
Imagine teaching a robot to pick up packages from a running conveyor belt. There are two classic schools of thought: one group trains Vision-Language-Action (VLA) models that excel at semantic understanding — knowing what an object is, what task to perform — but remain blind to physical dynamics. The other group builds World Models that predict the future — knowing where the object will be in 0.5 seconds — but suffer from brittle compounding errors when predictions go wrong.
InternVLA-A1 from InternRobotics takes a third path: unifying both in a single Mixture-of-Transformers (MoT) architecture, where three specialized experts — semantic understanding, visual foresight, and action execution — cooperate within a single forward pass.
The result? 75.1% success rate across 10 real-world manipulation tasks, and a remarkable +26.7% over π0.5 on dynamic tasks like in-motion conveyor sorting.
The Problem: The Semantics-Dynamics Gap
Before diving into the architecture, let's understand why this is hard.
Pure VLA models (like OpenVLA, π0) are built on top of MLLMs. They excel at language understanding, object recognition, and semantic reasoning. But they're physically blind: they can't infer that an object is sliding, swinging, or accelerating.
Pure World Models (video prediction systems) are the opposite: they can predict the next frame of a scene with impressive accuracy, but they don't understand task semantics. Worse, compounding errors are their nightmare — one misprediction cascades into a chain of bad predictions.
InternVLA-A1 bridges the "semantics-dynamics gap" by letting both sides support each other: the world model doesn't need perfect predictions for the action to succeed; the VLA doesn't need to infer physics if the world model already provides a dynamics hint.
Architecture: Mixture-of-Transformers
This is the heart of InternVLA-A1. Three experts operate within a unified transformer architecture, communicating through directional masked self-attention.
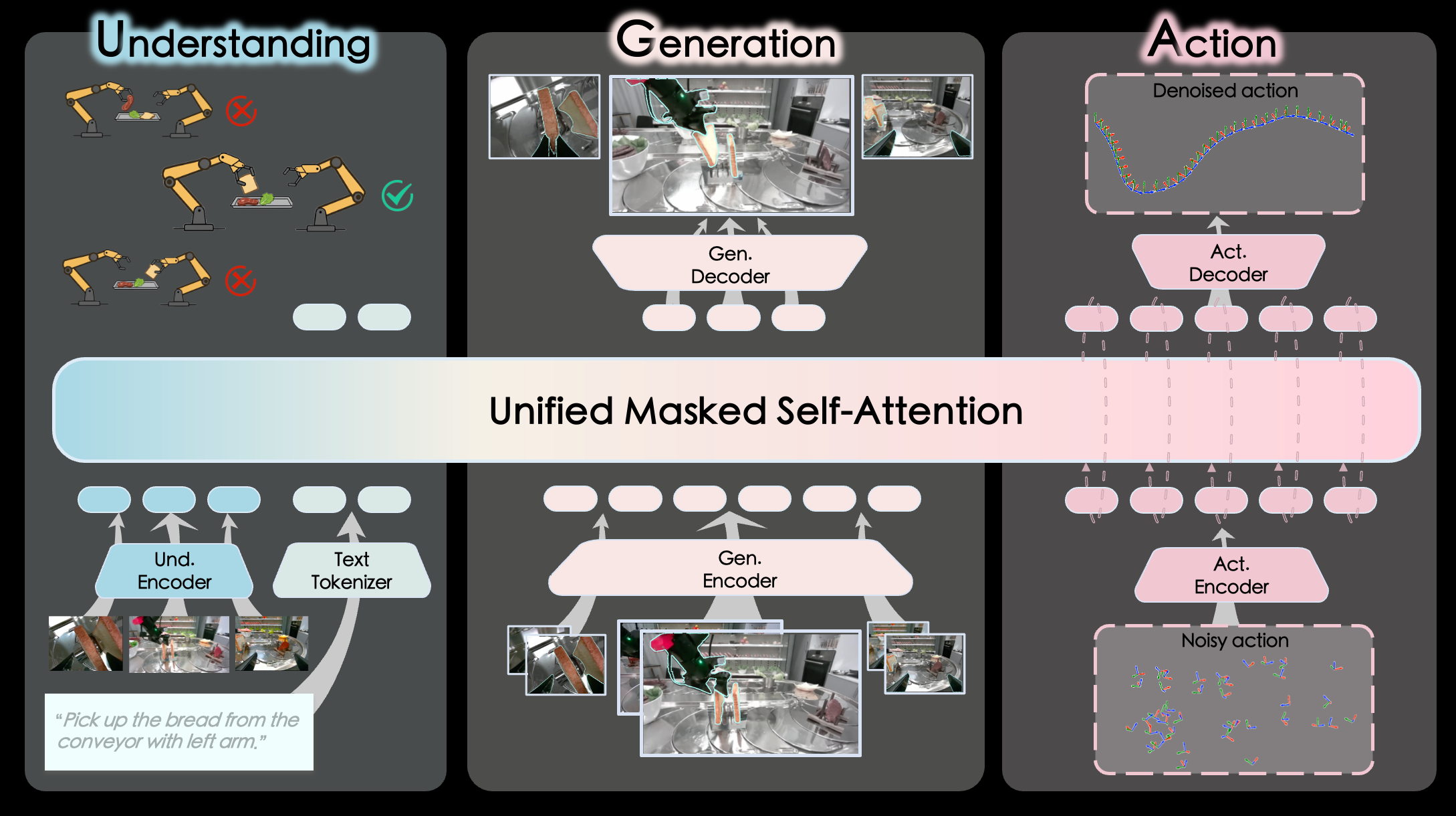
Expert 1: Understanding Expert
This is the language-vision brain. InternVLA-A1 comes in two variants:
| Variant | Understanding Expert | Total Params | Inference Speed |
|---|---|---|---|
| 2B | InternVL3 (0.94B) | ~1.8B | ~13 Hz |
| 3B | Qwen3-VL (2.13B) | ~3.2B | ~13 Hz |
This expert takes multi-view RGB images and a language instruction, producing contextual embeddings that encode task semantics. It answers: "What is this task? Which objects are relevant? What is the current scene state?"
