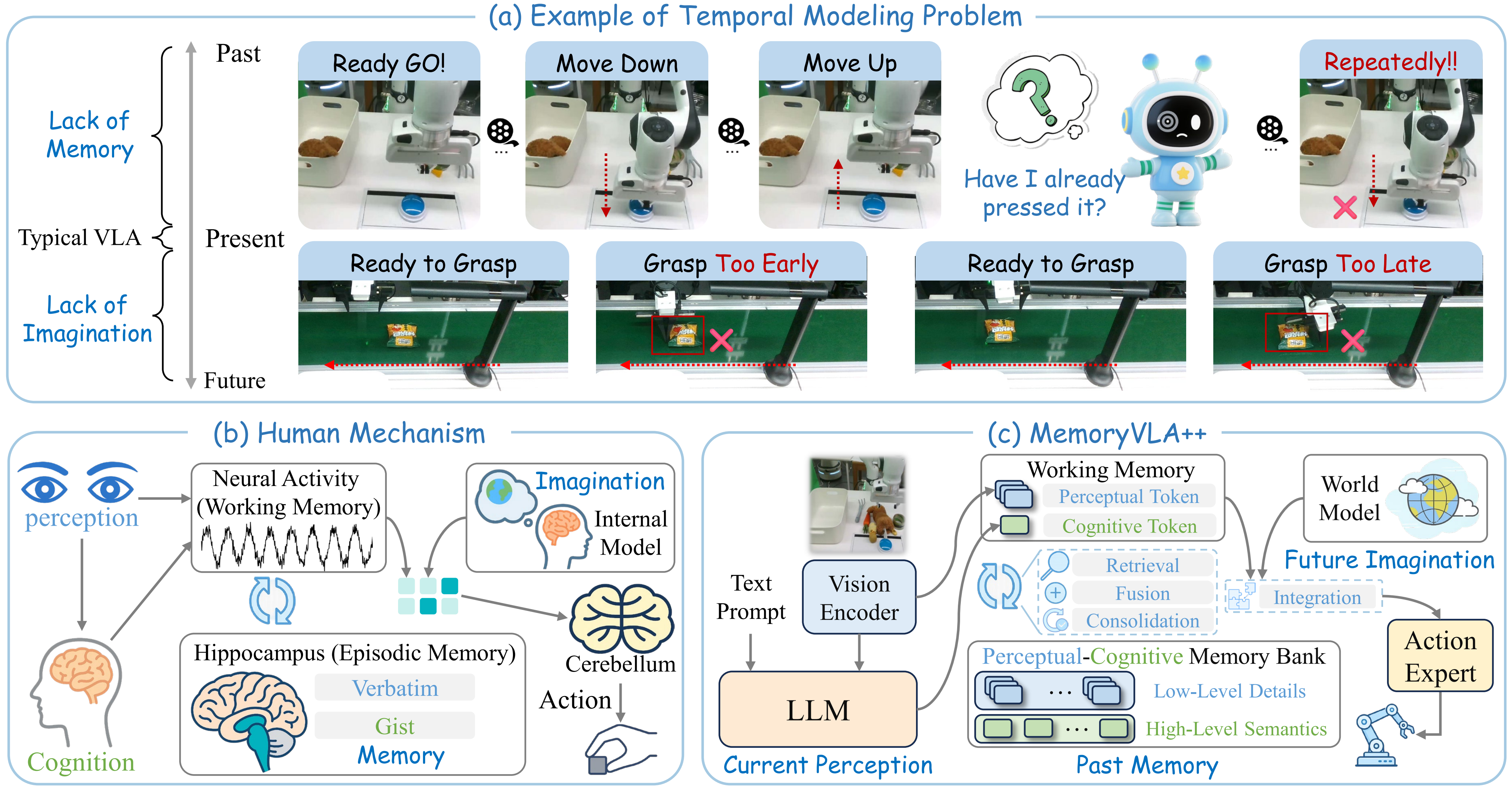
MemoryVLA++ là một paper đáng chú ý vì nó chạm đúng điểm yếu của nhiều VLA hiện nay: robot nhìn frame hiện tại rất giỏi, nhưng lại dễ quên việc vừa làm xong và khó đoán trạng thái tiếp theo của môi trường. Với manipulation dài hạn, đó là lỗi chết người. Nếu robot phải bấm nút theo thứ tự, tìm vật đã bị che, dọn bàn theo số lượng, hoặc gắp vật trên băng chuyền, chỉ nhìn ảnh hiện tại là chưa đủ. Robot cần nhớ quá khứ và "tưởng tượng" tương lai gần.
