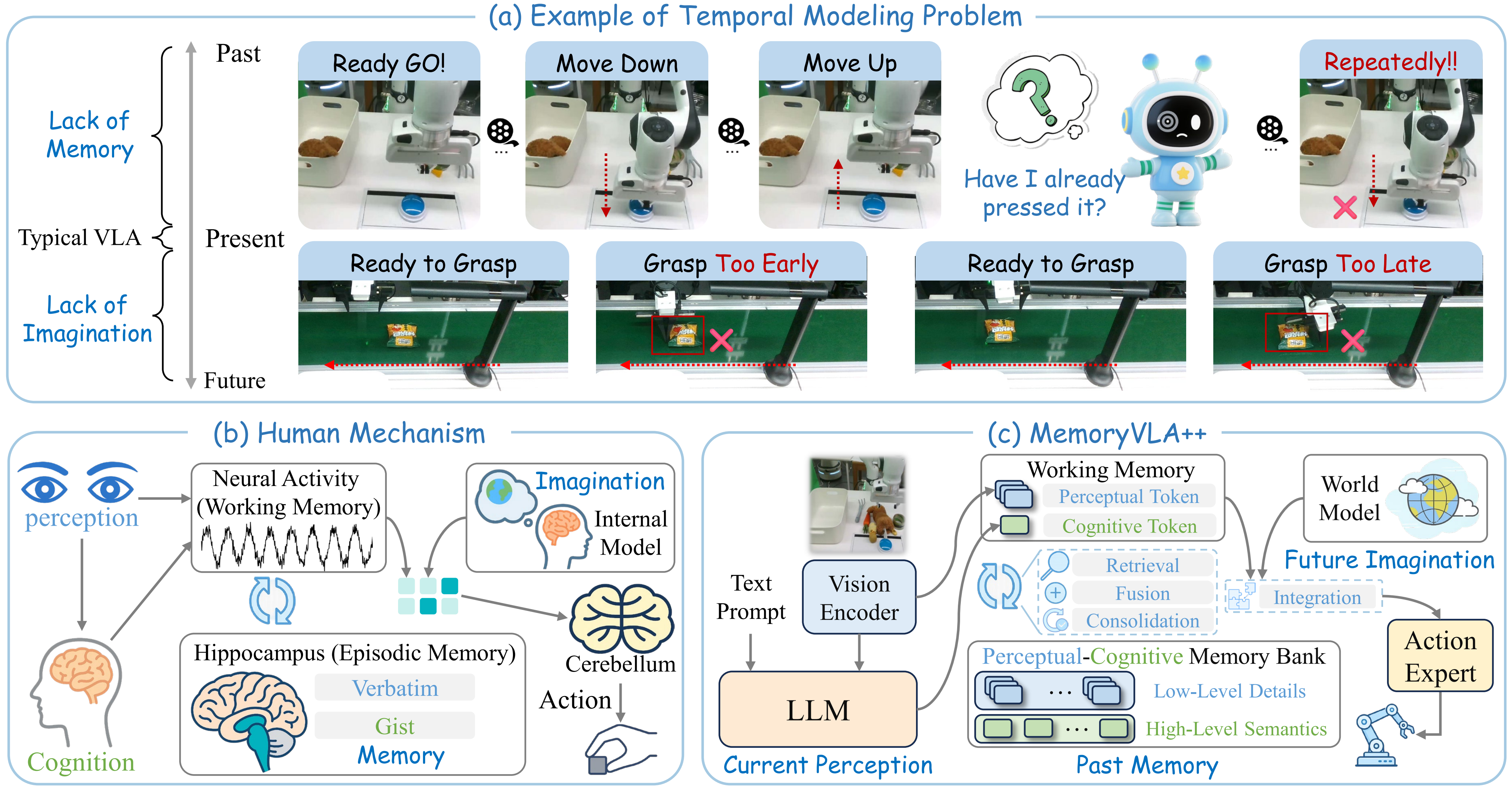
MemoryVLA++ is interesting because it targets a very practical failure mode in current Vision-Language-Action models: the robot can react to the current frame, but it often forgets what happened a few seconds ago and cannot anticipate what the scene will become next. For short pick-and-place tasks, that may be acceptable. For long-horizon manipulation, it is not.
