Embodied-R1.5-VLA là một trong những release đáng chú ý nhất của hướng Embodied Foundation Model trong năm 2026: thay vì train một Vision-Language-Action model từ đầu bằng hàng triệu trajectory robot, nhóm tác giả bắt đầu từ một VLM đã học năng lực embodied reasoning, rồi gắn thêm action head để fine-tune thành policy thao tác robot. Điểm quan trọng là checkpoint Embodied-R1.5-VLA-LIBERO đã được mở trên Hugging Face, code gốc nằm trong repo Embodied-R1.5, còn phần VLA training và inference dùng framework StarVLA.
Bài này hướng dẫn theo góc nhìn thực hành: hiểu paper đang làm gì, cài môi trường, chạy đánh giá LIBERO bằng checkpoint có sẵn, sau đó fine-tune lại VLA trên các suite LIBERO. Nếu bạn mới nghe về VLA, nên đọc trước bài VLA Models trong robotics. Nếu đã quen StarVLA, bài hướng dẫn StarVLA mô-đun sẽ giúp bạn nắm nhanh cách framework tách backbone, dataloader, trainer và action head.
Nguồn gốc của Embodied-R1.5
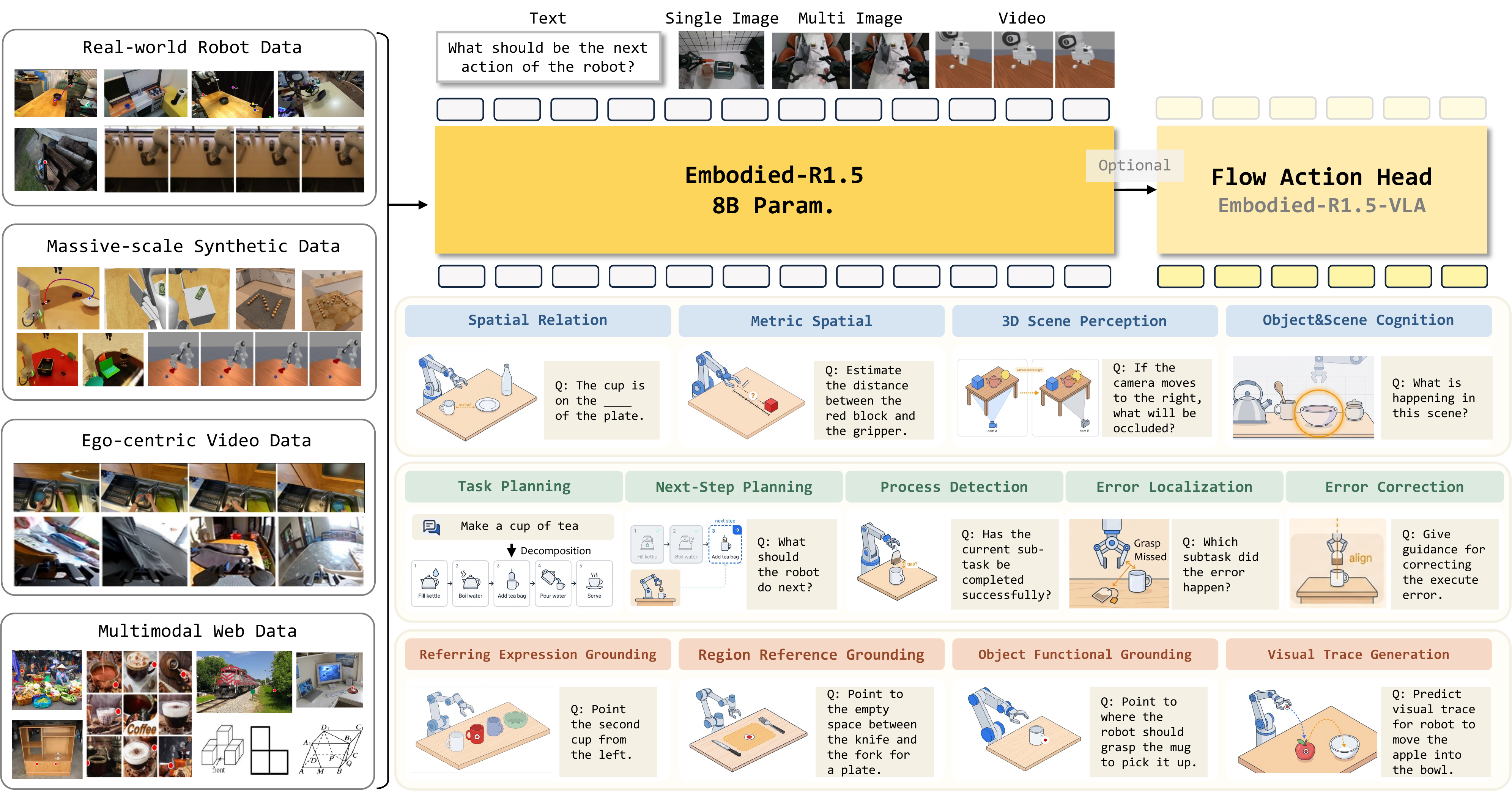
Paper Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models được công bố trên arXiv ngày 9/6/2026. Project page chính thức mô tả Embodied-R1.5 là một mô hình 8B tham số, xây trên Qwen3-VL-8B-Instruct, được huấn luyện để thống nhất nhiều năng lực embodied reasoning: cognition, spatial reasoning, task planning, correction, pointing và localization. Repo chính thức ở https://github.com/pickxiguapi/Embodied-R1.5; checkpoint model và dataset nằm trong collection Hugging Face IffYuan/embodied-r15.
