What problem does WEAVER solve?
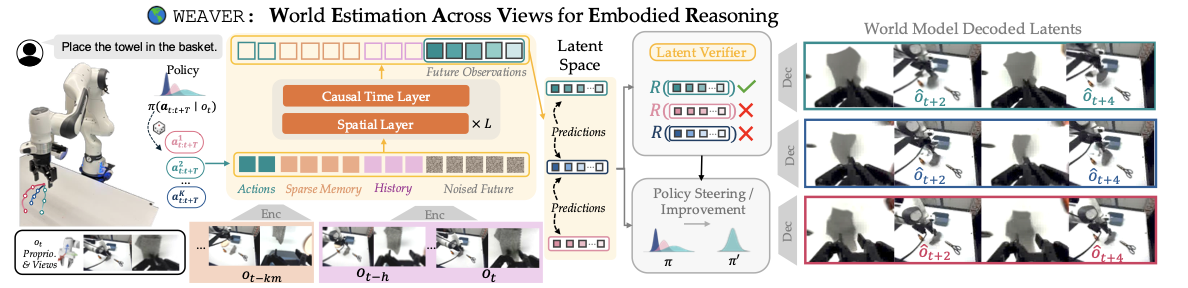
WEAVER, short for World Estimation Across Views for Embodied Reasoning, is the arXiv 2606.13672 paper WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation. The project page is arnavkj1995.github.io/WEAVER and the official code is arnavkj1995/WEAVER. The key point is that WEAVER is not another replacement for π0.5. It is a learned simulator around a VLA policy: it predicts future robot states in latent space, scores action chunks with reward and value heads, then uses those scores for policy evaluation, policy improvement, or test-time steering.
If you have read our posts on VLA models in robotics, Pi0-FAST training, or RISE world models for VLA-RL, the motivation will feel familiar. Modern VLA policies can perform real manipulation tasks, but they remain brittle when objects shift out of distribution, the gripper occludes the scene, or the task requires many consistent steps. π0.5 is a strong robot foundation policy, but the policy itself does not know in advance which sampled action chunk will lead to failure. WEAVER adds an imagination layer before execution: take the current observation, task language, and multiple candidate action chunks, imagine the outcomes, then choose or distill the better behavior.
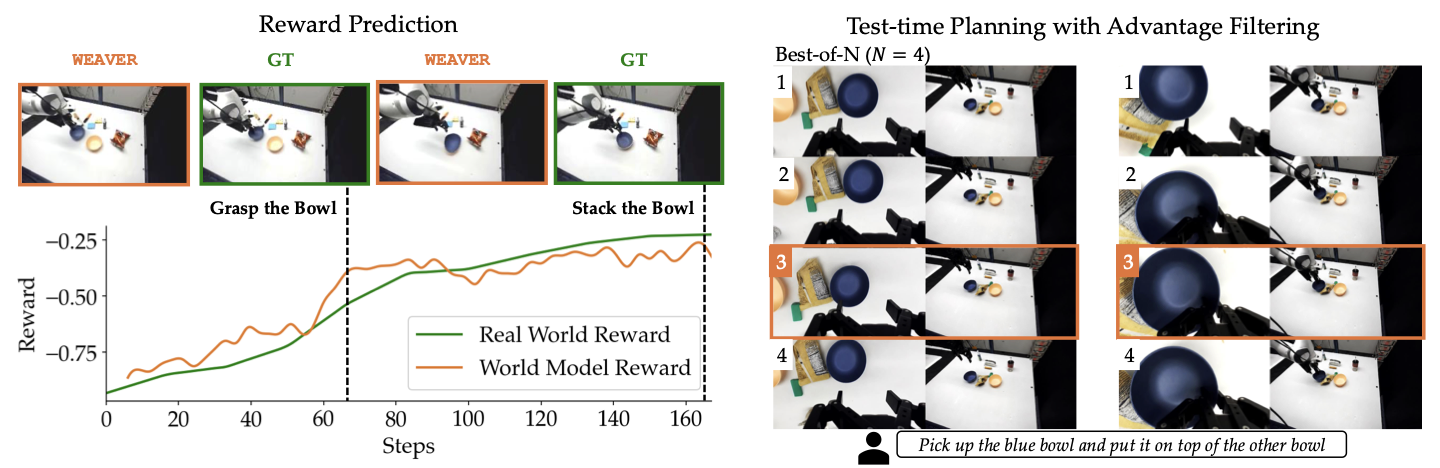
The paper defines three requirements for a useful robotics world model. First, fidelity: simulated rollouts should correlate with real outcomes, not merely look plausible. Second, consistency: predictions must stay coherent over long horizons, especially when the wrist camera moves, objects are occluded, towels and bags deform, or beans spill during pouring. Third, efficiency: inference must be fast enough for online planning. WEAVER reports ρ = 0.870 correlation with real-world success rate for policy evaluation after finetuning, a 38% real-world success-rate improvement when π0.5 is finetuned with real plus synthetic data, and a 14% test-time planning gain with a 5-10x speedup over prior world models.