Paper gốc có tên MemoryVLA++: Temporal Modeling via Memory and Imagination in Vision-Language-Action Models, arXiv 2606.09827, công bố ngày 8/6/2026 bởi nhóm Tsinghua, HKU, Dexmal và cộng sự. Project page chính thức ở https://shihao1895.github.io/MemoryVLA-PP-Web, còn GitHub repo hiện nằm tại shihao1895/MemoryVLA. Một chi tiết quan trọng: tại thời điểm viết bài 17/6/2026, repo đã release MemoryVLA và MemoryVLA+, nhưng phần MemoryVLA++ vẫn được ghi là sẽ release trong các tháng tới. Vì vậy bài này tách rõ hai lớp: phần paper mô tả kiến trúc MemoryVLA++, còn phần cài đặt thực hành dùng repo MemoryVLA hiện có làm nền để bạn chuẩn bị pipeline.
Vấn đề: VLA phản xạ chưa đủ cho manipulation dài hạn
Một VLA kiểu OpenVLA, CogACT hoặc π0 thường nhận ảnh RGB hiện tại, instruction ngôn ngữ, rồi predict action hoặc action chunk. Cách này mạnh ở tác vụ ngắn: pick, place, open drawer, close drawer. Nhưng khi tác vụ phụ thuộc thời gian, observation hiện tại có thể đánh lừa policy.
Ví dụ paper đưa ra là Button Pressing. Trước và sau khi robot bấm nút, ảnh có thể gần như giống nhau. Nếu robot không nhớ rằng nó vừa bấm rồi, policy có thể bấm lại hoặc dừng sai thời điểm. Ví dụ khác là Dynamic-Conveyor Grasping. Vật đang di chuyển trên băng chuyền; nếu robot chỉ phản ứng với ảnh hiện tại, nó sẽ gắp trễ. Nó cần dự đoán vị trí tương lai gần để chọn thời điểm tiếp cận.
Một cách đơn giản là nhét thêm nhiều frame quá khứ vào context. Nhưng attention cost tăng theo bình phương, nhiều frame liên tiếp lại dư thừa vì robot di chuyển chậm. Với tương lai, có thể sinh video frame rồi feed lại vào VLA, nhưng dự đoán pixel đẹp không đồng nghĩa với dynamics hữu ích cho control. MemoryVLA++ chọn hướng khác: quá khứ được nén vào memory bank, tương lai được biểu diễn bằng latent imagination, rồi action expert nhận representation đã có đủ past-present-future.
Ý tưởng chính của MemoryVLA++
MemoryVLA++ mô phỏng ba cơ chế nhận thức:
- Working memory: buffer ngắn hạn chứa perception và cognition của frame hiện tại.
- Episodic memory: bộ nhớ dài hơn, lưu chi tiết cảm nhận và ý nghĩa semantic của các bước trước.
- Internal model / world model: mô hình tưởng tượng diễn biến tương lai gần.
Trong robot policy, ba phần này được map thành:
- VLM encoder tạo perceptual tokens và cognitive token từ ảnh RGB và instruction.
- Perceptual-Cognitive Memory Bank (PCMB) lưu các token lịch sử, truy xuất bằng attention và hợp nhất bằng gate.
