
Hãy tưởng tượng bạn đang dạy robot nhặt một gói hàng từ băng chuyền đang chạy. Có hai trường phái tiếp cận: nhóm thứ nhất dạy robot "đọc hiểu" ngữ cảnh — biết đây là gói hàng, biết phải đặt vào giỏ — nhưng lại không cảm nhận được vật thể đang di chuyển. Nhóm thứ hai xây dựng một World Model để "tưởng tượng" tương lai — biết gói hàng sẽ ở đâu sau 0.5 giây — nhưng lại hay vỡ khi dự đoán sai.
InternVLA-A1 từ InternRobotics chọn con đường thứ ba: hợp nhất cả hai trong một kiến trúc Mixture-of-Transformers duy nhất, để ba chuyên gia — hiểu ngữ nghĩa, nhìn thấy tương lai, và ra lệnh hành động — cùng làm việc trong một forward pass.
Kết quả? 75.1% thành công trên 10 tác vụ thực tế, vượt π0.5 tới +26.7% trên các tác vụ động như phân loại băng chuyền.
Vấn đề: Khoảng cách giữa Ngữ nghĩa và Vật lý
Trước khi đào sâu vào kiến trúc, hãy hiểu tại sao đây là một bài toán khó.
VLA thuần túy (như OpenVLA, π0) xây dựng trên nền tảng MLLM — chúng giỏi hiểu ngôn ngữ, nhận biết vật thể, và lập luận ngữ nghĩa. Khi bạn nói "đặt ly nước lên bàn bên trái", robot hiểu ngay. Nhưng chúng mù về động học vật lý: không biết vật thể đang bay, đang lắc, hay đang trượt.
World Model thuần túy (như video prediction models) thì ngược lại: chúng dự đoán khung hình tiếp theo một cách chính xác, nhưng không hiểu ngữ nghĩa của tác vụ. Hơn nữa, lỗi tích lũy (compounding errors) là ác mộng của world model — một dự đoán sai dẫn đến loạt dự đoán sai tiếp theo.
