Năm 2024–2025, làn sóng Vision-Language-Action (VLA) models nổ ra mạnh mẽ: π₀, OpenVLA, RoboVLMs, ACT… Những model này được huấn luyện trên hàng chục triệu frame video robot, học từ ảnh RGB đơn thuần để sinh ra hành động. Kết quả trên benchmark ấn tượng, demo viral trên X/Twitter, nhưng khi đưa ra môi trường thực tế phức tạp — bàn lộn xộn, ánh sáng khác, vật thể bị che khuất — chúng lại thất bại theo những cách rất đặc trưng.
Câu hỏi đặt ra: có điều gì cơ bản mà 2D RGB không thể biểu diễn được không? Câu trả lời ngắn là có — và đó chính là hình học 3D. Series này là hành trình 7 bài đi từ lý do tại sao 2D không đủ, qua các phương pháp 3D-aware manipulation tiên tiến nhất (Robo3R, DP3, Omni-Manip, WholeBodyVLA…), đến roadmap triển khai thực tế trên Unitree G1.
Roadmap của series
| Bài | Chủ đề | Nội dung chính |
|---|---|---|
| Bài 1 (bài này) | Vì sao 2D chưa đủ | Động lực, 5 hạn chế cốt lõi, bức tranh tổng thể |
| Bài 2 | Robo3R — 3D từ RGB | Feed-forward 3D reconstruction không cần depth sensor |
| Bài 3 | DP3 — Diffusion Policy 3D | Point cloud + diffusion cho visuomotor policy |
| Bài 4 | Omni-Manip — Spatial 3D | Omnidirectional 3D perception cho large-workspace humanoid |
| Bài 5 | WholeBodyVLA + RL | Whole-body loco-manipulation với latent VLA và RL |
| Bài 6 | Thu thập dữ liệu 3D | HuMI, robot-free demo, chiến lược scale dữ liệu |
| Bài 7 | Roadmap Unitree G1 | Từ paper đến robot thật: deployment pipeline thực tế |
1. Robot nhìn thế giới qua một lỗ kim — và lỗ đó chỉ 2D
Hãy tưởng tượng bạn bịt một mắt và cố gắng nắm một chiếc cốc trên bàn. Bạn vẫn làm được — não người có khả năng ước lượng độ sâu đáng kinh ngạc từ một mắt nhờ các cue như perspective, shadow, texture gradient. Nhưng nếu bạn đột nhiên phải làm việc đó trong một phòng hoàn toàn đồng nhất (không bóng đổ, không texture), không biết kích thước thực của cái cốc, và tay bạn không có cảm giác xúc giác — bạn sẽ thất bại.
Đó chính xác là tình cảnh của robot học VLA từ ảnh RGB 2D.
Camera 2D chiếu thế giới 3D xuống mặt phẳng 2D theo phép chiếu phối cảnh (perspective projection). Phép chiếu này là nhiều-một: vô số cấu hình 3D khác nhau cho ra cùng một ảnh 2D. Thông tin bị mất trong quá trình này không thể phục hồi hoàn toàn chỉ từ một ảnh đơn.
2. Năm điểm yếu chết người của 2D RGB
2.1 Depth Ambiguity — Mập mờ chiều sâu
Xem xét phép chiếu phối cảnh cơ bản nhất: điểm 3D (X, Y, Z) được chiếu xuống pixel (x, y) = (fX/Z, fY/Z) với f là tiêu cự. Chú ý rằng điểm (2X, 2Y, 2Z) cũng cho ra đúng pixel đó — bởi vì 2f(2X)/(2Z) = fX/Z.
Nói cách khác: một con cờ vua nhỏ đặt gần và một con cờ vua to đặt xa có thể cho ra đúng cùng kích thước pixel. Policy học từ 2D không phân biệt được hai trường hợp này.
Với robot manipulation, điều này nghĩa là: "Tôi nên mở tay ra bao rộng?" — câu trả lời phụ thuộc vào kích thước thực (metric size) của vật thể, không phải kích thước pixel. Policy 2D phải đoán mò, và khi generalize sang môi trường mới với vật thể có kích thước khác, nó sẽ sai.
2.2 Occlusion — Che khuất
Manipulation thực tế luôn xảy ra trong cảnh bộn bề: vật thể che vật thể, tay robot che vật thể, hộp xếp chồng lên nhau. Camera 2D chỉ thấy bề mặt nhìn thấy được (visible surface), không thấy phần sau hoặc bên dưới.