- Video-generation world model dựa trên Stable Video Diffusion được adapt cho manipulation, nhưng chỉ dùng latent feature sau partial denoising thay vì decode video RGB hoàn chỉnh.
- Diffusion action expert nhận full temporal-aware tokens và sinh chuỗi action 7-DoF liên tục.
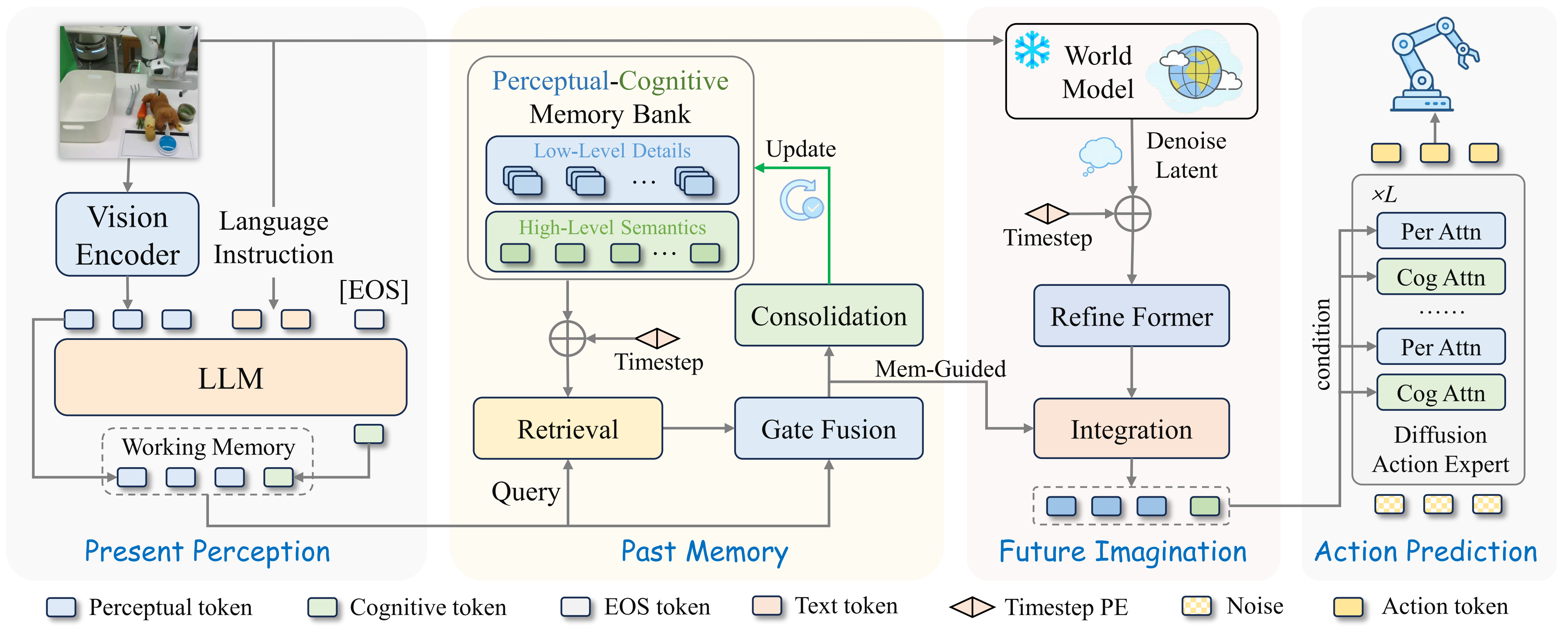
Điểm hay là MemoryVLA++ không coi memory và world model là hai module rời rạc. Memory hướng dẫn imagination integration: imagined latents chỉ được dùng khi chúng liên quan đến trạng thái và lịch sử hiện tại. Điều này giúp giảm nhiễu từ world model, vì video diffusion model có thể tưởng tượng nhiều chi tiết đẹp nhưng không cần thiết cho action.