InternVLA-A1 giải quyết "khoảng cách ngữ nghĩa-động học" (semantics-dynamics gap) bằng cách để hai bên hỗ trợ nhau: world model không cần dự đoán hoàn hảo để hành động đúng; VLA không cần tự suy ra vật lý nếu đã có cảnh báo từ world model.
Kiến trúc Mixture-of-Transformers (MoT)
Đây là trái tim của InternVLA-A1. Ba chuyên gia (experts) hoạt động trong một kiến trúc transformer hợp nhất, giao tiếp qua masked self-attention có chủ đích.
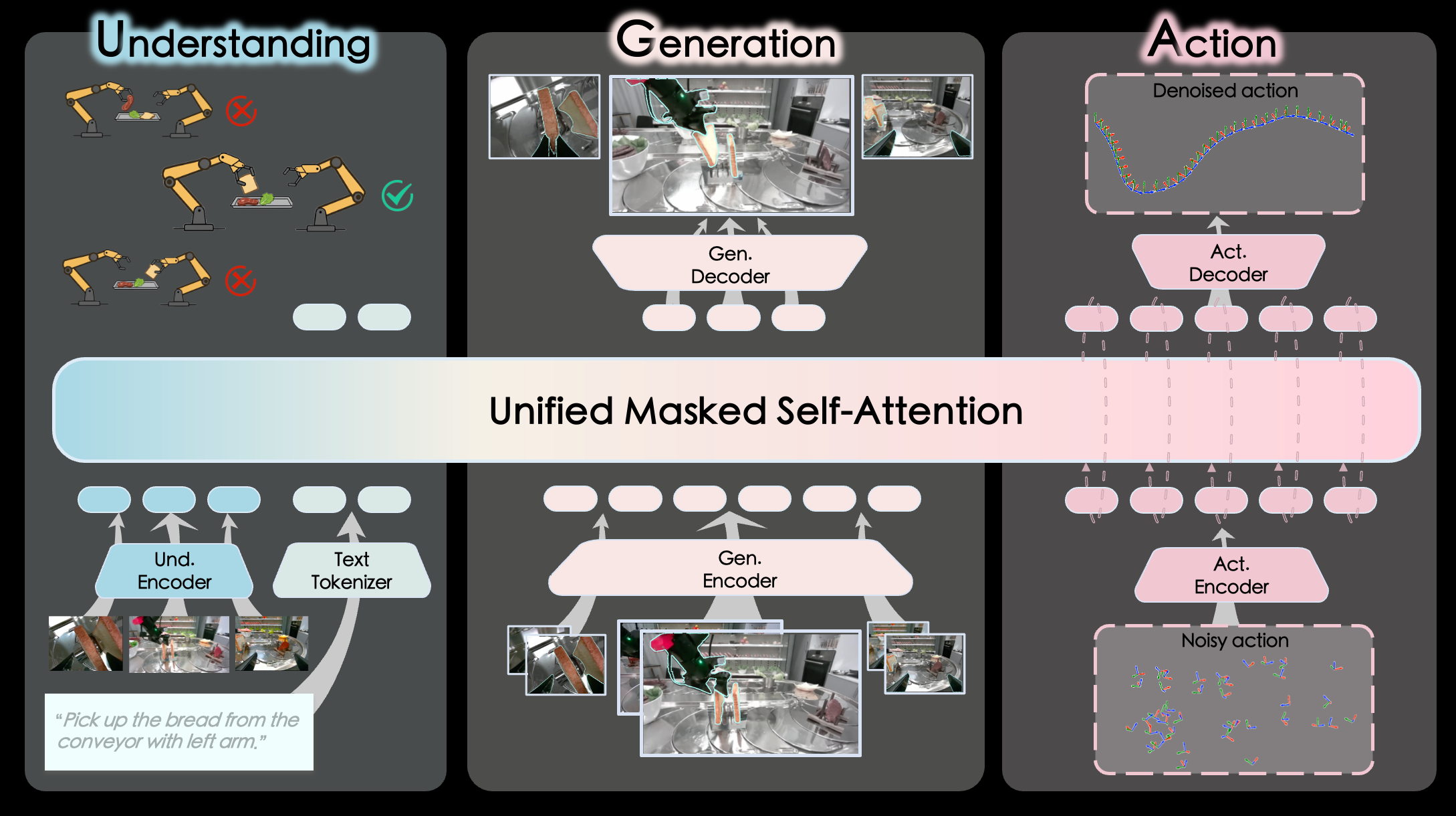
Expert 1: Understanding Expert
Đây là bộ não ngôn ngữ-thị giác. InternVLA-A1 có hai biến thể:
| Biến thể | Understanding Expert | Tổng tham số | Tốc độ |
|---|---|---|---|
| 2B | InternVL3 (0.94B) | ~1.8B | ~13 Hz |
| 3B | Qwen3-VL (2.13B) | ~3.2B | ~13 Hz |
Expert này nhận ảnh RGB từ nhiều góc camera cùng câu lệnh ngôn ngữ, tạo ra contextual embeddings mã hóa ngữ nghĩa tác vụ. Nó trả lời câu hỏi: "Đây là tác vụ gì? Vật thể nào liên quan? Trạng thái hiện tại là gì?"
Expert 2: Generation Expert (World Model)
Đây là "con mắt nhìn vào tương lai". Thay vì tạo video full-resolution (cực kỳ chậm), Generation Expert dùng COSMOS VAE tokenizer để nén hình ảnh:
6 ảnh đầu vào (3 góc camera × 2 timestep)
↓ COSMOS VAE encoder
Token latent 32×32 mỗi ảnh
↓ Convolution compression
Token 4×4 mỗi ảnh (giảm 64×)
↓ Parallel decoding
Dự đoán latent tương lai tại t+15
Bí quyết hiệu suất nằm ở parallel decoding — toàn bộ latent tương lai được dự đoán trong một forward pass duy nhất, thay vì sinh từng token một như autoregressive generation. Đây là lý do tại sao mô hình vẫn đạt ~13 Hz thực thi thời gian thực.
