Between 2024 and 2025, the Vision-Language-Action (VLA) wave swept through robotics research: π₀, OpenVLA, RoboVLMs, ACT… These models were trained on tens of millions of robot video frames, learning to generate actions directly from RGB images. Benchmark numbers looked impressive, demos went viral on X/Twitter — but when deployed in real, messy environments (cluttered tables, different lighting, partially occluded objects), they failed in characteristic ways.
The question is: is there something fundamentally missing in 2D RGB that makes manipulation hard? The short answer is yes — and that something is 3D geometry. This 7-part series is a journey from the fundamental limitations of 2D perception, through the most advanced 3D-aware manipulation methods (Robo3R, DP3, Omni-Manip, WholeBodyVLA…), to a practical deployment roadmap on Unitree G1.
Series Roadmap
| Article | Topic | Key Content |
|---|---|---|
| Article 1 (this one) | Why 2D is not enough | Motivation, 5 core limitations, big picture |
| Article 2 | Robo3R — 3D from RGB | Feed-forward 3D reconstruction without depth sensors |
| Article 3 | DP3 — 3D Diffusion Policy | Point cloud + diffusion for visuomotor policy |
| Article 4 | Omni-Manip — Spatial 3D | Omnidirectional 3D perception for large-workspace humanoids |
| Article 5 | WholeBodyVLA + RL | Whole-body loco-manipulation with latent VLA and RL |
| Article 6 | 3D Data Collection | HuMI, robot-free demos, data scaling strategy |
| Article 7 | Unitree G1 Roadmap | From paper to real robot: practical deployment pipeline |
1. The Robot Is Looking Through a Pinhole — And That Hole Is 2D
Imagine closing one eye and trying to grab a cup on your desk. You can still do it — the human brain is surprisingly good at estimating depth from monocular cues: perspective, shadows, texture gradients, prior knowledge of object sizes. But what if you had to do this in a completely featureless room (no shadows, no textures), had no idea how big the cup actually was, and your hand had no sense of touch? You would fail.
That is precisely the situation of a robot running a VLA policy trained on 2D RGB images.
A 2D camera projects the 3D world onto a 2D plane through perspective projection. This projection is many-to-one: infinitely many different 3D configurations produce the same 2D image. The information lost in this projection cannot be fully recovered from a single image alone.
2. Five Fatal Weaknesses of 2D RGB
2.1 Depth Ambiguity
Consider the basic perspective projection: a 3D point (X, Y, Z) maps to pixel (x, y) = (fX/Z, fY/Z) where f is the focal length. Notice that the point (2X, 2Y, 2Z) maps to exactly the same pixel — because 2f(2X)/(2Z) = fX/Z.
In other words: a small chess piece placed nearby and a large chess piece placed far away can produce identical pixel sizes. A policy trained on 2D cannot distinguish between these cases.
For robot manipulation, this means: "How wide should I open my gripper?" — the answer depends on the object's actual metric size, not its pixel size. The 2D policy has to guess, and when deployed on objects of different actual sizes, it will fail.
2.2 Occlusion
Real-world manipulation always happens in cluttered scenes: objects hiding other objects, the robot's own arm occluding targets, boxes stacked on boxes. A 2D camera only sees visible surfaces — it cannot see behind or underneath anything.
Consider Unitree G1 trying to pick up a water bottle that is half-hidden behind a cardboard box. A 2D policy trained on clear views of bottles may not know what to do when the bottle is partially occluded — because the image looks completely different. With a 3D point cloud, however, the robot "sees" the part of the bottle sticking out from behind the box and can infer its full position.
Occlusion is even more severe with self-occlusion from the robot's own hand: when the hand is grasping an object, it occludes that very object from the camera. The 2D policy must "imagine" where the object continues to exist behind the hand — a hard learning problem.
2.3 Lack of Metric Scale
2D images are fundamentally scale-invariant: a photo of a 5cm pebble on a desk and a 5m boulder outdoors can look identical if you position them at corresponding distances.
Deep learning features (CNN, ViT) are explicitly designed to be scale-invariant — this is great for recognition (a cat is a cat regardless of size) but catastrophic for manipulation (squeezing an egg gently vs. gripping a metal box requires very different forces).
