VLA-RFT is one of the more practical papers for the current Vision-Language-Action wave. Instead of stopping at imitation learning, the OpenHelix team fine-tunes a VLA manipulation policy with reinforcement learning inside a learned world simulator. The full paper is VLA-RFT: Vision-Language-Action Reinforcement Fine-tuning with Verified Rewards in World Simulators, submitted to arXiv on October 1, 2025. The authors also provide a project page, the OpenHelix-Team/VLA-RFT GitHub repository, and model checkpoints under the VLA-RFT Hugging Face organization.
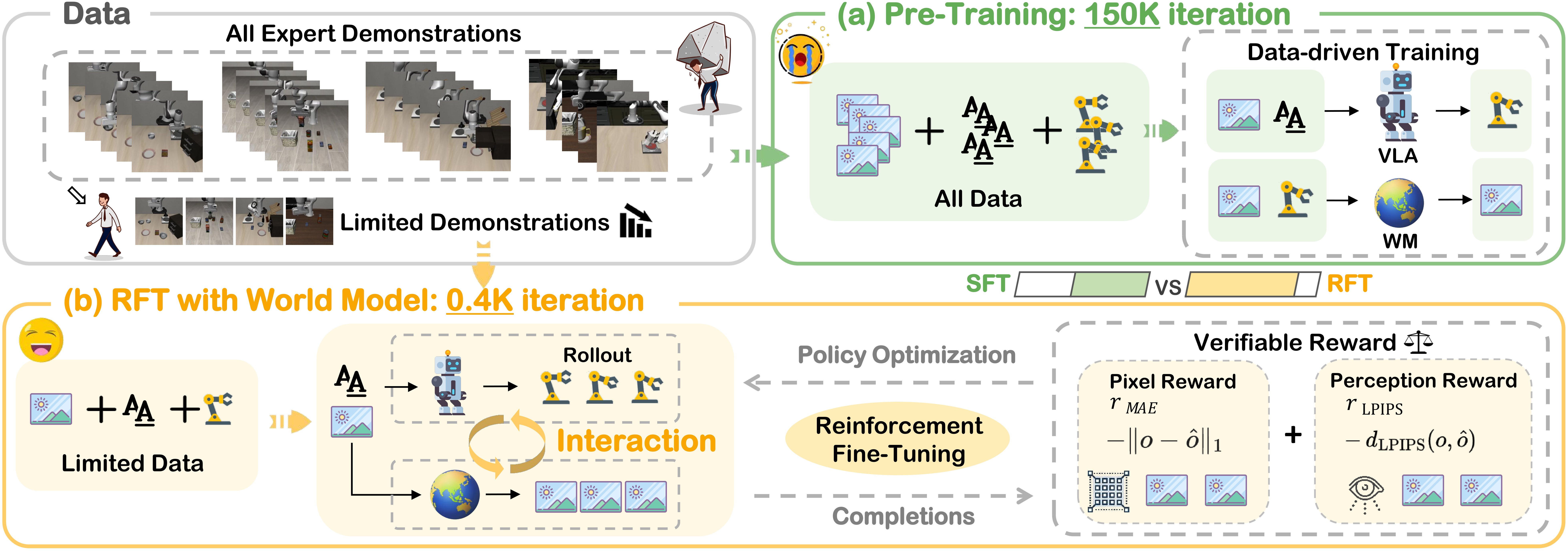
The key idea is not to replace real robots with a handcrafted physics simulator. VLA-RFT learns a data-driven world model from robot interaction data. Given an initial image and an action sequence, the world model predicts future visual observations. The VLA policy can then sample multiple action rollouts inside this learned simulator, receive dense verified rewards from the generated trajectories, and update its action head with GRPO. In simpler terms: VLA-RFT turns demonstration data into an interactive training environment, so the policy can learn from the consequences of its own actions without repeatedly touching the real robot.
If you are new to VLAs, start by understanding what VLA models are and how VLA-Adapter works on LIBERO. This article focuses on the next step: how to fine-tune a manipulation VLA with RL while avoiding the cost of long real-robot rollouts.
The problem: imitation learning accumulates errors
Most VLA systems are trained with behavior cloning or supervised fine-tuning. The dataset provides examples like:
(image, language instruction, robot state) -> action
The model learns to imitate the expert action at each timestep. This is simple, scalable, and effective when the evaluation distribution matches the training data. The weakness appears when the robot drifts even slightly away from the expert trajectory. A bowl may start a few centimeters away from its usual position, the gripper may begin lower than expected, or the camera view may differ. The policy then sees a state that the demonstration dataset barely covers. One small action error leads to a stranger state, and the next action becomes even less reliable. This is the classic compounding error problem.