Điểm mới so với Embodied-R1 trước đó là phạm vi năng lực rộng hơn. Embodied-R1 tập trung vào "pointing" như một biểu diễn trung gian không phụ thuộc embodiment: robot không cần trực tiếp đoán joint command, mà đoán điểm cần grasp, vùng cần place hoặc visual trace. Embodied-R1.5 mở rộng hướng này thành một Embodied Foundation Model có thể lập kế hoạch, ground kế hoạch xuống tọa độ, tự sửa lỗi, rồi khi cần thì được fine-tune thành VLA trực tiếp sinh action liên tục.
Sơ đồ ý tưởng có thể tóm tắt như sau:
Image + language instruction
|
v
Qwen3-VL-based Embodied-R1.5 backbone
|
+--> cognition / spatial reasoning
+--> task planning
+--> pointing / visual trace / affordance grounding
+--> correction
|
v
VLA adaptation with action head
|
v
Continuous robot action chunk
Trong paper, nhóm tác giả nói họ xây một hệ dữ liệu hơn 15B tokens bằng ba pipeline tự động, rồi dùng multi-task balanced RL để giảm xung đột giữa các loại tác vụ khác nhau. Project page cũng nhấn mạnh framework Planner-Grounder-Corrector (PGC): cùng một model có thể chia task dài thành bước nhỏ, ground từng bước vào vị trí/điểm tương tác, rồi kiểm tra và sửa khi trạng thái không đúng.
Với VLA, họ không pretrain hành động quy mô lớn như nhiều VLA khác. Embodied-R1.5-VLA được xây trên backbone Embodied-R1.5, gắn action head và fine-tune bằng action data. Đây là lý do bài này tập trung vào LIBERO: benchmark này đủ nhỏ để người mới tái lập workflow, nhưng vẫn có đủ bốn nhóm task quan trọng trong robot manipulation.
LIBERO đo cái gì?
