WEAVER giải quyết vấn đề gì?
WEAVER, tên đầy đủ là World Estimation Across Views for Embodied Reasoning, là paper arXiv 2606.13672 với tiêu đề WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation. Project page nằm tại arnavkj1995.github.io/WEAVER và code chính thức ở arnavkj1995/WEAVER. Điểm đáng chú ý là WEAVER không cố thay thế π0.5. Nó đóng vai trò như một learned simulator cho manipulation: dự đoán tương lai của robot trong latent space, chấm reward/value cho các action chunk, rồi dùng kết quả đó để đánh giá, cải thiện hoặc steer policy.
Nếu bạn đã đọc VLA models trong robotics, Pi0-FAST training, hoặc RISE world model cho VLA-RL, pattern sẽ rất quen: VLA policy đã đủ mạnh để làm nhiều thao tác thật, nhưng vẫn dễ fail khi object lệch khỏi distribution, gripper che mất vật, hoặc task cần nhiều bước liên tục. π0.5 là một robot foundation policy mạnh, nhưng bản thân policy không tự biết trước action nào sẽ dẫn tới thất bại. WEAVER thêm một lớp "imagination" phía trước execution: lấy observation hiện tại, ngôn ngữ task và nhiều action candidates, tưởng tượng outcome, rồi chọn hoặc distill action tốt hơn.
Paper đặt ra ba tiêu chí cho world model trong robotics. Thứ nhất là fidelity: rollout mô phỏng phải tương quan với kết quả thật, không chỉ đẹp mắt. Thứ hai là consistency: dự đoán phải giữ coherent qua horizon dài, nhất là khi wrist camera xoay, object bị che, towel/bag biến dạng hoặc hạt đậu rơi khỏi cốc. Thứ ba là efficiency: inference phải đủ nhanh để dùng cho planning tại test time. WEAVER báo cáo correlation ρ = 0.870 với success rate thật trong policy evaluation sau finetune, cải thiện success rate 38% khi fine-tune π0.5 bằng real + synthetic data, và tăng 14% success rate trong test-time planning với tốc độ nhanh hơn prior WMs khoảng 5-10x.
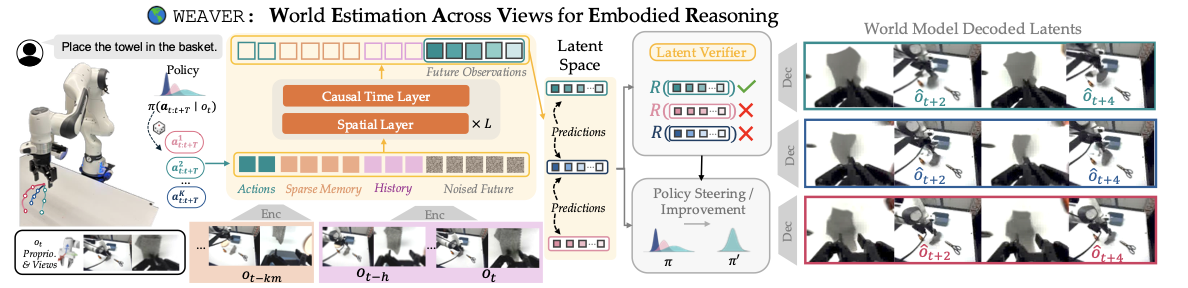
Ý tưởng paper theo cách dễ hiểu
Hãy tưởng tượng bạn có một π0.5 policy đang điều khiển Franka Panda. Mỗi lần policy nhận camera images và instruction như "put the towel into the basket", nó xuất ra một action chunk. Cách baseline thông thường là execute chunk đó ngay trên robot thật. Nếu chunk sai, robot làm hỏng bước hiện tại và bạn chỉ biết sau khi đã tốn một rollout.
WEAVER thay quy trình đó bằng vòng lặp:
multi-view observation + proprioception + instruction
|
v
π0.5 samples several candidate action chunks
|
v
WEAVER imagines future latents for each chunk
|
v
reward head + critic estimate advantage
|
v
choose best chunk, label policy data, or evaluate rollout
World model không cần decode mọi latent thành image ở mọi bước. Đây là điểm rất quan trọng. Nếu cứ generate video rồi đưa từng frame vào VLM judge, latency sẽ quá cao. WEAVER giữ phần scoring trong latent space: reward head đo progress của task, critic ước lượng return còn lại sau imagined horizon. Khi cần debug hoặc visualize, decoder mới biến latent thành multi-view images.
