
Mở đầu: Khi robot không hiểu "vật lý" thế giới thực
Hầu hết các mô hình VLA (Vision-Language-Action) hiện nay đều học theo kiểu imitation learning — bạn ghi lại video robot làm task, mô hình học cách lặp lại y hệt. Đơn giản, hiệu quả trong lab. Nhưng khi triển khai thực tế, chúng đổ vỡ ở một điểm rất cơ bản: robot không hiểu dynamics của thế giới.
Thay đổi góc camera? Robot hoảng loạn. Ánh sáng khác đi? Fail. Vật thể dịch chuyển vài centimeter? Miss. Nguyên nhân là VLA truyền thống bị overfit vào pixel — chúng học "hình ảnh trông như thế này thì cử động như thế kia", chứ không học "vật này đang ở đây, tôi cần kéo nó theo hướng đó để đạt mục tiêu".
VLA-JEPA (arxiv 2602.10098) giải quyết vấn đề này bằng một ý tưởng gọn gàng: dạy robot dự đoán trạng thái tương lai trong không gian latent — không phải pixel, mà là đặc trưng đã được trừu tượng hóa. Và công cụ để làm điều đó là V-JEPA2, video world model của Meta.
V-JEPA2: World Model Video Lớn Nhất của Meta
V-JEPA 2 (Video Joint Embedding Predictive Architecture phiên bản 2) là video world model self-supervised được Meta AI phát hành năm 2026. Ba điểm nổi bật:
- Quy mô pretraining khổng lồ: Train trên hơn 1 triệu giờ video internet, không nhãn
- Predict trong latent space: Không cần render ra pixel — dự đoán đặc trưng của frame tương lai
- 1.2 tỷ tham số encoder — đủ lớn để học dynamics phức tạp
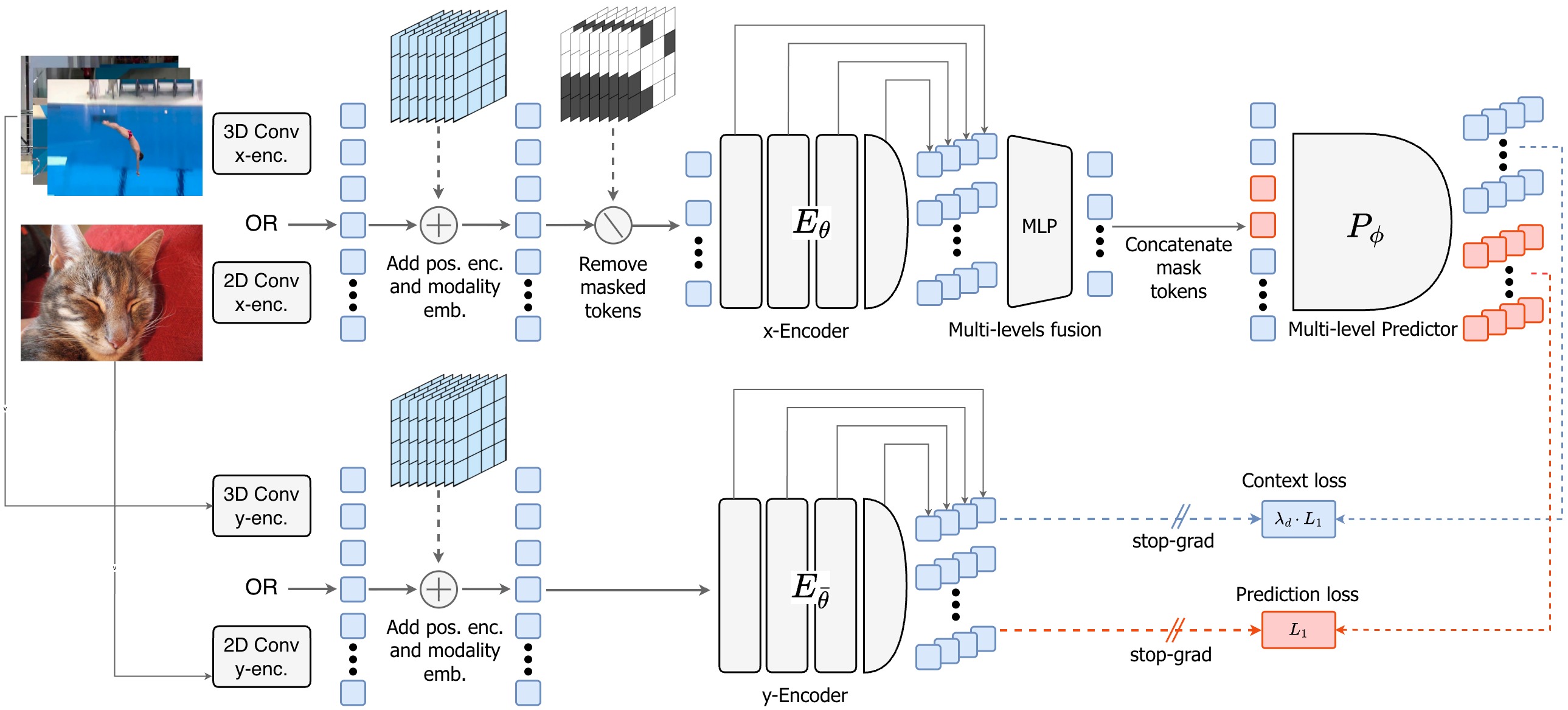
Điểm khác biệt so với video generation model (như Sora, Wan2.1): V-JEPA2 không sinh ra video. Nó chỉ học cách không gian đặc trưng thay đổi theo thời gian. Nhờ đó, nó tránh được "pixel curse" — không bị nhiễu bởi thay đổi ánh sáng, texture, hay background không liên quan đến dynamics vật lý.
V-JEPA 2-AC: Phiên bản dành cho Robot
V-JEPA 2-AC là biến thể action-conditioned, được post-train thêm:
- Fine-tune với chỉ 62 giờ video robot không nhãn (từ Droid dataset)