Reinforcement learning can address this because the policy is evaluated by rollout outcomes, not just per-step action labels. But RL on real robots is expensive, slow, and can damage hardware. RL in a conventional simulator is cheaper, but manipulation depends heavily on contact, friction, object geometry, lighting, camera placement, and gripper calibration. A policy that wins in simulation may fail on a real arm because of the sim-to-real gap.
VLA-RFT takes a middle path:
| Training route | Strength | Weakness |
|---|---|---|
| Imitation learning | Easy to train, uses demonstrations directly | Does not learn from policy-induced mistakes |
| Real-world RL | Optimizes the real task | Expensive, slow, risky |
| Physics-sim RL | Fast rollouts, many samples | Large sim-to-real gap for contact-rich manipulation |
| VLA-RFT | RL inside a learned world model | Depends on world-model quality |
This is related to the broader sim-to-real pipeline, but the simulator is not a rigid-body engine. It is a video and action prediction model trained from robot data.
Architecture overview
VLA-RFT has three main components:
- VLA policy: reads image, language instruction, and proprioception, then produces action chunks.
- World model: reads an initial frame and an action sequence, then predicts future frames.
- Verified reward plus GRPO optimizer: compares predicted trajectories with reference trajectories and updates the VLA action head.
The training loop can be understood as:
Initial image + instruction + robot state
|
v
VLA policy
action chunks a_1...a_T
|
v
Learned world model
predicted frames o_1...o_T
|
v
verified reward from trajectory similarity
|
v
GRPO update for VLA action head
The base policy in the paper is a lightweight variant of VLA-Adapter, a tiny-scale VLA that combines a compact VLM with a flow-matching action head. The VLA-RFT contribution is what happens after supervised pretraining: the policy is post-trained with reinforcement learning rather than only imitating action labels.
The world model is a lightweight autoregressive Transformer with roughly 138M parameters. According to the appendix, it has 12 layers, hidden size 768, FFN size 3072, 12 attention heads, maximum positional embedding length 8192, SiLU activation, and vocabulary size 9008. Inputs are image tokens and action tokens. Outputs are future image tokens decoded into predicted frames.
The LIBERO action space used in the paper is 7-dimensional and matches the VLA policy output. For a robot arm, you can roughly think of it as end-effector delta pose plus gripper control. The policy produces action chunks instead of isolated single-step actions, which helps smooth manipulation and reduces how often the large policy needs to be called.
Stage I: pretrain the world model and VLA policy
VLA-RFT does not start reinforcement learning from scratch. Stage I creates stable initial conditions for both the simulator and the actor.
World model pretraining learns:
p(o_1, o_2, ..., o_T | o_0, a_1, a_2, ..., a_T)
In practice, the LIBERO dataset contains robot trajectories. Training samples include the initial frame, the action sequence, and the future frames. The objective is maximum likelihood over image tokens. The model should learn that if the gripper moves left, the visual scene changes accordingly; if a drawer opens, the next frames should reflect that state change.
VLA policy pretraining is supervised fine-tuning:
pi(a_chunk | image, instruction, proprioception)
The action head uses flow matching. Flow matching is related to diffusion-style continuous generation: it starts from noise and transforms it toward a valid action. In VLA-RFT, the authors extend this into a stochastic policy during Stage II by adding a Sigma Net, allowing the policy to sample multiple action rollouts and compute log probabilities for RL optimization.
Pretraining both sides matters. RL in high-dimensional continuous action spaces can collapse quickly. If the world model predicts nonsense, the reward is misleading. If the initial policy produces unrealistic actions, the world model is pushed outside its training distribution. Pretraining keeps both components near useful robot behavior before reinforcement fine-tuning begins.
Stage II: reinforcement learning inside the world simulator
Stage II is the core of VLA-RFT. For the same initial frame and language instruction, the policy samples multiple action chunks. The world model rolls each action sequence into a predicted visual trajectory. The system then computes a reward for each trajectory.
for each task instance:
sample N action rollouts from the VLA policy
for each rollout:
predicted_video = world_model(initial_frame, actions)
reward = verified_reward(predicted_video, reference_video)
normalize rewards within the group
update policy with GRPO
GRPO stands for Group Relative Policy Optimization. It is similar in spirit to PPO, but it estimates advantage by comparing rollouts within the same group. Instead of requiring a separate critic, the average reward of rollouts from the same starting state acts as the baseline. Rollouts better than the group average are reinforced; worse rollouts are discouraged.