Với beginner, bạn có thể hiểu WEAVER là "simulator học từ data" nhưng thực tế hơn simulator cổ điển ở ba điểm. Nó không cần mesh/object physics chính xác cho từng vật. Nó học trực tiếp từ DROID và rollout thật. Nó chấm được action theo task language, không chỉ dự đoán pixel. Đổi lại, nó không phải simulator vật lý hoàn hảo: nếu camera không thấy contact, force hoặc object ở sau occlusion, model vẫn có thể đoán sai.
Kiến trúc WEAVER
WEAVER là một 928M parameter multi-view latent world model. Input chính gồm camera views, proprioceptive state, language instruction và action plan. Trong setup paper, robot dùng Franka Emika Panda, hai external Zed 2i cameras, một wrist-mounted Zed Mini, nhưng WEAVER và π0.5 chủ yếu dùng right external view và wrist view. Dữ liệu được downsample về 5 Hz cho imagination.
Các thành phần chính:
| Thành phần | Vai trò | Ghi chú triển khai |
|---|---|---|
| SD3 VAE encoder/decoder | Nén camera frames thành latent và decode khi cần visualization | Mỗi view được encode thành patch tokens |
| Proprioception token | Đưa joint/gripper state vào cùng token dimension | Giúp contact-rich manipulation tốt hơn chỉ nhìn pixel |
| Sparse memory | Lưu mỗi vài frame trong quá khứ xa | Giữ context khi object ra khỏi FOV |
| Short-term history | Lưu hai frame gần nhất | Bắt motion và consequence của action gần đây |
| 32-layer dynamics Transformer | Dự đoán future latents conditioned on action tokens | Dùng spatial attention + causal temporal attention |
| Reward head | Chấm progress trong latent space | Distill từ RoboMeter progress rewards |
| Critic head | Ước lượng return sau imagined horizon | Giúp chọn action chunk bằng advantage |
Về training objective, WEAVER dùng flow matching để học vector field đưa noise về future latent thật. Thay vì tạo từng frame bằng diffusion schedule nặng, model học dự đoán velocity trong latent space. Paper còn dùng Diffusion Forcing, tức các future timesteps có noise level độc lập, giúp rollout dài coherent hơn. Để tăng tốc, WEAVER dùng SPRINT blocks để drop patch tokens, KV caching cho memory/history tokens trong denoising, cosine/power noise schedules, và ReFlow post-training để distill teacher nhiều bước thành student ít bước hơn.
Cài đặt repo
WEAVER là project research nặng GPU. Bạn có thể đọc code và chạy inference/evaluation với checkpoint release, nhưng training đầy đủ không phải workload cho laptop. Repo ghi rõ các launcher training dùng 4 H100 GPUs với distributed data parallelism. Nếu mục tiêu của bạn là học pipeline, hãy bắt đầu bằng checkpoint và dataset nhỏ trước.
Môi trường cơ bản:
git clone --recurse-submodules https://github.com/arnavkj1995/WEAVER.git
cd WEAVER
uv venv --python 3.11
source .venv/bin/activate
uv sync
Nếu cần logging hoặc dev tools:
uv sync --extra logging --extra dev
Tải model weights:
hf download arnavkj1995/WEAVER --local-dir checkpoints
Lệnh này tải các folder WEAVER, WEAVER-FT và WEAVER-ReFlow, mỗi folder có checkpoint.pt, config.yaml và norm_stats_relabel.json. Nếu muốn thử OOD evaluation data của paper:
git lfs install
git clone https://huggingface.co/datasets/yilin-wu/droid_ood_data
Nếu chỉ cần annotations và metadata để đọc cấu trúc:
from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="yilin-wu/droid_ood_data",
repo_type="dataset",
allow_patterns=["annotations/**", "annotation_rewards/**", "norm_stats*.json"],
)
Chuẩn bị dataset
WEAVER kỳ vọng dữ liệu kiểu DROID đã preprocess, gồm actions, robot states, language features, rewards, norm stats, videos hoặc SD3 latents. Với DROID raw:
python datasets/preprocess_droid.py \
--data_root /path/to/raw_droid \
--output_root /path/to/preprocessed_droid
Output quan trọng có dạng:
weaver_droid/
├── annotations/<split>/<trajectory_id>.json
├── videos/<split>/<trajectory_id>.mp4
├── latents/<split>/<trajectory_id>.npz
└── done/<split>/<trajectory_id>
Sau preprocess, tính normalization statistics:
python datasets/compute_norm_stats.py \
--data_root /path/to/weaver_droid
Với rollout tự collect, repo cung cấp third_party/openpi/examples/droid/panda_log.py để chạy OpenPI policy server, log video + annotation JSON, rồi convert sang WEAVER format:
python -m datasets.preprocess_droid_ood \
--input_roots /path/to/your/task_folder \
--output_root /path/to/weaver_format_data \
--data_type train \
--tasks none
Một chi tiết beginner hay bỏ qua: reward labels không tự xuất hiện. WEAVER dùng RoboMeter để tạo reward_progress và reward_success, sau đó dataloader đọc annotation_rewards/<split>/. Nếu bạn train trên data riêng mà chưa label reward, reward head và critic sẽ không có supervision đúng.
