DREAM-Chunk is a practical idea for VLA robot deployment: instead of sampling one action chunk and executing it almost open-loop until the next policy call, sample multiple candidate chunks, use a lightweight latent world model to dream the future of each chunk, and at every control phase execute the action from the candidate whose predicted latent state best matches the real observation.
In plain terms, DREAM-Chunk does not retrain the base VLA and does not ask a huge policy to run at servo frequency. It spends extra test-time compute to expose several plausible futures, then switches among them while the robot is executing. That matters when the real world is stochastic: motors undershoot, a USB connector gets stuck, a moving object rolls faster than expected, one camera frame does not reveal velocity, or a human perturbs the target box during insertion.
Primary sources used for this guide:
- Paper: DREAM-Chunk: Reactive Action Chunking with Latent World Model
- arXiv HTML: 2606.18589v1
- Project page: wenxichen2746.github.io/DREAM-Chunk
- Code repository: the project page currently points to
https://github.com/TODO/DREAM-Chunk, which returned 404 when checked for this article. The installation section below therefore separates the verified official status from a reference skeleton you can adapt to SmolVLA or pi0.5 once official code is available.
If you are new to VLA systems, read SmolVLA training, pi0-FAST training, and world models for VLA before putting this method on hardware.
Why action chunking needs reactivity
Many modern VLA policies do not output one action at a time. They output a short sequence:
observation_t + language_instruction
|
v
VLA policy
|
v
action chunk A_t = [a_t, a_{t+1}, ..., a_{t+L-1}]