Kiến trúc từng bước
Pipeline inference có thể hiểu như sau:
RGB views + language instruction
|
v
VLM encoder: DINOv2 + SigLIP + LLaMA/Prismatic
|
+--> perceptual tokens: chi tiết hình ảnh, vị trí, object cue
+--> cognitive token: ý nghĩa instruction và trạng thái semantic
|
v
Working memory query PCMB
|
+--> retrieve historical perceptual/cognitive context
+--> gate fusion để trộn hiện tại với lịch sử
+--> token-merge consolidation để memory không phình to
|
v
World model imagination
|
+--> partial denoising trong latent space
+--> spatial attention + temporal attention
+--> memory-guided integration
|
v
Diffusion action expert
|
v
Action chunk: delta XYZ + delta RPY + gripper
Vision-language-cognition module
Paper xây module này trên VLM 7B. Ảnh RGB từ một hoặc nhiều camera được encode bằng DINOv2 và SigLIP song song. DINOv2 thường giữ tốt cấu trúc visual và object-level feature; SigLIP giúp alignment vision-language. Hai luồng feature được nối lại.
Sau đó có hai nhánh:
- Perceptual branch nén raw visual tokens bằng SE-bottleneck để tạo perceptual tokens. Đây là phần giữ chi tiết thấp: vị trí object, cạnh, vùng tiếp xúc, thay đổi nhỏ trong scene.
- Cognitive branch project visual tokens sang language embedding, nối với instruction token, rồi đưa qua LLaMA-7B. Output tại EOS được dùng làm cognitive token. Đây là semantic summary: robot đang làm nhiệm vụ gì, object nào quan trọng, subgoal hiện tại là gì.
Perceptual tokens và cognitive token hợp lại thành working memory. Với beginner, hãy nhớ đơn giản: perceptual = "robot nhìn thấy gì"; cognitive = "robot hiểu việc cần làm là gì".
PCMB: memory bank cho quá khứ
PCMB lưu hai stream song song:
- Perceptual memory: các token chi tiết của những frame trước.
- Cognitive memory: semantic summary của những frame trước.
