You're familiar with Imitation Learning — collect human demos, then teach the robot to copy? It works well, but has a fundamental ceiling: the robot can only be as good as the demo data it's seen. If the demos miss a scenario, the robot freezes.
GigaBrain-0 — an open-source VLA model family from GigaAI — solves this with a breakthrough idea: teach the robot to "imagine" the future before acting, then use Reinforcement Learning to optimize based on those imagined futures. In this article, I'll walk you through the core ideas, architecture, installation, training, and inference with fully open-source code.

Overview: What is GigaBrain-0?
GigaBrain-0 is actually a model family with multiple versions:
| Version | Description | Date |
|---|---|---|
| GigaBrain-0 | Foundation VLA model, Mixture-of-Transformers | 10/2025 |
| GigaBrain-0.1 | Upgraded version, more data, #1 on RoboChallenge | 02/2026 |
| GigaBrain-0.5 | VLA backbone 3.5B params with Embodied CoT | 02/2026 |
| GigaBrain-0.5M* | Full version: VLA + World Model + RL (RAMP) | 02/2026 |
This article focuses on GigaBrain-0.5M* — the most complete version, combining all three components: VLA backbone, World Model (GigaWorld), and the RAMP framework for Reinforcement Learning.
Paper: GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning — GigaBrain Team, 02/2026
GitHub: open-gigaai/giga-brain-0 (Apache 2.0)
Core Idea: The RAMP Framework
The Problem with Pure Imitation Learning
Most current VLA models (RT-2, Octo, π₀) rely on Imitation Learning — the robot learns to copy actions from demo data. This creates two fundamental limitations:
- Performance ceiling is bounded by demo quality — the robot can't outperform its teachers
- Poor generalization — out-of-distribution scenarios cause complete failure
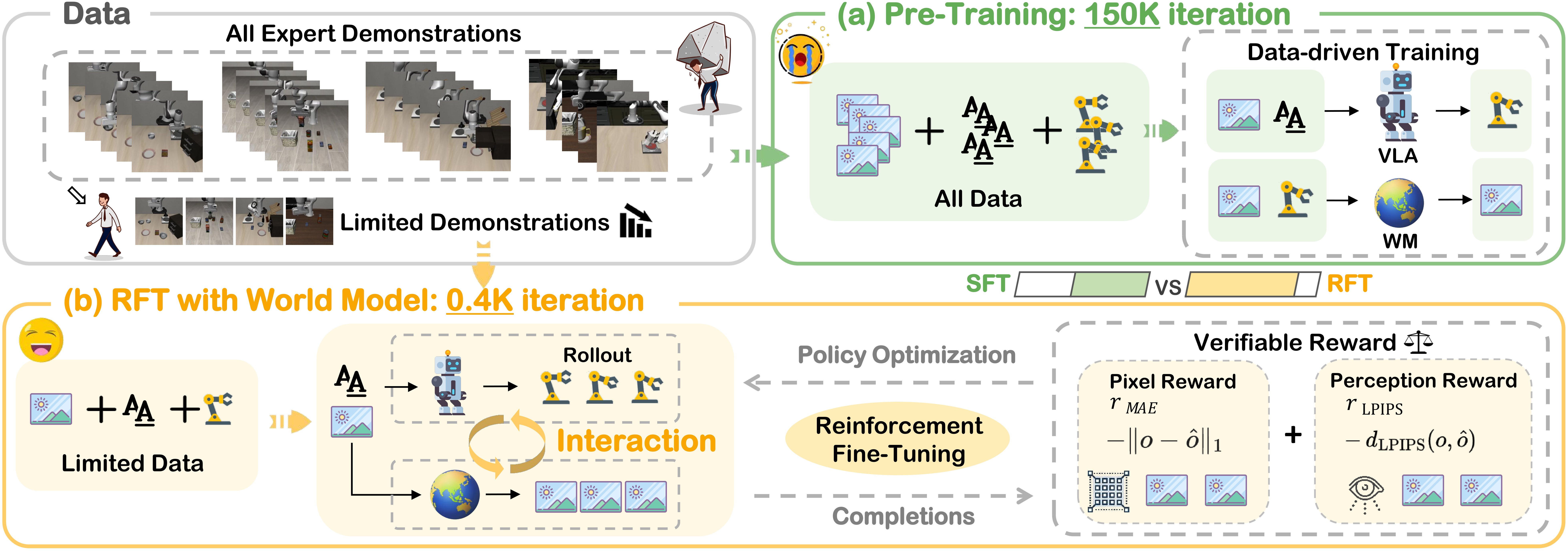
The Solution: Teach Robots to Dream, Then Learn from Dreams
RAMP (Reinforcement leArning via world Model-conditioned Policy) adds two key components:
- World Model (GigaWorld): A generative video model that predicts "what happens next" — like the robot "imagining" the future based on its current actions
- RL fine-tuning: Uses advantage functions from the World Model to optimize the policy, rather than just imitating
The core mathematical formulation:
π*(a|S) ∝ π_ref(a|S) · exp(A(S,a)/β)
Where the state is augmented: S = (o, z, l) with:
- o = current observation (RGB-D camera images)
- z = latent predictions from the World Model (imagined futures)
- l = language instruction
RAMP vs RECAP: Why RAMP Wins
RECAP (from Physical Intelligence, used in π₀.5) also uses RL, but only with binary signals (success/failure). The paper proves that RECAP is actually a special case of RAMP when you marginalize out the World Model information:
H(a|o,z,l) ≤ H(a|o,l)
In plain terms: when the robot can "see the future" (via z), it has less uncertainty than when it only sees the present. The result is RAMP improving by ~30% absolute over RECAP on hard tasks.
Detailed Architecture
GigaBrain-0.5M* consists of 3 main modules:
1. VLA Backbone (GigaBrain-0.5) — 3.5B params
- Vision-Language Encoder: PaliGemma-2 (Google) — processes RGB-D images + text instructions
- Action Head: Diffusion Transformer (DiT) with flow matching — generates action chunks (50 consecutive steps)
- Embodied Chain-of-Thought: Generates subgoal language + discrete action tokens + 2D manipulation trajectories via GRU decoder
Key feature: Knowledge Insulation prevents action prediction optimization from interfering with CoT generation — the two branches are gradient-isolated.
2. World Model (GigaWorld)
- Architecture: Wan 2.2 (spatiotemporal DiT with self-attention)
- Training: Flow matching with optimal transport path interpolation
- Dual outputs: Jointly predicts future visual states AND value estimates
- Prediction horizons: 12, 24, 36, 48 frames ahead
GigaWorld acts as the "dreaming brain" — it takes the current observation and action, then "imagines" what the next sequence of frames will look like. This information is encoded into a latent vector z and fed into the VLA backbone.
3. RAMP — The Glue
RAMP connects the World Model into the policy training loop:
- World Model generates z (latent predictions) for each observation
- Policy receives (o, z, l) instead of just (o, l)
- Advantage function A(S,a) computed from World Model's value predictions
- KL-regularized RL update keeps policy close to pretrained reference
Stochastic attention masking (p=0.2): During training, 20% of the time the World Model is "turned off" (masked). This prevents the policy from over-relying on the World Model — at inference, if the World Model is slow, the policy still works.
Environment Setup
Hardware Requirements
- GPU: NVIDIA A100/A800 (80GB VRAM) for training. RTX 4090 (24GB) for inference
- RAM: 64GB+ for training, 32GB for inference
- Storage: ~200GB for datasets + checkpoints
- CUDA: 12.1+
Step 1: Create Environment
# Create conda environment
conda create -n giga_brain_0 python=3.11.10 -y
conda activate giga_brain_0
# Install main dependencies
pip3 install giga-train giga-datasets lerobot==0.3.2 matplotlib numpydantic
Step 2: Clone and Install giga-models
# Clone giga-models (model definitions)
git clone https://github.com/open-gigaai/giga-models.git
cd giga-models && pip3 install -e .
cd ..
