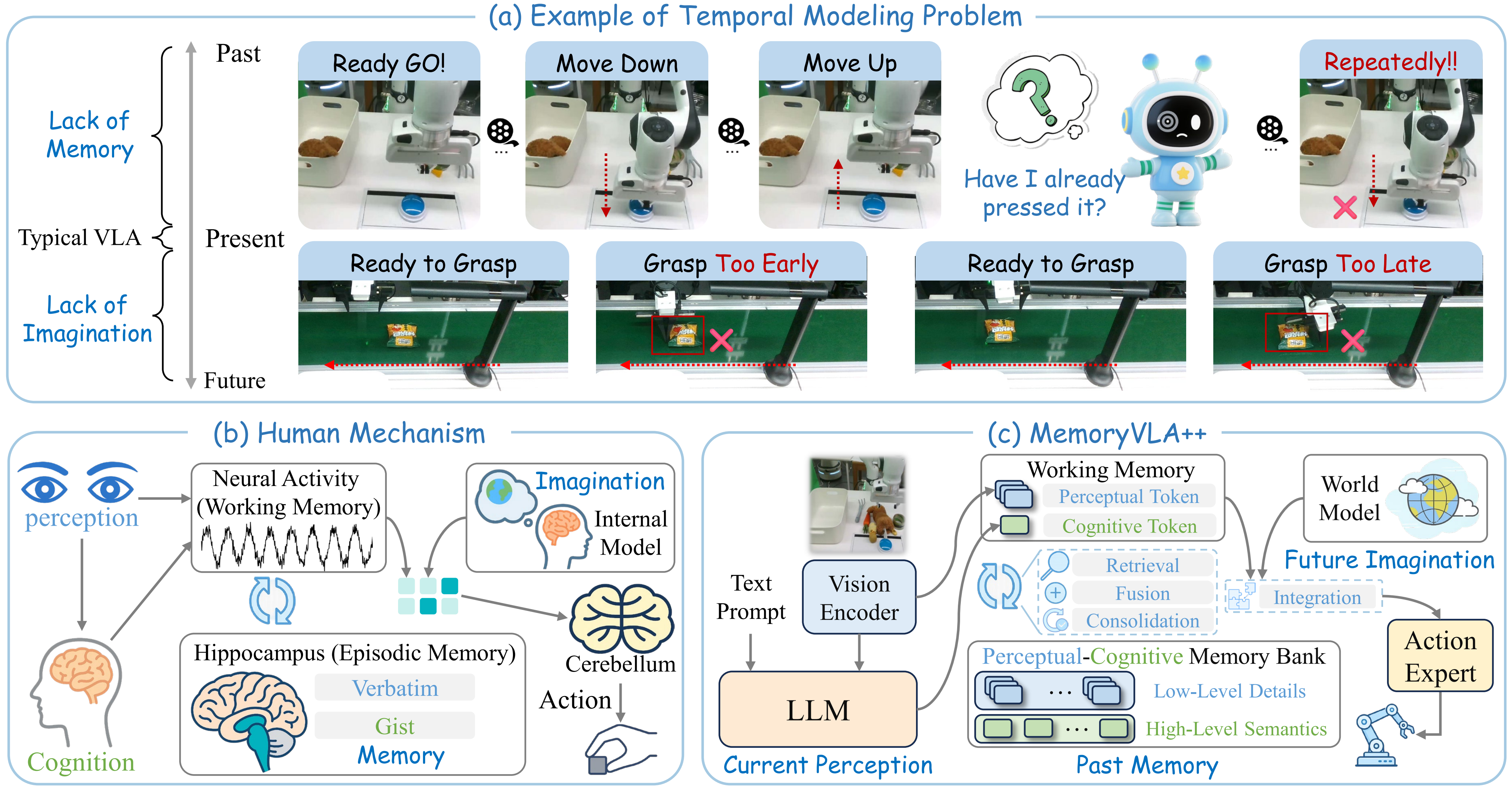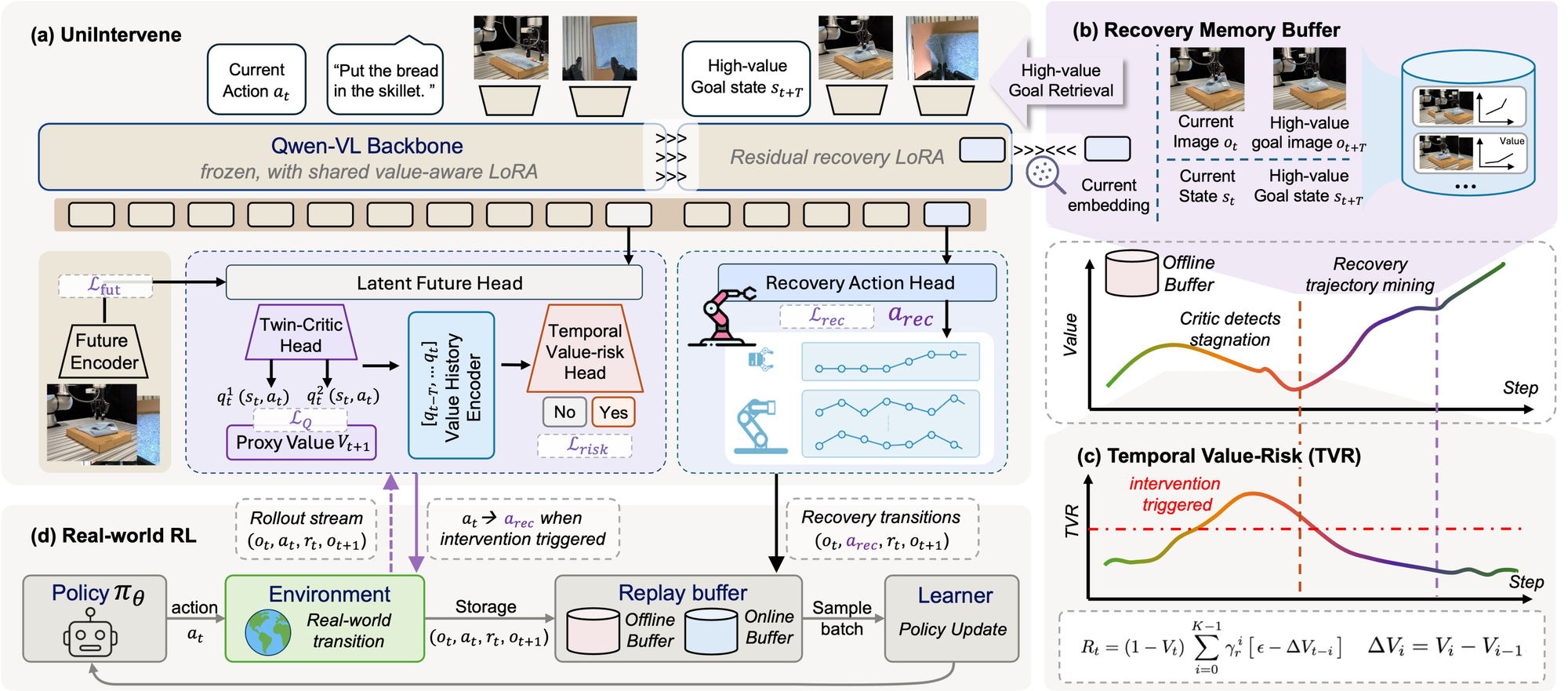
What Problem Does UniIntervene Solve?
When you fine-tune a robot manipulation policy with real-world reinforcement learning, the hard part is rarely the RL algorithm in isolation. The hard part is the robot spending physical time in states that are not catastrophic but also not productive: a gripper touches the object but never lifts it, a RAM module hovers near the slot but keeps scraping the edge, or a towel is dragged into a shape where the policy repeats the same useless motion. In common human-in-the-loop RL pipelines such as HiL-SERL, a human operator uses teleoperation to take over, recover the robot to a useful state, and release control back to the learning policy.
The paper UniIntervene: Agentic Intervention for Efficient Real-World Reinforcement Learning, submitted on June 10, 2026, proposes a way to reduce that human cost. Instead of asking a human to decide every intervention, the system learns an agentic intervention model that detects unproductive exploration and autonomously recovers the rollout toward a high-value state. According to the official project page, UniIntervene reaches 88% average success rate, improves average success by 8.6% over a state-of-the-art HiL-RL baseline, and reduces human interventions by 57% compared with HiL-SERL across five real robot manipulation tasks.