Hãy xét tình huống Unitree G1 cần nhặt một chai nước đang bị một hộp giấy che một nửa. Policy 2D được huấn luyện trên cảnh nhìn rõ chai có thể không biết phải làm gì khi chai bị che một nửa — vì ảnh trông hoàn toàn khác. Trong khi đó, nếu có point cloud 3D, robot "nhìn thấy" phần chai nhô ra phía sau hộp và có thể suy ra vị trí toàn bộ của chai.
Vấn đề occlusion còn nghiêm trọng hơn khi xét đến self-occlusion của tay robot: khi tay robot đang cầm vật, nó che khuất chính vật thể đó khỏi camera. Policy 2D cần học "tưởng tượng" vật thể tiếp tục tồn tại ở đâu đó sau tay — một bài toán học máy khó.
2.3 Thiếu Metric Scale — Không có thang đo thực
Ảnh 2D về bản chất là scale-invariant: bức ảnh của một viên đá 5cm trên bàn và một tảng đá 5m ngoài trời có thể trông giống nhau nếu bạn đặt chúng ở khoảng cách tương ứng.
Deep learning features (CNN, ViT) được thiết kế để không nhạy cảm với scale — điều này tốt cho nhận dạng (con mèo là con mèo dù nhỏ hay to) nhưng thảm họa cho manipulation (bóp nhẹ quả trứng vs bóp mạnh hộp kim loại cần lực khác nhau).
Khi policy không biết metric scale:
- Không biết trajectory cần dài bao nhiêu cm để reach vật thể
- Không biết cần mở gripper bao rộng
- Không biết lực cần thiết (force control)
- Không thể transfer chính xác giữa các camera setup khác nhau
2.4 Không có hình học trong Robot Frame
Để thực hiện manipulation, robot cần biết tọa độ của mục tiêu trong robot frame (hoặc ít nhất trong world frame). Policy 2D học ánh xạ từ pixel → action — ánh xạ này hoàn toàn phụ thuộc vào:
- Vị trí camera
- Góc nhìn camera
- Tiêu cự và intrinsics của camera
Khi bạn huấn luyện policy trên một camera setup và deploy lên camera khác (thậm chí chỉ xê dịch 5cm), ánh xạ pixel → action bị break hoàn toàn. Đây là lý do tại sao robot manipulation cần re-calibration tốn kém khi thay đổi bất kỳ thứ gì trong hardware setup.
Policy 3D-aware ngược lại: nó học trong canonical 3D space — không gian đó không đổi khi camera di chuyển (miễn là bạn biết camera extrinsics). Đây là lý do DP3 (bài 3) generalize tốt hơn nhiều sang viewpoint mới.
2.5 Collision Avoidance — Bài toán không thể giải bằng pixel
Khi robot cần di chuyển tay từ điểm A đến điểm B mà không va vào vật thể trong cảnh, motion planner cần biết hình học 3D của toàn bộ scene: mỗi vật thể chiếm thể tích 3D nào?
Từ ảnh 2D, bạn có thể đoán xem pixel nào thuộc về vật thể nào (segmentation), nhưng không biết vật thể đó dày bao nhiêu theo chiều nhìn. Điều này làm cho collision-free trajectory planning gần như không thể từ 2D thuần túy.
Ví dụ thực tế: AgiBot X2 khi thực hiện task "lấy hộp từ ngăn dưới tủ" phải luồn tay qua khe hẹp. Policy 2D không biết khe hẹp đó rộng bao nhiêu, tay robot dày bao nhiêu, và trajectory nào an toàn — trong khi với point cloud 3D, bài toán này có thể giải bằng planning algorithm chuẩn.
3. Bằng chứng thực nghiệm: 2D thua 3D nhường nào?
Công trình "Point Cloud Matters" (NeurIPS 2024, arXiv:2402.02500) là benchmark toàn diện nhất về vấn đề này. Với 125 task trên 2 simulator, cùng encoder và policy baseline chuẩn hóa, họ so sánh 3 loại observation: RGB, RGB-D, và Point Cloud.