This fits VLA-RFT well because a task instance can generate many candidate action sequences inside the world model. If rollout A moves the bowl closer to the drawer than rollout B, A receives a higher relative reward, and the policy increases the probability of actions like A.
How verified reward works
The paper does not rely only on sparse success/failure rewards. It studies three reward designs:
| Reward | How it is computed | Takeaway |
|---|---|---|
| R1 | Negative L1 distance between policy actions and dataset actions | Close to imitation, small gain |
| R2 | Render policy actions with the world model, then compare to real frames | Adds visual feedback but can inherit generation bias |
| R3 | Render both policy actions and reference actions inside the same world model, then compare | Best result, reduces world-model bias |
The best reward is R3. The reason is practical: if generated frames are compared directly to real frames, errors may come from imperfect pixel generation rather than poor actions. VLA-RFT instead feeds both the reference action sequence and the policy action sequence through the same world model. Both resulting trajectories live in the same generative space. The reward is then the negative weighted distance between them, using reconstruction-style and perceptual terms such as MAE and LPIPS over time.
The reward pipeline looks like:
Initial frame
|---------------- reference actions ------------|
| v
| WM trajectory ref
|
|---------------- policy actions ---------------|
v
WM trajectory policy
reward = - distance(WM trajectory policy, WM trajectory ref)
This is why the paper calls the signal verified reward. It does not require a human to label every rollout, yet it remains grounded in successful reference trajectories from the offline dataset.
Installing the GitHub code
The official repository is OpenHelix-Team/VLA-RFT. The README lists Python 3.10+, CUDA 12.2+, PyTorch 2.4+, and uv as prerequisites. The installation flow below follows the repository instructions:
git clone https://github.com/OpenHelix-Team/VLA-RFT.git
cd VLA-RFT
git submodule update --init --recursive
uv venv --seed -p 3.10
source .venv/bin/activate
uv pip install -e train/verl/".[gpu]"
uv pip install "https://github.com/Dao-AILab/flash-attention/releases/download/v2.6.0.post1/flash_attn-2.6.0.post1+cu122torch2.4cxx11abiFALSE-cp310-cp310-linux_x86_64.whl"
uv pip install -e train/verl/".[vllm]"
uv pip install -r train/verl/requirements.txt
uv pip install git+https://github.com/moojink/dlimp_openvla.git
uv pip install -e train/verl/vla-adapter/openvla-oft
uv pip install -e third_party/LIBERO
For restricted networks, the repository's third_party/README.md describes manual downloads for the LIBERO submodule, flash-attention wheel, and dlimp package.
One practical note: the experiments in the paper were run on 4 A800 GPUs. You can still inspect the code, run smaller evaluations, or experiment with a narrower suite on weaker hardware, but full RFT with 400 steps and 16 rollouts per update is not a lightweight laptop workload. This is research code, not a one-command production deployment package.
Preparing LIBERO data
VLA-RFT uses the modified LIBERO RLDS dataset from OpenVLA. The README says the dataset is about 10GB and contains four suites:
data/
└── modified_libero_rlds/
├── libero_spatial_no_noops/
├── libero_object_no_noops/
├── libero_goal_no_noops/
└── libero_10_no_noops/
The repository's data README uses:
cd data
git clone [email protected]:datasets/openvla/modified_libero_rlds
The _no_noops suffix means near-zero actions are filtered out. This matters. If a manipulation dataset contains too many moments where the robot does nothing, the policy can become overly conservative. For tasks such as opening drawers, placing bowls, and grasping small objects, learning "do nothing" too strongly is harmful.
Training RFT
The main training script is:
cd scripts/libero
bash post_train_rlvr.sh
The script sets LIBERO_TASK_NAME=object, creates TensorBoard logs, disables NCCL P2P for some environments, sets VLLM_ATTENTION_BACKEND=XFORMERS, and calls:
bash train/verl/examples/grpo_trainer/run_vla_rft.sh
Important hyperparameters reported in the paper:
| Component | Value |
|---|---|
| Advantage estimator | GRPO |
| Total RFT steps | 400 |
| Batch size | 16 |
| Rollout times | 16 |
| MSE auxiliary coefficient | 0.01 |
| Entropy coefficient | 0.003 |
| World model | Frozen during RFT |
| Policy update | Mainly action head and Sigma Net |
The small auxiliary MSE loss is an important detail. If the model optimizes only the RL objective, the action head can drift too far from the behavior-cloning prior. The MSE term keeps the policy near valid action regions, while entropy encourages enough exploration. This is a familiar trade-off in RL manipulation: rewards improve outcomes, but priors keep motion sane.
