Tóm tắt nhanh
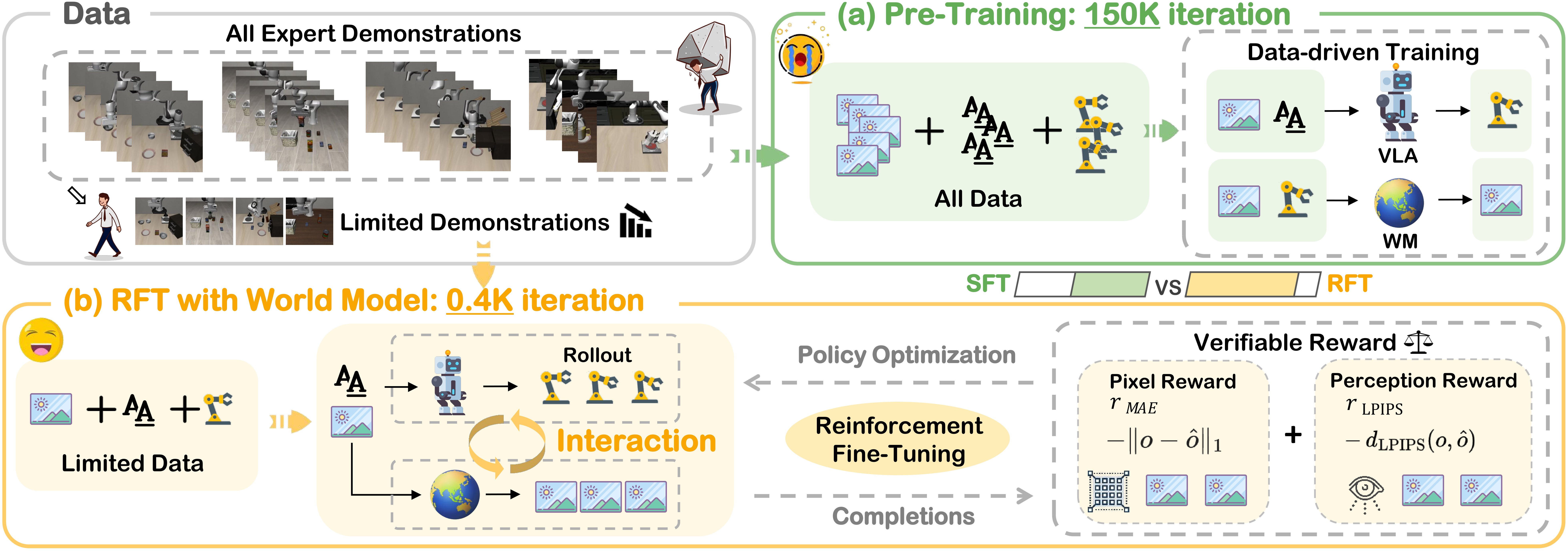
RISE: Self-Improving Robot Policy with Compositional World Model là paper RSS 2026 từ OpenDriveLab, Kinetix AI, CUHK, HKU, Tsinghua và các cộng sự. Chủ đề trong Robopapers EP86 rất đáng chú ý vì nó chạm vào một điểm nghẽn thật của robot learning: VLA policy có thể hiểu lệnh và bắt chước demonstration, nhưng vẫn dễ gãy khi thao tác thật có tiếp xúc, vật mềm, lỗi nhỏ, hoặc dynamic scene.
Nếu làm reinforcement learning trực tiếp trên robot thật, chi phí tăng rất nhanh. Mỗi rollout cần hardware, camera, reset môi trường, giám sát safety, và đôi khi phải thay vật thể. RISE đưa ra hướng khác: cho robot policy tự cải thiện trong imagination của một world model đã học từ dữ liệu robot. Policy không phải thử mọi action trên cánh tay thật. Nó đề xuất action chunk, world model tưởng tượng multi-view future, value model chấm mức tiến triển, rồi policy được update theo advantage.