Ở mỗi timestep, working memory hiện tại query PCMB bằng scaled dot-product attention. Paper thêm timestep positional encoding để model biết entry nào xảy ra trước, entry nào xảy ra sau. Nếu không có temporal order, memory bank chỉ là một túi feature hỗn độn; với long-horizon task, thứ tự thường quan trọng hơn bản thân object.
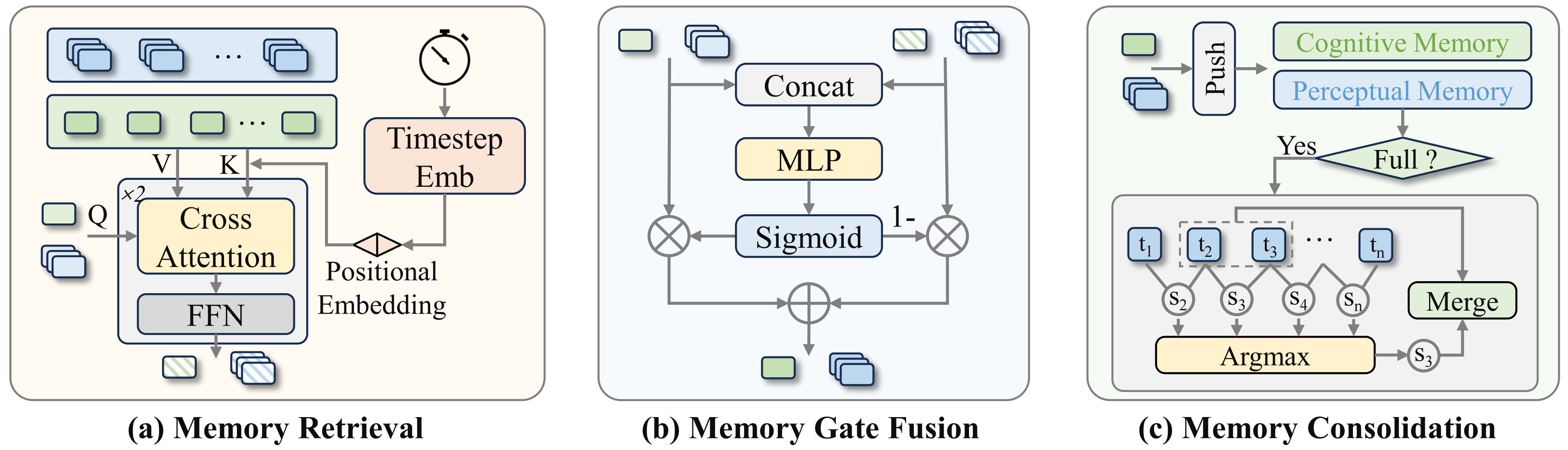
Sau retrieval, MemoryVLA++ dùng gate fusion thay vì cộng thẳng memory vào current token. Gate là một MLP + sigmoid nhận current token và retrieved token, rồi quyết định tỷ lệ trộn. Ý nghĩa thực tế: nếu frame hiện tại đủ thông tin, gate có thể giữ current feature; nếu task cần lịch sử, gate mở hơn cho retrieved memory.
Phần consolidation cũng quan trọng. Khi PCMB đạt capacity, model không FIFO đơn giản. Nó tìm cặp entry liền kề có cosine similarity cao nhất và merge chúng bằng trung bình. Đây là redundancy-aware consolidation. Robot manipulation thường có nhiều frame gần như giống nhau; merge các frame dư thừa giúp memory dài hơn mà không tăng quá nhiều compute.
World model: tưởng tượng tương lai bằng latent, không cần pixel đẹp
Memory giúp nhớ quá khứ, nhưng một số task cần dự đoán tương lai. MemoryVLA++ dùng Stable Video Diffusion 1.5B làm world model nền, rồi adapt trên manipulation videos để học prior robot-centric. World model nhận current observation và instruction, sau đó học reconstruct future video sequence với diffusion loss.
Điểm thực dụng nằm ở inference: world model được freeze và chỉ dùng để sinh latent imagination. Nó không decode video RGB. Thay vào đó, MemoryVLA++ chạy partial denoising, lấy multi-scale UNet features, dùng FPN gom feature, thêm temporal embedding, rồi dùng imagination former với spatial attention và temporal attention để nén thành imagined latent tokens.
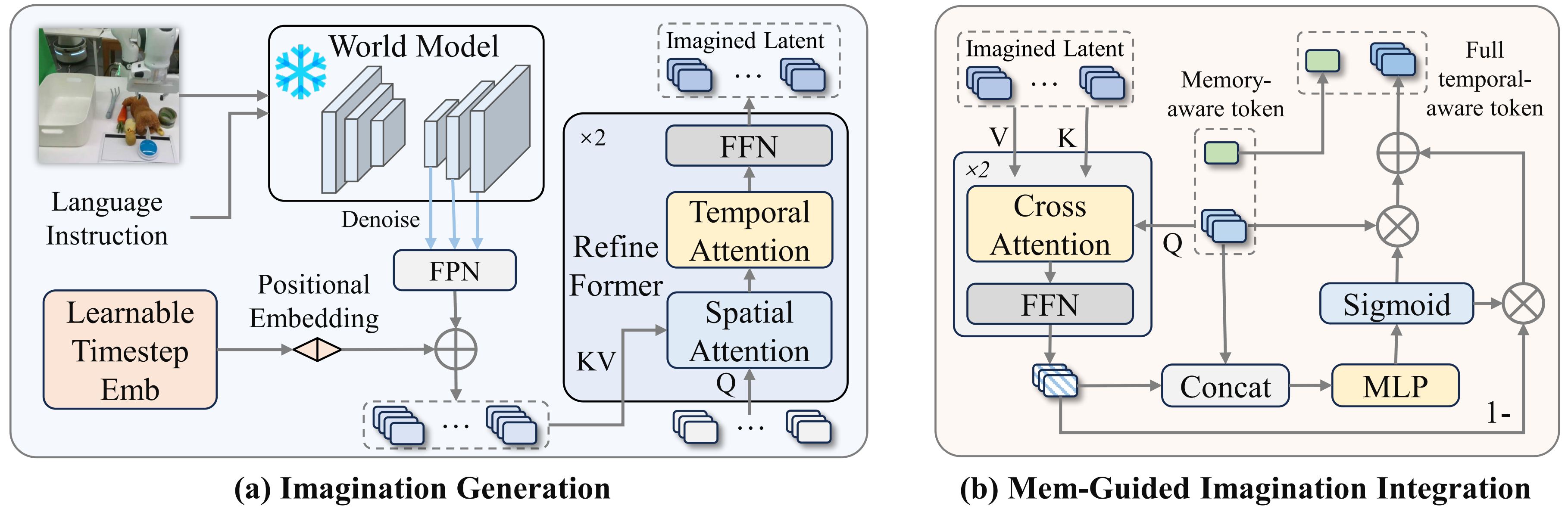