The original paper is MemoryVLA++: Temporal Modeling via Memory and Imagination in Vision-Language-Action Models, arXiv 2606.09827, released on June 8, 2026 by researchers from Tsinghua, HKU, Dexmal, and collaborators. The official project page is https://shihao1895.github.io/MemoryVLA-PP-Web, and the GitHub repository is shihao1895/MemoryVLA. One important implementation note: as of June 17, 2026, the repository has released MemoryVLA and MemoryVLA+, while the MemoryVLA++ code, model weights, and dataset are still marked as future releases. This guide therefore separates the paper architecture from the current hands-on setup. You can prepare the MemoryVLA stack now, then plug in the MemoryVLA++ branch when it is published.
Why reactive VLA is not enough
Most VLA policies take the current RGB observation and a language instruction, then predict an action token, a continuous action, or an action chunk. This works well when the task is short and the current image contains all information needed for the next move. The problem appears when the task is temporally dependent.
The paper uses two intuitive examples. In Button Pressing, the image before and after pressing a button can look almost identical. Without memory, the robot may not know whether the button was already pressed. In Dynamic-Conveyor Grasping, the object is moving. A purely reactive policy may reach the correct position too late because it does not predict where the object will be in the near future.
A simple fix is to concatenate more historical frames. That is expensive because Transformer attention grows quadratically with sequence length, and robot videos contain many redundant frames. Another fix is to generate future RGB frames and feed them back into the policy. That is also expensive, and visually sharp future frames are not necessarily control-relevant. MemoryVLA++ takes a more compact route: compress the past into a memory bank, represent the future in latent space, and condition a diffusion action expert on a representation that covers past, present, and future.
The core idea
MemoryVLA++ is inspired by three cognitive mechanisms:
- Working memory stores the current perceptual and semantic state.
- Episodic memory stores past experiences across the episode.
- Internal models imagine how the future scene may evolve.
In the robot policy, these become:
- A VLM encoder that turns RGB observations and language into perceptual tokens and a cognitive token.
- A Perceptual-Cognitive Memory Bank (PCMB) that stores and retrieves historical perceptual and semantic context.
- A video-generation world model that performs latent-space future imagination through partial denoising.
- A diffusion action expert that predicts continuous 7-DoF action sequences.
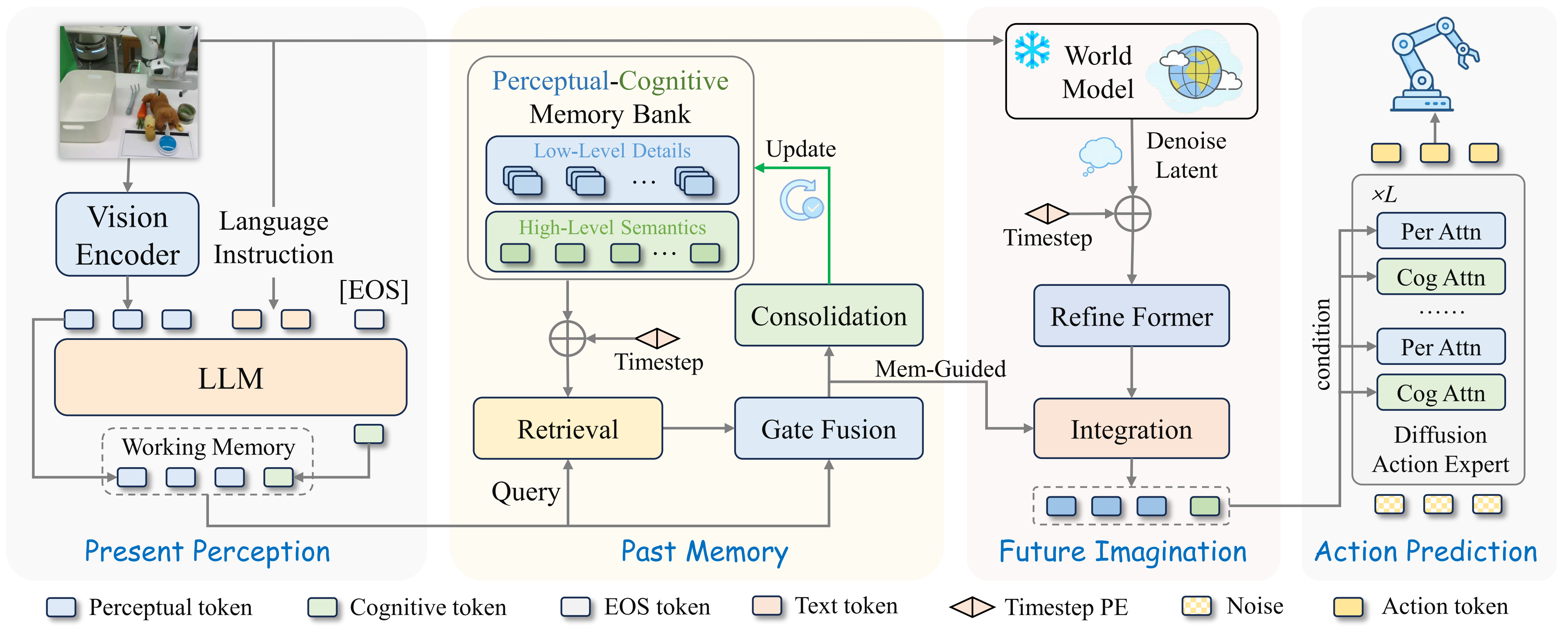
The key design is that memory and imagination are not independent add-ons. The memory-augmented representation guides which imagined future latents should influence the action policy. That matters because a video world model may generate many plausible but irrelevant visual details. The action policy only needs the future cues that change the control decision.