Nguồn chính để đọc:
| Nguồn | Link | Ghi chú |
|---|---|---|
| Paper | arxiv.org/abs/2602.11075 | Bản arXiv của paper RISE |
| Project page | opendrivelab.com/RISE | Có demo, method, results, video presentation |
| Code | github.com/OpenDriveLab/RISE | Repo Apache 2.0 cho code, docs, deploy |
| Assets | rise_assets | GIF demo robot thật dùng trong bài này |
Vấn đề RISE giải quyết
Một beginner thường nghe "VLA model" và nghĩ rằng robot đã có thể nhận ảnh, đọc instruction, rồi làm task như một assistant vật lý. Thực tế khó hơn. VLA như π0, π0.5, OpenVLA hoặc các policy tương tự thường được train chủ yếu bằng imitation learning: xem nhiều demonstration rồi học phân phối action. Cách này tốt khi trạng thái test gần với trạng thái trong dữ liệu train. Nhưng khi robot lệch khỏi quỹ đạo demo, lỗi có thể tích lũy.
Ví dụ, trong task Dynamic Brick Sorting, robot phải nhặt brick trên conveyor đang chạy và bỏ đúng màu vào bin. Nếu gripper chậm hơn nửa giây, brick đã trôi đi. Trong Backpack Packing, robot phải xử lý vật mềm và zipper. Trong Box Closing, robot phải phối hợp hai tay, gập flap và nhét tab vào khe hẹp. Những task này không chỉ cần nhận diện vật thể. Chúng cần contact-rich control, recovery, timing, và precision.
Reinforcement learning có vẻ là lời giải tự nhiên: để robot thử, nhận reward, và tự cải thiện. Nhưng on-policy RL trong thế giới thật bị ba rào cản:
- Serial interaction: một robot thật chỉ chạy được một rollout tại một thời điểm.
- Reset cost: sau mỗi failure phải đặt lại vật, sửa scene, hoặc kiểm tra hardware.
- Safety risk: exploration có thể làm rơi vật, kẹt gripper, đập camera, hoặc mòn actuator.
RISE hỏi một câu thực dụng hơn: nếu simulator thủ công không đủ giống thế giới thật, liệu ta có thể học một world model từ dữ liệu robot thật rồi dùng nó như môi trường RL không?
Ý tưởng paper trong một câu
RISE là viết tắt của Reinforcement learning via Imagination for SElf-improving robots. Ý tưởng cốt lõi:
offline robot data
|
v
train dynamics model + value model
|
v
policy proposes action chunk
|
v
world model imagines future observations
|
v
value model estimates progress and advantage
|
v
policy improves from imagined rollouts
Điểm quan trọng là RISE không cố tạo một simulator vật lý đầy đủ như MuJoCo, Isaac Sim hoặc Genesis. Nó học một model dự đoán future observations trực tiếp từ camera đa góc nhìn, conditioned on action. Nói đơn giản, model trả lời câu hỏi: "nếu robot đang nhìn thấy scene này và làm action chunk này, camera sẽ thấy gì sau vài bước?"
Sau đó value model trả lời câu hỏi thứ hai: "tương lai được tưởng tượng đó có tiến gần hơn tới hoàn thành task không?" Hai câu hỏi này tách riêng thành hai module. Đây là lý do paper gọi nó là Compositional World Model.
Kiến trúc tổng thể
Repo chính thức chia thành ba phần:
OpenDriveLab/RISE
├── policy_and_value/
│ ├── policy_offline_and_value/ # offline policy + value training dựa trên OpenPI
│ └── policy_online/ # online RL trong imagination
├── dynamics/
│ └── dynamics_model/ # action-conditioned dynamics model
└── deploy/ # deploy policy lên AgileX/Piper
Bạn có thể hiểu pipeline bằng bốn khối.
1. Base VLA policy
Policy bắt đầu từ π0.5, một pretrained VLA policy. Nó nhận multi-view RGB observations và language instruction, rồi sinh action chunk. RISE không học từ zero vì robot manipulation từ zero quá tốn dữ liệu. Thay vào đó, policy được warm-up bằng data thật gồm expert demonstrations, policy rollout thành công/thất bại, và một phần human corrections kiểu DAgger.