LIBERO là benchmark manipulation trong mô phỏng, thường dùng Franka/Panda robot và môi trường MuJoCo. Khi đọc kết quả, bạn sẽ gặp bốn suite:
| Suite | Ý nghĩa | Ví dụ task |
|---|---|---|
| LIBERO-Spatial | Kiểm tra quan hệ không gian | đặt vật bên trái/phải/trên một đối tượng |
| LIBERO-Object | Kiểm tra nhận dạng đối tượng | chọn đúng object trong nhiều object tương tự |
| LIBERO-Goal | Kiểm tra goal-conditioned task | hoàn thành mục tiêu mô tả bằng ngôn ngữ |
| LIBERO-Long | Kiểm tra long-horizon | task nhiều bước, dễ fail do tích lũy lỗi |
Kết quả được báo cáo bằng success rate. Một episode được tính thành công khi simulator xác nhận trạng thái cuối thỏa điều kiện task. Vì VLA chạy nhiều episode, con số trung bình mới có ý nghĩa. StarVLA README nói workflow LIBERO thường chạy 50 episode cho mỗi task, và một suite gồm 10 task, tức khoảng 500 trial mỗi suite.
Theo project page Embodied-R1.5, trên LIBERO Benchmark 40 Tasks, Embodied-R1.5-VLA không dùng action pretraining vẫn đạt:
| Model | Action pretraining | Goal | Spatial | Object | Long | Overall |
|---|---|---|---|---|---|---|
| OpenVLA-OFT | Có | 97.9 | 97.6 | 98.4 | 94.5 | 97.1 |
| pi0.5 | Có | 98.0 | 98.8 | 98.2 | 92.4 | 96.9 |
| OpenVLA-OFT | Không | 91.7 | 94.3 | 95.2 | 86.5 | 91.9 |
| pi0.5 | Không | 94.6 | 96.6 | 97.2 | 85.8 | 93.6 |
| Embodied-R1.5-VLA | Không | 97.4 | 97.8 | 99.2 | 93.2 | 97.3 |
Đây là kết quả báo cáo từ nhóm tác giả, không phải kết quả tôi chạy lại cục bộ. Điểm đáng chú ý không phải chỉ là Overall 97.3, mà là không cần action pretraining vẫn đạt nhóm đầu. Điều này ủng hộ giả thuyết của paper: nếu backbone đã có embodied cognition, pointing và correction tốt, thì action fine-tuning cần ít dữ liệu hơn để đạt policy mạnh.
Chuẩn bị phần cứng
Bạn có thể chạy inference nhẹ bằng checkpoint có sẵn trên một GPU lớn, nhưng fine-tune nghiêm túc vẫn cần máy nhiều VRAM. Dưới đây là cấu hình thực tế nên dùng:
| Mục tiêu | GPU gợi ý | Ghi chú |
|---|---|---|
| Đọc model card, tải checkpoint | Không cần GPU | chỉ dùng Hugging Face CLI |
| Evaluate LIBERO với checkpoint | RTX 4090 24GB hoặc A100 | tách starVLA env và libero env |
| Fine-tune thử một suite | 1-2 GPU 24GB | batch nhỏ, gradient accumulation |
Fine-tune libero_all |
8x A100/H800 theo hướng dẫn StarVLA | khoảng 30K steps, gần 10 epochs |
Nếu chỉ có laptop, bạn vẫn có thể học workflow và chuẩn bị data. Nhưng đừng kỳ vọng fine-tune model 8B hoặc Qwen3-VL backbone trên CPU. Với người mới, cách hợp lý nhất là chạy evaluation trước, sau đó thuê cloud GPU vài giờ để fine-tune một suite nhỏ như libero_goal.
Cài môi trường Embodied-R1.5
Repo Embodied-R1.5 dùng cho inference VLM, training SFT/RFT của Embodied Foundation Model, và liên kết tới VLA checkpoints. Phần VLA thực tế dùng StarVLA, nhưng bạn nên clone repo chính để đọc script, ví dụ inference, và format output.
