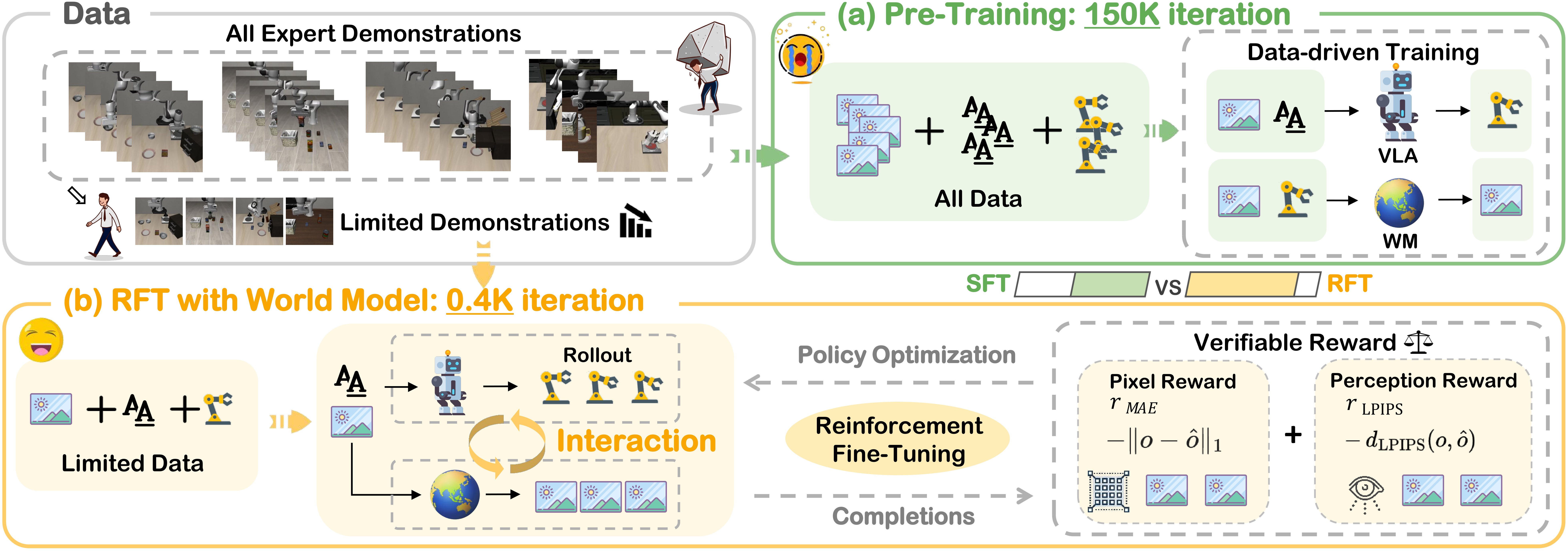
VLA-RFT là một paper rất đáng chú ý cho hướng Vision-Language-Action (VLA): thay vì chỉ imitation learning từ demonstration, nhóm OpenHelix dùng reinforcement fine-tuning trong một world simulator học từ dữ liệu robot thật. Paper có tên đầy đủ là VLA-RFT: Vision-Language-Action Reinforcement Fine-tuning with Verified Rewards in World Simulators, được nộp lên arXiv ngày 1/10/2025, kèm project page, GitHub repo OpenHelix-Team/VLA-RFT, và model trên Hugging Face VLA-RFT.
Điểm hay của VLA-RFT không nằm ở việc thay thế robot thật bằng một physics simulator cổ điển như MuJoCo hay Isaac. Thay vào đó, hệ thống học một data-driven world model: đưa vào ảnh ban đầu, instruction, state robot và action chunk, model dự đoán các frame tương lai. VLA policy sau đó có thể "thử" nhiều hành động trong world model, nhận verified reward từ trajectory dự đoán, rồi được optimize bằng GRPO. Nói ngắn gọn: VLA-RFT biến dữ liệu demonstration thành một môi trường tưởng tượng có thể tương tác, giúp policy học từ hậu quả của chính action nó sinh ra.
Nếu bạn mới theo dõi VLA, nên nắm trước khái niệm VLA models và VLA-Adapter trên LIBERO. Bài này đi sâu hơn vào câu hỏi thực dụng: làm sao fine-tune VLA manipulation bằng RL mà không cần hàng chục nghìn rollouts trên robot thật?