Inference and evaluation
After training a checkpoint, the repository provides an evaluation script:
cd scripts/libero
bash eval_libero.sh
You need to edit:
LIBERO_TASK_NAME=10 # spatial, object, goal, 10
MODEL_DIR=path/to/your/model/checkpoint
The script calls run_libero_eval.py with flags such as:
--use_flow_matching True
--use_proprio True
--num_images_in_input 1
--use_minivla True
--task_suite_name libero_${LIBERO_TASK_NAME}
If you hit an EGL error such as AttributeError: 'NoneType' object has no attribute 'eglQueryString', the README suggests installing OpenGL/EGL packages:
sudo apt-get update
sudo apt-get install libgl1-mesa-dev libegl1-mesa-dev libgles2-mesa-dev libglew-dev
At inference time, the world model does not need to sit in the robot control loop. It is mainly a training-time tool. The fine-tuned policy receives the current observation and instruction, then produces action chunks like a normal VLA policy. This is useful because you pay the world-model cost during training, while runtime remains standard policy inference.
Main results
On LIBERO standard suites, the paper reports:
| Policy | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|
| Base 3w | 82.4 | 84.8 | 85.4 | 57.2 | 77.5 |
| Base 15w | 88.4 | 88.0 | 92.8 | 77.2 | 86.6 |
| VLA-RFT 400 | 94.4 | 94.4 | 95.4 | 80.2 | 91.1 |
| Gain vs Base 15w | +6.0 | +6.4 | +2.6 | +3.0 | +4.5 |
The striking part is the number of fine-tuning steps. VLA-RFT uses 400 RFT steps, while the strong supervised baseline requires 150K iterations. In the appendix comparison with other RL methods, VLA-RFT gains +4.5 points in 400 steps; VLA-RL also gains +4.5 but uses 10,000 steps; offline RL baselines such as ARFM, RWR, and ReinboT use 40,000 steps.
The world model is also evaluated separately:
| Average metric | Value |
|---|---|
| MSE | 0.0039 |
| PSNR | 25.23 dB |
| SSIM | 0.906 |
| LPIPS | 0.059 |
These numbers do not mean the world model perfectly copies reality. They suggest that it is accurate enough to provide a trajectory-level learning signal. In robot learning, a reward that points in the right direction is often more valuable than perfect pixel prediction.
VLA-RFT also improves robustness under perturbations. For example, major goal-position perturbation rises from 44.8% to 51.5%, and minor combined perturbation rises from 63.5% to 70.0%. This matches the original motivation: a policy trained on its own imagined rollouts becomes less brittle than pure behavior cloning.
When should you use VLA-RFT?
VLA-RFT is a good fit when you have three things:
- A clean demonstration dataset with images, actions, proprioception, and task instructions.
- A world model, or enough compute to train one for your domain.
- A need to improve robustness without running long online RL sessions on real robots.
If you only have a few dozen demonstrations, start with imitation learning or VLA-Adapter first. If you have a highly accurate physics simulator and assets that match the real setup, conventional sim RL may still be useful. But if you already have real interaction data and want to use it more effectively than behavior cloning, VLA-RFT is a strong direction to explore.
The main limitation is that the reward is still anchored to expert trajectories. The policy learns to generate trajectories similar to successful references; it is not guaranteed to discover strategies better than the expert. The world model is also a bottleneck. If it does not understand contact dynamics, occlusion, object novelty, or camera changes, the reward may mislead the policy. The GitHub TODO also lists real-world deployment as future work, so LIBERO results should not be interpreted as production readiness for every robot arm.
Implementation checklist for robotics teams
[ ] Evaluate a supervised VLA-Adapter baseline on LIBERO or your internal dataset
[ ] Normalize the action space into a 7D format or your policy-compatible equivalent
[ ] Remove no-op-heavy and failed trajectories from the dataset
[ ] Pretrain the world model and inspect video rollouts, MSE, SSIM, and LPIPS
[ ] Pretrain the VLA policy with supervised fine-tuning
[ ] Run a short RFT job with smaller rollout count to debug reward behavior
[ ] Increase rollout times and batch size after rewards are stable
[ ] Evaluate both standard and perturbed settings
[ ] Move to real robots only with safety monitoring and conservative limits
In short, VLA-RFT is a concrete step from "VLAs that imitate" toward "VLAs that improve through imagined interaction." It does not remove the need for real robot data, but it uses that data more efficiently by turning it into a world simulator and a verified reward signal. For teams working at the intersection of imitation learning, world models, and reinforcement learning, this paper is worth reading carefully.