Without metric scale, a policy cannot know:
- How long a trajectory must be to actually reach the target (in cm)
- How wide to open the gripper
- How much force to apply (force control)
- How to transfer cleanly between different camera setups
2.4 No Geometry in Robot Frame
To execute manipulation, a robot needs to know the target's coordinates in its own robot frame (or at least in world frame). A 2D policy learns a pixel → action mapping — and this mapping is entirely dependent on:
- Camera position
- Camera viewing angle
- Camera focal length and intrinsics
If you train on one camera setup and deploy with a camera shifted by just 5cm, the pixel → action mapping breaks completely. This is why robot manipulation systems require expensive re-calibration when any hardware changes.
3D-aware policies, by contrast, learn in canonical 3D space — a space that remains consistent when the camera moves (as long as you know the camera extrinsics). This is why DP3 (Article 3) generalizes dramatically better to new viewpoints.
2.5 Collision Avoidance Is Impossible from Pixels Alone
When a robot needs to move its arm from point A to point B without hitting scene objects, the motion planner needs the 3D geometry of the entire scene: what 3D volume does each object occupy?
From 2D images, you can segment which pixels belong to which object — but you cannot know how thick that object is along the viewing direction. This makes collision-free trajectory planning nearly impossible from pure 2D.
Practical example: AgiBot X2 executing "retrieve a box from the lower cabinet shelf" must thread its arm through a narrow gap. A 2D policy cannot know how wide the gap is in metric units, how thick the robot arm is, and which trajectory is safe. With a 3D point cloud, this becomes a standard planning problem.
3. Empirical Evidence: How Much Does 3D Help?
"Point Cloud Matters" (NeurIPS 2024, arXiv:2402.02500) is the most comprehensive benchmark on this question. Across 125 tasks on 2 simulators, with standardized encoders and policy baselines, they compared 3 observation types: RGB, RGB-D, and Point Cloud.
The result? Point cloud wins consistently — even with the simplest possible design. The gap is especially pronounced on:
- Geometric generalization: same object category but different shapes
- Viewpoint generalization: different camera angle at deployment time
- Contact-rich tasks: requiring precise knowledge of object geometry
Average success rate (Point Cloud Matters, NeurIPS 2024):
┌─────────────────────┬───────────────┬───────────────┬──────────────┐
│ Observation type │ Base tasks │ Geo. var. │ View. var. │
├─────────────────────┼───────────────┼───────────────┼──────────────┤
│ RGB only │ ██████ 52% │ ███ 31% │ ████ 38% │
│ RGB-D │ ███████ 61% │ █████ 48% │ █████ 47% │
│ Point Cloud │ █████████ 78%│ ████████ 69% │ ███████ 64%│
└─────────────────────┴───────────────┴───────────────┴──────────────┘
(Illustrative numbers — see the paper for exact figures)
The implication is stark: when deploying outside the training environment, 2D policies degrade far faster than 3D policies.
4. The New Wave: 3D-Aware Manipulation
So what are the solutions? Three converging approaches define the 2025–2026 frontier:
4.1 Point Cloud Policies
Instead of RGB pixels, the robot receives a point cloud — a set of 3D points (x, y, z) in space — from a depth sensor (LiDAR, depth camera). Each point carries real metric coordinates, unaffected by camera viewpoint.
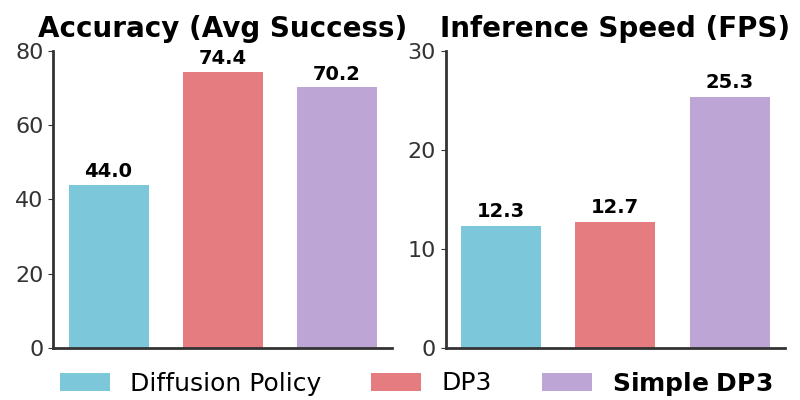
3D Diffusion Policy (DP3) (arXiv:2403.03954) is the strongest demonstration: 85% success rate on real-robot tasks with only 40 demonstrations per task — a number that 2D policies need hundreds of demos to match.