Vấn đề: imitation learning dễ bị compounding error
Phần lớn VLA hiện nay học theo kiểu behavior cloning hoặc supervised fine-tuning. Dataset chứa cặp:
(image, language instruction, robot state) -> action
Model học bắt chước expert action tại từng timestep. Cách này đơn giản, dễ scale, và hoạt động tốt khi test distribution gần giống training data. Nhưng khi robot bị lệch một chút, ví dụ vật thể đặt xa hơn, gripper bắt đầu thấp hơn, camera noise khác đi, policy có thể rơi vào state mà expert dataset không bao phủ. Một action sai nhỏ dẫn đến state mới lạ hơn, rồi action kế tiếp lại sai hơn. Đây là compounding error.
RL có thể xử lý điểm này vì policy được đánh giá bằng kết quả rollout, không chỉ bằng lỗi action từng bước. Nhưng RL trên robot thật đắt, chậm và có rủi ro va chạm. RL trong physics simulator thì rẻ hơn, nhưng manipulation rất nhạy với contact dynamics, friction, camera, asset, lighting. Sim-to-real gap làm policy có thể thắng benchmark ảo nhưng fail khi ra robot thật.
VLA-RFT chọn đường giữa:
| Cách train | Ưu điểm | Điểm yếu |
|---|---|---|
| Imitation learning | Dễ train, tận dụng demo | Không học từ lỗi của chính policy |
| Real-world RL | Reward đúng với robot thật | Đắt, chậm, nguy hiểm |
| Physics sim RL | Rollout nhanh, nhiều sample | Sim-to-real gap lớn |
| VLA-RFT | RL trong world model học từ data | Phụ thuộc chất lượng world model |
Ý tưởng này gần với tinh thần sim-to-real pipeline, nhưng "simulator" không được viết bằng engine vật lý. Nó là một video/action prediction model được train từ dữ liệu robot.
Kiến trúc tổng quan
VLA-RFT có ba khối chính:
- VLA policy: nhận ảnh, language instruction, proprioception, rồi sinh action chunk.
- World model: nhận frame ban đầu và action sequence, rồi dự đoán các frame tương lai.
- Verified reward + GRPO optimizer: so sánh trajectory dự đoán với reference trajectory để tạo reward, sau đó update action head.
Sơ đồ logic:
Initial image + instruction + robot state
|
v
VLA policy
action chunks a_1...a_T
|
v
Learned world model
predicted frames o_1...o_T
|
v
verified reward from trajectory similarity
|
v
GRPO update for VLA action head
Trong paper, base policy là một biến thể nhẹ của VLA-Adapter. Đây là hướng tiny-scale VLA dùng VLM backbone nhỏ và action head dạng flow matching. Điểm mới ở VLA-RFT là: sau supervised pretraining, họ không dừng ở SFT mà tiếp tục post-train bằng RL.
World model là một autoregressive Transformer nhẹ, khoảng 138M parameters, lấy cảm hứng từ các interactive video prediction model. Appendix của paper mô tả kiến trúc gồm 12 layers, hidden size 768, FFN size 3072, 12 attention heads, max position embedding 8192, activation SiLU và vocabulary size 9008. Đầu vào gồm image tokens và action tokens; đầu ra là future image tokens, sau đó decode lại thành frame.
Action space trong setting LIBERO là action 7 chiều, tương thích với output của VLA policy. Với robot arm, bạn có thể hiểu gần đúng là delta pose của end-effector cộng với gripper command. VLA sinh action chunk thay vì từng action đơn lẻ, giúp policy ra lệnh mượt hơn và giảm số lần gọi model.
Stage I: pretrain world model và VLA policy
VLA-RFT không bắt đầu RL từ model trắng. Stage I dùng offline dataset để tạo nền ổn định.
World model pretraining học xác suất frame tương lai theo chuỗi:
p(o_1, o_2, ..., o_T | o_0, a_1, a_2, ..., a_T)
Trong thực tế, dataset LIBERO chứa trajectory robot. Ta lấy frame đầu, action sequence, và frame tương lai làm target. Loss là maximum likelihood trên token ảnh. Mục tiêu là model phải dự đoán được: nếu gripper đi sang trái, vật thể hoặc camera view sẽ thay đổi ra sao; nếu drawer được kéo ra, frame tiếp theo nên trông như thế nào.