This is not just a safety stop. A safety stop asks, "Is the robot doing something unsafe?" UniIntervene asks a more useful training question: if the current action continues, is the task still making progress? If the estimated value stops improving over a temporal window, the model triggers recovery, retrieves a useful target from memory, and lets a goal-conditioned recovery policy produce a corrective action chunk.
If you are new to RL or VLA policies, start with the foundational reinforcement learning and Vision-Language-Action articles linked in the related section at the end. This guide takes the engineering view: what UniIntervene does, what the current repo contains, how to build a reproducible prototype, how to train and run inference, and how to interpret the results.
Sources, Repo, and Code Status
The main sources are:
| Source | Link | Notes |
|---|---|---|
| arXiv paper | arxiv.org/abs/2606.12372 | Authors, abstract, PDF, submitted June 10, 2026 |
| Project page | denghaoyuan123.github.io/UniIntervene-project | Method figures, video, task suite, result tables |
| GitHub repo | Denghaoyuan123/UniIntervene-project | Currently a static website repo, not training code |
One detail matters for anyone trying to reproduce the system today: the Code button on the project page is still a placeholder with href="#", and the GitHub README describes the repository as a "Static project / paper page." It is not a released training or inference codebase. So "trying UniIntervene" currently means rebuilding the pipeline from the paper or integrating the idea into your existing HiL-RL stack. It does not yet mean cloning an official package and running a single command.
That shapes the installation section below. The commands and structure are a practical prototype layout for ROS 2 or Python-based robot labs. When the authors release full code, the custom modules can be swapped for official implementations.
The Core Idea in One Sentence
UniIntervene turns intervention from manual human correction into value-aware autonomous recovery:
policy action
|
v
future-conditioned value estimator
|
v
temporal value-risk critic
|
+-- value still improving -> execute policy action
|
+-- sustained stagnation -> retrieve high-value goal
|
v
recovery policy action chunk
In a standard HiL-RL loop, the human operator is both the trigger and the controller:
Robot gets stuck -> human notices -> human takes over -> human recovers
UniIntervene tries to internalize the middle part:
Robot stops progressing -> value-risk critic triggers -> memory selects goal -> recovery policy acts
The human stays in the loop, but mainly for residual cases: unsafe situations, failure modes that are not represented in memory, or states far outside the training distribution.
Architecture: Four Main Modules
The project page describes UniIntervene as a Qwen-VL backbone with a Latent Future Head, twin critic, temporal value-risk supervision, Recovery Action Head, and memory buffer. The paper appendix is more specific: the intervention backbone is Qwen3-VL-2B-Instruct with LoRA rank 16; the future target comes from a frozen V-JEPA2 encoder; the proxy value function uses SigLIP-SO400M + Gemma-3-270M; and recovery actions use a FAST tokenizer over action chunks.
1. Proxy Value Function
Before training the intervention model, UniIntervene trains an offline proxy value function. It converts sparse success or failure outcomes into a continuous progress signal. For a successful episode of length T, transition t receives normalized progress:
v_t = t / (T - 1)
Failed episodes remain low value. The objective combines Bellman consistency, progress regression, a monotonicity loss, and a small CQL-style regularizer to reduce value overestimation outside the data distribution:
L_proxy = L_TD + L_progress + 0.05 * L_CQL
This model is crucial because both the trigger and the recovery memory depend on it. If the proxy value is poorly calibrated, UniIntervene may trigger too early, trigger too late, or retrieve the wrong goal.
2. Future-Conditioned Action-Value Estimator
Instead of estimating value directly from the current frame, UniIntervene predicts the latent consequence of the current action:
observation o_t + instruction l + action a_t
|
v
Qwen3-VL shared hidden state h_t
|
v
future head predicts z_hat_{t+1}
|
v
twin value head predicts q_hat_t
The motivation is practical. In contact-rich manipulation, a single frame can look bad while still being necessary. During RAM insertion, for example, the module may be slightly tilted for a few frames while the policy aligns it before pressing down. A future-conditioned value estimate asks, "What latent future does this action lead to?" rather than "Does this frame already look like the goal?"