Architecture walkthrough
A beginner-friendly view of the inference pipeline is:
RGB views + language instruction
|
v
VLM encoder: DINOv2 + SigLIP + LLaMA/Prismatic
|
+--> perceptual tokens: local visual and object details
+--> cognitive token: high-level semantic summary
|
v
Working memory queries PCMB
|
+--> retrieve historical perceptual/cognitive context
+--> gate-fuse current and historical tokens
+--> consolidate redundant entries with token merge
|
v
World model latent imagination
|
+--> partial denoising
+--> spatial and temporal attention
+--> memory-guided integration
|
v
Diffusion action expert
|
v
Action chunk: delta XYZ + delta RPY + gripper
Vision-language-cognition module
The paper builds this module on a 7B VLM. RGB observations from one or more camera views are encoded by parallel DINOv2 and SigLIP encoders. DINOv2 helps preserve visual structure and object-level features, while SigLIP helps align images with language. Their raw visual tokens are then processed by two branches.
The perceptual branch uses an SE-bottleneck compression module to produce perceptual tokens. These tokens keep fine-grained visual cues such as object position, contact regions, and small scene changes. The cognitive branch projects visual tokens into the language embedding space, concatenates them with the tokenized instruction, and feeds the sequence into LLaMA-7B. The output at the EOS position becomes the cognitive token, a compact semantic summary of the task state.
In plain terms: perceptual tokens answer "what does the robot see?", while the cognitive token answers "what does this mean for the current instruction?"
PCMB: memory for the past
The PCMB stores two streams:
- Perceptual memory entries for fine visual detail.
- Cognitive memory entries for high-level semantic summaries.
At each timestep, the current working memory queries the PCMB with scaled dot-product attention. The paper adds timestep positional encoding to preserve temporal order. This is important because a long-horizon task is not just a bag of past frames. The order of events often determines the correct next action.
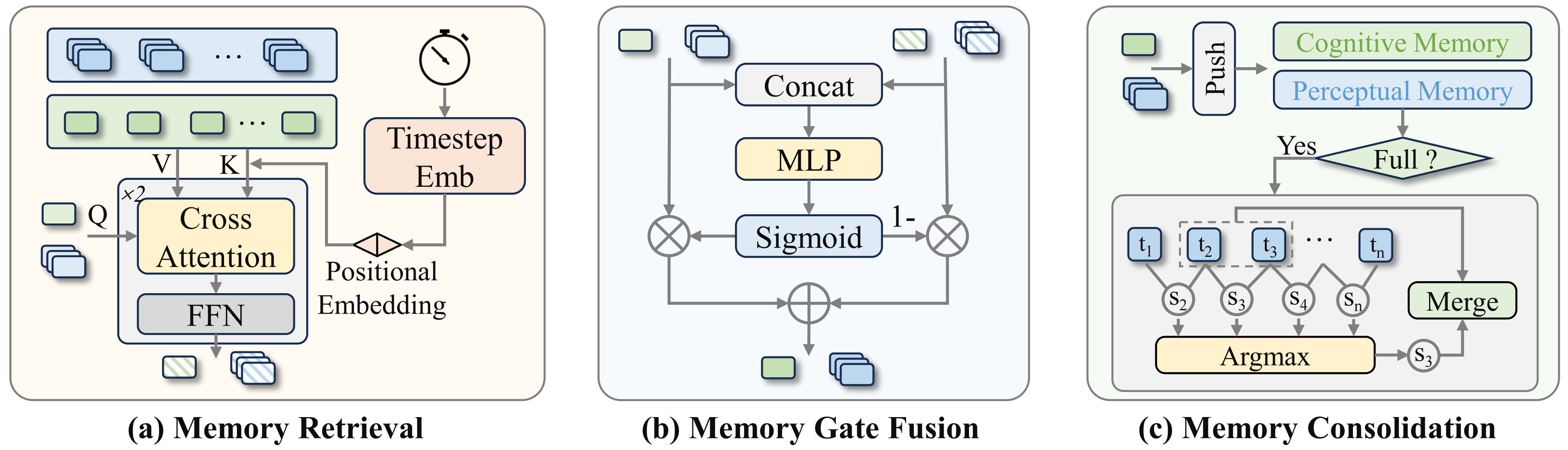
After retrieval, MemoryVLA++ does not simply add historical features to current features. It uses gate fusion. A small MLP with sigmoid activation decides how much of the retrieved memory and how much of the current token should be retained. If the current image is enough, the gate can keep the present. If the task depends on history, the gate can open toward memory.