Expert 2: Generation Expert (World Model)
This is the "eye into the future." Rather than generating full-resolution video (prohibitively slow), the Generation Expert uses the COSMOS VAE tokenizer to compress images:
6 input images (3 camera views × 2 timesteps)
↓ COSMOS VAE encoder
Latent tokens 32×32 per image
↓ Convolutional compression
4×4 tokens per image (64× reduction)
↓ Parallel decoding (single forward pass)
Predicted latent future frames at t+15
The key to real-time performance is parallel decoding — all future latents are predicted in a single forward pass, not generated token-by-token like autoregressive models. This is why the model achieves ~13 Hz despite containing a world model.
The Generation Expert answers: "At t+15, where will the object be? What will the robot arm look like?"
Expert 3: Action Expert
The final expert synthesizes information from both upstream experts to generate robot control commands. It uses Flow Matching with Beta(1.5, 1.0) time sampling — a method that outperforms DDPM-style diffusion by learning a velocity field that transforms Gaussian noise into the target action distribution in fewer steps.
Information Flow: Directional Masked Attention
The three experts don't operate independently — they communicate through directional masked self-attention:
Understanding → Generation → Action
↑ ↑
└──────────────┘
(no reverse flow)
Action tokens can attend to both Understanding and Generation embeddings, but not vice versa. This ensures:
- Actions are always informed by both semantics and physics prediction
- World model predictions aren't contaminated by action biases
Training Pipeline: Two Stages
Stage 1: Large-Scale Pre-training
Pre-training runs for 700,000 steps on 692 million frames from heterogeneous sources:
| Source | Type | Frames | Weight |
|---|---|---|---|
| InternData-A1 | Simulation | 396M | 0.64 |
| AgiBot-World | Real-world robot | 206M | 0.18 |
| EgoDex | Human egocentric video (no action labels) | 68M | 0.08 |
| RoboTwin | Simulation | 17M | 0.08 |
| RoboMind | Real-world robot | 5M | 0.02 |
Notable: EgoDex is first-person human video with no robot action labels. InternVLA-A1 learns from it purely through visual prediction objectives. Ablation studies show that training on this heterogeneous mix — sim + real + human video — outperforms training on any single source alone.
InternData-A1 statistics:
- 630,000+ trajectories across 70 tasks and 227 scenes
- 4 robot embodiments, 18 skill types
- Covers rigid, articulated, deformable, and fluid object manipulation
- Generation throughput: 209.7 hours of simulation data per day on 8 RTX 4090 GPUs
Training loss:
L_total = λ · L_gen + L_act
Where:
L_gen: L2 loss on predicted latent future frames (vs. ground truth from frozen VAE encoder)L_act: Flow Matching loss for the action distributionλ = 0.01: Balances the two objectives — generation must not overshadow action learning
Optimizer: AdamW (β₁=0.9, β₂=0.95), learning rate 5×10⁻⁵, batch size 512.
Stage 2: Post-training (Task-Specific Fine-tuning)
After pre-training, the model is fine-tuned for 60,000 steps at lower learning rates (5×10⁻⁵ → 5×10⁻⁶ decay) on task-specific data. This is the stage you'll run when deploying on your own robot.
Installation and Setup
System Requirements
Python 3.10
CUDA 12.8
PyTorch 2.7.1
GPU: NVIDIA RTX 4090 (or equivalent, ≥24GB VRAM)
Installation
# Clone repository
git clone https://github.com/InternRobotics/InternVLA-A1.git
cd InternVLA-A1
# Create conda environment
conda create -n internvla python=3.10
conda activate internvla
# Install dependencies (see tutorials/installation.md for full details)
pip install -e .