Generation Expert trả lời: "Ở t+15, vật thể sẽ ở đâu? Cánh tay robot sẽ trông như thế nào?"
Expert 3: Action Expert
Expert cuối cùng tổng hợp thông tin từ hai expert trên để đưa ra lệnh điều khiển robot. Nó dùng Flow Matching — một phương pháp hiệu quả hơn Diffusion Policy truyền thống — để tạo ra phân phối liên tục của hành động.
Flow Matching học một trường vận tốc (velocity field) để biến đổi nhiễu Gaussian thành phân phối hành động mục tiêu, thường hội tụ nhanh hơn DDPM với ít bước suy luận hơn.
Luồng Thông tin: Masked Self-Attention
Ba experts không hoạt động độc lập — chúng giao tiếp qua masked self-attention có hướng:
Understanding → Generation → Action
↑ ↑
└──────────────┘
(không có chiều ngược lại)
Understanding embeddings được Action Expert "nhìn thấy" trực tiếp, và Generation embeddings cũng vậy. Nhưng Action Expert không "gây ô nhiễm" ngược lại Understanding hay Generation. Cơ chế này đảm bảo:
- Action luôn được informed bởi cả ngữ nghĩa lẫn dự đoán vật lý
- World model prediction không bị "lệch" bởi bias hành động
Chi tiết Training: Hai Giai Đoạn
Giai đoạn 1: Pre-training ở Quy Mô Lớn
Pre-training kéo dài 700,000 bước, học từ 692 triệu frames từ các nguồn dị cấu hình:
| Nguồn | Loại | Số frames | Trọng số |
|---|---|---|---|
| InternData-A1 | Simulation | 396M | 0.64 |
| AgiBot-World | Real-world robot | 206M | 0.18 |
| EgoDex | Human video (không có action label) | 68M | 0.08 |
| RoboTwin | Simulation | 17M | 0.08 |
| RoboMind | Real-world robot | 5M | 0.02 |
Điểm đáng chú ý: EgoDex là video góc nhìn người đầu tiên (egocentric) — không có nhãn hành động robot. InternVLA-A1 học từ chúng chỉ qua mục tiêu dự đoán hình ảnh. Ablation study trong paper cho thấy huấn luyện trên dữ liệu dị cấu hình (kết hợp sim + real + human video) cho kết quả tốt nhất so với chỉ dùng một loại.
Hàm loss huấn luyện:
L_total = λ · L_gen + L_act
Trong đó:
L_gen: L2 loss trên latent dự đoán tương lai (so với ground truth từ VAE encoder)L_act: Flow matching loss cho phân phối hành độngλ = 0.01: Cân bằng hai mục tiêu — generation không được "lấn át" action
Giai đoạn 2: Post-training (Task-Specific)
Sau pre-training, model được fine-tune 60,000 bước với learning rate thấp hơn trên dữ liệu tác vụ cụ thể. Đây là giai đoạn bạn sẽ chạy khi muốn deploy lên robot của mình.
Cài Đặt và Chạy InternVLA-A1
Yêu cầu hệ thống
Python 3.10
CUDA 12.8
PyTorch 2.7.1
GPU: NVIDIA RTX 4090 (hoặc tương đương, ≥24GB VRAM)
Cài đặt
# Clone repo
git clone https://github.com/InternRobotics/InternVLA-A1.git
cd InternVLA-A1
# Tạo conda environment
conda create -n internvla python=3.10
conda activate internvla
# Cài dependencies (xem installation.md trong tutorials/ để chi tiết)
pip install -e .
Tải model weights
# Model 3B base (dùng cho real-world)
huggingface-cli download InternRobotics/InternVLA-A1-3B
# Model 3B đã fine-tune trên RoboTwin 2.0
huggingface-cli download InternRobotics/InternVLA-A1-3B-RoboTwin
Inference nhanh
Notebook ví dụ nằm tại tests/policies/internvla_a1_3b/open_loop_genie1_real.ipynb — chạy inference open-loop trên dữ liệu thực tế.
