Ở bài 1 của series, chúng ta đã thấy tại sao ảnh RGB 2D không đủ để robot arm thực hiện manipulation đáng tin cậy: depth ambiguity, thiếu metric scale, không biết object nằm ở đâu trong không gian thực. Câu hỏi tiếp theo đặt ra tự nhiên: làm sao để robot "thấy" được hình học 3D từ camera RGB thông thường, trong thời gian thực, đủ chính xác cho manipulation?
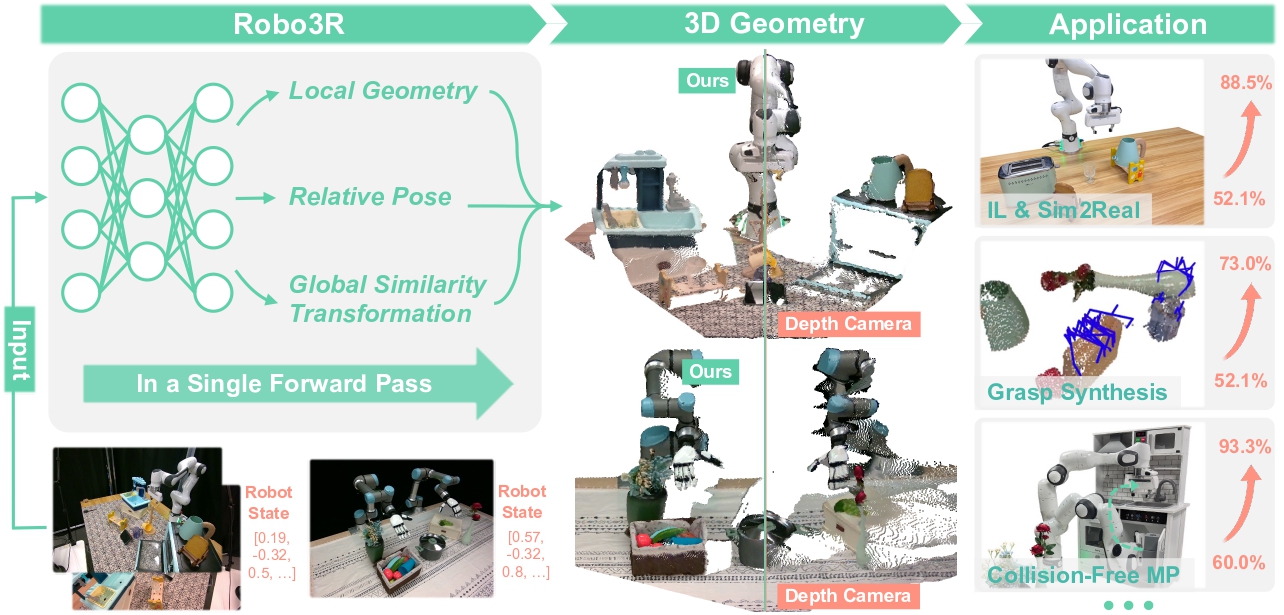
Bài này phân tích Robo3R — một phương pháp feed-forward 3D reconstruction được công bố tại RSS 2026 — và lý giải tại sao nó đang thay đổi cách chúng ta xây dựng pipeline perception cho robot arm.
Robo3R là gì và tại sao nó khác
Robo3R là viết tắt của Robot 3D Reconstruction, một model được thiết kế để giải một bài toán cụ thể: từ ảnh RGB (một hoặc hai camera) và trạng thái robot hiện tại, dựng lên hình học 3D metric-scale của cảnh vật trong robot frame — trong thời gian thực.
Paper: Robo3R: Enhancing Robotic Manipulation with Accurate Feed-Forward 3D Reconstruction — Sizhe Yang, Linning Xu, Hao Li, Juncheng Mu, Jia Zeng, Dahua Lin, Jiangmiao Pang — RSS 2026, Shanghai AI Laboratory / CUHK / USTC / Tsinghua.