git clone https://github.com/pickxiguapi/Embodied-R1.5.git
cd Embodied-R1.5
conda create -n er15 python=3.10 -y
conda activate er15
pip install "transformers>=4.57.0" qwen-vl-utils vllm openai pillow
Bạn có thể chạy Embodied-R1.5 như một VLM bằng vLLM:
vllm serve IffYuan/Embodied-R1.5 \
--served-model-name "Embodied-R1.5" \
--tensor-parallel-size 1 \
--mm-encoder-tp-mode data \
--gpu-memory-utilization 0.7 \
--async-scheduling \
--media-io-kwargs '{"video": {"num_frames": 32}, "image": {"max_num": 32}}' \
--max_model_len 20000 \
--limit-mm-per-prompt '{"image": 8, "video": 1}' \
--host 0.0.0.0 \
--port 22002
Output VLM được chuẩn hóa trong thẻ <answer>...</answer>. Với pointing, model trả JSON chứa point_2d; các tọa độ được normalize về thang [0, 1000], không phụ thuộc độ phân giải ảnh gốc. Với trace 3D, output có thêm depth theo mét. Đây là lớp reasoning/grounding. Để robot thật hoặc simulator chạy, ta cần action head của VLA.
Cài StarVLA cho VLA training
Embodied-R1.5 README ghi rõ: VLA training và inference dùng starVLA. Vì vậy phần thao tác LIBERO nên làm trong repo StarVLA:
git clone https://github.com/starVLA/starVLA.git
cd starVLA
conda create -n starVLA python=3.10 -y
conda activate starVLA
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
pip install -e .
Nếu flash-attn lỗi, kiểm tra CUDA và PyTorch:
nvcc -V
pip list | grep -E 'torch|transformers|flash-attn'
StarVLA guideline ghi flash-attn==2.7.4.post1 đã được xác nhận hoạt động tốt với CUDA 12.0 và 12.4. Với AMD MI300X/ROCm, cộng đồng đã báo cáo có thể chạy bằng cách đổi attention implementation sang sdpa, nhưng nếu bạn là beginner thì nên bắt đầu bằng NVIDIA GPU để giảm biến số.
Tải checkpoint Embodied-R1.5-VLA-LIBERO
Checkpoint được release ở Hugging Face:
huggingface-cli download IffYuan/Embodied-R1.5-VLA-LIBERO \
--local-dir playground/Pretrained_models/Embodied-R1.5-VLA-LIBERO
Bạn cũng nên tải base VLM nếu muốn fine-tune từ backbone hoặc thay framework:
huggingface-cli download IffYuan/Embodied-R1.5 \
--local-dir playground/Pretrained_models/Embodied-R1.5
Trong thực tế, checkpoint Hugging Face có thể chỉ chứa weight/config, còn script StarVLA yêu cầu đường dẫn checkpoint PyTorch cụ thể. Hãy mở playground/Pretrained_models/Embodied-R1.5-VLA-LIBERO và xác định file .pt, .safetensors hoặc config tương ứng. Nếu script StarVLA hiện tại chỉ hỗ trợ checkpoint layout của StarVLA/bench-libero, bạn cần chỉnh CKPT và config loader cho đúng format. Đây không phải lỗi của model, mà là điểm thường gặp khi ghép checkpoint paper mới với framework đang phát triển nhanh.
Cài môi trường LIBERO
Không nên cài LIBERO chung môi trường StarVLA. Evaluation dùng mô hình client-server: một terminal chạy policy server trong env starVLA, terminal còn lại chạy simulator trong env libero.
conda create -n libero python=3.10 -y
conda activate libero
pip install mujoco==3.2.3
git clone https://github.com/Lifelong-Robot-Learning/LIBERO.git
cd LIBERO
pip install -e .
cd ..
pip install tyro matplotlib mediapy websockets msgpack numpy==1.24.4
Trên server headless, thêm biến môi trường để MuJoCo render bằng EGL:
export MUJOCO_GL=egl
export PYOPENGL_PLATFORM=egl
Nếu gặp lỗi OpenGL, kiểm tra driver NVIDIA, nvidia-smi, và biến LD_LIBRARY_PATH. Đa số lỗi evaluation LIBERO không nằm ở model mà nằm ở render backend, phiên bản MuJoCo hoặc mismatch Python package.
Chạy evaluation LIBERO
Trong repo StarVLA, thư mục examples/LIBERO/eval_files/ chứa hai script quan trọng:
run_policy_server.sh: khởi động policy server, load checkpoint và expose endpoint nhận observation.eval_libero.sh: chạy simulator, gửi observation sang server, nhận action và tính success rate.
