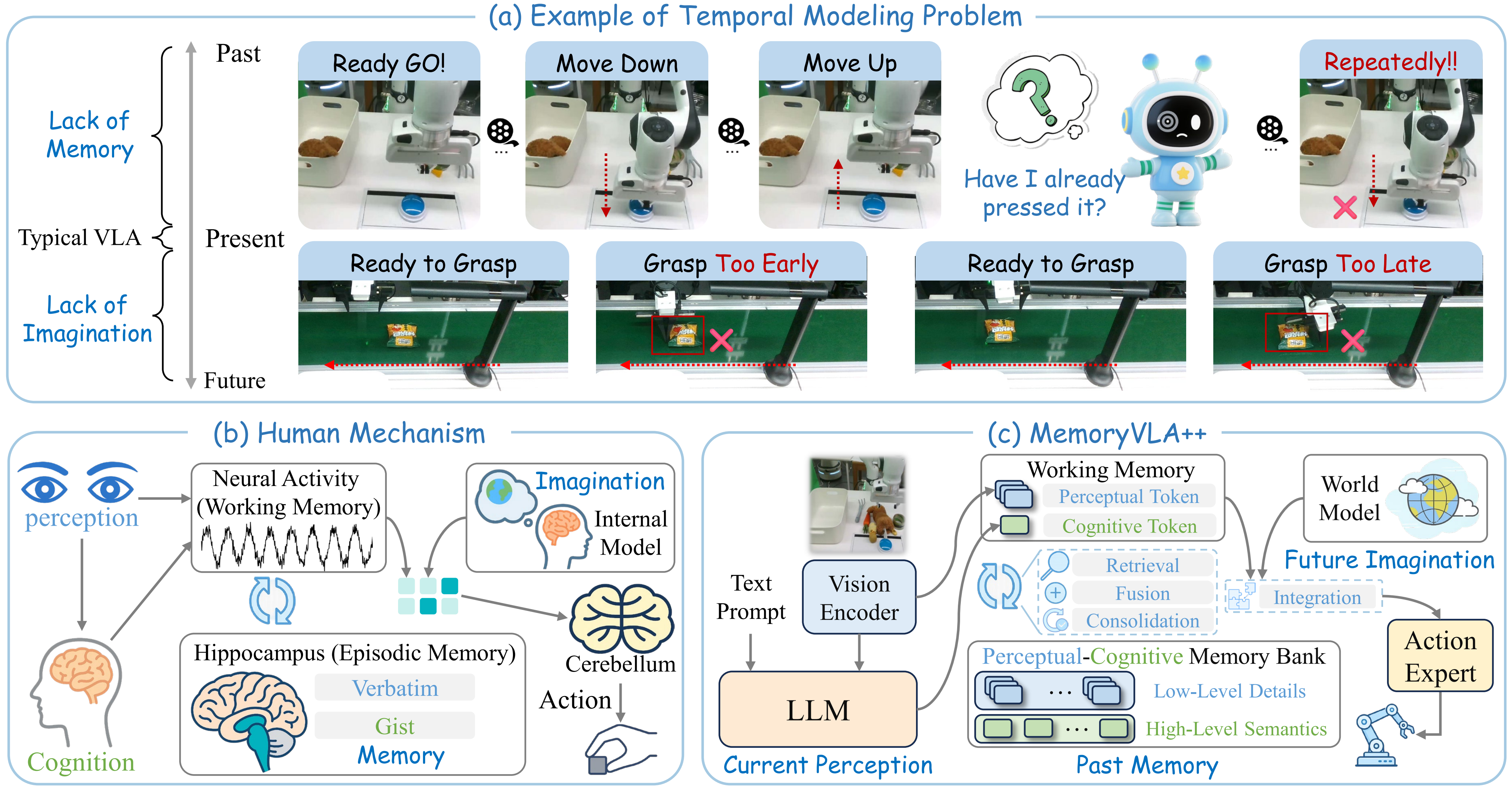
UniIntervene giải quyết vấn đề gì?