Fine-tuning trên Dữ Liệu Của Bạn (LeRobot V2.1)
Đây là workflow để deploy InternVLA-A1 lên robot thực tế với dữ liệu tự thu thập.
Bước 1: Tải dataset mẫu
# Ví dụ: task "Put pen into pen holder" từ Genie-1 real-robot dataset
hf download \
InternRobotics/InternData-A1 \
real/genie1/Put_the_pen_from_the_table_into_the_pen_holder.tar.gz \
--repo-type dataset \
--local-dir data
Bước 2: Giải nén và tổ chức
tar -xzf data/real/genie1/Put_the_pen_from_the_table_into_the_pen_holder.tar.gz -C data
rm -rf data/real
mkdir -p data/v21
mv data/set_0 data/v21/a2d_pick_pen
Bước 3: Chuyển đổi format V2.1 → V3.0
InternVLA-A1 dùng LeRobot V3.0 format nội bộ. Nếu dataset của bạn ở V2.1 (phổ biến hơn), cần convert:
python src/lerobot/datasets/v30/convert_my_dataset_v21_to_v30.py \
--old-repo-id v21/a2d_pick_pen \
--new-repo-id v30/a2d_pick_pen
Bước 4: Tính normalization statistics
python util_scripts/compute_norm_stats_single.py \
--action_mode delta \
--chunk_size 50 \
--repo_id v30/a2d_pick_pen
Bước 5: Chạy fine-tuning
# Format: bash launch/internvla_a1_3b_finetune.sh <dataset> <action_mode> <use_stats_file>
bash launch/internvla_a1_3b_finetune.sh v30/a2d_pick_pen delta true
# Với dataset LeRobot chuẩn (absolute action)
bash launch/internvla_a1_3b_finetune.sh lerobot/pusht abs false
Lưu ý quan trọng: Trước khi chạy script, mở launch/internvla_a1_3b_finetune.sh và cấu hình:
HF_HOME: đường dẫn cache HuggingFaceWANDB_API_KEY: key cho W&B logging (nếu dùng)CONDA_ROOT: đường dẫn conda installation- CUDA device settings
Kết Quả Benchmark
Real-world manipulation (10 tác vụ tĩnh)
| Model | Thành công TB | So với InternVLA-A1 |
|---|---|---|
| InternVLA-A1 (3B) | 75.1% | — |
| π0.5 | 70.7% | -4.4% |
| π0 | 60.6% | -14.5% |
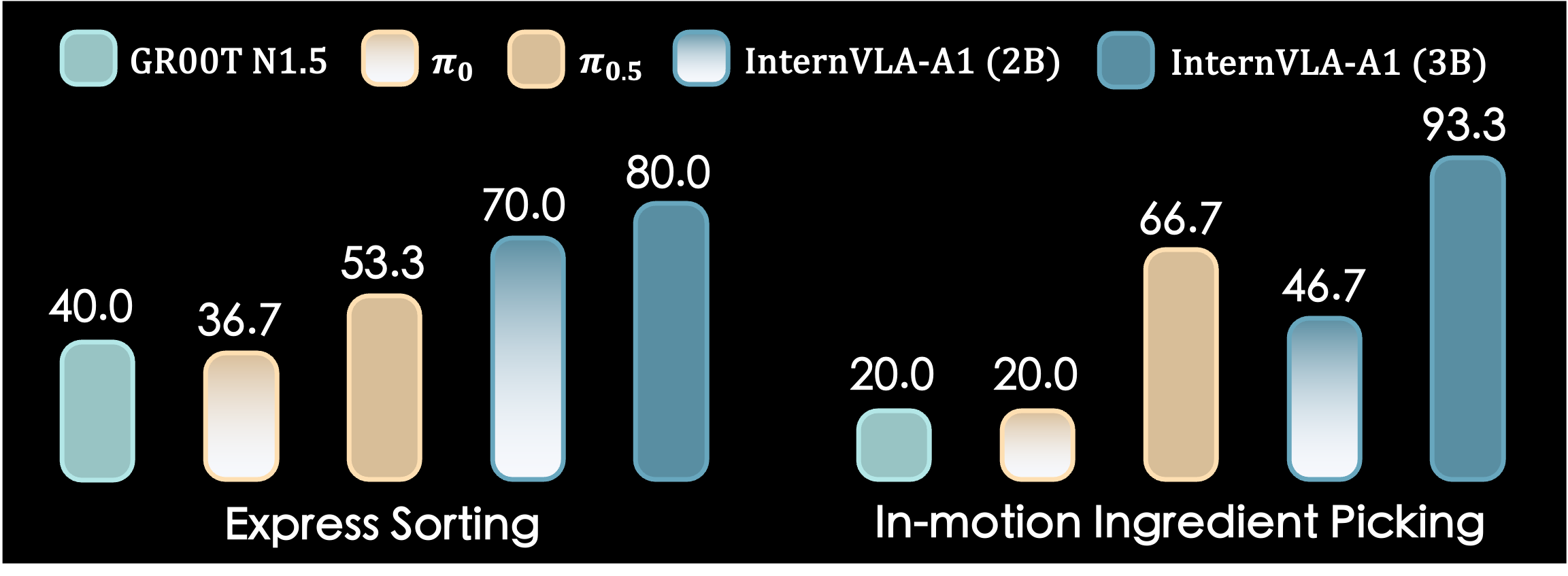
Dynamic manipulation (2 tác vụ có vật thể chuyển động)
| Model | In-motion Ingredient Picking | Parcel Sorting |
|---|---|---|
| InternVLA-A1 (3B) | ~93% | ~80% |
| π0.5 | ~66% | ~55% |
