|---|---|---|
| Pre-training | Galaxea + AgiBot World Alpha | 16 NVIDIA H100, batch 512, about 7 days | Learn general robot dynamics priors |
| Task fine-tuning | Task-specific LeRobot data | 8 NVIDIA H100, batch 64, about 3 days | Adapt to the task domain, cameras, objects, and actions |
The main repository commands are:
cd RISE/dynamics/dynamics_model
# download LTX backbone components and related checkpoints
./download.sh
# pre-train, if you have enough data and compute
bash train_task_centric.sh
# fine-tune for a target task
python norm.py --datasets brick_sorting --save-config data/utils/action_norm.json
bash task_finetune.sh
For beginners, the practical lesson is that RISE is not a laptop-scale training recipe. It is a research system designed for large GPU clusters. You can still study the architecture, data format, and module inference, but reproducing the full paper results requires compute close to what the paper reports.
Online RL in imagination
Online training lives under policy_and_value/policy_online. The docs start training with an embodiment script:
bash policy_and_value/policy_online/examples/embodiment/run_embodiment.sh rl_release
Important config fields include:
| Config | Meaning |
|---|---|
rollout.model_dir |
IL policy checkpoint used for initialization |
dynamics_model_config |
dynamics model config |
reward_model_config |
value/reward model config |
reward_model_ckpt |
value model checkpoint |
algorithm.num_group_envs |
number of parallel rollout environments |
chunk_reward |
use the reward of the last predicted frame for the action chunk |
advantage_scale |
scaling coefficient for computed advantage |
The repo supports GPU placement for env, rollout, and actor. A partial-sharing setup looks like:
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout: 4-7
actor: 0-7
Real-robot inference
One of the most important deployment details is simple: the world model is not used during real-robot inference. The dynamics model and value model are training-time tools. At deployment, the real robot runs only the improved policy.
The deployment docs target AgileX Piper dual-arm robots, Ubuntu 20.04, ROS Noetic, and RealSense cameras:
# Terminal 1: cameras
roslaunch realsense2_camera multi_camera.launch
# Terminal 2: robot arms
bash deploy/Piper_ros_private-ros-noetic/can_config.sh
roslaunch piper start_ms_piper.launch mode:=1 auto_enable:=true
# Terminal 3: inference
conda activate deploy
python deploy/piper_deploy.py \
--host 172.16.99.11 \
--port 8000 \
--ctrl_type joint \
--use_temporal_smoothing \
--chunk_size 50 \
--lang_embeddings "Pick and sort bricks on the conveyor."
Before deployment, a distributed .dcp checkpoint needs to be converted to a PyTorch state dict:
python toolkits/ckpt_convertor/convert_dcp_to_state_dict.py \
--dcp_path <YOUR_DCP_CKPT_DIR> \
--output_path <YOUR_EXPECTED_PT_CKPT_DIR>
In the paper's setup, the robot is a dual 7-DoF AgileX system with absolute joint control. The appendix describes each arm as 6 DoF plus a 1-DoF gripper, with wrist-mounted cameras and a top-down camera about 0.75 m above the workspace. The control frequency is 30 Hz.
Experimental results
RISE is evaluated on three real-world tasks:
| Task | Why it is hard |
|---|---|
| Dynamic Brick Sorting | A conveyor belt introduces dynamics; the robot must grasp and sort by color |
| Backpack Packing | Soft and compliant objects can deform, jam, or move unpredictably |
| Box Closing | Requires precise bimanual coordination |
The main result table from the paper reports:
| Method | Brick success | Brick score | Backpack success | Backpack score | Box success | Box score |
|---|---|---|---|---|---|---|
| π0.5 | 35% | 8.28 | 30% | 4.25 | 35% | 7.50 |
| π0.5 + DAgger | 15% | 6.10 | 50% | 7.00 | 40% | 7.50 |
| π0.5 + PPO | 10% | 7.68 | 35% | 5.88 | 10% | 4.75 |
| π0.5 + DSRL | 10% | 6.65 | 10% | 3.50 | 10% | 7.63 |
| RECAP | 50% | 9.00 | 40% | 6.13 | 60% | 8.13 |
| RISE | 85% | 9.78 | 85% | 9.50 | 95% | 9.88 |
The table is instructive because direct RL baselines do not automatically win. On Dynamic Brick Sorting, the base π0.5 policy reaches 35% success, while π0.5 + PPO drops to 10%. That is a familiar real-world RL failure mode: exploration and unstable updates can degrade a previously useful policy.
RISE improves because it combines three signals: a strong pretrained policy, a fast action-conditioned world model that can generate imagined rollouts, and a progress value model that converts imagined outcomes into advantage. Compared with RECAP, RISE is not limited to offline advantage labels; it keeps producing online training data in imagination.
Limitations and practical reading
RISE does not prove that world models can replace physics simulators in all robotics settings. A video world model can still fail on rare contact dynamics, complex deformation, unusual object states, or out-of-distribution camera views. If the dynamics model imagines the wrong future and the value model scores it too optimistically, the policy can learn the wrong behavior. The paper mitigates this through short action chunks, offline data mixing, EMA rollout policies, task-specific fine-tuning, and the decision to remove the world model from real-robot inference.
The second limitation is compute. Full dynamics pre-training uses 16 H100 GPUs for about a week, and task fine-tuning and value training also require serious hardware. For a small lab, the right takeaway is not necessarily "copy RISE end to end." The more reusable recipe is:
- Start from a capable VLA or imitation policy.
- Collect successes and failures, not only expert demonstrations.
- Train a progress/value model instead of relying only on terminal success.
- Use an action-conditioned world model to generate candidate futures.
- Deploy only the improved policy when latency and robustness matter.
For teams working with LeRobot or OpenPI, RISE is a strong blueprint for the step after imitation learning. It sits between real-robot VLA RL and a classical sim-to-real pipeline: not pure physical simulation, not pure real-world RL, but RL inside a learned imagination environment.
Sources
- Paper: RISE: Self-Improving Robot Policy with Compositional World Model
- Project page: opendrivelab.com/RISE
- Code: github.com/OpenDriveLab/RISE
- Dynamics docs: RISE dynamics_model.md
- Deployment docs: RISE deploy.md