This interface is called action chunking. It is useful because large VLA models are often slower than the robot control loop. A policy may run at 2-10 Hz while the robot needs actions at 30 Hz or higher. Instead of calling the large model every servo tick, the robot calls it once, receives a chunk, and executes several steps before replanning.
The weakness is also clear. Later actions inside the chunk were selected from an older observation. If the gripper slips, the connector misses the port, the object velocity is hidden by partial observability, or the environment changes after the chunk was sampled, the remaining actions can become stale. The robot is still executing a plan that made sense for a world that no longer exists.
Naive open-loop chunking says: "I already decided, so I will keep going." DREAM-Chunk changes the execution rule to: "I still use long chunks to reduce policy calls, but I keep several predicted futures alive and choose again while moving."
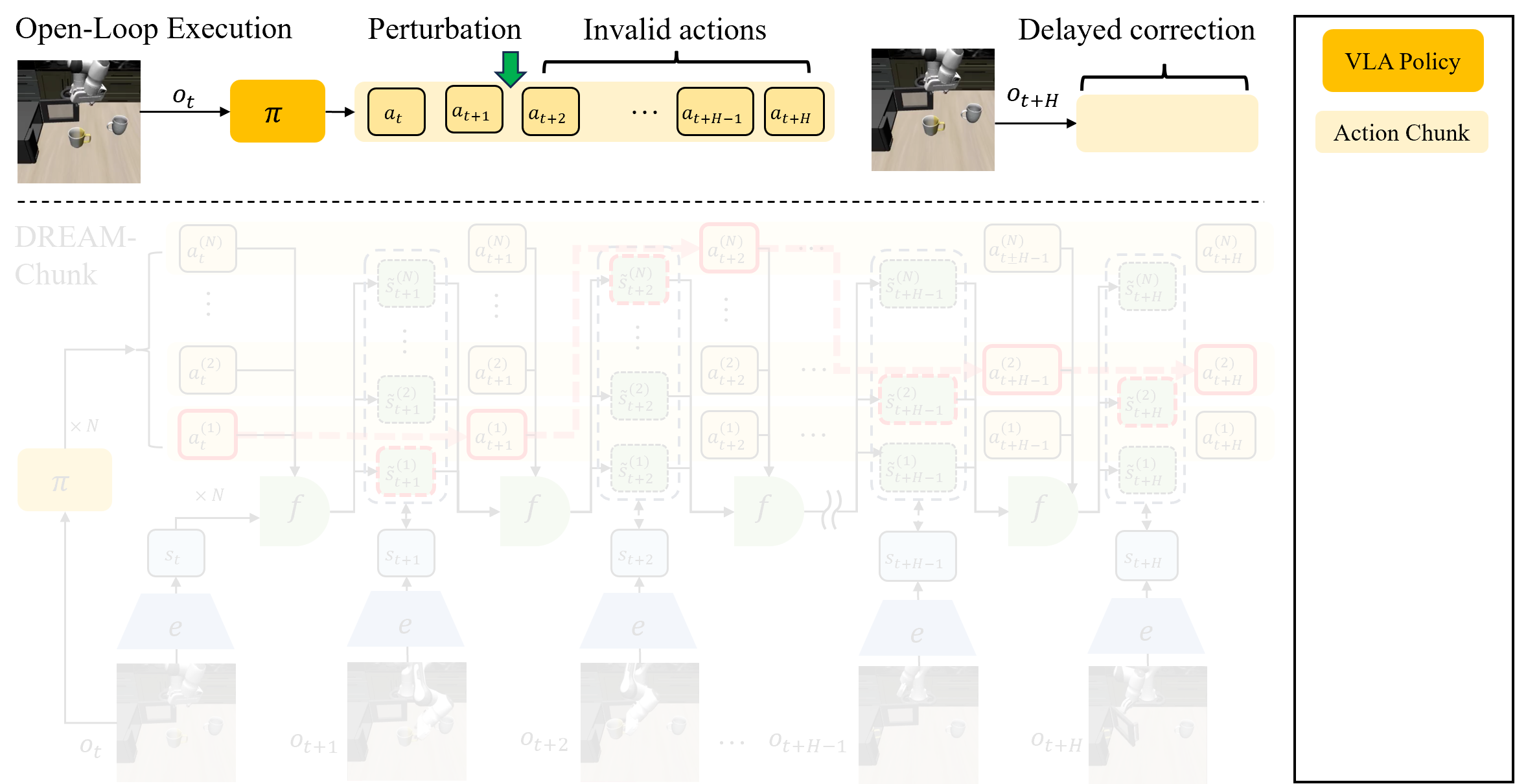
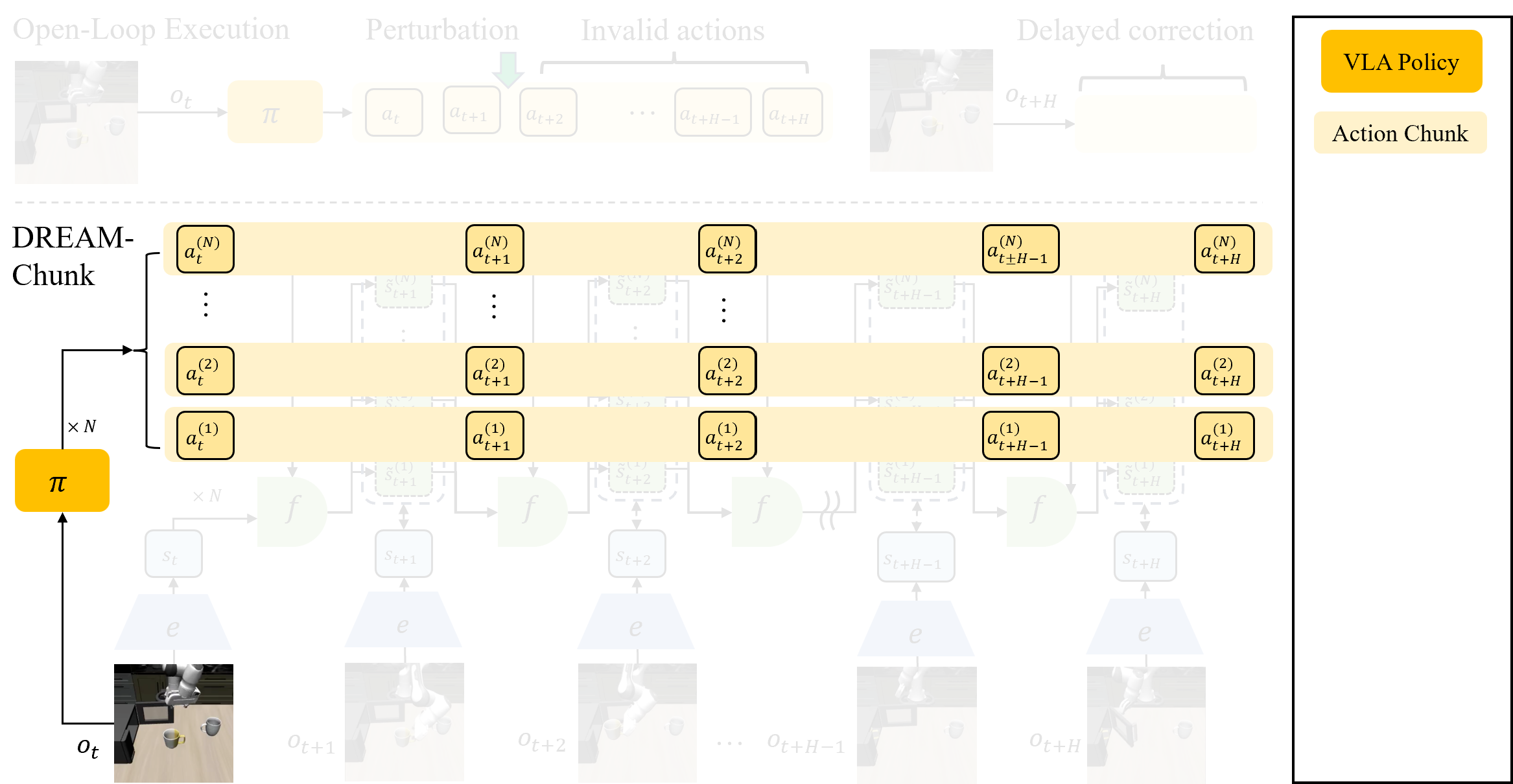
The paper idea in five steps
DREAM-Chunk stands for Dreamed-state REactive Action Matching for Action Chunking. The method assumes three components: a frozen chunking policy pi, an encoder E, and a latent dynamics model f. The policy samples action chunks, the encoder maps observations into latent states, and the dynamics model predicts the next latent state from the current latent state and action.
The inference loop is:
1. Read the current observation o_t.
2. Sample N candidate action chunks from the VLA:
A^1, A^2, ..., A^N
3. Encode the current observation:
z_t = E(o_t)
4. Roll out the latent future of each chunk:
z^i_{t+k+1} = f(z^i_{t+k}, a^i_{t+k})
5. At execution phase k:
- encode the real observation z_real = E(o_{t+k})
- compare z_real with z^1_{t+k}, ..., z^N_{t+k}
- pick the candidate with the closest dreamed state
- execute action a^i_{t+k}