Khoảng cách +26.7% trên In-motion Ingredient Picking là minh chứng rõ nhất cho giá trị của Generation Expert: khi vật thể đang di chuyển, khả năng dự đoán vật lý là yếu tố quyết định.
Ablation: Tại sao Generation Expert quan trọng?
Paper so sánh model đầy đủ với phiên bản bỏ Generation Expert:
- Với Generation Expert: 77.0% thành công
- Không có Generation Expert: 57.6% thành công
- Chênh lệch: -19.4%
Đây là bằng chứng định lượng rằng world model không chỉ là "optional add-on" — nó cốt lõi với hiệu suất của mô hình.
Tại sao Mixture-of-Transformers thay vì Pipeline Riêng Biệt?
Câu hỏi hay: tại sao không dùng hai model riêng — một VLA và một world model — rồi kết hợp output?
Ba lý do MoT tốt hơn:
-
Gradient chảy xuyên suốt: Trong training, lỗi từ action loss có thể "ngược dòng" ảnh hưởng cả understanding và generation, tạo ra sự co-adaptation. Hai model riêng biệt không có điều này.
-
Latency thấp hơn: Một forward pass duy nhất thay vì hai serial calls. Với yêu cầu 13 Hz real-time, mỗi millisecond đều quan trọng.
-
Shared representations: Understanding Expert học features hữu ích cho cả generation lẫn action. Nếu tách biệt, mỗi bên phải học lại từ đầu.
Nhược điểm: khó debug hơn vì lỗi có thể xuất phát từ bất kỳ expert nào. Và khi muốn thay thế một expert (ví dụ: dùng VLM tốt hơn), phải re-train toàn bộ.
Kết Luận
InternVLA-A1 đặt ra một paradigm thú vị: thay vì chọn giữa "biết nghĩa" và "biết vật lý", hãy xây dựng kiến trúc cho phép cả hai cùng phát triển. Mixture-of-Transformers với ba chuyên gia là câu trả lời của InternRobotics — và kết quả benchmark cho thấy đây là hướng đi đúng, đặc biệt với các tác vụ có đối tượng chuyển động.
Nếu bạn đang xây dựng pipeline manipulation cho robot thực tế và cần khả năng thích ứng với môi trường động, InternVLA-A1 là lựa chọn đáng thử nghiệm — đặc biệt khi code và model weights đã open-source hoàn toàn.
Tham khảo:
- InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation — InternRobotics, arXiv 2601.02456, tháng 1/2026
- GitHub Repository
- HuggingFace Model: InternVLA-A1-3B