Download Model Weights
# Base 3B model (for real-world deployment)
huggingface-cli download InternRobotics/InternVLA-A1-3B
# 3B model fine-tuned on RoboTwin 2.0 (for simulation benchmarking)
huggingface-cli download InternRobotics/InternVLA-A1-3B-RoboTwin
Quick Inference
An example Jupyter notebook is provided at tests/policies/internvla_a1_3b/open_loop_genie1_real.ipynb for open-loop inference on real-world data.
Fine-tuning on Your Own Data (LeRobot V2.1)
This is the workflow for deploying InternVLA-A1 on a real robot using your own demonstration data.
Step 1: Download a sample dataset
# Example: "Put pen into pen holder" task from the Genie-1 real-robot dataset
hf download \
InternRobotics/InternData-A1 \
real/genie1/Put_the_pen_from_the_table_into_the_pen_holder.tar.gz \
--repo-type dataset \
--local-dir data
Step 2: Extract and organize
tar -xzf data/real/genie1/Put_the_pen_from_the_table_into_the_pen_holder.tar.gz -C data
rm -rf data/real
mkdir -p data/v21
mv data/set_0 data/v21/a2d_pick_pen
Step 3: Convert V2.1 → V3.0 format
InternVLA-A1 uses LeRobot V3.0 format internally. If your data is in V2.1 format (the more common format), convert it first:
python src/lerobot/datasets/v30/convert_my_dataset_v21_to_v30.py \
--old-repo-id v21/a2d_pick_pen \
--new-repo-id v30/a2d_pick_pen
Step 4: Compute normalization statistics
python util_scripts/compute_norm_stats_single.py \
--action_mode delta \
--chunk_size 50 \
--repo_id v30/a2d_pick_pen
Step 5: Run fine-tuning
# Format: bash launch/internvla_a1_3b_finetune.sh <dataset> <action_mode> <use_stats_file>
bash launch/internvla_a1_3b_finetune.sh v30/a2d_pick_pen delta true
# With a standard LeRobot dataset (absolute actions)
bash launch/internvla_a1_3b_finetune.sh lerobot/pusht abs false
Important: Before running, configure the following in the launch script:
HF_HOME: path to your HuggingFace cacheWANDB_API_KEY: your Weights & Biases API key (if using W&B logging)CONDA_ROOT: your conda installation path- CUDA device settings for your hardware
Benchmark Results
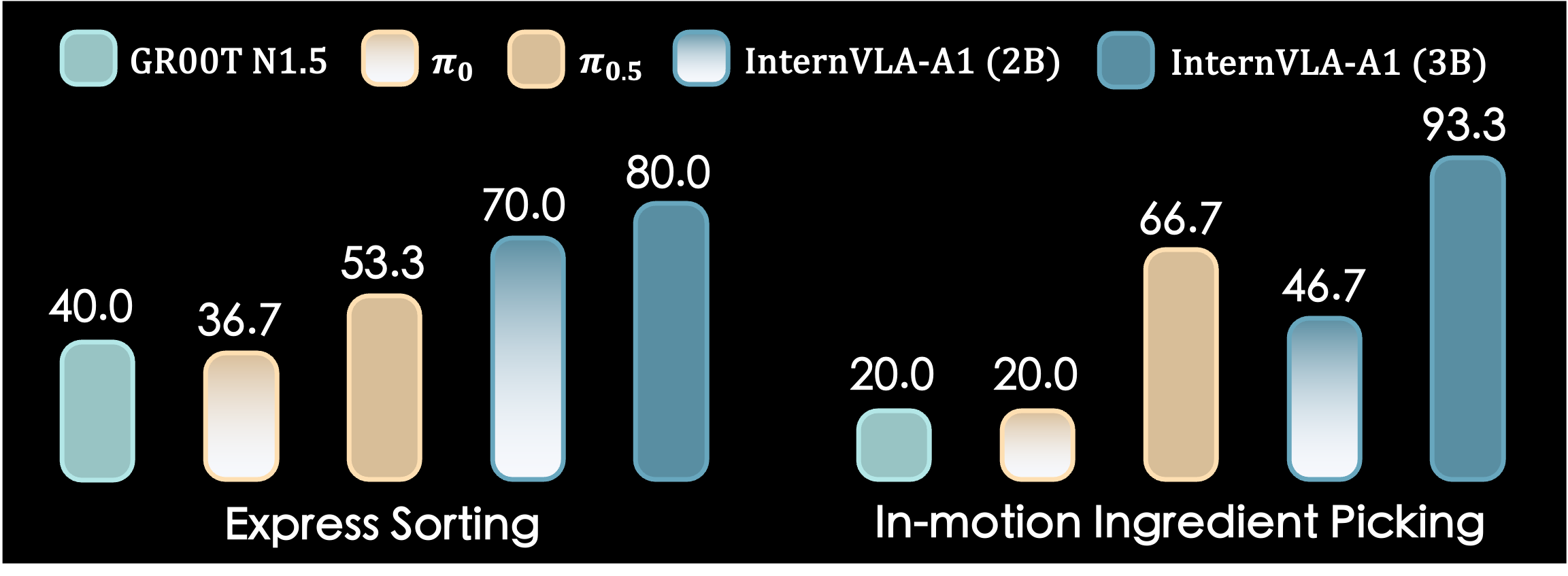
Real-world Manipulation (10 static tasks)
| Model | Avg Success Rate | vs. InternVLA-A1 |
|---|---|---|
| InternVLA-A1 (3B) | 75.1% | — |
| π0.5 | 70.7% | -4.4% |
| π0 | 60.6% | -14.5% |
| InternVLA-A1 (2B) | 64.7% | -10.4% |
Dynamic Manipulation (2 tasks with moving objects)
| Model | In-motion Ingredient Picking | Express Sorting |
|---|---|---|
| InternVLA-A1 (3B) | 93.3% | 80.0% |
| π0.5 | ~66% | ~53% |
| π0 | 20.0% | 40.0% |
The +73.3% gap over π0 on In-motion Ingredient Picking is striking. When objects are in motion, the ability to predict their future position is the deciding factor — and that's exactly what the Generation Expert provides.
RoboTwin 2.0 Simulation Benchmark (50 tasks)
| Model | Easy Setting | Hard Setting (Domain Rand.) |
|---|---|---|
| InternVLA-A1-3B | 89.40% | 89.64% |
| π0.5 | ~86.8% | ~87.0% |
Ablation: How Much Does Each Component Matter?
| Configuration | Success Rate | Drop vs. Full |
|---|---|---|
| Full InternVLA-A1 (3B) | 77.0% | — |
| Without Generation Expert | 57.6% | -19.4% |