Nếu bạn fine-tune robot manipulation policy bằng real-world reinforcement learning, vấn đề đầu tiên thường không phải là thuật toán RL trên giấy. Vấn đề thật là robot bị kẹt trong những trạng thái "không hẳn nguy hiểm nhưng không tiến triển": gripper đã chạm vật nhưng không nhấc được, RAM module gần đúng slot nhưng cứ cạ cạnh, khăn bị kéo lệch nên policy lặp lại một động tác vô ích. Trong các pipeline human-in-the-loop RL như HiL-SERL, người vận hành phải dùng teleoperation để takeover, kéo robot về một trạng thái có ích, rồi nhả lại cho policy học tiếp.
Paper UniIntervene: Agentic Intervention for Efficient Real-World Reinforcement Learning, submitted ngày 10/06/2026, đề xuất một cách giảm chi phí đó: thay vì để con người quyết định mọi intervention, hệ thống học một agentic intervention model để tự phát hiện rollout đang bị stagnation và tự recovery về high-value state. Theo project page chính thức, UniIntervene đạt 88% average success rate, tăng 8.6% so với HiL-RL baseline, đồng thời giảm 57% human interventions so với HiL-SERL trên 5 task manipulation thực.
Điểm quan trọng: đây không phải một "safety stop" đơn giản. Safety stop chỉ hỏi "robot có nguy hiểm không?". UniIntervene hỏi câu khác: nếu tiếp tục action hiện tại, task có đang tiến triển không? Nếu value không tăng trong một cửa sổ thời gian, model trigger recovery, retrieve một target tốt từ memory, rồi dùng goal-conditioned recovery policy để tạo corrective action chunk.
Nếu bạn mới với RL, nên đọc trước các bài nền tảng về reinforcement learning và Vision-Language-Action models trong phần liên quan cuối bài. Bài này đi theo góc nhìn engineer: UniIntervene hoạt động thế nào, repo hiện có gì, cách dựng một bản thử nghiệm, training, inference, và đọc kết quả ra sao.
Nguồn gốc, repo, và trạng thái code
Các nguồn chính cần đọc:
| Nguồn | Link | Ghi chú |
|---|---|---|
| Paper arXiv | arxiv.org/abs/2606.12372 | Có tên tác giả, abstract, PDF, submitted 10/06/2026 |
| Project page | denghaoyuan123.github.io/UniIntervene-project | Có hình method, video, task suite, bảng kết quả |
| GitHub repo | Denghaoyuan123/UniIntervene-project | Hiện là static website repo, chưa phải training code |
Điểm cần nói thẳng: nút Code trên project page hiện vẫn là placeholder href="#", và README của GitHub repo ghi đây là "Static project / paper page", không phải repository chứa training scripts. Vì vậy, "thử UniIntervene" ở thời điểm hiện tại nên hiểu là tái tạo pipeline theo paper hoặc tích hợp ý tưởng vào HiL-RL stack sẵn có, không phải clone một package chính thức rồi chạy một lệnh.
Điều này cũng ảnh hưởng tới cách cài đặt trong bài: phần dưới dùng pseudo-code và cấu trúc repo đề xuất để bạn thử trên lab stack riêng, ví dụ ROS 2 + Python control loop + policy server + replay buffer. Khi tác giả public code thật, bạn có thể thay các module custom bằng implementation chính thức.
Ý tưởng paper trong một câu
UniIntervene biến intervention từ việc con người sửa lỗi thủ công thành một quá trình value-aware autonomous recovery:
policy action
|
v
future-conditioned value estimator
|
v
temporal value-risk critic
|
+-- value still improving -> execute policy action
|
+-- sustained stagnation -> retrieve high-value goal
|
v
recovery policy action chunk
Trong HiL-RL truyền thống, human operator là trigger và controller:
Robot làm sai -> người thấy sai -> người takeover -> người lái recovery
Trong UniIntervene, model cố gắng tự làm phần giữa:
Robot không tiến triển -> value-risk critic trigger -> memory chọn goal -> recovery policy tự lái
Human vẫn còn trong loop, nhưng được đẩy về vai trò xử lý residual cases: tình huống nguy hiểm, failure mode chưa có trong memory, hoặc state quá out-of-distribution.