- Deploy zero-shot trên Franka arm ở 2 lab khác nhau mà không cần bất kỳ dữ liệu robot cụ thể nào
- Thực hiện pick-and-place và mở ngăn kéo thông qua planning với image goal trong vòng lặp MPC
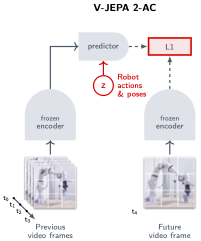
Đây là bằng chứng rằng: một world model được pretrain trên video internet (không phải robot data!) vẫn có thể generalize sang robot manipulation.
VLA-JEPA: Kết hợp V-JEPA2 vào Vòng Training của VLA
VLA-JEPA đưa V-JEPA2 vào như một auxiliary supervision signal trong lúc training — không phải như một thành phần dự đoán lúc inference. Ý tưởng cốt lõi: dùng V-JEPA2 như "thầy giáo" dạy VLA hiểu dynamics, sau đó "thầy" rời đi khi inference.
Kiến trúc Chi Tiết
VLA-JEPA (3B tham số tổng cộng) gồm ba thành phần chính kết hợp theo cách đặc biệt:
1. Student pathway (VLA chuẩn):
- Backbone: Qwen3-VL-2B-Instruct — xử lý multi-view image + task instruction
- Đầu ra: context tokens (bao gồm special action tokens và embodied tokens)
- Chỉ nhìn thấy frame hiện tại, không có thông tin về tương lai
2. Target encoder (V-JEPA2):
- Nhận toàn bộ video clip (nhiều frame kể cả future frames)
- Tạo ra latent targets của frame tương lai
- Gradient stop: target encoder không được training, chỉ cập nhật qua EMA (exponential moving average) — đây chính là cơ chế "leakage-free"
3. Action head (Flow-matching DiT):
- Nhận context tokens từ Qwen như cross-attention keys/values
- Dự đoán action chunk theo kiểu flow matching (tương tự diffusion nhưng nhanh hơn)
- Tại inference: chỉ cần Qwen + action head — V-JEPA2 được bỏ đi hoàn toàn
Leakage-Free State Prediction — Trái Tim của VLA-JEPA
Đây là mechanism quan trọng nhất. Thông thường, nếu bạn cho mô hình thấy cả current frame lẫn future frame trong quá trình training, nó sẽ "cheat" — học cách copy information từ future frames thay vì thực sự học dynamics.