Trong repo, phần policy và value nằm ở policy_and_value/policy_offline_and_value. Docs release có ba config chính:
| Config | Mục đích |
|---|---|
Compute_norm |
Tính normalization stats cho dataset |
Policy_offline_release |
Train offline policy warm-up |
value_release |
Train value model |
2. Controllable dynamics model
Dynamics model là phần "imagination". Nó dự đoán tương lai từ visual history và action chunk. Paper khởi tạo từ Genie Envisioner GE-base, một video diffusion model thừa hưởng thiết kế từ LTX-Video. Theo paper, Cosmos có thể mất hơn 10 phút để sinh 25 multi-view observations, trong khi GE cần dưới 2 giây cho cùng horizon, nên phù hợp hơn cho RL throughput.
RISE vẫn phải biến GE-base từ text-conditioned video model thành action-conditioned robot dynamics model. Nhóm tác giả thêm một lightweight action encoder và pre-train trên dữ liệu action-labeled lớn như AgiBot World Alpha và Galaxea Open World Dataset. Họ cũng dùng Task-Centric Batching: trong một batch, tập trung nhiều sample cùng task nhưng khác action để model học quan hệ action to motion rõ hơn.

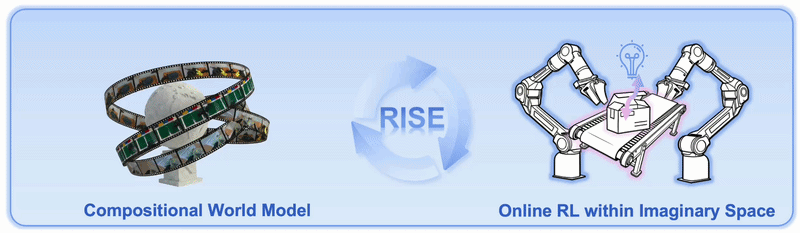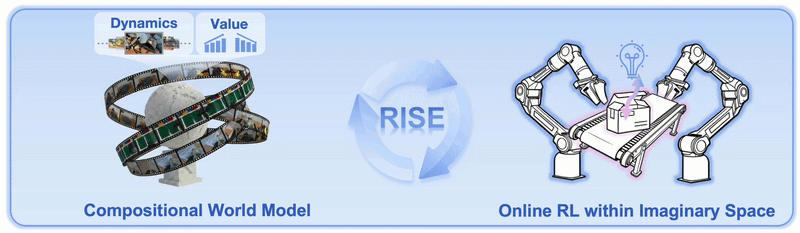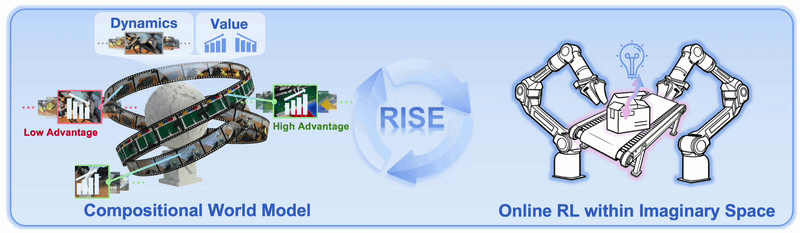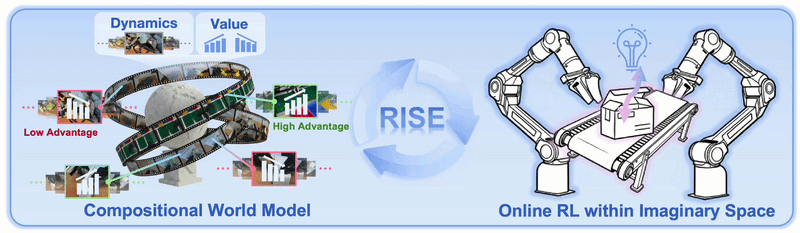
3. Progress value model
World model chỉ sinh video chưa đủ. Robot còn cần biết video đó là tốt hay xấu. Vì vậy RISE dùng Progress Value Model để chấm scalar value cho observation. Model này cũng khởi tạo từ pretrained VLA backbone, vì backbone đã có robot-centric visual understanding và hỗ trợ multi-view input tốt hơn nhiều VLM ảnh đơn.