Tại sao không decode video? Vì action policy không cần ảnh tương lai đẹp. Nó cần tín hiệu kiểu: object đang trượt sang trái, băng chuyền đang đưa vật đến vùng reachable, drawer sẽ mở thêm một chút nếu kéo tiếp. Latent feature thường đủ và rẻ hơn.
Sau khi có imagined tokens, MemoryVLA++ để memory-augmented perceptual tokens query imagined tokens bằng cross-attention. Kết quả lại đi qua gate fusion. Đây là chỗ "memory-guided" phát huy tác dụng: nếu imagination không liên quan đến lịch sử task, gate có thể giảm ảnh hưởng của nó.
Diffusion action expert
Action expert là diffusion Transformer theo kiểu DDIM. Đầu vào là full temporal-aware tokens gồm perceptual token đã trộn memory + imagination và cognitive token đã trộn memory. Action output cho single-arm là 7 chiều: delta x, delta y, delta z, delta roll, delta pitch, delta yaw, gripper. Với dual-arm, action vector là nối action của hai tay.
Trong diffusion denoising, noisy action sequence được nối với cognitive token để có high-level guidance, sau đó attention sang perceptual token để lấy chi tiết visual. Model train bằng MSE giữa predicted action sequence và target action sequence, rồi inference bằng DDIM sampling. Paper dùng 10 DDIM steps và classifier-free guidance scale 1.5.
Cài đặt môi trường thực hành
Vì MemoryVLA++ code chưa release đầy đủ, cách thực tế là chuẩn bị repo MemoryVLA hiện có. Khi branch MemoryVLA++ được release, bạn chỉ cần cập nhật branch và thêm world-model artifacts.
Yêu cầu từ repo:
- Python 3.10
- PyTorch 2.2.0
- CUDA 12.1
flash-attn==2.5.5nếu train- GPU mạnh; paper train trên 8 NVIDIA A100 hoặc H20
Lệnh setup nền:
conda create --name memvla python=3.10
conda activate memvla
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu121
conda install -c nvidia cuda-nvcc=12.1 cuda-toolkit=12.1 -y
pip install flash_attn-2.5.5+cu122torch2.2cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
git clone https://github.com/shihao1895/MemoryVLA
cd MemoryVLA
pip install -e .