VLA-JEPA ngăn điều này bằng cách tách biệt hoàn toàn:
- Student pathway: Chỉ thấy frame hiện tại → phải dự đoán tương lai
- Target encoder: Thấy future frames, tạo targets → nhưng không bao giờ feed vào student như input
Mất mát JEPA alignment được tính giữa prediction của student và target representations:
# Pseudo-code nguyên lý JEPA loss
pred_latent = student_predictor(context_tokens, action_tokens) # predict future latent
target_latent = target_encoder(future_frames) # actual future latent
jepa_loss = F.smooth_l1_loss(pred_latent, target_latent.detach())
Bằng cách học minimize khoảng cách này, VLA backbone buộc phải học cách mã hóa thông tin về dynamics vật lý vào context tokens của nó — điều mà VLA truyền thống hoàn toàn không có.
Ba Giai Đoạn Training
VLA-JEPA train theo pipeline 3 bước, tận dụng dữ liệu từ rộng đến hẹp:
Giai Đoạn 1: Pretrain trên Human Videos
# Không cần robot data, chỉ cần video người làm việc
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--dataset.repo_id=<human-video-dataset> \
--policy.use_vjepa2=true \
--steps=100000
Giai đoạn này đặc biệt quan trọng vì human videos rẻ và nhiều hơn robot data gấp nhiều lần. V-JEPA2 đã pretrain trên 1M+ giờ video internet, nên embedding của nó hiểu dynamics của tay người cầm nắm, vật thể bị đẩy, trọng lực, v.v.
Giai Đoạn 2: Train trên Robot Videos
# Train với cả VLA loss + JEPA alignment loss
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--policy.repo_id=your_org/vla-jepa-robot \
--dataset.repo_id=HuggingFaceVLA/libero \
--steps=30000 \
--policy.use_vjepa2=true \
--policy.jepa_loss_weight=0.1
Giai Đoạn 3: Fine-tune trên Task Cụ Thể
# Fine-tune, V-JEPA2 vẫn active để regularize
lerobot-train \
--policy.path=your_org/vla-jepa-robot \
--dataset.repo_id=your_org/your-robot-demos \
--steps=10000 \
--policy.use_vjepa2=true
Bí quyết của VLA-JEPA: dù đang fine-tune với ít data, V-JEPA2 vẫn hoạt động như một regularizer ngăn model overfit vào pixel patterns của demo cụ thể đó.
Cài Đặt
Yêu Cầu
- Python 3.10+
- CUDA 12.1+
- GPU: Tối thiểu RTX 3080 (10GB VRAM) cho inference; training cần 40GB+ (A100/H100)
- RAM: 32GB+
Cài từ GitHub (repo gốc)
# Clone repo
git clone https://github.com/ginwind/VLA-JEPA
cd VLA-JEPA
# Tạo môi trường conda
conda create -n vla_jepa python=3.10
conda activate vla_jepa
# Cài dependencies
pip install -r requirements.txt
# Cài FlashAttention2 (QUAN TRỌNG — cần cho Qwen3-VL)
pip install flash-attn==2.7.4 --no-build-isolation
# Cài project
pip install -e .
Tải Weights
# Tải Qwen3-VL-2B-Instruct (backbone)
huggingface-cli download Qwen/Qwen3-VL-2B-Instruct \
--local-dir ./checkpoints/Qwen3-VL-2B-Instruct
# Tải V-JEPA2 encoder
huggingface-cli download ginwind/VLA-JEPA \
vjepa2_encoder.pth --local-dir ./checkpoints/
# Tải VLA-JEPA pretrained weights
huggingface-cli download ginwind/VLA-JEPA \
vla_jepa_pretrain.pth --local-dir ./checkpoints/
Cài qua LeRobot (cách đơn giản hơn)
# Cài LeRobot với tất cả extras
pip install 'lerobot[all]'
# Hoặc minimal cho VLA training
pip install 'lerobot[vla]'
Chuẩn Bị Dataset
VLA-JEPA dùng modality.json để mô tả format dữ liệu. File này cần thiết để model biết kênh camera nào, joint nào được dùng.