Training WEAVER
Có ba mode chính. Pretrain học world model từ dataset lớn:
DATASET_PATH=/path/to/preprocessed_droid \
SCRATCH_DIR=/path/to/output/model_dir \
sbatch scripts/pretrain.sh
Finetune dùng checkpoint đã có rồi cập nhật trên task/robot setup riêng:
PRETRAINED_DIR=/path/to/pretrained/logs/chkpts \
DATASET_PATH=/path/to/finetune_data \
EXP_NAME=weaver_finetune \
FINETUNE_SUFFIX=finetune \
sbatch scripts/finetune.sh
ReFlow post-training giảm số denoising steps để planning nhanh hơn:
PRETRAINED_DIR=/path/to/teacher/logs/chkpts \
PRETRAINED_CKPT_NAME=checkpoint.pt \
DATASET_PATH=/path/to/preprocessed_droid \
EXP_NAME=weaver_reflow \
FINETUNE_SUFFIX=reflow \
sbatch scripts/reflow.sh
Trong paper, model được pretrain trên DROID 1M steps, batch size 32, batch length 8, memory frames 6, memory stride 5, AdamW, EMA 0.9999. Transformer có 32 layers, 16 heads, embedding dimension 1536, head dimension 96, SPRINT probability 0.5. Finetuning trên task data chạy 16k steps với learning rate thấp hơn. Đây là lý do bạn nên xem WEAVER như infrastructure cho lab/GPU cluster, không phải notebook demo nhẹ.
Inference và evaluation
Để generate rollout views:
python -m weaver.generate_views \
--checkpoint /path/to/logs/chkpts \
--output-dir /path/to/eval_output \
--split val \
--use-real-history \
--overrides \
dataset.path=/path/to/eval_dataset \
model.val_steps=27 \
eval_horizon=5 \
eval_bootstrap=5 \
inference.pyramid_stagger_width=1 \
inference.pyramid_schedule=cosine
Các knobs quan trọng:
| Tham số | Ý nghĩa |
|---|---|
model.val_steps |
Số flow denoising steps |
eval_horizon |
Số future frames sinh trong mỗi chunk |
eval_bootstrap |
Số generated frames feed back cho chunk kế tiếp |
inference.pyramid_schedule |
linear, cosine, power, hoặc sigmoid |
inference.pyramid_stagger_width |
Độ lệch schedule giữa các future frames |
NFE hiệu dụng được tính là:
NFE = val_steps + eval_horizon * pyramid_stagger_width
Để compute FID/FVD/LPIPS:
EVAL_DIR=/path/to/eval_output \
sbatch scripts/compute_eval_metrics.sh
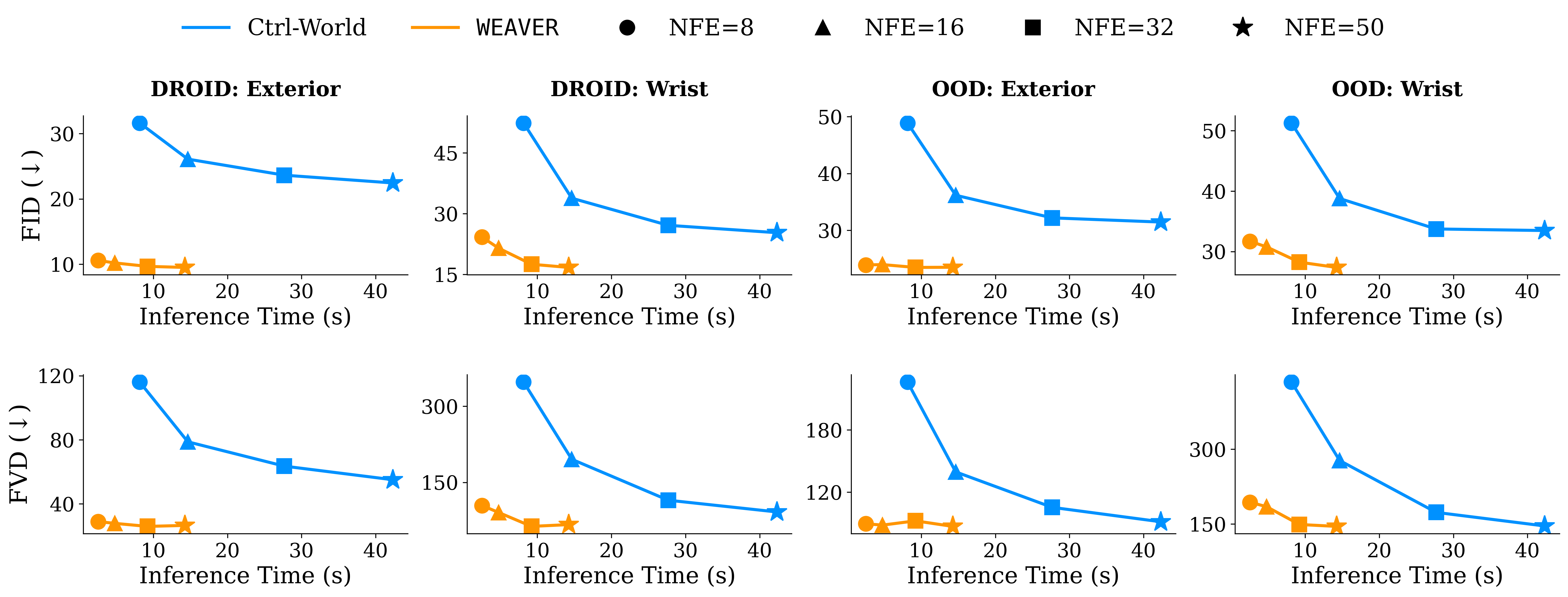