The key detail is phase-aligned matching. At phase k, the robot compares the real latent state only with dreamed latent states at phase k. It does not jump from phase 8 of one chunk to phase 2 of another. This keeps the temporal structure of the action sequence intact while still allowing reactive switching across candidates.
Architecture: frozen VLA, small world model
DREAM-Chunk separates the large policy from the lightweight predictive module:
+----------------------+
observation ---> | frozen VLA policy pi | ---> N action chunks
+----------------------+
|
v
+----------------------+
observation ---> | encoder E | ---> latent state z
+----------------------+
|
v
+----------------------+
latent + action -> dynamics f | ---> dreamed latent rollouts
+----------------------+
The VLA can be SmolVLA, as in the SO-101 experiments, or pi0.5, as in the Franka experiment. DREAM-Chunk does not fine-tune the policy. The additional model is the auxiliary world model, which is much smaller than the VLA. The paper notes that a JEPA-style world model can have roughly 15 million parameters, while SmolVLA is around 450 million parameters and larger VLAs can exceed 2 billion parameters. In hardware experiments, VLA inference takes more than 100 ms, while world-model encoding, prediction, and matching stay at the millisecond scale.
The paper studies several latent world model families:
| World model type | Intuition | Useful when |
|---|---|---|
| RSSM, Dreamer, R2-Dreamer style | The latent state has deterministic and stochastic parts | You need stable rollout under uncertainty |
| JEPA or LEWM, decoder-free | Learn predictive latent representations without reconstructing full images | You want a fast matcher for control |
DREAM-Chunk is not tied to one world-model architecture. The core requirement is that the latent space must be predictive enough to distinguish the consequences of candidate chunks, and the latent dynamics must remain reliable over the chosen execution horizon.