3. Temporal Value-Risk Critic
A naive trigger such as if value < threshold then intervene is fragile. Folding a towel, wiping a board, or inserting a tube can all pass through temporary low-value states. UniIntervene uses the trend:
Delta V_i = V_i - V_{i-1}
R_t = (1 - V_t) * sum(gamma_r^i * max(0, epsilon - Delta V_{t-i}))
Plain interpretation:
| Term | Meaning |
|---|---|
Delta V |
whether value is increasing step by step |
epsilon |
the minimum expected progress rate |
sliding window K=8 |
avoid reacting to one noisy frame |
(1 - V_t) |
reduce risk near completion |
R_t |
risk of sustained stagnation |
When sigmoid(R_hat_t) >= tau_int, with tau_int = 0.5 in the paper, the system triggers recovery.
4. Memory-Guided Goal-Conditioned Recovery
Once the system knows the rollout is stuck, it still needs to know where to recover. UniIntervene builds a recovery memory from previous rollouts:
M = {
intervention_state -> high_value_future_state
}
Each entry stores a low-progress or intervention state paired with a better future state from the same rollout. At inference time, the model embeds the current context and retrieves the nearest memory key by cosine similarity:
current context: phi(o_t, instruction)
memory key: phi(o_fail_j, instruction_j)
retrieve: argmax cosine similarity
goal: high-value state paired with that key
The recovery policy receives the current observation, retrieved goal, and instruction, then generates an action chunk with horizon H=8. The key point is that the policy does not replay old actions. It learns goal-reaching behavior: memory says where to recover, while the policy learns how to get there.
Installing a Prototype
Because official training code has not been released yet, use a prototype structure with clean interfaces. That will make it easier to replace individual modules later.
uniintervene_lab/
configs/
ur7e_ram_insertion.yaml
data/
demos/
rollouts/
recovery_memory/
src/
robot_env.py
policy_server.py
proxy_value.py
intervention_model.py
recovery_policy.py
train_proxy_value.py
train_intervention.py
train_recovery.py
run_hil_rl.py
Minimal Python environment:
python -m venv .venv
source .venv/bin/activate
pip install torch torchvision transformers accelerate peft
pip install numpy scipy opencv-python h5py tqdm
pip install gymnasium stable-baselines3
pip install faiss-cpu
For a real robot, add your control stack:
pip install rclpy # if your ROS 2 Python environment is already built
pip install pyspacemouse
For a UR7e or similar arm, keep two loops separate:
| Loop | Suggested rate | Role |
|---|---|---|
| Low-level servo | 100-500 Hz | receive velocity or pose commands, enforce safety |
| Policy loop | 5-20 Hz | run policy, intervention model, and recovery policy |
Do not let VLM inference directly drive actuators at high frequency. The model should output an action chunk or target delta; a low-level controller should execute it under velocity, force, and workspace limits.
Data Preparation
You need three types of data:
| Data | Used for | Example |
|---|---|---|
| Successful demonstrations | SFT policy, proxy value progress | 20 demos per task, matching the paper's pi0.5 baseline |
| Failed rollouts | proxy value, trigger labels | stuck rollouts, near misses, wrong grasps |
| Intervention segments | recovery memory, recovery policy | operator takeover from bad state to useful state |
A simple episode schema:
{
"task": "ram_insertion",
"instruction": "Insert the RAM module into the slot",
"success": true,
"steps": [
{
"t": 0,
"wrist_rgb": "frames/wrist_000000.jpg",
"third_rgb": "frames/third_000000.jpg",
"ee_pose": [0, 0, 0, 0, 0, 0, 1],
"action": [0, 0, 0, 0, 0, 0, 0],
"human_intervene": false
}
]
}
Always log human_intervene, because intervention rate is one of the main metrics. If you use a SpaceMouse, log both the raw command and the command after safety filtering.