Điều quan trọng nhất cần hiểu ngay từ đầu: Robo3R không phải SLAM, không phải NeRF, không phải multi-view stereo truyền thống. Đây là một mô hình feed-forward — tức là nó chạy một lần qua mạng neural và ra luôn kết quả, không có vòng lặp tối ưu hóa nào.
Tốc độ thực tế
- 43.5 Hz với single-view (monocular)
- 18.7 Hz với binocular (stereo)
Đủ để chạy trong control loop của robot arm (thường 20–50 Hz).
Tại sao SLAM và multi-view truyền thống không đủ?
Trước khi đi vào Robo3R, hãy hiểu tại sao các phương pháp cũ gặp khó khăn trong robot manipulation:
| Phương pháp | Vấn đề với manipulation |
|---|---|
| SLAM (ORB-SLAM, LIO-SAM) | Drift tích lũy theo thời gian; cần chuyển động camera đủ parallax; không ra metric scale từ monocular |
| Multi-view stereo (COLMAP) | Offline, không real-time; cần nhiều ảnh chụp từ góc độ khác nhau; không thể chạy trong control loop |
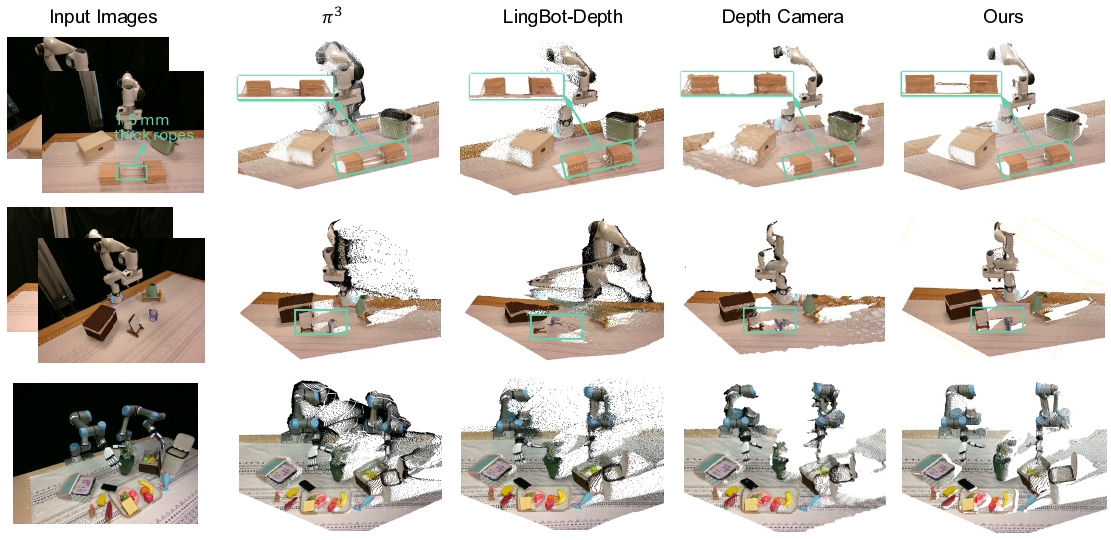
| Depth camera (RealSense, Azure Kinect) | Không hoạt động với vật thể trong suốt (kính, chai), phản chiếu (kim loại), hoặc rất mỏng (<5mm); ảnh hưởng bởi ánh sáng mạnh |
| Monocular depth estimation (MiDaS, Depth Anything) | Cho ra depth scale-relative, không phải metric — robot không biết vật nằm cách tay bao nhiêu cm thực tế |
Ví dụ thực tế: Unitree G1 cần chèn vít vào lỗ 2mm. Với depth camera, sai số đo lường ở vật nhỏ và mỏng có thể lên đến 5–10mm — nhiều hơn cả đường kính lỗ. Monocular depth estimation cho ra giá trị tương đối, không biết đó là 3cm hay 30cm. Cả hai đều thất bại ở task này.