Kết quả? Point cloud thắng nhất quán — kể cả với thiết kế đơn giản nhất. Đặc biệt nổi bật ở các task:
- Geometric generalization: vật thể cùng loại nhưng hình dạng khác nhau
- Viewpoint generalization: camera góc khác khi deploy
- Contact-rich tasks: yêu cầu biết chính xác geometry của vật thể
Kết quả trung bình (Point Cloud Matters, NeurIPS 2024):
┌─────────────────────┬───────────────┬───────────────┬──────────────┐
│ Observation type │ Base tasks │ Geo. var. │ View. var. │
├─────────────────────┼───────────────┼───────────────┼──────────────┤
│ RGB only │ ██████ 52% │ ███ 31% │ ████ 38% │
│ RGB-D │ ███████ 61% │ █████ 48% │ █████ 47% │
│ Point Cloud │ █████████ 78%│ ████████ 69% │ ███████ 64%│
└─────────────────────┴───────────────┴───────────────┴──────────────┘
(Số liệu minh họa, xem paper gốc để có con số chính xác)
Ý nghĩa của gap này: khi deploy robot ra ngoài environment training, 2D policy thất bại nhanh hơn rất nhiều so với 3D policy.
4. Xu hướng mới: 3D-Aware Manipulation
Vậy giải pháp là gì? Có ba hướng tiếp cận đang hội tụ vào năm 2025–2026:
4.1 Point Cloud Policy
Thay vì dùng pixel RGB, robot nhận point cloud — tập hợp điểm 3D (x, y, z) trong không gian — từ depth sensor (LiDAR, depth camera). Mỗi điểm mang tọa độ metric thực, không bị ảnh hưởng bởi góc nhìn camera.
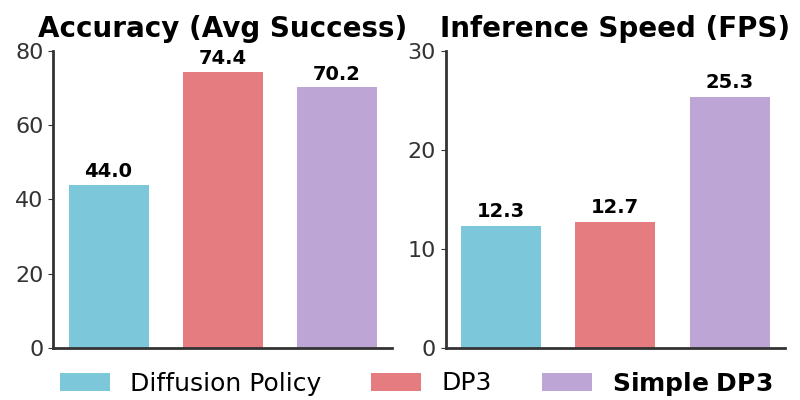
3D Diffusion Policy (DP3) (arXiv:2403.03954) là minh chứng mạnh nhất: đạt 85% success rate trên robot thực với chỉ 40 demonstrations/task — con số mà policy 2D cần hàng trăm demo để đạt được.
4.2 Feed-Forward 3D Reconstruction
Nếu không có depth sensor? Hướng mới nhất là dự đoán 3D geometry từ RGB trong một forward pass duy nhất — không cần optimization iterative, không cần calibration phức tạp.