| Without pre-training | 25.4% | -51.6% |
| Real data only (no synth) | lower | — |
Two key takeaways:
- Pre-training is critical — removing it cuts performance by more than half. 700K steps of heterogeneous pre-training is what gives the model its generalization ability.
- The Generation Expert contributes 19.4 percentage points — it's not an optional add-on.
Why Mixture-of-Transformers Instead of Two Separate Models?
A natural question: why not just run a separate VLA and a separate world model, then combine their outputs?
Three reasons MoT wins:
-
End-to-end gradient flow: During training, action loss gradients backpropagate through all three experts simultaneously, enabling co-adaptation. Two separate models can't do this.
-
Lower latency: One forward pass instead of two sequential calls. At 13 Hz real-time requirements, every millisecond counts.
-
Shared representations: The Understanding Expert learns features useful for both generation and action. Separate models must re-learn these independently, wasting capacity.
The tradeoffs: harder to debug (errors can originate from any expert), and swapping out one expert (e.g., upgrading the VLM backbone) requires retraining the whole system.
Practical Considerations for Deployment
Before integrating InternVLA-A1 into your robot stack, a few things to keep in mind:
Camera setup: The model expects multi-view RGB input (3 camera views × 2 timesteps). A single wrist-mounted camera won't cut it — plan for at least one global view + one wrist view.
Action chunk size: The model predicts action chunks of 50 steps. Your robot's control loop frequency will determine how many of those get executed before the next inference.
Dynamic vs. static scenes: The biggest gains from InternVLA-A1 over baseline VLAs appear in dynamic environments. For purely static pick-and-place on a fixed table, the performance gap narrows — the Generation Expert contributes less when nothing is moving.
Hardware: Real-time inference (~13 Hz) requires torch.compile on an RTX 4090. On smaller GPUs, expect lower throughput — profile your specific setup before committing to a control frequency.
Conclusion
InternVLA-A1 proposes a compelling answer to the semantics-dynamics gap in robot manipulation: rather than choosing between "knows semantics" and "knows physics," build an architecture where both can co-develop. The Mixture-of-Transformers with three specialized experts is InternRobotics' answer — and the benchmark results back it up, especially on dynamic manipulation tasks where traditional VLAs struggle most.
If you're building a manipulation pipeline for real-world deployment in environments where objects move, conveyor belts run, or humans interact with the workspace, InternVLA-A1 is worth serious consideration — especially given that code, model weights, and training tutorials are all open-source under CC BY-NC-SA 4.0.
References:
- InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation — InternRobotics, arXiv 2601.02456, January 2026
- GitHub Repository
- HuggingFace: InternVLA-A1-3B
- Project Homepage