Feed-forward 3D Reconstruction: cơ chế hoạt động
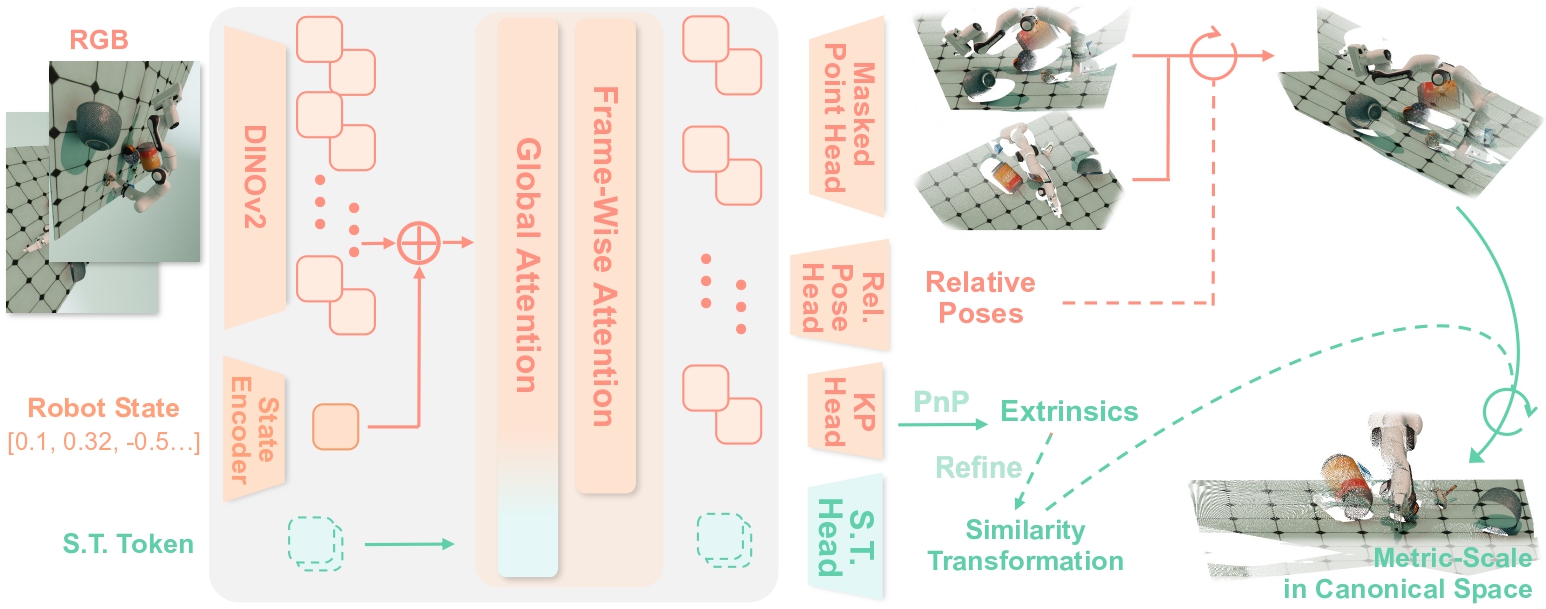
Robo3R được thiết kế với 4 thành phần chính, chạy tuần tự như một pipeline feed-forward:
1. Backbone transformer với alternating attention
Đầu vào: ảnh RGB từ một hoặc nhiều camera + robot state (joint angles, end-effector pose).
Model dùng transformer backbone với cơ chế alternating attention — xen kẽ giữa:
- Global attention: nhìn toàn bộ ảnh để hiểu context
- Frame-wise attention: tập trung vào từng frame riêng lẻ để trích đặc trưng cục bộ
Thiết kế này cho phép model vừa hiểu scene tổng thể, vừa giữ được chi tiết cục bộ quan trọng cho manipulation (cạnh vật thể, keypoint grasping).
2. Đồng thời ước tính local geometry + camera pose
Đây là điểm khác biệt quan trọng: Robo3R đồng thời (jointly) ước tính:
- Scale-invariant local geometry: hình dạng bề mặt, pháp tuyến, depth tương đối của từng điểm
- Relative camera poses: camera đang ở đâu so với nhau (với multi-view) hoặc so với robot base
Trong SLAM truyền thống, hai bước này thường tách rời và phụ thuộc vào nhau theo vòng tuần hoàn. Robo3R học cả hai cùng lúc trong một forward pass.