The paper idea in plain language
Imagine you have a π0.5 policy controlling a Franka Panda. When the policy receives camera images and an instruction such as "put the towel into the basket", it outputs an action chunk. The usual baseline is to execute that chunk immediately on the real robot. If the chunk is poor, the robot damages the current rollout and you only discover the failure after paying the physical cost.
WEAVER inserts the following loop:
multi-view observation + proprioception + instruction
|
v
π0.5 samples several candidate action chunks
|
v
WEAVER imagines future latents for each chunk
|
v
reward head + critic estimate advantage
|
v
choose best chunk, label policy data, or evaluate rollout
The world model does not need to decode every latent into an image at every step. That design choice matters. If every candidate required video generation followed by a slow VLM judge, latency would make planning impractical. WEAVER keeps scoring in latent space: the reward head estimates task progress, while the critic estimates return beyond the imagined horizon. The decoder is used when you need visualization, debugging, or side-by-side rollout videos.
For a beginner, the simplest mental model is "a simulator learned from robot data." It is more flexible than a classical simulator in three ways. It does not need exact meshes or physical parameters for every object. It learns directly from DROID and real rollouts. It can score actions relative to a language task, not only predict pixels. The tradeoff is also important: it is not a perfect physics engine. If contacts, forces, or occluded object geometry are not visible from the cameras, the model can still guess incorrectly.
WEAVER architecture
WEAVER is a 928M-parameter multi-view latent world model. Its inputs are camera views, proprioceptive state, a language instruction, and a candidate action plan. In the paper setup, the robot is a Franka Emika Panda with two external Zed 2i cameras and one wrist-mounted Zed Mini camera, although WEAVER and π0.5 primarily use the right external view and the wrist view. Data is downsampled to 5 Hz for imagination.
The main components are:
| Component | Role | Implementation note |
|---|---|---|
| SD3 VAE encoder/decoder | Compress camera frames into latents and decode them when visualization is needed | Each view becomes patch tokens |
| Proprioception token | Adds joint and gripper state to the same token dimension | Important for contact-rich manipulation |
| Sparse memory | Stores every few frames from the distant past | Keeps scene context under occlusion |
| Short-term history | Stores the last two frames | Captures recent motion and action consequences |
| 32-layer dynamics Transformer | Predicts future latents conditioned on action tokens | Uses spatial attention and causal temporal attention |
| Reward head | Scores progress directly in latent space | Distilled from RoboMeter progress rewards |
| Critic head | Estimates return beyond the imagined horizon | Enables advantage-based action selection |
For the training objective, WEAVER uses flow matching to learn a vector field from noise to the true future latent. Instead of generating frames with a heavy pixel-space diffusion process, the model predicts velocity in latent space. The paper also uses Diffusion Forcing, where future timesteps receive independently sampled noise levels, improving long-horizon coherence. For speed, WEAVER uses SPRINT blocks to drop patch tokens, KV caching for memory and history tokens during denoising, cosine or power noise schedules, and ReFlow post-training to distill a multi-step teacher into a faster student.
Installing the repository
WEAVER is a heavy research codebase. You can inspect the code and run inference or evaluation from released checkpoints, but full training is not a laptop workload. The repository states that the training launchers use four H100 GPUs with distributed data parallelism. If your goal is to learn the pipeline, start with checkpoints and a small dataset slice.
