
Bắt đầu từ đây: pipeline RISE là gì?
Nếu bạn đã đọc bài phân tích kiến trúc RISE, bạn biết ý tưởng cốt lõi: thay vì làm reinforcement learning trực tiếp trên robot thật — tốn thời gian reset, nguy cơ hỏng hardware, throughput thấp — RISE cho policy "thực hành trong đầu". Policy đề xuất action, world model tưởng tượng tương lai, value model chấm điểm, rồi policy được cải thiện theo advantage mà không cần cánh tay robot thật bật nguồn thêm lần nào.
Paper RISE: Self-Improving Robot Policy with Compositional World Model từ OpenDriveLab và các cộng sự đã được nhận vào RSS 2026. Code chính thức nằm ở github.com/OpenDriveLab/RISE, giấy phép Apache 2.0.
Bài này tập trung vào câu hỏi thực tế: chạy pipeline này từ đầu đến cuối như thế nào?
Toàn bộ pipeline gồm 4 giai đoạn cần chạy theo thứ tự nghiêm ngặt:
Giai đoạn 1 → Data preparation (HDF5 → LeRobot format)
Giai đoạn 2 → Offline training (policy + value model)
Giai đoạn 3 → Dynamics model (world model CDM)
Giai đoạn 4 → Online self-improvement (RL trong imagination)
Mỗi giai đoạn phụ thuộc vào output của giai đoạn trước. Bỏ qua hoặc làm sai thứ tự sẽ khiến online loop không converge.
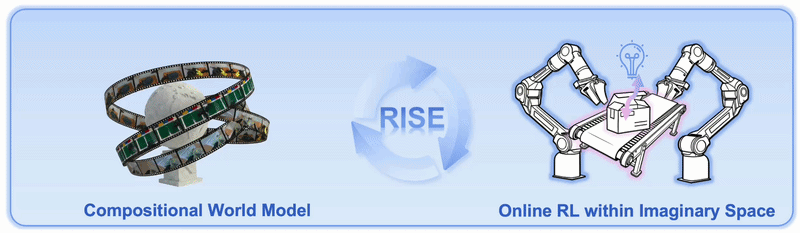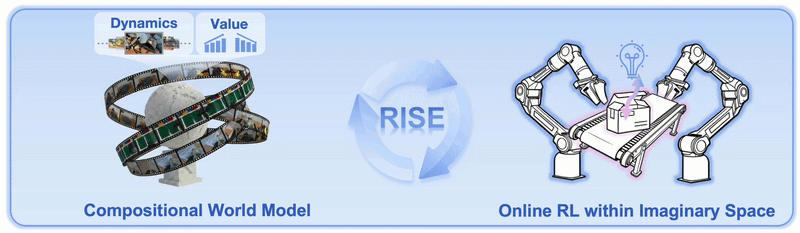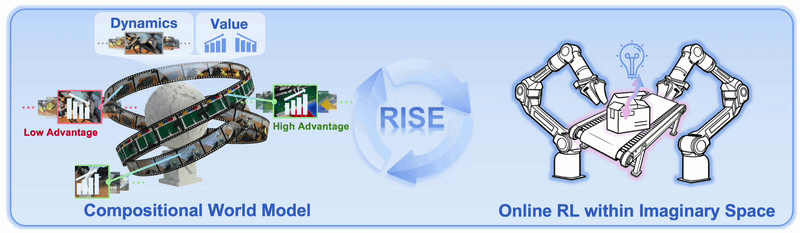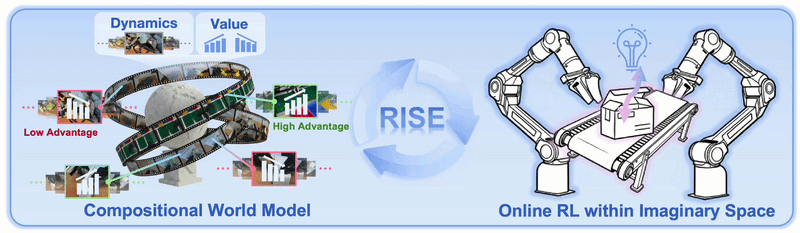
Yêu cầu phần cứng và phần mềm
RISE không phải framework bạn có thể chạy trên laptop hoặc máy workstation thông thường. Online self-improvement loop yêu cầu ít nhất 4 GPU, và paper gốc dùng 8×A100 để training và evaluation.