3. Global alignment vào Robot Frame
Sau khi có local geometry từ nhiều frame, model thực hiện learned global similarity transformation để:
- Đưa tất cả geometry về một hệ tọa độ thống nhất
- Canonical robot frame: hệ tọa độ gắn với base của robot (giống như
/base_linktrong ROS) - Quan trọng: transformation này học được từ dữ liệu, không phải calibration thủ công
Kết quả: một point cloud 3D trong robot frame, sẵn sàng cho collision checking, grasp planning, và policy input.
4. Masked Point Head — chi tiết quan trọng nhất

Để xử lý vật thể nhỏ và mỏng (thách thức lớn nhất của depth sensor), Robo3R dùng masked point head — một prediction head đặc biệt phân tách đầu ra thành 3 thành phần:
Mỗi pixel → [depth d, normalized coordinates (nx, ny), mask m]
↓
d × [nx, ny, 1] → 3D point trong local frame
mask m → phân biệt foreground (vật thể) vs background
Sau đó dùng keypoint-based PnP (Perspective-n-Point) để refine camera extrinsics và global alignment, giúp tăng độ chính xác đặc biệt ở vật thể nhỏ.
Canonical Robot Frame là gì và tại sao quan trọng?
Đây là khái niệm trung tâm của Robo3R mà người mới hay bỏ qua.
Vấn đề với "world frame" tùy ý
Khi robot di chuyển, camera gắn trên tay robot cũng di chuyển theo. Nếu bạn xây dựng 3D map trong "camera frame" hay "world frame" tùy ý, mỗi lần robot di chuyển, bạn phải transform lại toàn bộ map. Với manipulation, điều này phức tạp vì end-effector cần biết vị trí vật thể tương đối với chính nó, không phải với thế giới bên ngoài.
Canonical Robot Frame
Canonical robot frame là hệ tọa độ cố định tại base của robot:
- Gốc tọa độ: trung tâm robot base (hoặc
/base_link) - Trục Z: hướng lên
- Trục X: hướng về phía trước robot
- Không đổi khi gripper hay arm di chuyển
Khi Robo3R tái dựng 3D scene trong canonical robot frame, policy học được có thể:
- Trực tiếp dùng tọa độ 3D để tính toán gripper trajectory
- Không cần transform phức tạp giữa camera frame và robot frame
- So sánh vị trí vật thể với robot kinematic state một cách trực tiếp
Hãy hình dung đây giống như bạn luôn nhìn bản đồ theo hướng Bắc, không quay bản đồ theo chiều bạn đang nhìn — mọi tọa độ luôn nhất quán, dễ tính toán.
Metric Scale — tại sao 0.007 lại quan trọng?
Robo3R đạt scale error 0.007 (sai số tỷ lệ mét). So sánh với các phương pháp khác thường có scale error > 0.46.
Ý nghĩa thực tế: với distance 30cm, sai số 0.007 tương đương ~2mm — trong phạm vi chấp nhận được cho nhiều task manipulation. Scale error 0.46 tương đương ~14cm — vô dụng cho grasping chính xác.
scale_error = |d_predicted - d_ground_truth| / d_ground_truth
Robo3R: 0.007 → với d=30cm, sai số ≈ 2mm ✓
Competitors: 0.46+ → với d=30cm, sai số ≈ 14cm ✗
Robo3R-4M: dataset đằng sau model
Model không thể học metric scale từ không khí — nó cần dữ liệu synthetic với ground truth 3D. Nhóm tác giả xây dựng Robo3R-4M:
| Thông số | Giá trị |
|---|---|
| Tổng frames | 4 triệu |
| Số scenes | 120,000 |
| Object assets | 16,911 (DTC + Objaverse) |
| Textures | 4,710 |
| Environment maps | 6,512 (ánh sáng đa dạng) |
| Robot | Franka FR3 (NVIDIA Isaac Sim) |
| Modalities | RGB, depth, semantic masks, robot states, camera intrinsics/extrinsics |
Hai subset:
- 100k scenes: vật thể đặt ngẫu nhiên trên bàn (scene tổng quát)
- 20k scenes: một vật thể được gripper cầm, các vật khác trên bàn (grasping scenarios)
Điều làm dataset này đặc biệt: đa dạng về object material — bao gồm cả vật trong suốt, phản chiếu, và hình dạng mỏng — những thứ depth camera thực tế không xử lý được.