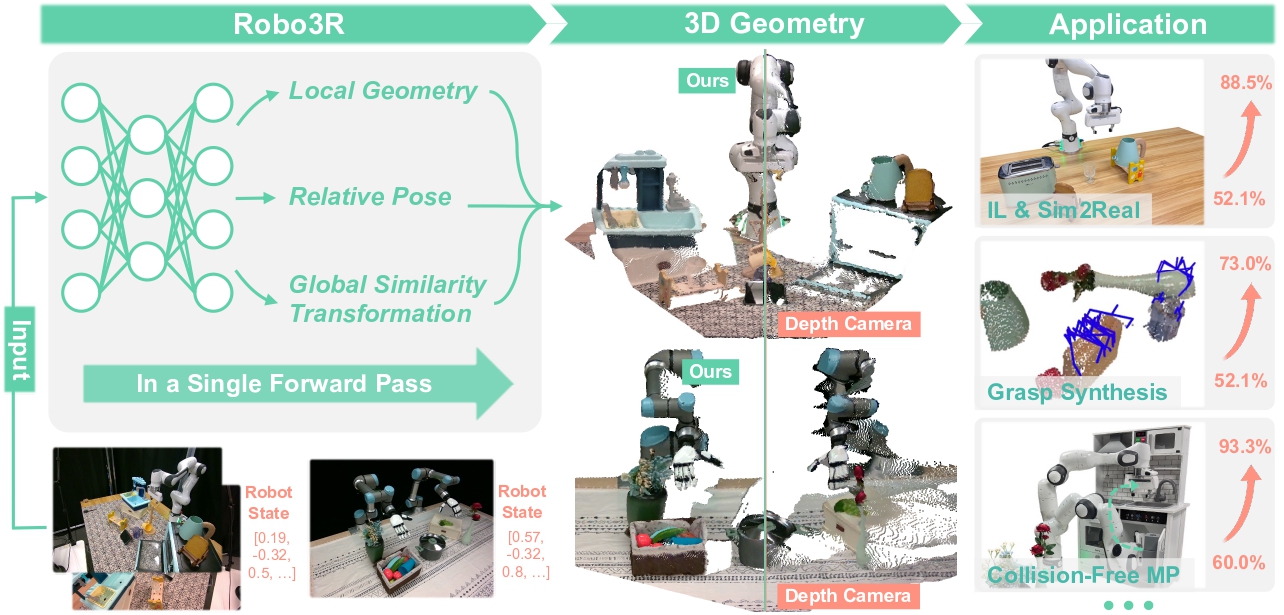
4.2 Feed-Forward 3D Reconstruction
What if you don't have a depth sensor? The latest approach is predicting 3D geometry from RGB in a single forward pass — no iterative optimization, no complex calibration.
Robo3R (arXiv:2602.10101, RSS 2026) builds a feed-forward model that takes RGB images + robot state as input and outputs an accurate metric-scale point cloud. The key: Robo3R was trained on Robo3R-4M — 4 million synthetic frames with full 3D annotation.
Robo3R predicts metric-scale point clouds from RGB without depth sensors — source: yangsizhe.github.io/robo3r
4.3 Canonical Robot-Frame 3D and Spatial Constraints
The third direction uses 3D not just for perception but for planning and control. Omni-Manip (arXiv:2603.05355) uses a 360° LiDAR (Livox MID-360) with Time-Aware Attention Pooling to process omnidirectional point clouds, enabling humanoids to manipulate objects outside the camera's field of view.
OmniManip (arXiv:2501.03841, CVPR 2025 Highlight) takes an object-centric approach: defining a canonical space for each object based on functional affordances, then using 6D pose tracking for closed-loop control.
5. The Big Picture: Papers That Define This Series
Six papers will be analyzed in depth across the remaining articles. Here is a quick preview:
Robo3R (RSS 2026)
"Enhancing Robotic Manipulation with Accurate Feed-Forward 3D Reconstruction" arXiv:2602.10101
Problem solved: how do you get accurate 3D from RGB without a depth sensor? Solution: a feed-forward model trained on 4M synthetic frames, predicting metric-scale point clouds. Result: consistent improvement across imitation learning, sim-to-real transfer, grasp synthesis, and collision-free planning.