The bank also has a consolidation mechanism. When PCMB reaches capacity, the model finds the most similar adjacent entries and merges them by averaging. This is better than simple FIFO for robot videos because consecutive manipulation frames are often redundant. Token-merge consolidation keeps the memory compact while preserving longer temporal coverage.
World model: latent imagination instead of pretty pixels
Past memory solves only half of the temporal problem. Some tasks require anticipating the near future. MemoryVLA++ uses Stable Video Diffusion, a 1.5B video diffusion model, as the base world model and adapts it to manipulation videos. The adapted world model is conditioned on the current observation and language instruction, then trained to reconstruct future video sequences.
During policy training and inference, however, the world model is frozen and used only for latent imagination. It does not decode future RGB frames. MemoryVLA++ performs partial denoising, extracts multi-scale intermediate UNet features, aggregates them with an FPN, adds temporal embeddings, and compresses the result with an imagination former using spatial and temporal attention.
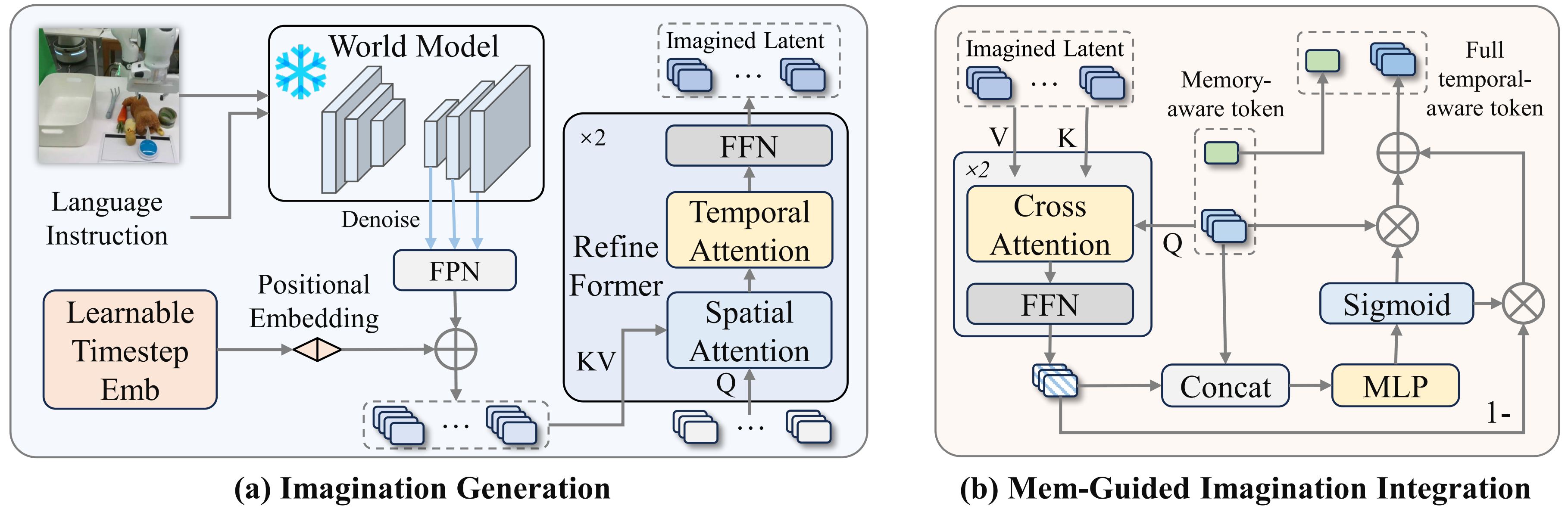
This design is pragmatic. The policy does not need photorealistic future video. It needs control-relevant dynamics: an object is sliding left, a conveyor will bring the object into reach, a drawer will continue opening if the gripper pulls, or a container will occlude the target after the next move.