Hardware tối thiểu để chạy:
- 4× GPU A100/H100 40GB (hoặc tương đương) cho cấu hình "Complete Sharing"
- 8× GPU nếu muốn reproduce kết quả paper chính xác
- RAM hệ thống: ≥ 64 GB
- Storage: ≥ 500 GB SSD (dynamics model checkpoint lớn + dataset video)
Software requirements:
- Python 3.11.14 — không phải 3.12+, quan trọng
- CUDA 12.x
- Conda (hoặc mamba để install nhanh hơn)
- ffmpeg (để resize video cho dynamics model)
Nếu bạn chỉ có 4 GPU và muốn test, dùng cấu hình "Complete Sharing" (giải thích ở bước 5). Throughput sẽ thấp hơn nhưng pipeline vẫn chạy được.
Giai đoạn 1: Cài đặt môi trường
# Tạo conda environment với Python 3.11.14
conda create -n rise python=3.11.14 -y
conda activate rise
# Clone repo
git clone https://github.com/OpenDriveLab/RISE.git
cd RISE
# Cài tất cả dependencies qua install script
bash install.sh
Script install.sh tự cài các thư viện lớn: OpenPI fork (VLA backbone), LTX-Video (video generation backbone cho dynamics model), Ray (distributed training framework), và các dependencies robot control. Lần đầu mất 15–30 phút tùy tốc độ mạng.
Lưu ý version: RISE dùng một fork của OpenPI với một số modification cho advantage conditioning. Đừng cài OpenPI vanilla từ pip — dùng version trong install.sh.
Giai đoạn 2: Chuẩn bị data — HDF5 sang LeRobot
RISE được phát triển trên robot Piper của AgileX Robotics với camera setup 3 góc:
- 1 camera đầu (head view)
- 2 camera cổ tay (wrist view trái + phải)
Setup này quan trọng vì dynamics model cần sinh multi-view future đồng thời. Nếu bạn dùng robot khác với số camera khác, bạn cần sửa config camera trong phần dynamics model.
2a. Cấu trúc raw data (HDF5)
Data thu thập từ robot được lưu ở dạng HDF5 với video tách biệt:
raw_dataset/
└── aloha_mobile_dummy/
├── episode_000.hdf5 # joint angles, actions
├── episode_001.hdf5
└── video/
├── episode_000_cam_high.mp4
├── episode_000_cam_left_wrist.mp4
└── episode_000_cam_right_wrist.mp4
2b. Convert sang LeRobot format
LeRobot là format chuẩn của HuggingFace cho robot learning data, dùng parquet cho action/state và mp4 cho video. RISE cung cấp script convert từ HDF5 ALOHA:
cd RISE/policy_and_value/policy_offline_and_value
python examples/aloha_real/convert_to_lerobot.py \
--data-dir /path/to/raw_dataset \
--repo-ids aloha_mobile_dummy \
--prompt "Pick up the block and sort it by color" \
--save-dir /path/to/lerobot_output \
--save_repoid brick_sorting
Argument quan trọng nhất là --prompt: đây là task description ngôn ngữ tự nhiên dùng làm conditioning cho VLA. Viết ngắn gọn, rõ ràng, phản ánh đúng task. Policy sẽ conditioned trên prompt này suốt cả pipeline.
Output layout sau khi convert:
brick_sorting/
├── data/
│ └── chunk-000/
│ ├── episode_000000.parquet
│ └── episode_000001.parquet
├── meta/
│ ├── info.json
│ ├── episodes.jsonl
│ ├── episodes_stats.jsonl
│ └── tasks.jsonl
└── videos/
└── chunk-000/
└── *.mp4
2c. Resize video cho dynamics model
Dynamics model cần video ở resolution 256×192 để training và inference hiệu quả. RISE cung cấp script ffmpeg tự động:
cd RISE/dynamics/dynamics_model
./preprocess.sh brick_sorting
Script tạo thêm videos_small/ bên cạnh videos/, giữ nguyên bản gốc. Sau bước này dataset sẵn sàng cho cả offline policy training lẫn dynamics model training.
Paper dùng bao nhiêu data? Khoảng 100–200 demonstration episodes mỗi task. Ít hơn 50 episodes sẽ khiến dynamics model overfit và sinh imagined future không ổn định.
Giai đoạn 3: Offline training — Policy và Value model
Đây là bước training "baseline" trước khi tự cải thiện. Cần train 2 model độc lập: VLA policy và value model.
3a. Tính normalization statistics
Chạy 1 lần để tính mean/std của action space và observation space:
cd RISE/policy_and_value/policy_offline_and_value
python scripts/compute_norm_stats_fast.py --config-name Compute_norm
Kết quả được cache vào file, không cần chạy lại trừ khi thêm data mới.