DP3 — 3D Diffusion Policy (RSS 2024)
"Generalizable Visuomotor Policy Learning via Simple 3D Representations" arXiv:2403.03954
Combines point cloud with diffusion model — simple but extremely effective. 85% success rate with 40 demos. More importantly: generalizes far better to new viewpoints, new objects, and new instances. The improved version (iDP3) extends this to humanoid manipulation.
Omni-Manip (2026)
"Beyond-FOV Large-Workspace Humanoid Manipulation with Omnidirectional 3D Perception" arXiv:2603.05355
Uses 360° LiDAR instead of cameras for omnidirectional point clouds. Enables Fourier GR to perform tasks in large workspaces, even when objects are outside the camera's field of view. 82/120 successful tasks vs. 2D baselines achieving only 18–25/120.
WholeBodyVLA (ICLR 2026)
"Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control" arXiv:2512.11047
A unified VLA framework for loco-manipulation: learns a Latent Action Model from egocentric video without action annotations, then decodes into dual-arm joint actions + locomotion commands. Demonstrated on AgiBot X2 with tasks including pushing carts with >50kg loads.

HuMI — Humanoid Manipulation Interface (2026)
"Humanoid Whole-Body Manipulation from Robot-Free Demonstrations" arXiv:2602.06643
Solves the data collection problem: instead of using the robot itself for demonstrations, uses a portable capture device worn by a human to record full-body motion (not just hands). 3x more efficient than teleoperation. 70% success rate in unseen environments.
SPEAR-1 (CVPR 2026)
"Scaling Beyond Robot Demonstrations via 3D Understanding" arXiv:2511.17411
A robot foundation model integrating 3D perception with language-instructed control. The key innovation: requires only 1/20th of the robot data compared to other SOTA models by leveraging non-robot data with 3D annotations (EgoExo-4D). Europe's first open robotic foundation model competitive with π₀.
6. Unitree G1, AgiBot X2, Fourier GR — The Platforms Behind This Series
This series uses Unitree G1 as the running example because it is currently the most accessible humanoid platform for the open-source research community. With 43 DOF total (7-DOF dual arms, 6-DOF legs), the G1 is an ideal testbed for whole-body manipulation research.
Beyond G1, you will also encounter:
- AgiBot X2: the primary platform for WholeBodyVLA and OmniManip, a bimanual humanoid with strong locomotion capability
- Fourier GR-1/GR-2: used in Omni-Manip and multiple other papers, representative of the new generation of Asian humanoid platforms
Why not Boston Dynamics Atlas or Tesla Optimus? Because they are not open-source and not accessible to independent researchers. Unitree G1 (around $16,000) was the first humanoid to put a capable bipedal platform in the hands of small labs.
7. Why Now? Why 2025–2026?
Three technology streams converged at the same time:
Stream 1: Diffusion models matured. Diffusion Policy (2023) proved that action generation can be learned from data in a clean, generalizable way. DP3 extended this to 3D input.
Stream 2: Feed-forward 3D models. Models like DUSt3R, MASt3R, and MonST3R (2024) demonstrated that 3D reconstruction can be fast and accurate in a single forward pass. Robo3R brought this paradigm to manipulation.
Stream 3: LLM/VLMs for planning. GPT-4V, PaLM-E, and modern VLMs became capable enough to understand scenes and plan at the language level. When combined with 3D perception → 3D-aware VLA.
These three streams together created a window of opportunity to solve manipulation in a way that was not possible before. That is why all six papers in this series appeared in the narrow window of 2024–2026.
Conclusion: 3D Is Not Optional
If you are building a robot manipulation system and thinking "RGB camera is enough," ask yourself: "Does my task require knowing actual distances, occluded regions, or the 3D geometry of the scene?" For the vast majority of real-world manipulation — the answer is yes.
2D RGB policies work fine in controlled environments with good lighting, fixed cameras, and simple tasks. But as you scale up — more objects, more tasks, varied environments — the fundamental limits of 2D become unavoidable.
This series will walk through each solution step by step. Article 2 is next, dissecting Robo3R — how they built a feed-forward 3D reconstruction system that needs no depth sensor, and why this changes the game. If you work in robot manipulation or are interested in foundation models for robotics, this is not something you want to skip.