Value model được train bằng hai tín hiệu:
| Tín hiệu | Vai trò |
|---|---|
| Progress estimate loss | Dạy model hiểu task đang tiến tới đâu trong episode |
| Temporal-Difference learning | Dạy model nhạy với success/failure và lỗi nhỏ |
Theo paper, progress loss được dùng trong 10k steps đầu. Sau đó TD learning được thêm vào trong 40k steps tiếp theo. Tổng value training khoảng 50k steps cho mỗi task.
4. Self-improving loop
Sau warm-up, RISE chạy vòng tự cải thiện:
- Lấy initial state từ offline dataset.
- Prompt rollout policy với "optimal advantage" để nó đề xuất action tốt.
- Dynamics model sinh future multi-view states.
- Value model chấm advantage thực tế cho action đó.
- Advantage được discretize thành 10 bins.
- Policy được train để sinh action tương ứng với advantage condition.
- Offline data được mix lại để tránh catastrophic forgetting.
Một chi tiết rất quan trọng: RISE không cần world model mô phỏng đến terminal state để lấy reward cuối cùng. Nó chỉ cần chunk-wise advantage cho action hiện tại. Vì generative video model dễ tích lũy lỗi nếu rollout quá dài, paper giới hạn consecutive interaction từ mỗi offline state tối đa hai lần.
Cài đặt repo
RISE đã release training code và pretrained dynamics model. Cài đặt cơ bản theo docs:
git clone https://github.com/OpenDriveLab/RISE.git
cd RISE
conda create -n rise python=3.11.14 -y
conda activate rise
bash install.sh
install.sh cài nhiều phần:
| Thành phần | Vai trò |
|---|---|
policy_offline_and_value |
OpenPI-based offline policy và value training |
lerobot |
Data format và toolchain robot dataset |
rlinf[embodied] |
Online RL infrastructure |
mini_lerobot |
Utility chuyển đổi dữ liệu |
dynamics |
Package cho dynamics model |
torchcodec |
Video IO |
Vì paper dùng training quy mô lớn, beginner không nên kỳ vọng laptop chạy full pipeline. Cấu hình trong paper gồm 16 NVIDIA H100 cho dynamics pre-training khoảng 7 ngày, 8 H100 cho task fine-tuning khoảng 3 ngày, và 8 GPU cho policy/value training. Nhưng repo vẫn hữu ích nếu bạn muốn học cấu trúc, thử inference dynamics model, hoặc fine-tune nhỏ trên lab dataset.
Chuẩn bị dữ liệu
Training code kỳ vọng LeRobot-style data. Nếu bạn thu dữ liệu trên Piper ở dạng HDF5, repo có script chuyển sang format LeRobot:
cd policy_and_value/policy_offline_and_value
python examples/aloha_real/convert_to_lerobot.py \
--data-dir /path/to/raw_dataset \
--repo-ids aloha_mobile_dummy \
--prompt "Pick and sort bricks on the conveyor." \
--save-dir /path/to/lerobot_output_root \
--save_repoid brick_sorting_rise
Layout kỳ vọng:
<dataset_name>/
├── data/chunk-000/episode_*.parquet
├── meta/
│ ├── info.json
│ ├── episodes.jsonl
│ ├── episodes_stats.jsonl
│ └── tasks.jsonl
└── videos/chunk-000/*.mp4
Với dynamics model, docs khuyến nghị resize video về 256x192 cho mỗi view. RISE dùng ba view: một head view và hai wrist views. Đây là chi tiết rất thực tế. Nếu camera calibration, frame sync, hoặc naming của view không ổn định, dynamics model sẽ học nhầm motion và value model cũng chấm sai.
Paper dùng task-specific data như sau:
| Task | Data trong paper |
|---|---|
| Dynamic Brick Sorting | 3063 human demonstrations, 610 policy rollouts |
| Backpack Packing | 2478 human demonstrations, 507 policy rollouts |
| Box Closing | 2286 human demonstrations, 524 policy rollouts, 540 DAgger corrections |
Training từng phần
Bước 1: Tính normalization stats
Trong thư mục policy_and_value/policy_offline_and_value:
python scripts/compute_norm_stats_fast.py --config-name Compute_norm
Normalization quan trọng vì robot action thường có thang khác nhau: joint angle, gripper command, Cartesian delta, velocity hoặc action token. Nếu normalize sai, policy có thể học action scale lệch ngay cả khi image encoder tốt.