3b. Các config đã đăng ký
RISE đăng ký 3 config chính trong src/openpi_value/training/config.py:
| Config | Mục đích | Thời gian ước tính |
|---|---|---|
Policy_offline_release |
Train VLA policy (OpenPI backbone) | 1–2 ngày / 8×A100 |
value_release |
Train value model (progress estimator) | 12–24 giờ / 8×A100 |
Compute_norm |
Tính normalization stats | <30 phút |
3c. Train policy và value model
# Train offline policy trên 8 GPU
bash train.sh Policy_offline_release 8
# Train value model trên 8 GPU
bash train.sh value_release 8
Cả hai có thể chạy song song nếu bạn có đủ GPU. Nếu training bị gián đoạn, resume dễ dàng:
bash train.sh Policy_offline_release 8 --resume
3d. Label dataset với value predictions
Sau khi có checkpoint value model, cần label lại toàn bộ dataset với per-frame advantage signals. Đây là bước "cầu nối" quan trọng: policy sẽ học cách weight demonstration theo chất lượng action, không chỉ imitate blindly.
bash label_value.sh vis_value_release_joint_T \
/path/to/checkpoints/value_release_joint/<experiment>/<step>
Bước này chạy value model inference trên từng frame của dataset, gán advantage score. Dataset sau khi labeled có thêm cột advantage trong parquet files.
Để visualize value predictions và kiểm tra chất lượng:
bash vis_value.sh vis_value_release_joint_T \
/path/to/checkpoints/value_release_joint/<experiment>/<step>
Nếu value prediction cho thấy high advantage ở các frame "near success" và low advantage ở các frame "far from goal", value model đã học đúng.
Giai đoạn 4: Dynamics model — Controllable Dynamics Model
Controllable Dynamics Model (CDM) là phần độc đáo nhất của RISE so với các RL robot pipeline khác. CDM là world model học cách sinh multi-view video future từ action sequence và state hiện tại, được build trên LTX-Video backbone.
CDM không phải video generator thông thường — nó được conditioned trên action sequence, tức là bạn có thể "hỏi" CDM: "nếu robot thực hiện action này, future sẽ trông như thế nào từ 3 góc camera?"
4a. Cấu trúc data cho CDM
CDM dùng cùng LeRobot dataset như offline training, nhưng cần thêm videos_small/ đã resize ở bước 2c. Đặt dataset vào thư mục dataset/ trong repo:
cp -r /path/to/brick_sorting RISE/dynamics/dynamics_model/dataset/
4b. Download LTX-Video backbone
CDM finetune từ LTX-Video pretrained checkpoint. Tham khảo hướng dẫn download trong dynamics/dynamics_model/README.md.
4c. Finetune CDM
cd RISE/dynamics/dynamics_model
# Chạy training script theo hướng dẫn trong docs/dynamics_model.md
CDM cần học 2 thứ:
- Appearance của robot workspace (phòng thí nghiệm cụ thể, object cụ thể)
- Relationship giữa action và visual change (gripper move trái → hình ảnh thay đổi như thế nào)
Insight quan trọng: CDM không cần sinh video photorealistic. Nó chỉ cần đủ chính xác để value model có thể đánh giá tiến triển task. Trong thực tế, video tưởng tượng thường hơi mờ hoặc nhòe ở detail nhỏ, nhưng vẫn đủ để phân biệt "gripper đang tiếp cận object" so với "gripper đang xa object".
Giai đoạn 5: Online self-improvement loop
Đây là bước mà tất cả các phần trước hội tụ. Policy thực sự "tự cải thiện trong imagination" bằng cách:
- Rollout policy trong CDM (không cần robot thật)
- Value model chấm điểm từng imagined trajectory
- Tính advantage = imagined reward - baseline
- Update policy theo advantage
5a. Khởi chạy Ray và online loop
bash policy_and_value/policy_online/examples/embodiment/run_embodiment.sh rl_release
Lần chạy đầu tiên mất ~10 phút để:
- Load CDM checkpoint (lớn)
- Load policy + value model checkpoint
- Compile torch graphs với
torch.compile - Khởi tạo Ray cluster
Đây là bình thường. Từ lần thứ 2 trở đi (hoặc sau resume) thời gian startup nhanh hơn nhiều.
Để debug không cần đợi compile:
# Trong config file
actor:
model:
openpi:
use_torch_compile: False
5b. Cấu hình GPU allocation
Online loop gồm 3 components cần GPU: env (CDM inference), rollout (policy rollout), actor (policy update). Có 3 cách phân bổ:
Partial Sharing — default, balance giữa throughput và GPU count:
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout: 4-7
actor: 0-7
Complete Sharing — khi chỉ có 4 GPU:
cluster:
num_nodes: 1
component_placement:
env,rollout,actor: all
Complete Separation — throughput cao nhất, cần ≥12 GPU:
cluster:
num_nodes: 1
component_placement:
env: 0-1
rollout: 2-5
actor: 6-7
5c. Tỷ lệ offline/online data — điểm quan trọng
RISE ablation study cho thấy offline_data_ratio = 0.6 là tối ưu: 60% data từ demonstration offline, 40% từ imagined rollouts. Nếu online ratio quá cao, policy có thể quên chất lượng demonstration gốc và collapse.
algorithm:
offline_data_ratio: 0.6
num_group_envs: 32 # số parallel imagined environments
num_group_envs ảnh hưởng trực tiếp đến throughput. Với 4 GPU cho env, đặt num_group_envs: 32 nghĩa là mỗi GPU xử lý 8 imagined environments song song.