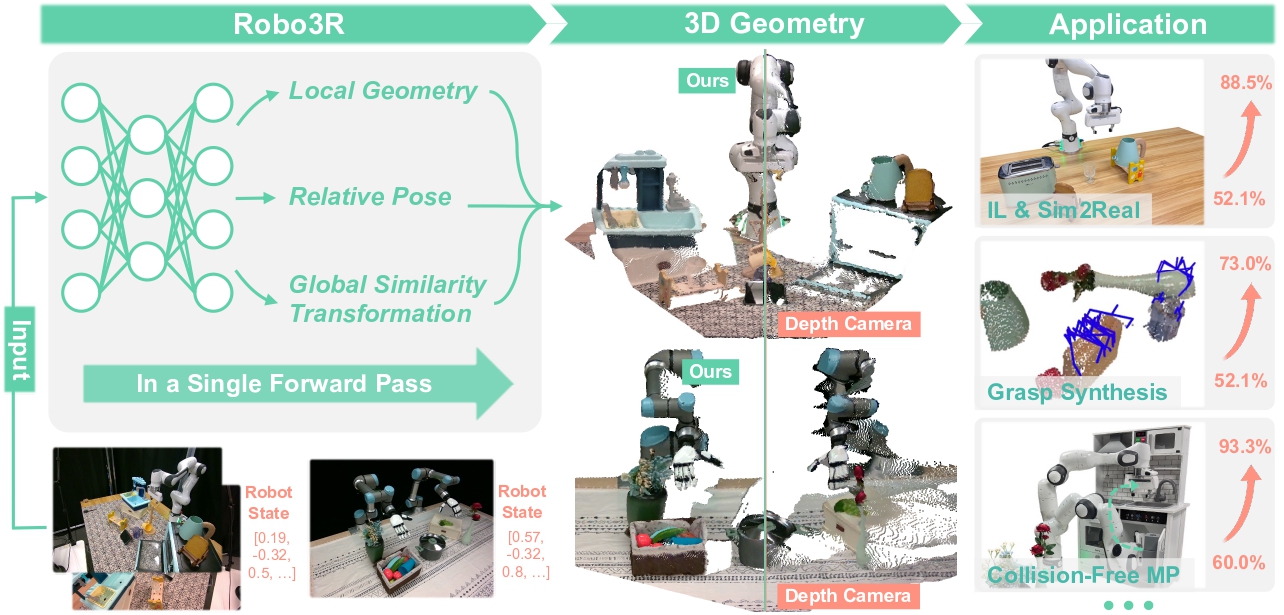
Robo3R (arXiv:2602.10101, RSS 2026) xây dựng model feed-forward nhận đầu vào là ảnh RGB + robot state, đầu ra là point cloud metric-scale chính xác. Điểm độc đáo: Robo3R được train trên Robo3R-4M — 4 triệu frame synthetic với annotation 3D đầy đủ.
Robo3R dự đoán point cloud metric-scale từ RGB không cần depth sensor — nguồn: yangsizhe.github.io/robo3r
4.3 Canonical Robot-Frame 3D và Spatial Constraints
Hướng thứ ba không chỉ dùng 3D cho perception mà còn cho planning và control. Omni-Manip (arXiv:2603.05355) dùng LiDAR 360° (Livox MID-360) kết hợp với Time-Aware Attention Pooling để xử lý point cloud toàn cảnh, cho phép humanoid thực hiện manipulation ngoài vùng nhìn thấy của camera (beyond-FOV).
OmniManip (arXiv:2501.03841, CVPR 2025 Highlight) lại tiếp cận theo hướng object-centric: định nghĩa không gian canonical cho mỗi vật thể dựa trên affordances, sau đó dùng 6D pose tracking để close-loop control.
5. Bức tranh toàn cảnh: Các paper tiêu biểu trong series
Sáu paper dưới đây sẽ được phân tích sâu trong các bài tiếp theo của series. Đây là preview nhanh:
Robo3R (RSS 2026)
"Enhancing Robotic Manipulation with Accurate Feed-Forward 3D Reconstruction" arXiv:2602.10101
Vấn đề giải quyết: làm sao có 3D chính xác từ RGB mà không cần depth sensor? Giải pháp: model feed-forward train trên 4M frame synthetic, dự đoán point cloud metric-scale. Kết quả: consistent improvement trên imitation learning, sim-to-real, grasp synthesis, và collision-free planning.
DP3 — 3D Diffusion Policy (RSS 2024)
"Generalizable Visuomotor Policy Learning via Simple 3D Representations" arXiv:2403.03954
Kết hợp point cloud với diffusion model — simple nhưng cực kỳ hiệu quả. 85% success rate với 40 demos. Quan trọng hơn: generalize tốt hơn rất nhiều sang viewpoint mới, vật thể mới, instance mới. Phiên bản iDP3 (Improved DP3) mở rộng cho humanoid manipulation.
Omni-Manip (2026)
"Beyond-FOV Large-Workspace Humanoid Manipulation with Omnidirectional 3D Perception" arXiv:2603.05355
Sử dụng LiDAR 360° thay vì camera để có point cloud omnidirectional. Cho phép Fourier GR thực hiện task trong không gian làm việc lớn, kể cả khi vật thể ra ngoài FOV camera. 82/120 tasks thành công so với baselines 2D chỉ đạt 18–25/120.