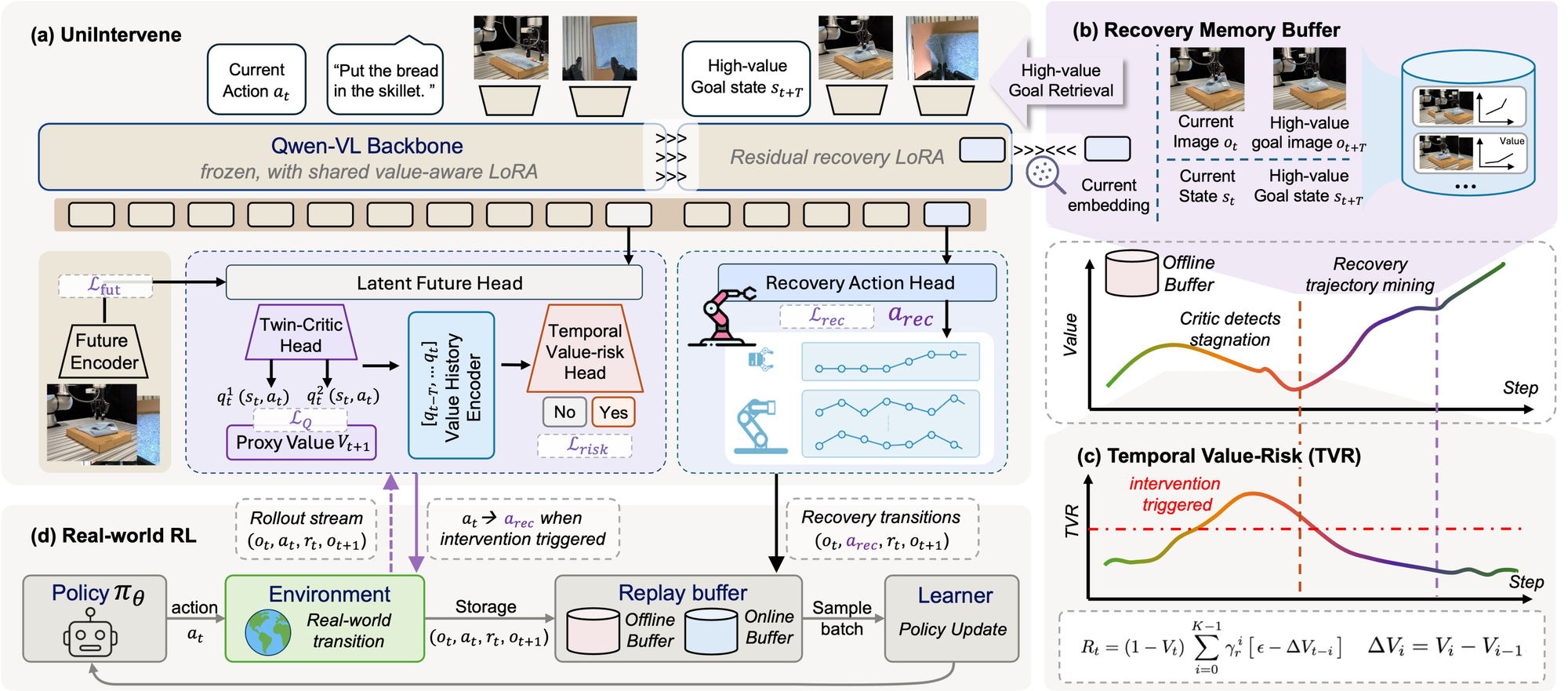
Kiến trúc: bốn module chính
Project page mô tả UniIntervene gồm Qwen-VL backbone, Latent Future Head, twin critic, temporal value-risk supervision, recovery action head và memory buffer. Paper appendix chi tiết hơn: backbone là Qwen3-VL-2B-Instruct với LoRA rank 16; future target dùng V-JEPA2 frozen encoder; proxy value dùng SigLIP-SO400M + Gemma-3-270M; recovery action dùng FAST tokenizer cho action chunk.