Basic environment setup:
git clone --recurse-submodules https://github.com/arnavkj1995/WEAVER.git
cd WEAVER
uv venv --python 3.11
source .venv/bin/activate
uv sync
For logging or development tools:
uv sync --extra logging --extra dev
Download the model weights:
hf download arnavkj1995/WEAVER --local-dir checkpoints
This downloads the WEAVER, WEAVER-FT, and WEAVER-ReFlow folders. Each folder contains checkpoint.pt, config.yaml, and norm_stats_relabel.json. To try the OOD evaluation data used by the paper:
git lfs install
git clone https://huggingface.co/datasets/yilin-wu/droid_ood_data
If you only want annotations and metadata to understand the layout:
from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="yilin-wu/droid_ood_data",
repo_type="dataset",
allow_patterns=["annotations/**", "annotation_rewards/**", "norm_stats*.json"],
)
Preparing data
WEAVER expects preprocessed DROID-style trajectories containing actions, robot states, language features, rewards, normalization statistics, and either view videos or SD3 latents. For raw DROID:
python datasets/preprocess_droid.py \
--data_root /path/to/raw_droid \
--output_root /path/to/preprocessed_droid
The important output layout is:
weaver_droid/
├── annotations/<split>/<trajectory_id>.json
├── videos/<split>/<trajectory_id>.mp4
├── latents/<split>/<trajectory_id>.npz
└── done/<split>/<trajectory_id>
After preprocessing, compute normalization statistics:
python datasets/compute_norm_stats.py \
--data_root /path/to/weaver_droid
For rollouts you collect yourself, the repo provides third_party/openpi/examples/droid/panda_log.py to run an OpenPI policy server, log video plus annotation JSON, and convert the data into WEAVER format:
python -m datasets.preprocess_droid_ood \
--input_roots /path/to/your/task_folder \
--output_root /path/to/weaver_format_data \
--data_type train \
--tasks none
One beginner detail is easy to miss: reward labels do not appear automatically. WEAVER uses RoboMeter to produce reward_progress and reward_success, then the dataloader reads annotation_rewards/<split>/. If you train on custom data without reward labels, the reward head and critic will not receive meaningful supervision.
Training WEAVER
There are three main modes. Pretraining learns the world model from a large dataset:
DATASET_PATH=/path/to/preprocessed_droid \
SCRATCH_DIR=/path/to/output/model_dir \
sbatch scripts/pretrain.sh
Finetuning starts from a checkpoint and adapts it to your task or robot setup:
PRETRAINED_DIR=/path/to/pretrained/logs/chkpts \
DATASET_PATH=/path/to/finetune_data \
EXP_NAME=weaver_finetune \
FINETUNE_SUFFIX=finetune \
sbatch scripts/finetune.sh
ReFlow post-training reduces the denoising budget so planning becomes faster:
PRETRAINED_DIR=/path/to/teacher/logs/chkpts \
PRETRAINED_CKPT_NAME=checkpoint.pt \
DATASET_PATH=/path/to/preprocessed_droid \
EXP_NAME=weaver_reflow \
FINETUNE_SUFFIX=reflow \
sbatch scripts/reflow.sh
In the paper, the model is pretrained on DROID for 1M steps with batch size 32, batch length 8, 6 memory frames, memory stride 5, AdamW, and EMA 0.9999. The Transformer has 32 layers, 16 heads, embedding dimension 1536, head dimension 96, and SPRINT probability 0.5. Finetuning on task data runs for 16k steps with a lower learning rate. That is why WEAVER should be viewed as lab or cluster infrastructure, not a lightweight notebook demo.