Nếu bạn chỉ muốn đọc code và chạy evaluation bằng checkpoint có sẵn, có thể bỏ qua Flash Attention. Nếu chạy SimplerEnv hoặc ManiSkill mà lỗi Vulkan/OpenGL, repo gợi ý cài các gói Mesa:
sudo apt install -y libegl1-mesa libgl1-mesa-dev libgles2-mesa-dev
sudo apt install -y libgl1 libglib2.0-0 libglx-mesa0 libopengl0 libglu1-mesa mesa-utils
sudo apt install -y ffmpeg
Chuẩn bị dataset
Repo MemoryVLA dùng RLDS format. Với beginner, RLDS có thể hiểu là format episode-based cho robot data: mỗi episode gồm observation, action, language instruction và metadata theo timestep.
Dataset được repo nhắc đến:
| Dataset | Dùng cho | Ghi chú |
|---|---|---|
| LIBERO RLDS | simulation manipulation | khoảng 22 GB bản processed |
| Bridge RLDS | WidowX / SimplerEnv | khoảng 157 GB bản processed |
| Fractal RLDS | OXE-style manipulation | dùng cho benchmark Fractal |
| Custom RLDS | robot riêng | đặt dưới <data_root_dir>/custom_finetuning/1.0.0 |
Action nên là delta end-effector:
EEF Delta XYZ (3) + Roll-Pitch-Yaw (3) + Gripper Open/Close (1)
Với robot thật, paper mô tả quy trình thu teleoperation qua ROS, camera RGB 640x480 ở 30 fps, sau đó downsample ảnh về 224x224. Frame được giữ lại khi end-effector dịch hơn 0.01 m hoặc đổi orientation hơn 0.4 rad. Quy tắc này giúp loại frame quá dư thừa, đồng thời vẫn giữ các điểm chuyển động quan trọng.
Training: train policy và adapt world model
Training MemoryVLA++ có hai pha khái niệm:
Pha 1: adapt world model cho manipulation
World model xuất phát từ Stable Video Diffusion, vốn học trên video Internet. Muốn dùng cho robot, nó cần adapt trên video manipulation. Sample training gồm current observation, instruction và future video sequence. Diffusion model được train reconstruct clean future sequence từ noisy latent/video. Sau pha này, world model giữ được prior động học hữu ích hơn: vật trượt, tay máy tiến gần object, drawer mở, object rơi vào container.
Trong policy training, paper freeze world model. Đây là lựa chọn đáng chú ý. Ablation cho thấy update world model trong policy training kém hơn freeze, có thể vì policy gradient hoặc imitation loss làm hỏng visual dynamics prior đã học.
Pha 2: train VLA policy
Policy train end-to-end với VLM, PCMB, imagination integration và diffusion action expert. Paper dùng PyTorch FSDP trên 8 GPU A100/H20, batch 26-32 sample/GPU, global batch 208-256, learning rate 2e-5. Action expert khoảng 300M parameters, còn LLM backbone 7B.
Với repo hiện tại, training command có dạng:
# Bridge
bash script/train/bridge/train_bridge.sh
# LIBERO
bash script/train/libero/train_libero_spatial.sh
bash script/train/libero/train_libero_object.sh
bash script/train/libero/train_libero_goal.sh
bash script/train/libero/train_libero_100.sh
# Fractal hoặc real-world
bash script/train/fractal/train_fractal.sh
bash script/train/real_world/train_real.sh
Trước khi chạy, bạn phải sửa hf_token, wandb_entity, checkpoint path, dataset path và log directory trong script tương ứng. Nếu fine-tune robot riêng, convert data sang RLDS, đặt dataset dưới custom_finetuning/1.0.0, rồi set vla.data_mix="custom_finetuning".
Inference và deploy robot thật
Inference thực tế có ba trạng thái cần quản lý:
- Episode start: reset PCMB, reset hidden state nếu có, set
episode_first_frame=True. - Each control tick: gửi ảnh RGB + instruction, update PCMB, chạy world model latent imagination, sample action chunk.
- Action execution: execute action chunk hoặc action đầu tiên tùy control loop, rồi lặp lại với frame mới.