1. Proxy value function
Trước khi train intervention model, nhóm tác giả train một proxy value function offline. Nó biến sparse success/failure thành progress signal liên tục. Với successful episode dài T, transition t nhận normalized progress:
v_t = t / (T - 1)
Failed episode có value thấp. Objective gồm Bellman consistency, progress regression, monotonicity loss và một CQL-style regularizer nhỏ để tránh overestimate state ngoài distribution:
L_proxy = L_TD + L_progress + 0.05 * L_CQL
Vì trigger và memory retrieval đều phụ thuộc value này, nếu proxy value sai thì toàn bộ hệ thống sẽ trigger quá sớm, quá muộn, hoặc retrieve nhầm goal.
2. Future-conditioned action-value estimator
Thay vì estimate value trực tiếp từ frame hiện tại, UniIntervene dự đoán latent consequence của action:
observation o_t + instruction l + action a_t
|
v
Qwen3-VL shared hidden state h_t
|
v
future head predicts z_hat_{t+1}
|
v
twin value head predicts q_hat_t
Lý do rất thực dụng: trong contact-rich manipulation, một frame đơn lẻ có thể nhìn "xấu" nhưng vẫn cần thiết. Ví dụ khi cắm RAM, module hơi nghiêng trong vài frame chưa chắc là failure; nó có thể là bước align trước khi press down. Future-conditioned value giúp hỏi "action này dẫn tới latent future nào?" thay vì "frame này trông giống goal chưa?".
3. Temporal value-risk critic
Naive trigger kiểu if value < threshold then intervene rất dễ sai. Robot folding towel hoặc wiping board thường đi qua low-value state tạm thời. UniIntervene dùng trend:
Delta V_i = V_i - V_{i-1}
R_t = (1 - V_t) * sum(gamma_r^i * max(0, epsilon - Delta V_{t-i}))
Diễn giải đơn giản:
| Thành phần | Ý nghĩa |
|---|---|
Delta V |
value có tăng qua từng bước không |
epsilon |
tốc độ progress tối thiểu kỳ vọng |
sliding window K=8 |
tránh phản ứng với noise một frame |
(1 - V_t) |
gần thành công thì giảm risk |
R_t |
risk của stagnation kéo dài |
Khi sigmoid(R_hat_t) >= tau_int, paper dùng tau_int = 0.5, system trigger recovery.
4. Memory-guided goal-conditioned recovery
Khi biết rollout đang kẹt, model vẫn cần biết nên recovery tới đâu. UniIntervene xây một recovery memory từ prior rollouts:
M = {
intervention_state -> high_value_future_state
}
Mỗi entry lưu một state bị can thiệp hoặc state low-progress, cùng một future state tốt hơn trong cùng rollout. Khi inference, model embedding current context rồi tìm memory key gần nhất bằng cosine similarity:
current context: phi(o_t, instruction)
memory key: phi(o_fail_j, instruction_j)
retrieve: argmax cosine similarity
goal: high-value state paired with that key
Recovery policy nhận current observation, retrieved goal, instruction, rồi sinh action chunk horizon H=8. Điểm hay là policy không replay action cũ. Nó học goal-reaching behavior: memory nói "đi đâu", recovery policy học "đi như thế nào".