The imagined tokens are then queried by memory-augmented perceptual tokens through cross-attention. Another gate fuses the imagined representation with the memory-enhanced current representation. This is the "memory-guided" part: future cues are selected under the context of what has already happened.
Diffusion action expert
The action expert is a diffusion Transformer implemented with DDIM. For a single-arm robot, each action has seven dimensions: delta x, delta y, delta z, delta roll, delta pitch, delta yaw, gripper. For dual-arm manipulation, the action vector concatenates both arms.
During denoising, noisy action tokens are concatenated with the cognitive token to provide high-level task guidance. The resulting features then attend to perceptual tokens to inject fine-grained visual detail. The model is trained with MSE loss between predicted and target action sequences, and the final denoised representations are projected through an MLP to generate continuous actions. The paper reports inference with 10 DDIM sampling steps and classifier-free guidance scale 1.5.
Installing the current repository
Because MemoryVLA++ code is not fully released yet, start with the current MemoryVLA repository. This gives you the environment, evaluation scripts, RLDS data path, and deployment style that MemoryVLA++ is expected to extend.
Repository requirements:
- Python 3.10
- PyTorch 2.2.0
- CUDA 12.1
flash-attn==2.5.5for training- A serious GPU setup; the paper trains on 8 NVIDIA A100 or H20 GPUs
Basic setup:
conda create --name memvla python=3.10
conda activate memvla
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu121
conda install -c nvidia cuda-nvcc=12.1 cuda-toolkit=12.1 -y
pip install flash_attn-2.5.5+cu122torch2.2cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
git clone https://github.com/shihao1895/MemoryVLA
cd MemoryVLA
pip install -e .
If you only inspect code or run evaluation from existing checkpoints, Flash Attention may not be needed. If SimplerEnv or ManiSkill fails with Vulkan or OpenGL errors, the repository FAQ recommends Mesa and ffmpeg packages:
sudo apt install -y libegl1-mesa libgl1-mesa-dev libgles2-mesa-dev
sudo apt install -y libgl1 libglib2.0-0 libglx-mesa0 libopengl0 libglu1-mesa mesa-utils
sudo apt install -y ffmpeg
Preparing data
The repository uses RLDS format. For beginners, think of RLDS as an episode-based robot dataset format: each episode stores observations, actions, language instructions, and timestep metadata.
Datasets mentioned by the repository include:
| Dataset | Use case | Note |
|---|---|---|
| LIBERO RLDS | simulation manipulation | processed dataset around 22 GB |
| Bridge RLDS | WidowX and SimplerEnv | processed dataset around 157 GB |
| Fractal RLDS | OXE-style manipulation | used for Fractal benchmarks |
| Custom RLDS | your own robot | place under <data_root_dir>/custom_finetuning/1.0.0 |
The expected action convention is end-effector delta control:
EEF Delta XYZ (3) + Roll-Pitch-Yaw (3) + Gripper Open/Close (1)
For real robots, the paper collects demonstrations via teleoperation and ROS. Franka and WidowX use fixed three-view RGB cameras with Intel RealSense D435. Dual-ARX5 uses fixed RGB cameras plus a wrist-mounted RGB camera. RGB is captured at 640x480 and 30 fps, then downsampled to 224x224. Frames are temporally subsampled by keeping a frame when end-effector translation exceeds 0.01 m or orientation change exceeds 0.4 rad. The processed episodes are converted to RLDS.
Training: world model first, policy second
Conceptually, MemoryVLA++ training has two stages.
Stage 1: adapt the world model
The world model starts from Stable Video Diffusion, which was trained on broad Internet video. For robot control, it is adapted on manipulation videos so it learns robot-centric dynamics. A training sample contains current observation, instruction, and a future video sequence. The diffusion objective trains the model to reconstruct the clean future sequence from a noisy version conditioned on the current image and language.
During VLA policy training, the paper freezes the world model. This is not just an implementation detail. The ablation study shows that freezing performs better than updating the world model inside policy training, likely because the pretrained dynamics prior is useful and should not be distorted by downstream imitation loss.