Kết quả: số liệu thực tế
Imitation Learning (16 trials/task)
| Task | Robo3R | Depth Camera | Cải thiện |
|---|---|---|---|
| Sweep Bean | 14/16 (87.5%) | 4/16 (25%) | +62.5% |
| Insert Screw | 15/16 (93.8%) | 7/16 (43.8%) | +50% |
| Breakfast | 12/16 (75%) | 11/16 (68.8%) | +6.2% |
| BiDex Pour | 16/16 (100%) | 16/16 (100%) | 0% |
Insert Screw là task khắc nghiệt nhất: lỗ 2mm, cần độ chính xác dưới milimet. Robo3R đạt 93.8% vs depth camera chỉ 43.8% — gần như gấp đôi.
Sim-to-Real Transfer
| Task | Robo3R | Depth Camera |
|---|---|---|
| Push Cube | 16/16 (100%) | 7/16 (43.8%) |
| Pick Cube | 12/16 (75%) | 5/16 (31.3%) |
Cải thiện trong sim2real đặc biệt ấn tượng vì depth camera chịu ảnh hưởng của domain gap (ánh sáng, noise pattern khác nhau giữa sim và real). Robo3R, học từ RGB, ít bị ảnh hưởng bởi sensor noise hơn.
Collision-Free Motion Planning (vật thể mỏng)
| Method | Success (5 trials) |
|---|---|
| Robo3R | 5/5 (100%) |
| Depth Camera | 2/5 (40%) |
Depth camera bỏ sót điểm trên bề mặt mỏng — robot va chạm vật thể. Robo3R dựng được point cloud đầy đủ ngay cả với vật mỏng ~1.5mm.
Kết nối với SPEAR-1: khi 3D perception gặp VLA
Robo3R giải quyết bài toán perception — làm sao dựng 3D từ RGB. Nhưng câu hỏi tiếp theo là: 3D perception này giúp ích gì cho policy/VLA learning?
Câu trả lời đến từ SPEAR-1 (Scaling Beyond Robot Demonstrations via 3D Understanding):
Paper: SPEAR-1: Scaling Beyond Robot Demonstrations via 3D Understanding — Nikolay Nikolov et al. — CVPR 2026, INSAIT Sofia University.
SPEAR-1 cho thấy: nếu bạn pretrain VLM với khả năng 3D understanding (ước tính bounding box 3D, khoảng cách object, quan hệ spatial) trước khi fine-tune thành VLA, model học manipulation hiệu quả hơn rất nhiều:
- 20× ít dữ liệu robot hơn so với π0.5 để đạt cùng performance
- 57.3% success rate trên SIMPLER benchmark so với SpatialVLA 42.7% và OpenVLA 1.0%
- Hoạt động zero-shot trong môi trường chưa thấy bao giờ
Cơ chế: SPEAR-1 mở rộng PaliGemma (SigLIP + Gemma) bằng MoGe monocular depth encoder và 1,024 specialized 3D tokens, cho phép model reason về không gian 3D trực tiếp trong ngôn ngữ.
Điểm chung giữa Robo3R và SPEAR-1
Cả hai đều khẳng định một nguyên lý: 3D understanding là foundation không thể thiếu cho manipulation policy.
- Robo3R: cung cấp 3D geometry chính xác cho policy input (point cloud trong robot frame)
- SPEAR-1: tích hợp 3D understanding vào bản thân VLM/VLA backbone
Hai hướng tiếp cận bổ sung cho nhau — bạn có thể dùng Robo3R để tái dựng scene, rồi dùng SPEAR-1 style VLA để ra action.