Cài đặt bản thử nghiệm
Vì repo chính thức chưa public training code, bạn có thể dựng skeleton như sau. Mục tiêu là giữ interface rõ, để sau này thay module bằng code chính thức dễ hơn.
uniintervene_lab/
configs/
ur7e_ram_insertion.yaml
data/
demos/
rollouts/
recovery_memory/
src/
robot_env.py
policy_server.py
proxy_value.py
intervention_model.py
recovery_policy.py
train_proxy_value.py
train_intervention.py
train_recovery.py
run_hil_rl.py
Môi trường Python tối thiểu:
python -m venv .venv
source .venv/bin/activate
pip install torch torchvision transformers accelerate peft
pip install numpy scipy opencv-python h5py tqdm
pip install gymnasium stable-baselines3
pip install faiss-cpu
Nếu chạy robot thật, bạn cần thêm control stack riêng:
pip install rclpy # nếu dùng ROS 2 Python environment đã build
pip install pyspacemouse
Với UR7e hoặc robot tương tự, hãy tách rõ hai loop:
| Loop | Tần số gợi ý | Vai trò |
|---|---|---|
| Low-level servo | 100-500 Hz | nhận velocity/pose command, enforce safety |
| Policy loop | 5-20 Hz | chạy VLA/policy, intervention, recovery |
Không nên để VLM inference trực tiếp điều khiển actuator ở tần số cao. Hãy để model xuất action chunk hoặc target delta, sau đó low-level controller execute với giới hạn vận tốc, force và workspace.
Chuẩn bị dữ liệu
Bạn cần ba loại dữ liệu:
| Dữ liệu | Dùng để train gì | Ví dụ |
|---|---|---|
| Demonstrations thành công | SFT policy, proxy value progress | 20 demos/task như paper dùng cho pi0.5 baseline |
| Failed rollouts | proxy value, trigger labels | rollout policy bị kẹt, near-miss, wrong grasp |
| Intervention segments | recovery memory, recovery policy | operator takeover từ bad state tới good state |
Một schema đơn giản cho mỗi episode:
{
"task": "ram_insertion",
"instruction": "Insert the RAM module into the slot",
"success": true,
"steps": [
{
"t": 0,
"wrist_rgb": "frames/wrist_000000.jpg",
"third_rgb": "frames/third_000000.jpg",
"ee_pose": [0, 0, 0, 0, 0, 0, 1],
"action": [0, 0, 0, 0, 0, 0, 0],
"human_intervene": false
}
]
}
Hãy log cả human_intervene, vì intervention rate là metric chính. Nếu dùng SpaceMouse, log raw command và action sau khi safety filter.
Training pipeline từng bước
Bước 1: train hoặc chọn base policy
Paper dùng pi0.5 (SFT) làm policy baseline với 20 demonstrations mỗi task. Trong lab của bạn, base policy có thể là Diffusion Policy, ACT, OpenVLA/OpenVLA-OFT, hoặc controller học từ LeRobot dataset. Nếu đang làm VLA/RL, ProcVLM cũng là một nhánh liên quan: ProcVLM tập trung vào reward progress, còn UniIntervene tập trung vào when/how to intervene.
Bước 2: train proxy value
Pseudo-code:
for batch in loader:
obs_t, obs_tp1, instruction, reward, done, progress = batch
v_t = proxy_value(obs_t, instruction)
v_tp1 = proxy_value(obs_tp1, instruction).detach()
td_target = reward + gamma * (1 - done) * v_tp1
loss_td = smooth_l1(v_t, td_target)
loss_progress = smooth_l1(v_t, progress)
loss_mono = relu(v_t - v_tp1).mean()
loss_cql = conservative_state_value_loss(v_t, negatives)
loss = loss_td + loss_progress + 0.05 * loss_cql + loss_mono
loss.backward()
optimizer.step()
Validation quan trọng nhất không phải loss nhỏ, mà là curve value của successful rollout tăng đều và failed rollout nằm thấp. Nếu successful và failed overlap mạnh, temporal value-risk sẽ không đáng tin.