VLA policy pretraining là supervised fine-tuning. Policy học:
pi(a_chunk | image, instruction, proprioception)
Action head dùng flow matching. Flow matching giống diffusion ở chỗ bắt đầu từ noise rồi biến đổi dần thành action, nhưng formulation thường gọn hơn cho continuous action. Trong VLA-RFT, flow matching còn được mở rộng thành stochastic policy ở Stage II bằng một Sigma Net, để policy có thể sample nhiều rollout khác nhau và tính log probability cho RL.
Tại sao phải pretrain cả hai? Vì RL trong high-dimensional action space rất dễ collapse. Nếu world model dự đoán lung tung, reward sẽ sai. Nếu VLA policy ban đầu sinh action vô nghĩa, world model cũng bị đẩy vào vùng ngoài data. Pretraining giữ cả simulator lẫn actor ở vùng hợp lý.
Stage II: RL trong world simulator
Stage II là phần cốt lõi. Với cùng initial frame và instruction, policy sinh nhiều action chunks. World model rollout từng action chunk thành predicted visual trajectory. Sau đó hệ thống tính reward.
for each task instance:
sample N action rollouts from VLA policy
for each rollout:
predicted_video = world_model(initial_frame, actions)
reward = verified_reward(predicted_video, reference_video)
normalize rewards within the group
update policy with GRPO
GRPO, hay Group Relative Policy Optimization, tương tự tư duy PPO nhưng dùng reward tương đối trong cùng nhóm rollout để ước lượng advantage. Thay vì cần critic riêng, mỗi nhóm rollout từ cùng starting state có baseline là reward trung bình của nhóm. Rollout nào tốt hơn trung bình được tăng xác suất, rollout nào kém hơn bị giảm.
Điều này hợp với VLA-RFT vì một task instance có thể generate nhiều action candidate trong world model mà không cần robot thật. Nếu rollout A đưa bowl gần drawer hơn rollout B, reward của A cao hơn và policy học tăng xác suất kiểu action đó.
Verified reward được tính như thế nào?
Điểm quan trọng là VLA-RFT không chỉ dùng reward sparse kiểu success/fail. Paper thử ba reward design:
| Reward | Cách tính | Nhận xét |
|---|---|---|
| R1 | Negative L1 giữa action policy và action dataset | Gần imitation, gain nhỏ |
| R2 | World model render action policy rồi so với ảnh thật | Có visual feedback, nhưng lệch do bias generation |
| R3 | Render cả policy action và reference action trong cùng world model rồi so sánh | Tốt nhất, giảm bias của world model |
Reward tốt nhất là R3. Ý tưởng rất thực dụng: nếu so predicted frames trực tiếp với real frames, lỗi có thể đến từ world model không tái tạo pixel hoàn hảo, không hẳn do action policy kém. Vì vậy, VLA-RFT đưa cả reference action và policy action vào cùng world model. Hai trajectory đều nằm trong cùng generative space. Sau đó reward là negative weighted sum của reconstruction-style loss và perceptual similarity loss như MAE/LPIPS theo thời gian.
Sơ đồ:
Initial frame
|---------------- reference actions ------------|
| v
| WM trajectory ref
|
|---------------- policy actions ---------------|
v
WM trajectory policy
reward = - distance(WM trajectory policy, WM trajectory ref)
Đây là lý do paper gọi là verified rewards. Reward không cần human label từng rollout, nhưng vẫn có grounding từ trajectory thành công trong offline dataset.
Cài đặt từ GitHub
Repo chính thức là OpenHelix-Team/VLA-RFT. README yêu cầu Python 3.10+, CUDA 12.2+, PyTorch 2.4+ và uv. Dưới đây là cách cài theo repo. Đây là command tham khảo để chạy trên máy Linux có GPU NVIDIA phù hợp:
git clone https://github.com/OpenHelix-Team/VLA-RFT.git
cd VLA-RFT
git submodule update --init --recursive
uv venv --seed -p 3.10
source .venv/bin/activate
uv pip install -e train/verl/".[gpu]"
uv pip install "https://github.com/Dao-AILab/flash-attention/releases/download/v2.6.0.post1/flash_attn-2.6.0.post1+cu122torch2.4cxx11abiFALSE-cp310-cp310-linux_x86_64.whl"
uv pip install -e train/verl/".[vllm]"
uv pip install -r train/verl/requirements.txt
uv pip install git+https://github.com/moojink/dlimp_openvla.git
uv pip install -e train/verl/vla-adapter/openvla-oft
uv pip install -e third_party/LIBERO
Nếu network bị hạn chế, repo có hướng dẫn tải thủ công LIBERO, flash-attention wheel và dlimp trong third_party/README.md.