Training Pipeline
Step 1: Train or Choose a Base Policy
The paper uses pi0.5 (SFT) as the policy baseline with 20 demonstrations per task. In your lab, the base policy could be Diffusion Policy, ACT, OpenVLA/OpenVLA-OFT, or a controller trained from a LeRobot dataset. If you are exploring VLA plus RL, ProcVLM is a related direction: ProcVLM focuses on progress reward, while UniIntervene focuses on when and how to intervene.
Step 2: Train the Proxy Value Function
Pseudo-code:
for batch in loader:
obs_t, obs_tp1, instruction, reward, done, progress = batch
v_t = proxy_value(obs_t, instruction)
v_tp1 = proxy_value(obs_tp1, instruction).detach()
td_target = reward + gamma * (1 - done) * v_tp1
loss_td = smooth_l1(v_t, td_target)
loss_progress = smooth_l1(v_t, progress)
loss_mono = relu(v_t - v_tp1).mean()
loss_cql = conservative_state_value_loss(v_t, negatives)
loss = loss_td + loss_progress + 0.05 * loss_cql + loss_mono
loss.backward()
optimizer.step()
The most important validation is not a small scalar loss. You want the value curve of successful rollouts to rise consistently while failed rollouts stay low. If successful and failed trajectories overlap heavily, temporal value-risk will be unreliable.
Step 3: Mine Trigger Labels
Use the value sequence to mark stagnation:
def mine_trigger_labels(values, k=8, eps=0.005):
labels = [0] * len(values)
for t in range(k, len(values)):
window = values[t-k:t+1]
deltas = [window[i] - window[i-1] for i in range(1, len(window))]
shortfall = sum(max(0.0, eps - d) for d in deltas)
plateau = max(window) - min(window) < 0.03
decline = sum(d < 0 for d in deltas) >= k // 2
if shortfall > 0.04 and (plateau or decline):
labels[t] = 1
return labels
Do not make the trigger too aggressive. If it fires constantly, the recovery policy effectively becomes the main policy and you lose useful RL exploration.
Step 4: Train the Intervention Model
The intervention model learns several heads together:
| Head | Target | Loss |
|---|---|---|
| Future head | V-JEPA2 latent of o_{t+1} |
normalized MSE |
| Value head | proxy value target | Smooth-L1 |
| Risk head | temporal value-risk R_t |
Smooth-L1 |
| Trigger head | mined intervention label | focal loss |
Pseudo-code:
h = qwen_vl(obs_t, instruction, action_t, query_token=True)
z_pred = future_head(h)
q_pred = twin_value_head(z_pred).min()
risk_pred = risk_head(z_pred, value_history)
trigger_logit = trigger_head(z_pred.detach(), q_pred.detach())
loss = (
mse_norm(z_pred, vjepa2(obs_tp1)) +
smooth_l1(q_pred, q_target) +
smooth_l1(risk_pred, risk_target) +
focal_loss(trigger_logit, trigger_label)
)
Step 5: Build the Recovery Memory
Mine segments where value improves clearly:
for episode in episodes:
values = proxy_value_sequence(episode)
for start in range(0, len(values) - span):
end = start + span
if values[end] - values[start] >= delta and values[end] > tau_goal:
memory.add(
key_obs=episode.obs[start],
key_state=episode.state[start],
goal_obs=episode.obs[end],
goal_state=episode.state[end],
instruction=episode.instruction,
)
According to the appendix, the paper keeps roughly 120 recovery targets for Pick Eggplant, Tube Insertion, RAM Insertion, and Wipe Whiteboard, and 240 targets for Fold Towel because the deformable task is longer and noisier.
Step 6: Train the Recovery Policy
The recovery policy is behavior cloning over segments from intervention states to high-value goals:
goal = retrieve_goal(memory, obs_t, instruction)
action_tokens = fast_tokenizer.encode(action_chunk)
logits = recovery_policy(obs_t, goal.obs, instruction)
loss = cross_entropy(logits, action_tokens)
If you do not yet have a FAST action tokenizer, start with a continuous action MLP or a diffusion action head. But if your base policy is a VLA or action-token model, tokenized chunks will fit the modern stack better.