Bước 3: mine trigger labels
Từ value sequence, đánh dấu các đoạn stagnation:
def mine_trigger_labels(values, k=8, eps=0.005):
labels = [0] * len(values)
for t in range(k, len(values)):
window = values[t-k:t+1]
deltas = [window[i] - window[i-1] for i in range(1, len(window))]
shortfall = sum(max(0.0, eps - d) for d in deltas)
plateau = max(window) - min(window) < 0.03
decline = sum(d < 0 for d in deltas) >= k // 2
if shortfall > 0.04 and (plateau or decline):
labels[t] = 1
return labels
Đừng quá aggressive. Nếu trigger quá nhiều, bạn biến recovery policy thành policy chính và mất lợi ích RL exploration.
Bước 4: train intervention model
Intervention model học nhiều head cùng lúc:
| Head | Target | Loss |
|---|---|---|
| Future head | V-JEPA2 latent của o_{t+1} |
normalized MSE |
| Value head | proxy value target | Smooth-L1 |
| Risk head | temporal value-risk R_t |
Smooth-L1 |
| Trigger head | mined intervention label | focal loss |
Pseudo-code:
h = qwen_vl(obs_t, instruction, action_t, query_token=True)
z_pred = future_head(h)
q_pred = twin_value_head(z_pred).min()
risk_pred = risk_head(z_pred, value_history)
trigger_logit = trigger_head(z_pred.detach(), q_pred.detach())
loss = (
mse_norm(z_pred, vjepa2(obs_tp1)) +
smooth_l1(q_pred, q_target) +
smooth_l1(risk_pred, risk_target) +
focal_loss(trigger_logit, trigger_label)
)
Bước 5: build recovery memory
Mine các segment có value tăng rõ:
for episode in episodes:
values = proxy_value_sequence(episode)
for start in range(0, len(values) - span):
end = start + span
if values[end] - values[start] >= delta and values[end] > tau_goal:
memory.add(
key_obs=episode.obs[start],
key_state=episode.state[start],
goal_obs=episode.obs[end],
goal_state=episode.state[end],
instruction=episode.instruction,
)
Theo appendix, paper giữ khoảng 120 recovery targets cho từng task Pick Eggplant, Tube Insertion, RAM Insertion, Wipe Whiteboard, và 240 targets cho Fold Towel vì task này dài và noisy hơn.
Bước 6: train recovery policy
Recovery policy là behavior cloning trên segment từ bad/intervention state tới high-value goal:
goal = retrieve_goal(memory, obs_t, instruction)
action_tokens = fast_tokenizer.encode(action_chunk)
logits = recovery_policy(obs_t, goal.obs, instruction)
loss = cross_entropy(logits, action_tokens)
Nếu bạn chưa có FAST tokenizer, có thể bắt đầu bằng continuous action MLP hoặc diffusion action head. Nhưng nếu base policy là VLA/action-token model, tokenized chunk sẽ khớp hơn với stack hiện đại.
Inference: chạy trong HiL-RL loop
Trong rollout thật, UniIntervene nằm giữa base policy và robot controller:
while not done:
obs = env.observe()
action = base_policy(obs, instruction)
q, risk, trigger = intervention_model(obs, instruction, action, value_history)
value_history.append(q)
if trigger > 0.5:
goal = memory.retrieve(obs, instruction)
action_chunk = recovery_policy(obs, goal, instruction)
env.execute_chunk(action_chunk)
replay.add_recovery(obs, goal, action_chunk)
else:
env.step(action)
replay.add_policy_step(obs, action)
if human_requests_takeover():
correction = teleop.read()
env.step(correction)
replay.add_human_intervention(obs, correction)
Một rule thực tế: luôn giữ human override ở tầng cao hơn UniIntervene. UniIntervene giảm intervention, không thay thế safety operator trong giai đoạn research.