Installation: official status and reference setup
At the time of writing, the project page publishes the paper, figures, results, and videos, but the Code link is still a placeholder that resolves to a 404 page. Do not assume there is an official repository you can clone today. A practical setup is to prepare your VLA environment, then add DREAM-Chunk as an inference wrapper once the official implementation or your own implementation is ready.
A reasonable Python environment is:
conda create -n dreamchunk python=3.10 -y
conda activate dreamchunk
pip install torch torchvision torchaudio
pip install transformers accelerate einops opencv-python
pip install lerobot
pip install numpy scipy tqdm h5py zarr
For SO-101 with LeRobot, you also need the camera stack, robot bus, calibration files, and dataset pipeline. For Franka, you need your controller bridge, camera capture, and hardware safety stack. DREAM-Chunk does not replace the low-level controller. It only decides which action from the candidate chunks should be executed at the current phase.
Organize your implementation around four interfaces:
class ChunkPolicy:
def sample_chunks(self, observation, instruction, num_samples: int):
"""Return tensor [N, H, action_dim]."""
class WorldEncoder:
def encode(self, observation):
"""Return latent vector z."""
class LatentDynamics:
def rollout(self, z0, chunks):
"""Return dreamed latents [N, H, latent_dim]."""
class DreamChunkExecutor:
def select_action(self, observation, dreamed_latents, chunks, phase: int):
z_real = self.encoder.encode(observation)
z_phase = dreamed_latents[:, phase]
idx = nearest_neighbor(z_real, z_phase)
return chunks[idx, phase]
In a real implementation, nearest_neighbor is usually cosine distance or L2 distance in a normalized latent space. If your world model has a stochastic latent state, match on the deterministic hidden state or the mean of the latent distribution, but keep the training and inference representation consistent.
Training: keep the policy, train the world model
Training has two branches.
The first branch is the chunking policy. Train SmolVLA, pi0.5, or another OpenVLA-style policy on demonstration data as usual: observations, language instructions, robot states, and action sequences. The policy learns to produce an action chunk from the current observation. If you use LeRobot, this branch looks like normal SmolVLA training or pi0-FAST training: synchronize frames and actions, normalize actions, split train/validation data, then train the policy with its native objective.
The second branch is the auxiliary world model. It uses the same trajectories, but the target is not the action. The target is latent transition:
input:
observation o_t
action a_t
target:
representation of observation o_{t+1}
loss:
latent prediction loss
+ representation regularization
+ optional contrastive or redundancy-reduction loss
The paper evaluates variants based on R2-Dreamer, LeWorldModel, and EB-JEPA. In Kinetix, the default setting is an RSSM-based world model trained with one-step prediction loss and Barlow Twins regularization. LEWM and EB-JEPA use latent regularization such as SigReg or VICReg. If you are implementing this from scratch, start with one-step latent prediction before adding more complex losses.
One practical detail matters more than most beginners expect: DREAM-Chunk works best when demonstrations contain corrective behaviors. If your dataset only contains clean, perfect trajectories, sampling more chunks mainly produces small variations around the nominal path. When the real robot deviates, the candidate pool may not contain a useful recovery action. During data collection, intentionally include safe corrections: a slightly missed grasp that gets fixed, an insertion that gets re-approached, a target shifted within a safe region, or a moving object caught after a timing error.
A beginner-friendly dataset checklist:
| Component | Save this | Why it matters |
|---|---|---|
| RGB or RGB-D frames | main camera, wrist camera if available | the encoder needs observations |
| Proprioception | joints, gripper, TCP pose if available | helps the latent state identify robot configuration |
| Actions | delta pose, joint target, gripper command | the dynamics model needs action-conditioned prediction |
| Instruction | natural-language task command | the policy is language-conditioned |
| Correction metadata | optional but useful | helps debug whether recovery options exist |
Inference: choosing N, H, and timing
The three important inference parameters are N, H, and the control rate.