Pipeline thực tế: Robo3R trong robot manipulation system
Với Unitree G1 hoặc robot arm bất kỳ, đây là cách Robo3R fit vào hệ thống:
┌─────────────────────────────────────────────────────┐
│ PERCEPTION LAYER │
│ │
│ RGB Camera(s) ──┐ │
│ Robot State ──┤──► Robo3R ──► Point Cloud 3D │
│ (joint angles) ──┘ (canonical frame) │
└──────────────────────────┬──────────────────────────┘
│
┌──────▼──────┐
│ USAGE │
└──────┬──────┘
┌────────────────┼────────────────┐
▼ ▼ ▼
Imitation Grasp Planning Collision-Free
Learning (GraspNet, Motion Planning
(DP3, ACT) AnyGrasp) (MoveIt2)
Cách Robo3R thay thế depth sensor trong pipeline
Trước Robo3R:
# Pipeline cũ — phụ thuộc depth camera
rgb_image = camera.get_rgb()
depth_map = depth_camera.get_depth() # thất bại với vật trong suốt
point_cloud = backproject(rgb_image, depth_map, intrinsics)
point_cloud_robot = transform(point_cloud, camera_to_robot_tf)
Với Robo3R:
# Pipeline mới — chỉ cần RGB + robot state
rgb_image = camera.get_rgb()
robot_state = robot.get_joint_angles()
point_cloud_robot = robo3r.infer(rgb_image, robot_state)
# point_cloud_robot đã ở canonical robot frame, metric-scale
# Không cần depth camera, không cần camera-robot calibration phức tạp
Limitations và những gì chưa giải quyết được
Robo3R không phải silver bullet. Một số hạn chế cần biết:
-
Trained với Franka FR3: Dataset chủ yếu dùng Franka. Với robot khác (Unitree G1, UR5, KUKA), cần fine-tune hoặc re-generate data tương đương. Robo3R-4M cung cấp pipeline để làm điều này, nhưng vẫn cần effort.
-
Single robot type trong dataset: Tất cả 120k scenes đều với Franka. Generalization sang morphology khác chưa được test rộng rãi.
-
Synthetic-to-Real gap còn đó: Dù kết quả thực tế rất tốt, model vẫn train hoàn toàn trên synthetic data (Isaac Sim). Với môi trường đặc biệt (ánh sáng cực đoan, vật liệu không có trong dataset), performance có thể giảm.
-
Chưa test với dynamic scenes: Khi vật thể di chuyển nhanh (conveyor belt, human hand-off), 18–43 Hz có thể không đủ tracking chính xác.
Tóm lại: Robo3R đặt nền cho cái gì?
Robo3R giải quyết bài toán fundamental: làm cho robot "thấy" 3D đúng metric từ camera thông thường. Không cần depth sensor đắt tiền, không cần SLAM phức tạp, không cần offline processing — chỉ cần RGB + robot state, chạy real-time, cho ra point cloud đáng tin cậy trong robot frame.
Đây là perception foundation mà tất cả các layer bên trên (grasp planning, policy, VLA) đều cần. Như người thợ xây cần đo khoảng cách chính xác trước khi đặt gạch, robot cần biết vật ở đâu trong không gian 3D trước khi lên kế hoạch hành động.
Ở bài 3, chúng ta sẽ đi xa hơn: khi đã có point cloud 3D, Diffusion Policy 3D (DP3) dùng nó như thế nào để train visuomotor policy hiệu quả hơn ảnh RGB đơn thuần?
Bài viết liên quan
- Bài 1: Vì sao VLA 2D chưa đủ cho manipulation — Động lực và bức tranh tổng thể của series
- Bài 3: DP3 — Diffusion Policy 3D với Point Cloud — Dùng 3D geometry cho visuomotor policy
- Bài 5: WholeBodyVLA + RL cho Humanoid — Whole-body loco-manipulation với latent VLA