Inference and evaluation
To generate rollout views:
python -m weaver.generate_views \
--checkpoint /path/to/logs/chkpts \
--output-dir /path/to/eval_output \
--split val \
--use-real-history \
--overrides \
dataset.path=/path/to/eval_dataset \
model.val_steps=27 \
eval_horizon=5 \
eval_bootstrap=5 \
inference.pyramid_stagger_width=1 \
inference.pyramid_schedule=cosine
The key knobs are:
| Parameter | Meaning |
|---|---|
model.val_steps |
Number of flow denoising steps |
eval_horizon |
Number of future frames generated per chunk |
eval_bootstrap |
Number of generated frames fed back into the next chunk |
inference.pyramid_schedule |
linear, cosine, power, or sigmoid |
inference.pyramid_stagger_width |
Schedule offset across future frames |
The effective NFE is:
NFE = val_steps + eval_horizon * pyramid_stagger_width
To compute FID, FVD, and LPIPS:
EVAL_DIR=/path/to/eval_output \
sbatch scripts/compute_eval_metrics.sh
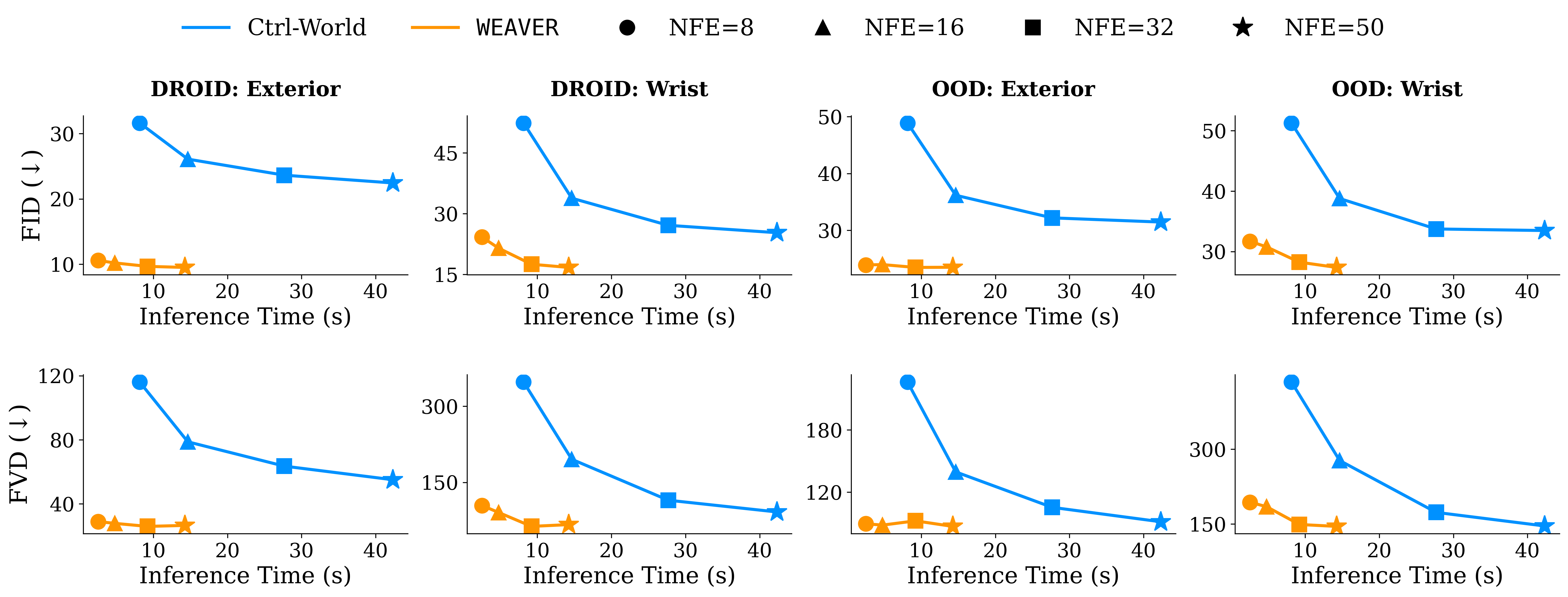
In Table 1 of the paper, on DROID validation, WEAVER at NFE=16 reaches exterior FID 10.20 and FVD 27.83 in 4.78 seconds, while Ctrl-World at NFE=16 reports FID 26.09 and FVD 78.73 in 14.65 seconds. On OOD task data, WEAVER at NFE=16 is also better on exterior FID/FVD and faster. The practical warning is that wrist-camera prediction remains harder than external-view prediction because the viewpoint changes continuously and occlusion is severe.