N is the number of candidate chunks. Larger N improves coverage, but policy inference becomes heavier. The Kinetix results show that increasing sample size improves performance, especially under high action noise. On hardware, however, the benefit can disappear if the added policy latency or network round trip becomes too large. The Franka remote-inference experiment illustrates this trade-off: remote DREAM-Chunk still beats the local open-loop baseline, but increasing N too far does not keep improving success because delay offsets reactivity.
H is the execution horizon: the number of actions executed before replanning. If H is too short, you are close to high-frequency replanning and use little of DREAM-Chunk's within-chunk matching. If H is too long, world-model rollout errors accumulate and chunk actions become stale. The paper uses different horizons for different hardware tasks, matching the demonstration frame rate: SO-101 at 30 Hz and Franka at 10 Hz.
A minimal inference loop looks like this:
while not done:
obs0 = robot.observe()
chunks = policy.sample_chunks(obs0, instruction, num_samples=N)
z0 = encoder.encode(obs0)
dreamed = dynamics.rollout(z0, chunks)
for phase in range(H):
obs = robot.observe()
z = encoder.encode(obs)
idx = argmin_distance(z, dreamed[:, phase])
action = chunks[idx, phase]
robot.step(action)
In a production robot stack, use asynchronous inference. While the robot is executing the last part of the current chunk, another process can sample and roll out the next candidate batch. Log the selected candidate index, the latent distance to each dreamed state, and the executed action. These logs are the fastest way to tell whether failures come from poor candidate diversity, bad latent matching, or weak low-level execution.
Results reported in the paper
The simulation benchmark is Kinetix, a 2D physics-control suite with locomotion, manipulation, and Atari-like tasks. The authors add Gaussian noise to executed actions to create stochastic dynamics, then compare DREAM-Chunk with naive asynchronous execution, RTC, BID, and Adaptive Chunking.
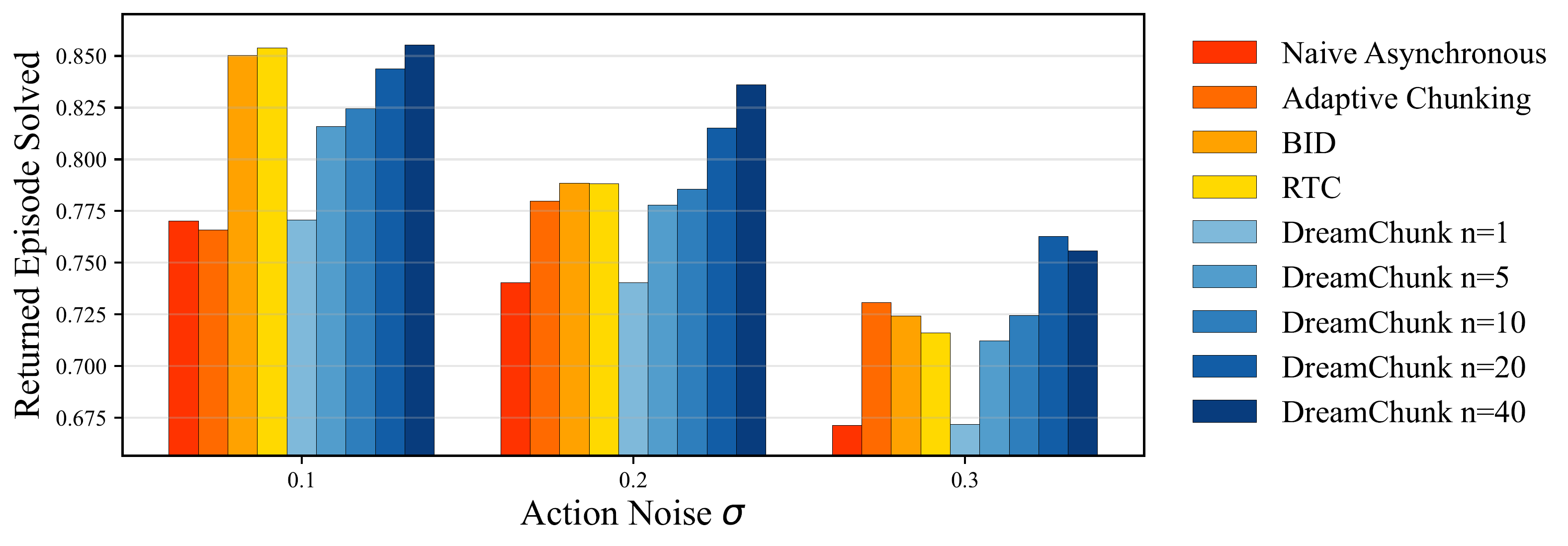
The simulation findings have three layers:
- Under low action noise, several test-time chunking methods can improve over naive open-loop execution.