Kết quả paper
Benchmark dùng UR7e arm, parallel-jaw gripper, wrist camera, fixed third-person camera và SpaceMouse. Năm task gồm Pick Eggplant, Tube Insertion, RAM Insertion, Wipe Whiteboard, Fold Towel.
| Method | Pick SR/IR | Tube SR/IR | RAM SR/IR | Wipe SR/IR | Fold SR/IR | Avg SR/IR |
|---|---|---|---|---|---|---|
pi0.5 SFT |
95 / - | 30 / - | 10 / - | 65 / - | 70 / - | 54 / - |
| HiL-SERL | 90 / 28.7 | 60 / 30.2 | 85 / 32.3 | 85 / 30.5 | 85 / 49.8 | 81 / 34.3 |
| HiL-SERL + FA-RL | 85 / 20.4 | 60 / 22.1 | 75 / 27.9 | 80 / 21.9 | 85 / 30.9 | 77 / 24.6 |
| HiL-SERL + UniIntervene | 95 / 10.0 | 70 / 15.8 | 95 / 12.1 | 90 / 10.9 | 90 / 24.1 | 88 / 14.6 |
SR là success rate, càng cao càng tốt. IR là human intervention rate, càng thấp càng tốt. Điểm đáng chú ý là UniIntervene không chỉ giảm IR; nó còn tăng SR trên mọi task. Điều này cho thấy autonomous recovery không chỉ tiết kiệm công người vận hành, mà còn đưa rollout về trạng thái học được thay vì để policy lặp vô ích.
Ablation cũng hợp lý: bỏ value prediction hoặc temporal value-risk làm trigger tệ hơn; bỏ memory goal làm online success giảm dù intervention F1 gần như không đổi. Nói cách khác, "trigger đúng lúc" và "recovery đúng chỗ" là hai vấn đề khác nhau.
Khi nào nên thử UniIntervene?
UniIntervene đáng thử nếu lab của bạn đã có:
| Điều kiện | Vì sao cần |
|---|---|
| Base policy đã chạy được | UniIntervene không thay thế policy chính |
| Replay logging tốt | cần successful, failed, intervention segments |
| Teleop interface ổn định | cần data recovery ban đầu và safety fallback |
| Value/progress validation | trigger phụ thuộc calibration của proxy value |
| Task có stagnation rõ | contact-rich insertion, wiping, folding, regrasping |
Không nên bắt đầu UniIntervene nếu robot của bạn chưa có safety envelope, chưa log data đầy đủ, hoặc task quá đơn giản đến mức SFT policy đã gần 100%. Với task đơn giản, overhead của VLM + recovery memory có thể không đáng.
Checklist triển khai nhanh
[ ] Chọn 1 task contact-rich, ví dụ insertion hoặc wiping
[ ] Thu 20-50 demonstrations thành công
[ ] Chạy base policy để lấy failed rollouts
[ ] Thu intervention segments bằng SpaceMouse/teleop
[ ] Train proxy value, kiểm tra success curve tăng đều
[ ] Mine stagnation labels với window K=8
[ ] Train intervention model với future/value/risk/trigger heads
[ ] Build recovery memory, audit top-1 retrieval similarity
[ ] Train recovery policy trên action chunks
[ ] Chạy HiL-RL với human override luôn bật
[ ] Report SR, IR, số intervention mỗi episode, failure mode
Hạn chế cần nhớ
Paper cũng nêu rõ vài hạn chế. Thứ nhất, trigger phụ thuộc proxy value. Nếu value function không phản ánh task progress, model sẽ trigger sai. Thứ hai, recovery memory chỉ tốt với failure modes đã từng thấy. Một state hoàn toàn mới có thể retrieve goal không phù hợp. Thứ ba, kết quả hiện tập trung vào tabletop manipulation với một robot embodiment; chưa có bằng chứng đủ mạnh cho mobile manipulation, humanoid whole-body policy, hoặc multi-robot deployment.
Vì vậy, hãy xem UniIntervene như một lớp intervention automation phía trên HiL-RL, không phải một công thức thần kỳ loại bỏ con người khỏi real-world RL.