Improving π0.5 with synthetic data
Policy improvement is the part that makes WEAVER especially relevant for VLA builders. The README pipeline is:
- Run an OpenPI server with π0.5 on a GPU machine.
- Let π0.5 sample multiple candidate action chunks.
- Roll out each candidate inside WEAVER latent space.
- Use the reward head and critic to compute advantage.
- Keep the best segment if its advantage passes a threshold.
- Convert synthetic data to DROID layout, then to LeRobot.
- Finetune π0.5 with real plus synthetic data.
Command skeleton:
uv run scripts/serve_policy.py --env DROID --num-samples 5
synth_options=(
CHECKPOINT=/path/to/chkpts
DATASET_PATH=/path/to/dataset
OUTPUT_DIR=/path/to/output
NUM_TRAJECTORIES=1000
NUM_SAMPLES=5
NUM_CHUNKS=4
OPEN_LOOP_HORIZON=9
SELECTION_CRITERION=advantage
PI_HOST=<server-ip>
PI_PORT=8000
)
env "${synth_options[@]}" bash scripts/synth_data_gen.sh
Then convert:
python third_party/openpi/examples/droid/convert_synthetic_data_to_droid.py \
--input-dirs /path/to/synthetic_data_folder /path/to/real_data_folder \
--output-dir ../data/data_mixed_droid_all \
--tasks cup_task marker_task
python third_party/openpi/examples/droid/convert_synthetic_droid_data_to_lerobot.py \
--data_dir ../data/data_mixed_droid_all \
--repo_name your-hf-username/your-dataset-name
Finally finetune from third_party/openpi:
uv run scripts/train.py pi05_droid_finetune_real_syn_adv \
--exp-name=droid-20k-real-syn-finetune \
--overwrite
The paper reports that finetuning π0.5 with real plus WEAVER-generated synthetic data gives the strongest success rate on tasks such as Stack Bowls, PnP Bag, PnP Marker, PnP Towel, and Pour Beans. On average, WEAVER reports a 38% real-world success-rate improvement on top of π0.5. The qualitative appendix also notes that the finetuned policy produces smoother motion, fewer overly large steps, and more precise grasping and placement.
Test-time steering
If you do not want to retrain π0.5, WEAVER also supports test-time planning. For every current observation, the policy samples N action chunks, WEAVER imagines each chunk, the reward and critic heads estimate advantage, and the robot executes the best chunk. The README uses:
planning_options=(
CHECKPOINT=/path/to/chkpts
OUTPUT_DIR=/path/to/output
TASK="stack the red block"
NUM_SAMPLES=8
OPEN_LOOP_HORIZON=9
SELECTION_CRITERION=advantage
MAX_STEPS=700
PI_HOST=<server-ip>
PI_PORT=8000
)
env "${planning_options[@]}" bash scripts/steer_pi_policy.sh
This is single-chunk best-of-N search, not full long-horizon tree search. Because latency is still the bottleneck, WEAVER only looks a short distance ahead, but it looks ahead quickly enough to improve action selection. The paper reports a 14% average success-rate improvement over the base policy, with larger gains when the base policy is weaker. The limitation is clear: if a task requires multi-stage recovery or delayed consequences, one chunk of imagination may not be enough.
When should you use WEAVER?
Use WEAVER when you already have a base VLA policy, DROID-style rollouts or similar data, and a real need to reduce physical trials for evaluation, finetuning, or planning. It is especially relevant for teams using OpenPI/π0.5, Franka or DROID-like setups, and a serious GPU server. If you are still learning the basics, start with the LeRobot ecosystem guide and train a smaller policy first; WEAVER becomes much easier once you understand data layout, action chunks, and policy servers.
Do not expect WEAVER to replace a physics simulator in every case. It still suffers from partial observability, lacks direct force or tactile sensing, struggles with granular and deformable dynamics, and depends heavily on data coverage. But the main lesson is clear: VLA manipulation does not only need a stronger policy; it also needs a fast enough world model so the policy can think before it acts.
References
- Paper: WEAVER, Better, Faster, Longer
- Project page: arnavkj1995.github.io/WEAVER
- Code: github.com/arnavkj1995/WEAVER
- Model weights: huggingface.co/arnavkj1995/WEAVER