WholeBodyVLA (ICLR 2026)
"Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control" arXiv:2512.11047
Framework VLA thống nhất cho loco-manipulation: học Latent Action Model từ video egocentric không cần action annotation, sau đó decode thành dual-arm joints + locomotion commands. Demo trên AgiBot X2 với tasks đẩy xe tải >50kg, squat để lấy vật.

HuMI — Humanoid Manipulation Interface (2026)
"Humanoid Whole-Body Manipulation from Robot-Free Demonstrations" arXiv:2602.06643
Giải quyết vấn đề thu thập dữ liệu: thay vì dùng robot để demo, dùng thiết bị portable gắn lên người, capture toàn bộ body motion (không chỉ tay). Hiệu quả gấp 3x so với teleoperation. 70% success rate trong môi trường chưa thấy.
SPEAR-1 (CVPR 2026)
"Scaling Beyond Robot Demonstrations via 3D Understanding" arXiv:2511.17411
Robot foundation model tích hợp 3D perception với language-instructed control. Điểm đặc biệt: chỉ cần 1/20 lượng robot data so với các model SOTA khác bằng cách dùng non-robot data có 3D annotation (EgoExo-4D). Model đầu tiên từ châu Âu (INSAIT) cạnh tranh với π₀.
6. Unitree G1, AgiBot X2, Fourier GR — Xương sống của series
Series này dùng Unitree G1 làm ví dụ xuyên suốt vì đây là humanoid platform phổ biến nhất trong cộng đồng research open-source hiện tại. G1 với 43 DOF (degrees of freedom), dual-arm 7-DOF mỗi bên, locomotion 6-DOF mỗi chân, là nền tảng lý tưởng để thử nghiệm whole-body manipulation.
Ngoài G1, các platform sẽ xuất hiện trong series:
- AgiBot X2: nền tảng của WholeBodyVLA và OmniManip, bimanual humanoid với khả năng locomotion mạnh
- Fourier GR-1/GR-2: được dùng trong Omni-Manip và nhiều research khác, tiêu biểu cho humanoid thế hệ mới từ châu Á
Tại sao không dùng Boston Dynamics Atlas hay Tesla Optimus? Vì chúng không open-source và không accessible cho researcher độc lập. Unitree G1 (khoảng $16,000) là platform đầu tiên đưa humanoid vào tay lab nhỏ.
7. Tại sao bây giờ? Tại sao 2025–2026?
Ba luồng công nghệ hội tụ đồng thời:
Luồng 1: Diffusion models trưởng thành. Diffusion Policy (2023) chứng minh rằng action generation có thể học từ data một cách clean và generalizable. DP3 mở rộng luồng này sang 3D input.
Luồng 2: Feed-forward 3D models. Những model như DUSt3R, MASt3R, MonST3R (2024) chứng minh rằng 3D reconstruction có thể nhanh và accurate trong một forward pass. Robo3R đưa paradigm này vào manipulation.
Luồng 3: LLM/VLM cho planning. GPT-4V, PaLM-E, VLMs đã đủ mạnh để hiểu scene và plan ở level ngôn ngữ. Khi kết hợp với 3D perception → VLA 3D-aware.
Ba luồng này cộng lại tạo ra window of opportunity để giải quyết manipulation theo cách mà trước đây không thể. Đó là lý do tất cả 6 paper trong series đều xuất hiện trong khoảng 2024–2026.
Kết luận: 3D không phải optional
Nếu bạn đang xây dựng robot manipulation system và nghĩ rằng RGB camera là đủ, hãy đặt câu hỏi: "Task của tôi có cần biết khoảng cách thực, biết phần bị che khuất, biết hình học 3D của scene không?" Với phần lớn real-world manipulation — câu trả lời là có.
2D RGB policy hoạt động tốt trong môi trường controlled, ánh sáng tốt, camera cố định, task đơn giản. Nhưng khi scale lên — nhiều vật thể hơn, nhiều task hơn, môi trường khác nhau — giới hạn cơ bản của 2D sẽ lộ rõ.
Series này sẽ đi từng bước một: Bài 2 tiếp theo sẽ mổ xẻ Robo3R — cách họ xây dựng feed-forward 3D reconstruction không cần depth sensor và tại sao điều này thay đổi cuộc chơi. Nếu bạn đang làm việc với robot manipulation hay interested trong foundation models cho robotics, đây là thứ không thể bỏ qua.