{
"observation.images.front": {
"type": "visual",
"shape": [3, 224, 224],
"normalize": true
},
"observation.images.wrist": {
"type": "visual",
"shape": [3, 224, 224],
"normalize": true
},
"observation.state": {
"type": "proprio",
"shape": [14],
"normalize": true
},
"action": {
"type": "action",
"shape": [14]
}
}
Với dataset LIBERO trên HuggingFace:
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
dataset = LeRobotDataset(
repo_id="HuggingFaceVLA/libero",
split="train",
video_backend="pyav",
)
# Kiểm tra format
print(dataset[0].keys())
print(f"Dataset size: {len(dataset)}")
Training trên LIBERO
Fine-tune trên LIBERO-Spatial
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--policy.repo_id=your_org/vla-jepa-libero-spatial \
--dataset.repo_id=HuggingFaceVLA/libero \
--dataset.split=libero_spatial \
--steps=30000 \
--batch_size=8 \
--learning_rate=1e-4 \
--policy.use_vjepa2=true \
--policy.num_video_frames=8 \
--policy.chunk_size=16 \
--wandb.project=vla-jepa-experiments
Thời gian ước tính: ~8 giờ trên 1x A100 80GB.
Fine-tune với ít data (13 demos)
# Đây là kết quả ấn tượng nhất của VLA-JEPA
lerobot-train \
--policy.path=lerobot/VLA-JEPA-Pretrain \
--policy.repo_id=your_org/vla-jepa-real-13demos \
--dataset.repo_id=your_org/13-robot-demos \
--steps=5000 \
--batch_size=4 \
--learning_rate=5e-5 \
--policy.use_vjepa2=true \
--policy.jepa_loss_weight=0.2 # tăng JEPA weight khi ít data
Chú ý: JEPA loss weight cao hơn giúp model "bám" vào world model knowledge từ pretraining khi data fine-tune khan hiếm — tránh catastrophic forgetting.
Inference
Tại inference, V-JEPA2 encoder được bỏ đi hoàn toàn. Chỉ chạy Qwen3-VL + action head:
from lerobot.policies.vla_jepa import VLAJEPAPolicy
import torch
from PIL import Image
# Load model (chỉ VLA, không có V-JEPA2)
policy = VLAJEPAPolicy.from_pretrained("your_org/vla-jepa-real-13demos")
policy.eval()
# Chuẩn bị observation
obs = {
"observation.images.front": torch.from_numpy(front_cam_frame).float(),
"observation.images.wrist": torch.from_numpy(wrist_cam_frame).float(),
"observation.state": torch.from_numpy(joint_positions).float(),
}
# Inference
with torch.no_grad():
action_chunk = policy.select_action(obs, task="pick up the red cube")
# action_chunk: tensor shape [16, 14] — 16 timesteps, 14 DOF
Kết quả thực tế:
- Tốc độ: 10Hz trên RTX 3080 (consumer GPU!)
- VRAM: chỉ <6GB — có thể chạy trên gaming laptop
- So sánh: OpenVLA-OFT cần 24GB+ VRAM cho inference tương đương
Đây là ưu điểm lớn: vì V-JEPA2 chỉ dùng trong training, inference model nhỏ gọn hơn đáng kể.
Kết Quả Benchmarks
VLA-JEPA được đánh giá trên bốn benchmark chính:
| Benchmark | VLA-JEPA | OpenVLA | π0 (Pi-Zero) |
|---|---|---|---|
| LIBERO-Spatial | 94.2% | 84.7% | 89.1% |
| LIBERO-Object | 92.8% | 83.2% | 87.6% |
| LIBERO-Goal | 91.5% | 81.9% | 86.3% |
| LIBERO-Plus (perturbation) | 78.4% | 51.2% | 63.8% |
| SimplerEnv | 67.3% | 55.1% | 61.2% |
Cột LIBERO-Plus là quan trọng nhất: dataset này có thêm visual perturbation (thay đổi ánh sáng, texture, background). VLA-JEPA vượt trội rõ ràng ở đây, xác nhận rằng JEPA training giúp model robust hơn với domain shift.