Trong Table 1 của paper, trên DROID validation, WEAVER NFE=16 đạt exterior FID 10.20 và FVD 27.83 trong 4.78 giây, trong khi Ctrl-World NFE=16 là FID 26.09, FVD 78.73 trong 14.65 giây. Trên OOD task data, WEAVER NFE=16 cũng tốt hơn Ctrl-World ở exterior FID/FVD và nhanh hơn. Điểm cần nhớ: wrist-camera vẫn khó hơn exterior view vì viewpoint thay đổi liên tục và bị occlusion nhiều.
Cải thiện π0.5 bằng synthetic data
Policy improvement là phần khiến WEAVER thú vị với người làm VLA. Pipeline trong README:
- Chạy OpenPI server với π0.5 trên GPU machine.
- Cho π0.5 sample nhiều candidate action chunks.
- WEAVER rollout từng candidate trong latent space.
- Reward head + critic tính advantage.
- Giữ segment tốt nhất nếu advantage vượt threshold.
- Convert synthetic data sang DROID layout, rồi sang LeRobot.
- Fine-tune π0.5 bằng real + synthetic data.
Command skeleton:
uv run scripts/serve_policy.py --env DROID --num-samples 5
synth_options=(
CHECKPOINT=/path/to/chkpts
DATASET_PATH=/path/to/dataset
OUTPUT_DIR=/path/to/output
NUM_TRAJECTORIES=1000
NUM_SAMPLES=5
NUM_CHUNKS=4
OPEN_LOOP_HORIZON=9
SELECTION_CRITERION=advantage
PI_HOST=<server-ip>
PI_PORT=8000
)
env "${synth_options[@]}" bash scripts/synth_data_gen.sh
Sau đó convert:
python third_party/openpi/examples/droid/convert_synthetic_data_to_droid.py \
--input-dirs /path/to/synthetic_data_folder /path/to/real_data_folder \
--output-dir ../data/data_mixed_droid_all \
--tasks cup_task marker_task
python third_party/openpi/examples/droid/convert_synthetic_droid_data_to_lerobot.py \
--data_dir ../data/data_mixed_droid_all \
--repo_name your-hf-username/your-dataset-name
Cuối cùng fine-tune trong third_party/openpi:
uv run scripts/train.py pi05_droid_finetune_real_syn_adv \
--exp-name=droid-20k-real-syn-finetune \
--overwrite
Kết quả paper: fine-tune π0.5 bằng real + synthetic data sinh bởi WEAVER cho success rate mạnh nhất trong các task như Stack Bowls, PnP Bag, PnP Marker, PnP Towel và Pour Beans. Trung bình, WEAVER báo cáo cải thiện real-world success rate 38% trên nền π0.5. Qualitative appendix cũng ghi nhận policy sau fine-tune có motion mượt hơn, ít step quá lớn và grasp/place chính xác hơn.