Bước 2: Train offline policy và value model
bash train.sh Policy_offline_release 8
bash train.sh value_release 8
Nếu training bị ngắt:
bash train.sh Policy_offline_release 8 --resume
Sau khi có value checkpoint, label value và advantage cho rollout data:
bash label_value.sh vis_value_release_joint_T /path/to/checkpoints/value_release_joint/<exp>/<step>
Về mặt khái niệm, bước này biến dataset từ "observation, action" thành "observation, action, estimated advantage". Policy sau đó không chỉ bắt chước action, mà còn học rằng action nào thuộc bin advantage cao.
Bước 3: Train dynamics model
Trong dynamics/dynamics_model, tải LTX backbone và pretrained dynamics model:
./download.sh
Pre-train nếu bạn có dataset lớn:
bash train_task_centric.sh
Fine-tune cho task riêng:
python norm.py --datasets <your_finetune_dataset> --save-config data/utils/action_norm.json
bash task_finetune.sh
Đối với lab nhỏ, hướng thực tế là dùng pretrained dynamics model của RISE làm điểm bắt đầu, fine-tune ít epoch trên task riêng, rồi kiểm tra qualitative rollout thật kỹ. Nếu video prediction không bám action, self-improving loop sẽ học từ "ảo giác" sai.
Bước 4: Online training trong imagination
RISE dùng script embodiment:
bash policy_and_value/policy_online/examples/embodiment/run_embodiment.sh rl_release
Config online training cho phép chia GPU cho ba component:
| Component | Vai trò |
|---|---|
env |
Chạy world model environment |
rollout |
Sinh imagined rollouts |
actor |
Update policy |
Ví dụ placement mặc định:
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout: 4-7
actor: 0-7
Docs cũng lưu ý lần chạy đầu có thể mất khoảng 10 phút vì load dynamics model, reward model và torch compile. Khi debug, có thể tắt actor.model.openpi.use_torch_compile.
Inference và deploy lên Piper
Điểm hay của RISE là world model chỉ dùng trong training. Khi deploy, robot thật chỉ chạy policy đã cải thiện. Paper nhấn mạnh world model tạo zero inference overhead.
Để deploy, trước tiên convert distributed checkpoint sang PyTorch state dict:
python toolkits/ckpt_convertor/convert_dcp_to_state_dict.py \
--dcp_path <YOUR_DCP_CKPT_DIR> \
--output_path <YOUR_EXPECTED_PT_CKPT_DIR>
Deployment target trong repo là AgileX Piper dual-arm robot với Ubuntu 20.04, ROS Noetic, RealSense cameras và OpenPI policy server. Trên robot, chạy ba terminal:
# Terminal 1: cameras
roslaunch realsense2_camera multi_camera.launch
# Terminal 2: robot arms
bash deploy/Piper_ros_private-ros-noetic/can_config.sh
roslaunch piper start_ms_piper.launch mode:=1 auto_enable:=true
# Terminal 3: inference
conda activate deploy
python deploy/piper_deploy.py \
--host 172.16.99.11 \
--port 8000 \
--ctrl_type joint \
--use_temporal_smoothing \
--chunk_size 50 \
--lang_embeddings "Pick and sort bricks on the conveyor."
Với beginner, điều cần nhớ là piper_deploy.py không tự train gì cả. Nó nhận observation từ camera, gửi request tới policy server, nhận action chunk, rồi điều khiển robot. Nếu policy server, camera serial, ROS topic hoặc action scale sai, behavior sẽ sai ngay cả khi checkpoint tốt.