Lưu ý thực tế: paper chạy thí nghiệm trên 4 A800 GPUs. Bạn vẫn có thể đọc code, chạy evaluation nhỏ, hoặc thử một suite hẹp trên GPU yếu hơn, nhưng full RFT 400 steps với rollout times 16 không phải workload nhẹ. Đây là bài research code, chưa phải package pip cài một dòng để deploy production.
Chuẩn bị dữ liệu LIBERO
VLA-RFT dùng modified LIBERO RLDS dataset từ OpenVLA. Theo README, dataset khoảng 10GB, gồm bốn suite:
data/
└── modified_libero_rlds/
├── libero_spatial_no_noops/
├── libero_object_no_noops/
├── libero_goal_no_noops/
└── libero_10_no_noops/
Command trong README:
cd data
git clone [email protected]:datasets/openvla/modified_libero_rlds
Các folder _no_noops đã lọc gần-zero actions. Điều này quan trọng vì nhiều đoạn robot đứng yên có thể làm policy học bias "không làm gì". Khi training manipulation, dataset nhiều no-op sẽ làm action head quá bảo thủ, đặc biệt ở task cần tiếp xúc như mở drawer, đặt bowl, nhặt vật thể nhỏ.
Training RFT
Script training chính trong repo là:
cd scripts/libero
bash post_train_rlvr.sh
Script đặt LIBERO_TASK_NAME=object, tạo log TensorBoard, disable NCCL P2P trong một số môi trường, dùng VLLM_ATTENTION_BACKEND=XFORMERS, rồi gọi:
bash train/verl/examples/grpo_trainer/run_vla_rft.sh
Các hyperparameter quan trọng trong paper:
| Thành phần | Giá trị |
|---|---|
| Advantage estimator | GRPO |
| Total RFT steps | 400 |
| Batch size | 16 |
| Rollout times | 16 |
| MSE auxiliary coefficient | 0.01 |
| Entropy coefficient | 0.003 |
| World model | Frozen trong RFT |
| Policy update | Chủ yếu action head và Sigma Net |
Việc giữ một MSE auxiliary loss nhỏ là chi tiết đáng chú ý. Nếu chỉ dùng RL objective, action head có thể drift quá xa khỏi behavior cloning prior. MSE loss giữ policy gần vùng action hợp lệ, còn entropy khuyến khích exploration vừa đủ. Đây là trade-off quen thuộc trong RL manipulation: reward giúp tối ưu kết quả, nhưng prior giúp không phá hỏng motion cơ bản.
Inference và evaluation
Sau khi có checkpoint, repo cung cấp script evaluation:
cd scripts/libero
bash eval_libero.sh
Trong script, bạn cần sửa:
LIBERO_TASK_NAME=10 # spatial, object, goal, 10
MODEL_DIR=path/to/your/model/checkpoint
Evaluation gọi run_libero_eval.py với các flag đáng chú ý:
--use_flow_matching True
--use_proprio True
--num_images_in_input 1
--use_minivla True
--task_suite_name libero_${LIBERO_TASK_NAME}
Nếu gặp lỗi EGL như AttributeError: 'NoneType' object has no attribute 'eglQueryString', README gợi ý cài các package OpenGL/EGL:
sudo apt-get update
sudo apt-get install libgl1-mesa-dev libegl1-mesa-dev libgles2-mesa-dev libglew-dev
Ở inference, world model không nhất thiết nằm trong vòng điều khiển robot. World model chủ yếu dùng để fine-tune policy. Khi deploy/evaluate, policy đã RFT nhận observation hiện tại và instruction rồi sinh action chunk như VLA thông thường. Đây là điểm thực dụng: bạn trả chi phí world model trong training, còn runtime vẫn là policy inference.