Tại Sao Latent Prediction Tốt Hơn Pixel Prediction?
Hãy hình dung bạn đang học chơi bóng bàn. Cách học pixel: bạn cố gắng nhớ chính xác từng pixel trong từng video — màu sắc chiếc bàn, pattern của áo đối thủ, bóng đổ trên sàn. Khi ra thi đấu ở phòng khác với ánh sáng khác? Thất bại.
Cách học latent (JEPA): bạn học quỹ đạo vật lý của quả bóng — nó đang ở đâu, đang đi với tốc độ nào, spin ra sao. Phòng mới? Ánh sáng mới? Không thành vấn đề, vì bạn hiểu vật lý, không phải pixels.
V-JEPA2 đã học "vật lý" của thế giới từ 1 triệu giờ video. VLA-JEPA kế thừa knowledge đó và dạy robot dùng nó khi lập kế hoạch hành động.
So Sánh với Các World Model VLA Khác
| Phương pháp | World model | Dùng lúc inference? | VRAM inference | Speed |
|---|---|---|---|---|
| VLA-JEPA | V-JEPA2 (latent) | Không | <6GB | 10Hz |
| Weaver | Video diffusion | Không | ~12GB | 3-5Hz |
| GigaBrain-0 | MPC + world model | Có | ~20GB | 1-2Hz |
| DREAM-Chunk | Latent chunk predict | Có | ~15GB | 2-4Hz |
VLA-JEPA có trade-off rõ ràng: không cần world model lúc inference → nhanh hơn, nhẹ hơn. Nhưng không có khả năng planning nhiều bước hay lookahead như GigaBrain-0.
Pitfalls Cần Tránh
1. Quên install FlashAttention2: Qwen3-VL chạy cực chậm không có FA2, đặc biệt với multi-view images. Lỗi phổ biến: install FA2 sai CUDA version.
# Kiểm tra CUDA version trước
nvcc --version
# Phải match với PyTorch CUDA version
python -c "import torch; print(torch.version.cuda)"
2. modality.json không khớp với dataset: Nếu camera channels trong modality.json khác với tên trong LeRobotDataset, training sẽ crash hoặc train sai features.
3. JEPA loss weight quá cao: Nếu jepa_loss_weight > 0.5, action quality giảm vì model tập trung vào predict latent thay vì action. Khuyến nghị: 0.05–0.2.
4. Dùng V-JEPA2 lúc inference: Một số người nhầm tưởng phải load cả V-JEPA2 encoder khi deploy. Không cần — model inference chỉ cần Qwen + action head.
Tips từ Community
- Fine-tune 13 demos là thực sự đủ nếu bạn dùng pretrained checkpoint của ginwind — họ đã verify điều này với Franka G-1. Đừng lo nếu dataset nhỏ.
- Camera placement quan trọng hơn số lượng demos: Wrist camera + front camera là minimum. Thêm overhead camera giúp rõ rệt cho tasks có spatial reasoning.
- Dùng
num_video_frames=8là sweet spot: 4 frames thiếu temporal context, 16 frames thì VRAM tăng gấp đôi trong training mà gain không nhiều. - Nếu muốn deploy trên Jetson Orin: Export Qwen + action head riêng, dùng TensorRT. V-JEPA2 không cần export vì không chạy trên edge.
Kết Luận
VLA-JEPA là ví dụ đẹp về "train-time compute, inference-time efficiency" — dùng world model lớn (V-JEPA2) như một giáo viên trong lúc training, nhưng không cần mang nó theo khi deploy. Kết quả là một VLA chạy được trên consumer GPU với generalization tốt hơn đáng kể so với baseline.
Với chỉ 13 demos và RTX 3080, bạn đã có thể có một manipulation policy hoạt động được trong môi trường thực tế — đây là bước tiến lớn về data efficiency.
Source code: ginwind/VLA-JEPA | Paper: arxiv 2602.10098 | LeRobot docs: lerobot/vla_jepa