- Under stronger noise, within-chunk reactivity matters more because the robot needs to correct before the next policy call.
- Sampling more chunks helps only when the policy distribution contains corrective behaviors and the world model can reliably identify the matching latent future.
The paper also studies world-model architecture. LEWM and R2-Dreamer are competitive. EB-JEPA degrades more at longer horizons, likely because rollout error accumulates. A simple frozen-policy-encoder variant drifts toward Random Switch, which is a useful warning: policy features are not automatically good predictive dynamics features. The latent representation must be trained for action-conditioned future prediction.
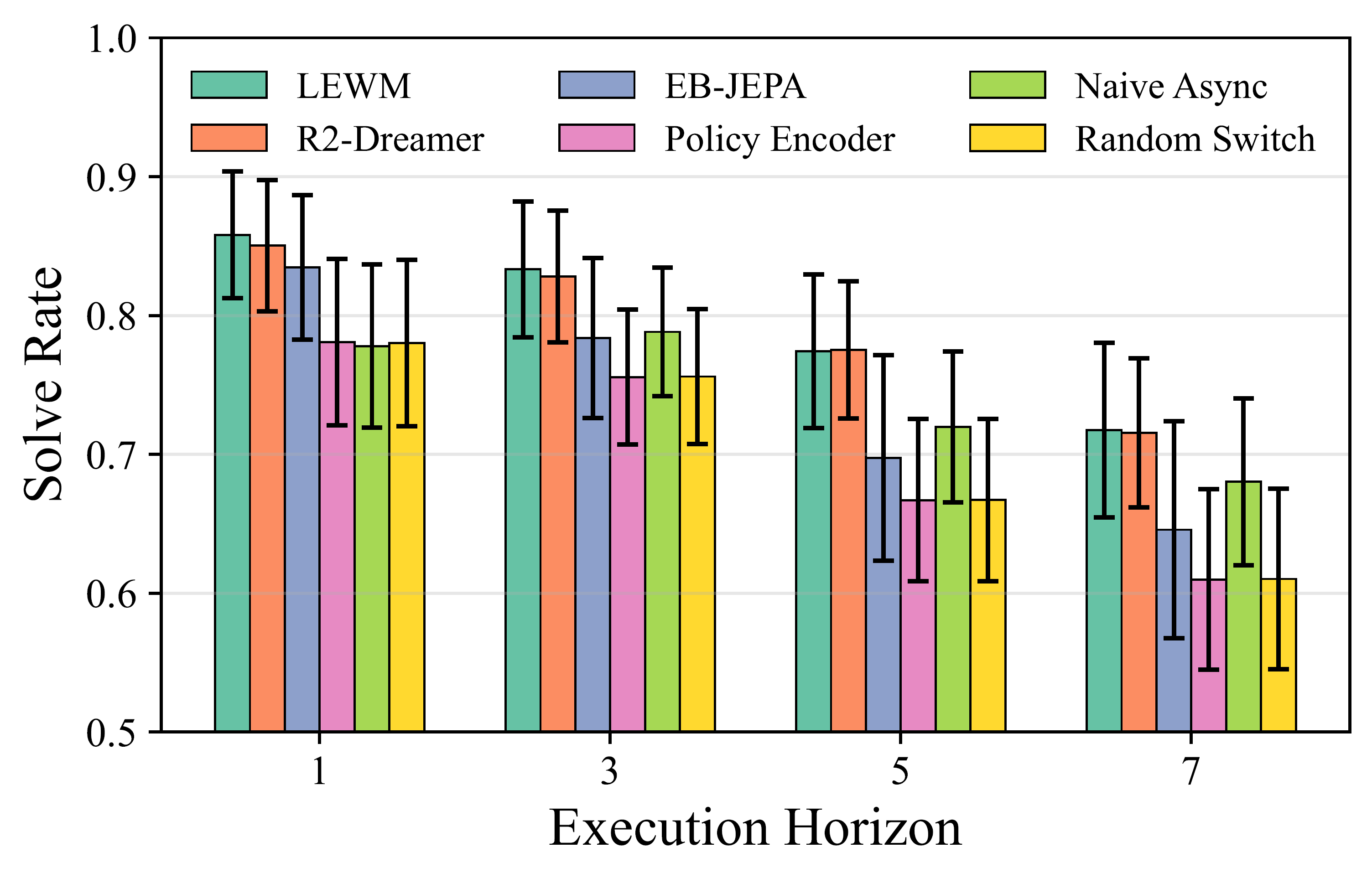
The hardware evaluation covers four tasks across two robot platforms:
| Platform | Policy | Task | Main stochasticity | Highlighted result |
|---|---|---|---|---|
| SO-101 | SmolVLA | USB insertion | servo precision, insertion error | open-loop 75% to DREAM-Chunk 95% |
| SO-101 | SmolVLA | grasp moving object | velocity is partially observable | open-loop 60% to 80% |
| SO-101 | SmolVLA | stack or pick toy | hardware imprecision | open-loop 35% to 45% |
| Franka Panda | pi0.5 | pick and insert can | external perturbation of target box | local open-loop 10% to local DREAM-Chunk with N=5 at 65% |
These results do not mean DREAM-Chunk solves manipulation in general. The observed corrections are mostly local variations around the current behavior mode, not entirely new strategies invented at test time. If the policy never learned how to recover from a stuck insertion, DREAM-Chunk cannot select a behavior that is absent from the candidate pool.
When should you use DREAM-Chunk?
DREAM-Chunk is worth trying when four conditions hold:
- Your policy already uses action chunking and policy inference is slow enough that open-loop execution is a real issue.
- Your robot faces moderate stochasticity: imperfect actuators, moving objects, missing velocity, partial observability, or small external perturbations.
- Your dataset includes some recovery behavior instead of only perfect demonstrations.
- You can train a lightweight latent world model that runs near the control loop.