# Clone giga-brain-0 (training + inference code)
git clone https://github.com/open-gigaai/giga-brain-0.git
cd giga-brain-0
Step 3: Download Pretrained Weights
Weights are hosted on HuggingFace (org: open-gigaai):
# Download VLA backbone (3.5B params, ~7GB)
huggingface-cli download open-gigaai/GigaBrain-0.1-3.5B-Base --local-dir checkpoints/gigabrain-0.1
# Download World Model
huggingface-cli download open-gigaai/GigaWorld-0-Video-GR1-2b --local-dir checkpoints/gigaworld
# Version without depth camera (easier to deploy)
huggingface-cli download open-gigaai/GigaBrain-0-3.5B-Base --local-dir checkpoints/gigabrain-0-nodepth
Data Preparation
GigaBrain-0 uses LeRobot format. If you have HDF5 data, convert as follows:
Convert HDF5 to LeRobot Format
python scripts/convert_from_hdf5.py \
--data-path /path/to/raw_hdf5_data_path \
--out-dir /path/to/lerobot_dataset \
--task "Pick up the red block and place it in the bin"
Compute Normalization Statistics
python scripts/compute_norm_stats.py \
--data-paths /path/to/dataset1 /path/to/dataset2 \
--output-path /path/to/norm_stats.json \
--embodiment-id 0 \
--delta-mask True,True,True,True,True,True,False,True,True,True,True,True,True,False \
--sample-rate 1.0 \
--action-chunk 50 \
--action-dim 32
Understanding delta-mask: Each True/False corresponds to an action dimension. True = use delta (change from previous step), False = use absolute value. Typically gripper uses absolute (open/close), joints use delta.
Training Pipeline — 4 Stages

Stage 1: World Model Pre-training
GigaWorld is trained on 10,931 hours of visual experience:
- 61% (6,653 hours) — data synthesized by the World Model itself (self-play)
- 39% (4,278 hours) — real robot data from multiple platforms (UR5, Franka, ARX5, ALOHA, Agibot G1)
Reward function uses sparse signals:
- 0 on task success
- -C_fail on failure
- -1 per timestep (encourages faster completion)
Stage 2: Policy Fine-tuning with World Model
This is the most critical step — fine-tuning the VLA backbone with World Model information:
# Fine-tune for AgileX Cobot Magic
python scripts/train.py --config configs.giga_brain_0_agilex_finetune.config
# Fine-tune for Agibot G1 humanoid
python scripts/train.py --config configs.giga_brain_0_agibot_finetune.config
# Train from scratch (if desired)
python scripts/train.py --config configs.giga_brain_0_from_scratch.config
Key hyperparameters:
- Batch size: 256
- Training steps: 20,000
- Stochastic masking: p=0.2
- Single denoising step (for efficiency)
- n-step temporal difference for advantage computation
Stage 3: Human-in-the-Loop Rollout (HILR)
After the policy is reasonably good, collect additional data by:
- Robot runs the policy autonomously
- Human operator intervenes when the robot is about to fail
- Automatic detection and removal of temporal discontinuities at intervention points
HILR data has a distribution closer to the actual policy than pure teleoperation, reducing distribution shift.
Stage 4: Continual Joint Training
World Model AND Policy are trained simultaneously on new HILR data. This creates a self-improvement loop:
Better Policy → Better HILR Data → More Accurate World Model → Better Policy → ...