5d. Multi-node training
Với dữ liệu lớn hơn hoặc task phức tạp hơn, có thể mở rộng sang nhiều node:
bash policy_and_value/policy_online/examples/embodiment/run_embodiment_ray_unified_multi_task.sh rl_release
Config placement trong multi-node: nếu có 2 node × 8 GPU = 16 GPU tổng, indices chạy từ 0–15.
5e. Resume online training
runner:
resume_dir: logs/20251221-00:15:14/${runner.logger.experiment_name}/checkpoints/global_step_13000
Sửa timestamp và experiment name khớp với log directory của run bạn muốn resume.

Kết quả trên 3 task thực tế
Paper báo cáo kết quả trên 3 task dexterous manipulation:
| Task | Offline baseline | Sau RISE self-improve | Cải thiện |
|---|---|---|---|
| Dynamic Brick Sorting | ~50% | ~85% | +35% |
| Backpack Packing | ~40% | ~85% | +45% |
| Box Closing | ~50% | ~85% | +35% |
Điểm đáng chú ý: toàn bộ improvement đến mà không cần thêm một lần tương tác robot thật nào sau bước offline training ban đầu. Đây là sự khác biệt cơ bản so với online RL truyền thống.
Những bẫy thường gặp
1. Python version sai. RISE được test kỹ trên Python 3.11.14. Dùng 3.12 có thể gặp lỗi với các dependency cũ hơn trong install.sh. Kiểm tra lại conda info trước khi bắt đầu.
2. Quên label value trước khi online training. Bước label_value.sh ở giai đoạn 3d là bắt buộc. Nếu bỏ qua, online loop sẽ chạy nhưng advantage signal sẽ bằng 0, không có cải thiện.
3. CDM underfitting. Nếu CDM chưa được finetune đủ (quá ít epoch hoặc quá ít data), video tưởng tượng sẽ không realistic. Kiểm tra loss curve của CDM trước khi chạy online loop.
4. OOM với Complete Sharing. Khi tất cả components share cùng GPU, đỉnh VRAM có thể cao hơn tổng VRAM của từng component riêng lẻ. Nếu gặp OOM, giảm num_group_envs xuống hoặc chuyển sang Partial Sharing.
5. Ray cluster không restart sạch. Nếu online loop bị kill đột ngột, Ray head node có thể còn zombie processes. Trước khi resume, chạy ray stop và ray start lại.
6. Offline/online ratio không đúng. Giữ offline_data_ratio >= 0.6. Paper thử nghiệm thấy ratio thấp hơn (0.3–0.4) dẫn đến policy forgetting và performance collapse sau vài nghìn steps.
So sánh RISE với các phương pháp RL robot khác
| Phương pháp | Cần robot thật cho RL? | Cần simulator? | Có VLA? | Complexity setup |
|---|---|---|---|---|
| Direct RL trên robot | ✅ Nhiều | ❌ | ❌ | Thấp nhưng tốn thời gian |
| RL trong Isaac Lab | ❌ | ✅ Cần sim | ❌ Thường không | Cao |
| DreamerV3 | ❌ | ❌ | ❌ | Trung bình |
| RISE | ❌ Không cần sau offline | ❌ Không cần | ✅ OpenPI | Cao |
RISE lấp đầy một khoảng trống cụ thể: bạn đã có VLA policy baseline từ imitation learning, muốn improve nó thêm mà không có access simulator tốt cho robot cụ thể của bạn (ví dụ robot tay mới chưa có MuJoCo model), và không muốn chạy hàng nghìn episode RL thật.
Tổng kết
Pipeline RISE gồm 4 giai đoạn với logic rõ ràng: data preparation chuẩn hóa format cho tất cả bước sau; offline training tạo baseline policy và evaluation signal; dynamics model tạo "simulator trong đầu" được học từ robot data thật; online loop dùng tất cả để cải thiện policy trong imagination.
Phần khó nhất là dynamics model: CDM cần đủ data (≥100 episodes), đúng resolution (256×192), và đủ training để sinh imagined future có chất lượng. Nếu CDM yếu, toàn bộ online loop sẽ thất bại.
Để đọc thêm về cách RISE hoạt động bên trong ở mức kiến trúc, xem RISE: VLA tự cải thiện bằng imagination. Để hiểu LeRobot format được dùng xuyên suốt pipeline, xem LeRobot ecosystem guide.