Do not treat DREAM-Chunk as a replacement for safety control, force control, impedance control, collision checking, or hardware limits. The selected action must still pass through workspace bounds, velocity limits, emergency stop logic, and the low-level robot controller. DREAM-Chunk is an execution strategy for a learned policy, not the final safety layer.
A practical lab recipe
For a small robotics lab, I would start with a narrow scope:
Task: SO-101 pick-and-place or simple insertion
Dataset: 100-200 demos, with 20-30% mild corrections
Policy: fine-tuned SmolVLA
World model: small encoder plus RSSM/MLP latent dynamics
N: start at 5, then try 10 if latency allows
H: 10-30 steps depending on control rate
Metrics: success rate, intervention count, latent match distance
Run these ablations before claiming improvement:
| Ablation | Question |
|---|---|
| Open-loop chunking | Does DREAM-Chunk actually beat the base policy? |
| Random Switch | Is latent matching useful, or is sampling alone enough? |
| N = 1, 5, 10 | Does performance scale with candidate count? |
| Short vs long horizon | How long does the world model remain reliable? |
| Clean demos vs correction demos | Does the dataset contain recoverable behavior? |
The most important debugging target is latent matching. If the distance from the real observation to all dreamed states grows throughout the chunk, the horizon is too long or the world model is weak. If the same chunk is always selected, candidate diversity is low. If the selected candidate jumps frequently but success does not improve, the latent space may be matching visual similarity rather than action-relevant state.
Main takeaway
DREAM-Chunk is interesting because it connects two strong trends: VLA action chunking and latent world models. Instead of using the world model to generate pretty future videos or plan from scratch, the paper uses it as a cheap test-time matcher. That makes chunk execution more reactive while keeping the base VLA frozen.
For teams building robot manipulation systems, the practical lesson is to look beyond "which policy is stronger?" Ask "which execution strategy uses the policy better when the real robot deviates from the nominal rollout?" DREAM-Chunk shows that a small world model, trained on the right latent dynamics and paired with demonstrations that contain corrections, can make an open-loop chunking policy much more robust.