Inference in a HiL-RL Loop
During real rollout, UniIntervene sits between the base policy and robot controller:
while not done:
obs = env.observe()
action = base_policy(obs, instruction)
q, risk, trigger = intervention_model(obs, instruction, action, value_history)
value_history.append(q)
if trigger > 0.5:
goal = memory.retrieve(obs, instruction)
action_chunk = recovery_policy(obs, goal, instruction)
env.execute_chunk(action_chunk)
replay.add_recovery(obs, goal, action_chunk)
else:
env.step(action)
replay.add_policy_step(obs, action)
if human_requests_takeover():
correction = teleop.read()
env.step(correction)
replay.add_human_intervention(obs, correction)
Keep human override above UniIntervene in the control hierarchy. UniIntervene reduces intervention, but it should not replace the safety operator during research.
Paper Results
The benchmark uses a UR7e arm, parallel-jaw gripper, wrist camera, fixed third-person camera, and SpaceMouse. The five tasks are Pick Eggplant, Tube Insertion, RAM Insertion, Wipe Whiteboard, and Fold Towel.
| Method | Pick SR/IR | Tube SR/IR | RAM SR/IR | Wipe SR/IR | Fold SR/IR | Avg SR/IR |
|---|---|---|---|---|---|---|
pi0.5 SFT |
95 / - | 30 / - | 10 / - | 65 / - | 70 / - | 54 / - |
| HiL-SERL | 90 / 28.7 | 60 / 30.2 | 85 / 32.3 | 85 / 30.5 | 85 / 49.8 | 81 / 34.3 |
| HiL-SERL + FA-RL | 85 / 20.4 | 60 / 22.1 | 75 / 27.9 | 80 / 21.9 | 85 / 30.9 | 77 / 24.6 |
| HiL-SERL + UniIntervene | 95 / 10.0 | 70 / 15.8 | 95 / 12.1 | 90 / 10.9 | 90 / 24.1 | 88 / 14.6 |
SR means success rate, higher is better. IR means human intervention rate, lower is better. The important point is that UniIntervene does not merely reduce IR; it also improves SR on every task. Autonomous recovery saves operator time and also returns rollouts to states where the policy can learn, instead of letting it repeat unproductive behavior.
The ablation results are also intuitive. Removing value prediction or temporal value-risk hurts triggering. Removing the memory goal reduces online success even when intervention F1 stays almost unchanged. In other words, "triggering at the right time" and "recovering to the right place" are separate problems.
When Should You Try UniIntervene?
UniIntervene is worth trying if your lab already has:
| Requirement | Why it matters |
|---|---|
| A working base policy | UniIntervene does not replace the main policy |
| Reliable replay logging | it needs successful, failed, and intervention segments |
| Stable teleoperation | needed for initial recovery data and safety fallback |
| Value/progress validation | the trigger depends on proxy value calibration |
| Tasks with clear stagnation | insertion, wiping, folding, regrasping |
It is not a good first step if your robot does not yet have a safety envelope, if you are not logging data cleanly, or if the task is so simple that an SFT policy is already near 100%. For easy tasks, the overhead of a VLM plus recovery memory may not be worth it.
Quick Implementation Checklist
[ ] Choose one contact-rich task, such as insertion or wiping
[ ] Collect 20-50 successful demonstrations
[ ] Run the base policy to collect failed rollouts
[ ] Collect intervention segments with SpaceMouse or teleoperation
[ ] Train proxy value and verify successful curves rise
[ ] Mine stagnation labels with window K=8
[ ] Train intervention model with future/value/risk/trigger heads
[ ] Build recovery memory and audit top-1 retrieval similarity
[ ] Train recovery policy on action chunks
[ ] Run HiL-RL with human override always enabled
[ ] Report SR, IR, interventions per episode, and failure modes
Limitations
The paper is clear about several limitations. First, the trigger depends on the proxy value function. If the value estimate does not reflect task progress, the temporal value-risk critic can fire too early or too late. Second, retrieval-based recovery depends on a memory of past intervention episodes, so it may fail on unseen failure modes. Third, the experiments focus on tabletop manipulation with one robot embodiment; there is not yet enough evidence for mobile manipulation, humanoid whole-body policies, or multi-robot deployment.
So the right mental model is: UniIntervene is an intervention automation layer on top of HiL-RL. It is not a magic recipe that removes humans from real-world robot learning.