Kết quả chính
RISE được đánh giá trên ba task thật, mỗi kết quả trung bình từ 20 autonomous trials. Bảng dưới rút gọn từ paper:
| Method | Brick success | Backpack success | Box success |
|---|---|---|---|
| π0.5 | 35% | 30% | 35% |
| π0.5 + DAgger | 15% | 50% | 40% |
| π0.5 + PPO | 10% | 35% | 10% |
| π0.5 + DSRL | 10% | 10% | 10% |
| RECAP | 50% | 40% | 60% |
| RISE | 85% | 85% | 95% |
Abstract tóm tắt mức tăng tuyệt đối: hơn +35% cho dynamic brick sorting, +45% cho backpack packing, và +35% cho box closing. Điều đáng chú ý là PPO và DSRL không tự động tốt hơn imitation baseline. Trong paper, online adaptation có thể làm performance tụt, ví dụ brick sorting từ 35% xuống 10%. Điều này nhắc lại một bài học quan trọng: RL không miễn phí. Nếu reward, state distribution hoặc training stability không đúng, RL có thể phá policy nền.
RISE cũng có ablation quan trọng:
| Ablation | Bài học |
|---|---|
| Offline ratio tốt nhất khoảng 0.6 | Giữ đủ offline data giúp tránh catastrophic forgetting |
| Chỉ online action chưa đủ | Online state từ dynamics model giúp mở rộng distribution |
| Bỏ dynamics pre-training | Sorting accuracy giảm mạnh |
| Bỏ progress loss hoặc TD learning | Value model kém nhạy với tiến trình và failure |
Trong dynamics model evaluation, RISE đạt PSNR 23.90, LPIPS 0.07, SSIM 0.82, FVD 66.84 và EPE 0.54 trên real-world tasks, tốt hơn các biến thể chính về motion controllability. EPE thấp đặc biệt quan trọng vì nó đo action-conditioned motion, không chỉ độ đẹp của video.
Cách đọc RISE cho người mới
Nếu bạn mới học robot learning, đừng bắt đầu bằng cách train full RISE. Hãy đọc theo thứ tự này:
- Hiểu imitation learning: policy học
observation -> actiontừ demonstration. - Hiểu exposure bias: khi robot lệch khỏi demonstration, policy không biết recovery.
- Hiểu value/advantage: action tốt hơn trung bình nên được tăng xác suất.
- Hiểu world model: model dự đoán future state khi biết action.
- Hiểu RISE: dùng world model để tạo on-policy-like data trong imagination.
Một mental model đơn giản:
Imitation learning: "làm giống người"
RL thật: "thử trên robot thật rồi rút kinh nghiệm"
RISE: "thử trong world model, chấm bằng value model, rồi mới deploy policy tốt hơn"
RISE không thay thế simulator truyền thống. Nó bổ sung một tầng học từ dữ liệu thật, đặc biệt hữu ích khi task quá phức tạp để mô phỏng bằng physics engine thủ công, nhưng vẫn có đủ camera/action logs để học dynamics.
Khi nào nên thử RISE trong lab?
RISE phù hợp nếu bạn có:
| Điều kiện | Vì sao cần |
|---|---|
| Multi-view camera ổn định | Dynamics model cần observation nhất quán |
| Action logs đồng bộ | Model phải biết action nào tạo ra motion nào |
| Dataset có success và failure | Value model cần phân biệt tiến triển thật |
| GPU đủ mạnh | Video diffusion và online RL rất nặng |
| Robot task contact-rich | Đây là nơi imitation-only thường yếu |
Không nên bắt đầu bằng RISE nếu bạn chỉ có vài chục episode, camera chưa sync, hoặc task đơn giản như pick-and-place tĩnh. Khi đó, LeRobot + imitation learning hoặc diffusion policy cơ bản sẽ dễ debug hơn.
Kết luận
RISE đáng chú ý vì nó không chỉ nói "world model cho robot" ở mức ý tưởng. Repo đã có code structure cho offline policy/value training, action-conditioned dynamics model, online RL trong imagination và deploy Piper. Paper cũng chứng minh trên task thật chứ không chỉ benchmark simulation.
Thông điệp chính cho engineer là: self-improving robot policy không nhất thiết phải học bằng hàng nghìn trial nguy hiểm trên robot thật. Nếu bạn có dữ liệu camera/action tốt, bạn có thể học một môi trường imagination đủ nhanh, dùng value model để tạo advantage dày hơn reward cuối episode, rồi cải thiện policy trước khi đưa lại vào hardware.