Kết quả chính
Trên LIBERO standard suites, paper báo cáo:
| Policy | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|
| Base 3w | 82.4 | 84.8 | 85.4 | 57.2 | 77.5 |
| Base 15w | 88.4 | 88.0 | 92.8 | 77.2 | 86.6 |
| VLA-RFT 400 | 94.4 | 94.4 | 95.4 | 80.2 | 91.1 |
| Gain vs Base 15w | +6.0 | +6.4 | +2.6 | +3.0 | +4.5 |
Điểm đáng chú ý là VLA-RFT chỉ dùng 400 fine-tuning steps, trong khi supervised baseline mạnh hơn cần 150K iterations. So với các RL method khác trong Appendix, VLA-RFT đạt +4.5 điểm với 400 steps; VLA-RL cũng +4.5 nhưng cần 10,000 steps; các offline RL như ARFM, RWR, ReinboT cần 40,000 steps.
World model cũng được đánh giá riêng:
| Metric trung bình | Giá trị |
|---|---|
| MSE | 0.0039 |
| PSNR | 25.23 dB |
| SSIM | 0.906 |
| LPIPS | 0.059 |
Các số này không có nghĩa world model là "bản sao hoàn hảo" của môi trường. Chúng cho thấy nó đủ tốt để cung cấp signal theo trajectory. Trong robot learning, đôi khi reward đúng hướng quan trọng hơn pixel prediction hoàn hảo.
VLA-RFT cũng cải thiện robustness ở perturbation settings. Ví dụ major goal position perturbation tăng từ 44.8% lên 51.5%, minor combined perturbation tăng từ 63.5% lên 70.0%. Điều này khớp với hypothesis ban đầu: khi policy được train bằng rollout của chính nó, nó có khả năng chịu lệch distribution tốt hơn behavior cloning thuần.
Khi nào nên dùng VLA-RFT?
VLA-RFT phù hợp khi bạn có ba điều kiện:
- Có demonstration dataset đủ sạch, gồm image, action, proprioception và task instruction.
- Có world model hoặc đủ compute để train world model trên domain đó.
- Muốn cải thiện robustness mà không thể chạy online RL dài ngày trên robot thật.
Nếu bạn chỉ có vài chục demo, nên bắt đầu bằng imitation learning hoặc VLA-Adapter trước. Nếu bạn có physics simulator rất tốt và asset sát với robot thật, sim RL truyền thống vẫn có chỗ đứng. Nhưng nếu bạn có nhiều interaction data từ robot thật và muốn tận dụng nó hơn mức behavior cloning, VLA-RFT là hướng đáng thử.
Hạn chế lớn nhất là reward vẫn neo vào expert trajectory. Policy học để tạo trajectory giống trajectory thành công, chưa chắc khám phá chiến lược vượt expert. World model cũng là bottleneck: nếu nó không hiểu contact dynamics, occlusion hoặc vật thể mới, reward có thể đánh lừa policy. Paper cũng ghi rõ real-world deployment vẫn nằm trong TODO của repo, nên không nên đọc kết quả LIBERO như bằng chứng production-ready trên mọi robot.
Checklist triển khai cho team robotics
[ ] Chạy evaluation baseline VLA-Adapter trên LIBERO hoặc dataset nội bộ
[ ] Chuẩn hóa action space thành 7D hoặc format tương thích policy
[ ] Lọc no-op và trajectory lỗi khỏi dataset
[ ] Pretrain world model, kiểm tra MSE/SSIM/LPIPS và video rollout
[ ] Pretrain VLA policy bằng SFT để có action hợp lệ
[ ] Chạy RFT ngắn với rollout times nhỏ để debug reward
[ ] Tăng rollout times và batch size khi reward ổn định
[ ] Evaluate standard setting và perturbation setting
[ ] Chỉ sau đó mới nghĩ đến robot thật với safety monitor
Tóm lại, VLA-RFT là một bước rõ ràng từ "VLA biết bắt chước" sang "VLA biết tự cải thiện trong một môi trường học được". Nó không loại bỏ nhu cầu dữ liệu thật, nhưng dùng dữ liệu thật hiệu quả hơn bằng cách biến nó thành world simulator và reward signal. Với cộng đồng robotics đang tìm đường giữa imitation learning, world models và reinforcement learning, đây là paper rất đáng đọc kỹ.