Stage 2: train the VLA policy
The VLA policy is trained with the VLM, PCMB, imagination integration module, and diffusion action expert. The paper reports PyTorch FSDP training on 8 A100 or H20 GPUs, 26-32 samples per GPU, global batch size 208-256, and learning rate 2e-5. The LLM backbone has 7B parameters, while the diffusion action expert has about 300M parameters.
Current repository training commands look like this:
# Bridge
bash script/train/bridge/train_bridge.sh
# LIBERO
bash script/train/libero/train_libero_spatial.sh
bash script/train/libero/train_libero_object.sh
bash script/train/libero/train_libero_goal.sh
bash script/train/libero/train_libero_100.sh
# Fractal or real-world data
bash script/train/fractal/train_fractal.sh
bash script/train/real_world/train_real.sh
Before launching training, edit hf_token, wandb_entity, checkpoint paths, dataset paths, and log directories. For your own robot data, convert episodes to RLDS, place them under custom_finetuning/1.0.0, and set vla.data_mix="custom_finetuning".
Inference and deployment
Deployment is stateful. A MemoryVLA++ server must preserve episode memory across frames. The basic loop is:
- Episode start: reset PCMB and set
episode_first_frame=True. - Each control tick: send RGB observation and instruction, update PCMB, run latent imagination, and sample an action chunk.
- Execution: execute the action chunk or the first action, then repeat with the next observation.
The current MemoryVLA deployment follows an OpenVLA/CogACT-style server-client design. The model runs on a server, and the robot sends requests as a client:
image = request.files["image"]
query = request.form["text"]
episode_first_frame = request.form["episode_first_frame"]
Server command:
bash script/eval/real_world/deploy.sh
When the MemoryVLA++ branch is released, pay special attention to memory reset. If every HTTP request is treated as an independent single-frame inference call, the system loses the main advantage of MemoryVLA++.
Reported results
The paper evaluates five simulation benchmarks and three real-robot task categories, covering nearly 200 task variations. Robots include Franka, WidowX, and Dual-ARX5.
| Evaluation group | Key result |
|---|---|
| LIBERO | 98.4% average success, 5.2 points above CogACT baseline |
| SimplerEnv | about 74.0% / 73.9% average success, 16.6-16.7 points above CogACT |
| Mikasa-Robo | 44.4% success, 15.0 points above the best previous single-frame VLA |
| Calvin | 4.29 average completed task length, 1.04 above CogACT |
| Libero-Plus | 82.7% average in the SFT robustness/generalization setting |
| Real general tasks | 85%, 9 points above CogACT |
| Real memory-dependent tasks | 83%, 26 points above CogACT |
| Real imagination-dependent tasks | 77%, 28 points above CogACT |
The ablations are also useful for practitioners:
- Memory length has a sweet spot; too short loses context, too long adds redundancy.
- Gate fusion beats direct addition.
- Token-merge consolidation beats FIFO.
- Using both perceptual and cognitive memory works better than either stream alone.
- One denoising step for imagination is already competitive; more steps increase cost with little gain.
- Longer imagination horizon improves long-horizon decisions.
- Memory-guided imagination integration beats direct addition of imagined tokens.
When should you use this design?
MemoryVLA++ is worth considering if your task has any of these properties:
- The same image can correspond to different task states.
- The robot must remember which object or step was already completed.
- The task has an order: press A then B, place items by sequence, clean a table by count.
- Objects move while the robot is acting.
- A short-horizon policy works for each subtask but fails when subtasks are chained.
If your task is a static, short pick-and-place problem, a standard diffusion policy or current VLA may be enough. Memory and world modeling add compute, state management, and training complexity. Use them when temporal dependency is the real bottleneck.
A practical lab checklist
For a small robotics lab, start with two controlled tasks:
- One memory-dependent task, such as pressing buttons in an order shown at the beginning.
- One imagination-dependent task, such as picking an object from a slow conveyor.
- Collect teleoperation data with fixed cameras, consistent language, and 7-DoF delta actions.
- Convert the data to RLDS.
- Fine-tune a MemoryVLA or CogACT baseline first.
- When MemoryVLA++ code is released, add PCMB and world-model imagination.
- Evaluate by episode success rate, not only validation loss.
Primary sources to read next: arXiv 2606.09827, the MemoryVLA++ project page, the shihao1895/MemoryVLA GitHub repository, and the authors' Hugging Face model/log collection.