Repo MemoryVLA triển khai deploy theo server-client giống OpenVLA/CogACT. Server chạy model, robot đóng vai client. Mỗi request gửi:
image = request.files["image"]
query = request.form["text"]
episode_first_frame = request.form["episode_first_frame"]
Lệnh server trong repo:
bash script/eval/real_world/deploy.sh
Khi MemoryVLA++ code release, phần khác biệt lớn nhất sẽ nằm ở stateful PCMB và world-model latent path. Bạn cần bảo đảm server không treat mỗi frame như request độc lập. Nếu mỗi HTTP request reset memory, MemoryVLA++ sẽ mất lợi thế chính.
Kết quả paper
Paper evaluate trên 5 simulation benchmarks và 3 nhóm real-robot task, tổng cộng gần 200 task variation. Các robot gồm Franka, WidowX và Dual-ARX5.
| Nhóm đánh giá | Kết quả chính |
|---|---|
| LIBERO | MemoryVLA++ đạt 98.4% average success, cao hơn CogACT baseline 5.2 điểm |
| SimplerEnv | đạt khoảng 74.0% / 73.9% average, hơn CogACT khoảng 16.6-16.7 điểm |
| Mikasa-Robo | đạt 44.4%, hơn single-frame VLA tốt nhất 15.0 điểm |
| Calvin | average completed task length 4.29, hơn CogACT 1.04 |
| Libero-Plus | SFT setting đạt 82.7% average trong robustness/generalization |
| Real general tasks | 85%, hơn CogACT 9 điểm |
| Real memory-dependent tasks | 83%, hơn CogACT 26 điểm |
| Real imagination-dependent tasks | 77%, hơn CogACT 28 điểm |
Ablation cũng đáng chú ý:
- Memory length quá ngắn thiếu context, quá dài tăng redundancy; default tốt nhất.
- Gate fusion tốt hơn cộng trực tiếp.
- Token merge tốt hơn FIFO cho consolidation.
- Kết hợp perceptual memory và cognitive memory tốt hơn chỉ dùng một loại.
- Với imagination, chỉ một denoising step đã cạnh tranh tốt; thêm step tăng cost nhưng ít cải thiện.
- Imagination horizon dài hơn có ích cho long-horizon decision.
- Memory-guided integration tốt hơn direct addition.
Khi nào nên dùng hướng MemoryVLA++?
MemoryVLA++ phù hợp nếu task của bạn có ít nhất một trong các dấu hiệu sau:
- Cùng một observation có thể đại diện cho nhiều trạng thái task khác nhau.
- Robot phải nhớ object nào đã được xử lý.
- Task có thứ tự: bấm nút A rồi B, đặt vật theo order, dọn nhiều món.
- Object di chuyển hoặc môi trường thay đổi trong lúc robot hành động.
- Bạn thấy policy ngắn hạn thành công ở subtask đơn lẻ nhưng fail khi nối thành episode dài.
Ngược lại, nếu task chỉ là pick-and-place tĩnh, horizon ngắn, scene không thay đổi, một diffusion policy hoặc VLA hiện tại có thể đủ. Memory và world model thêm compute, state management và training complexity.
Checklist triển khai cho lab
Nếu muốn thử hướng này trong lab Việt Nam, bắt đầu nhỏ:
- Chọn 1 task memory-dependent: ví dụ "bấm đúng nút theo màu đã thấy lúc đầu".
- Chọn 1 task imagination-dependent: ví dụ "gắp vật trên băng chuyền chậm".
- Thu data teleoperation với camera cố định, instruction nhất quán, action delta 7-DoF.
- Convert sang RLDS.
- Fine-tune MemoryVLA hoặc CogACT baseline trước.
- Khi MemoryVLA++ release, thêm PCMB và world-model imagination.
- Đánh giá bằng success rate theo episode, không chỉ loss validation.
Nguồn chính để tự đọc sâu hơn: arXiv 2606.09827, project page MemoryVLA++, GitHub shihao1895/MemoryVLA, và model/log collection trên Hugging Face của tác giả.