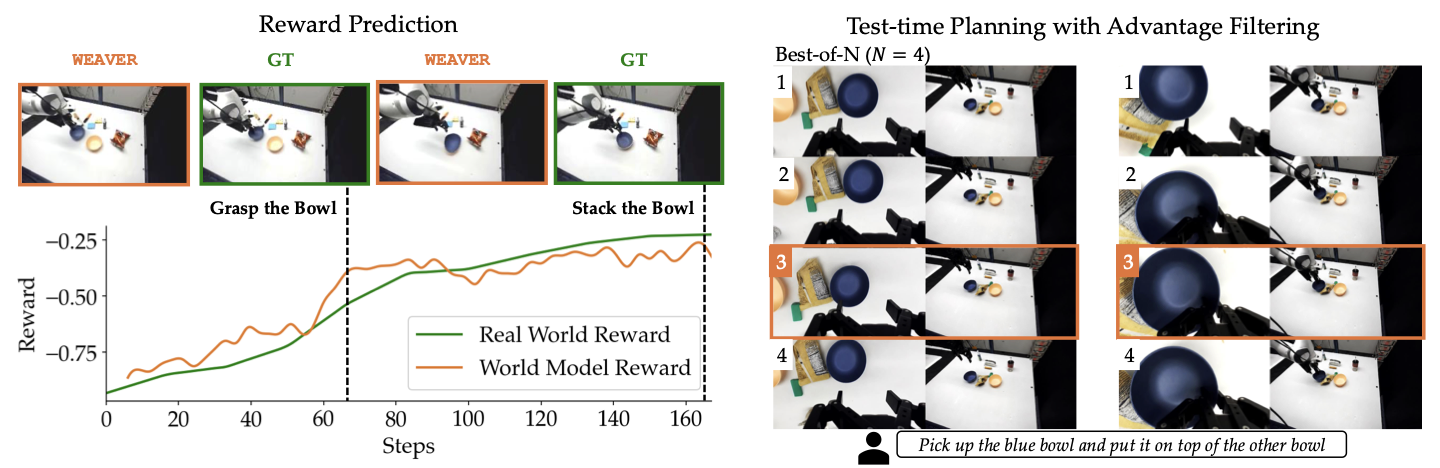
Test-time steering
Nếu bạn không muốn train lại π0.5, WEAVER còn có mode test-time planning. Với mỗi observation hiện tại, policy sample N action chunks, WEAVER rollout từng chunk, reward/critic tính advantage, rồi robot execute chunk tốt nhất. README gọi script:
planning_options=(
CHECKPOINT=/path/to/chkpts
OUTPUT_DIR=/path/to/output
TASK="stack the red block"
NUM_SAMPLES=8
OPEN_LOOP_HORIZON=9
SELECTION_CRITERION=advantage
MAX_STEPS=700
PI_HOST=<server-ip>
PI_PORT=8000
)
env "${planning_options[@]}" bash scripts/steer_pi_policy.sh
Đây là best-of-N search một chunk, không phải long-horizon tree search. Vì latency vẫn là bottleneck, WEAVER chỉ nhìn ngắn hạn nhưng nhìn đủ nhanh để cải thiện action selection. Paper báo cáo tăng average success rate 14% so với base policy, với gain cao hơn ở task mà base policy yếu. Hạn chế là nếu task cần kế hoạch nhiều stage hoặc recovery muộn, một chunk imagination có thể chưa đủ.
Khi nào nên dùng WEAVER?
Dùng WEAVER khi bạn đã có VLA policy nền, có nhiều rollout hoặc DROID-style data, và muốn giảm số trial thật cho evaluation/fine-tuning/planning. Nó đặc biệt hợp với lab đang dùng OpenPI/π0.5, Franka/DROID-style setup, và có GPU server đủ mạnh. Nếu bạn mới học VLA, hãy đọc LeRobot ecosystem và train một policy nhỏ trước; WEAVER sẽ dễ hiểu hơn khi bạn đã nắm data layout, action chunk và inference server.
Không nên kỳ vọng WEAVER thay thế physics simulator trong mọi trường hợp. Nó vẫn bị partial observability, chưa thấy force/tactile, khó với granular/deformable dynamics, và phụ thuộc mạnh vào data coverage. Nhưng bài học lớn của WEAVER rất rõ: VLA manipulation không chỉ cần policy mạnh; nó cần một world model đủ nhanh để policy có thể "nghĩ thử" trước khi hành động.
Nguồn tham khảo
- Paper: WEAVER, Better, Faster, Longer
- Project page: arnavkj1995.github.io/WEAVER
- Code: github.com/arnavkj1995/WEAVER
- Model weights: huggingface.co/arnavkj1995/WEAVER