Inference and Deployment
Offline Inference (Testing on Dataset)
python scripts/inference.py \
--model-path checkpoints/gigabrain-0.1 \
--data-path /path/to/lerobot_dataset \
--norm-stats-path /path/to/norm_stats.json \
--output-path /tmp/vis_path \
--delta-mask True,True,True,True,True,True,False,True,True,True,True,True,True,False \
--embodiment-id 0 \
--action-chunk 50 \
--original-action-dim 14 \
--tokenizer-model-path google/paligemma2-3b-pt-224 \
--fast-tokenizer-path physical-intelligence/fast \
--device cuda
Server-Client Deployment (For Real Robots)
On the GPU machine (server):
python scripts/inference_server.py \
--model-path checkpoints/gigabrain-0.1 \
--tokenizer-model-path google/paligemma2-3b-pt-224 \
--fast-tokenizer-path physical-intelligence/fast \
--delta-mask True,True,True,True,True,True,False,True,True,True,True,True,True,False \
--embodiment-id 0 \
--norm-stats-path /path/to/norm_stats.json \
--original-action-dim 14
On the robot machine (client):
# Client sends sensor data, receives action predictions
python scripts/inference_client.py
# Or dedicated client for AgileX robots
python scripts/inference_agilex_client.py
Two inference modes:
- Efficient Mode: Bypasses World Model (fastest, uses attention masking), suitable for simple tasks
- Standard Mode: World Model active, for complex tasks requiring long-horizon planning
Edge Deployment
GigaBrain-0-Small — a smaller variant optimized for NVIDIA Jetson AGX Orin, suitable for running directly on the robot without a separate GPU server.
Benchmark Results
RoboChallenge Leaderboard (02/2026)
| Model | Average Success Rate | Rank |
|---|---|---|
| GigaBrain-0.1 | 51.67% | #1 |
| π₀.5 (Physical Intelligence) | 42.67% | #2 |
Evaluated across 30 manipulation tasks on 20 different robots (UR5, Franka, ARX5, ALOHA).
RAMP vs RECAP — Direct Comparison
| Task | RAMP | RECAP | Improvement |
|---|---|---|---|
| Box Packing | ~95% | ~65% | +30% |
| Espresso Preparation | ~95% | ~65% | +30% |
| Laundry Folding | ~90% | ~60% | +30% |
The largest improvements are on long-horizon, complex tasks — where "imagining the future" provides the greatest advantage. For simple tasks (pick-and-place), the gap is smaller.
Value Prediction Quality
| Method | Inference Time | MAE | Kendall τ |
|---|---|---|---|
| VLM-based | 0.32s | 0.0683 | 0.7972 |
| WM value-only | 0.11s | 0.0838 | 0.7288 |
| WM state+value | 0.25s | 0.0621 | 0.8018 |
World Model predicting state+value jointly gives the best results, with acceptable latency (0.25s on A800).
Practical Tips
1. Start from Pretrained Weights
Don't train from scratch unless you have a large GPU cluster. Use GigaBrain-0.1-3.5B-Base or GigaBrain-0-3.5B-Base (no depth camera needed) as your starting checkpoint.
2. Get the Delta-Mask Right
A wrong delta-mask will cause the robot to "run away" — joints increasing to infinity. Rules:
- Joints (angles/positions):
True(delta) - Gripper:
False(absolute — open/close)
3. Action Chunk Size
Default is 50 steps. If your task has a higher control frequency (>30Hz), reduce the chunk size. If the task is slow (making espresso), 50 is reasonable.
4. Stochastic Masking at Deploy Time
Keep p=0.2 masking even during inference. This creates dropout-like regularization, making the policy more robust to World Model noise.
Conclusion
GigaBrain-0.5M* marks a major advancement: VLA that doesn't just imitate, but can "dream" and learn from its dreams. The RAMP framework enables systematic integration of world models into RL training, and experimental results show significant improvements over prior methods.
With open-source code (Apache 2.0), pretrained weights on HuggingFace, and support for multiple robot platforms, this is one of the most accessible VLA frameworks available today for the robotics community.
Important links:
- Paper: arxiv.org/abs/2602.12099
- GitHub: github.com/open-gigaai/giga-brain-0
- Project page: gigabrain05m.github.io
- HuggingFace: huggingface.co/open-gigaai
Related Posts
- VLA Models: From Language to Robot Actions — Overview of Vision-Language-Action models
- Reinforcement Learning Basics for Robotics — RL fundamentals before diving into RAMP
- Diffusion Policy for Robot Manipulation — Understanding Diffusion Transformers — the backbone of GigaBrain