Mô hình dữ liệu khi evaluate:
LIBERO simulator
observation: image, proprio/state, language instruction
|
| websocket / msgpack
v
StarVLA policy server
Embodied-R1.5 backbone + action head
|
v
action chunk: [x, y, z, roll, pitch, yaw, gripper]
|
v
LIBERO environment step
Terminal 1:
conda activate starVLA
# Sửa CKPT trong examples/LIBERO/eval_files/run_policy_server.sh
# Ví dụ:
# CKPT=playground/Pretrained_models/Embodied-R1.5-VLA-LIBERO/checkpoints/steps_xxxxx_pytorch_model.pt
bash examples/LIBERO/eval_files/run_policy_server.sh
Chờ log kiểu:
server listening on 0.0.0.0:6694
Terminal 2:
conda activate libero
export MUJOCO_GL=egl
export PYOPENGL_PLATFORM=egl
# Sửa paths trong examples/LIBERO/eval_files/eval_libero.sh
bash examples/LIBERO/eval_files/eval_libero.sh
Khi chạy xong, script sẽ in success rate và lưu video trong results/{task_suite}/{checkpoint_name}/. Nếu mới thử lần đầu, hãy chạy một suite trước, ví dụ libero_goal, để kiểm tra toàn bộ pipeline. Sau đó mới chạy đủ bốn suite.
Chuẩn bị data để fine-tune
StarVLA dùng format LeRobot cho dataset LIBERO. Bạn có thể tải bốn subset bằng script:
conda activate starVLA
cd starVLA
export DEST=/path/to/your/data/directory
bash examples/LIBERO/data_preparation.sh
Script sẽ tải:
libero_spatial_no_noops_1.0.0_lerobotlibero_object_no_noops_1.0.0_lerobotlibero_goal_no_noops_1.0.0_lerobotlibero_10_no_noops_1.0.0_lerobot- dữ liệu VLM co-training như
LLaVA-OneVision-COCO
Sau khi tải, cấu trúc nên giống:
playground/Datasets/
├── LEROBOT_LIBERO_DATA/
│ ├── libero_spatial_no_noops_1.0.0_lerobot/
│ │ ├── meta/
│ │ │ └── modality.json
│ │ └── ...
│ ├── libero_object_no_noops_1.0.0_lerobot/
│ ├── libero_goal_no_noops_1.0.0_lerobot/
│ └── libero_10_no_noops_1.0.0_lerobot/
└── LLaVA-OneVision-COCO/
Kiểm tra dataloader:
python starVLA/dataloader/lerobot_datasets.py \
--config_yaml examples/LIBERO/train_files/starvla_cotrain_libero.yaml
Nếu lỗi modality.json, copy file từ examples/LIBERO/train_files/modality.json vào từng thư mục meta/. Nếu lỗi thiếu data key, mở một sample dataset và kiểm tra tên field ảnh, state, action có đúng schema StarVLA đang mong đợi không.
Hiểu config training
Trong examples/LIBERO/train_files/starvla_cotrain_libero.yaml, phần quan trọng nhất là framework, action model, dataset và trainer:
framework:
name: QwenOFT
qwenvl:
base_vlm: ./playground/Pretrained_models/Embodied-R1.5
attn_implementation: flash_attention_2
action_model:
action_dim: 7
state_dim: 7
future_action_window_size: 7
action_horizon: 8
datasets:
vlm_data:
dataset_py: vlm_datasets
per_device_batch_size: 4
vla_data:
dataset_py: lerobot_datasets
data_root_dir: playground/Datasets/LEROBOT_LIBERO_DATA
data_mix: libero_all
per_device_batch_size: 16
trainer:
max_train_steps: 100000
save_interval: 10000
eval_interval: 100
learning_rate:
base: 2.5e-05
qwen_vl_interface: 1.0e-05
action_model: 1.0e-04
loss_scale:
vla: 1.0
vlm: 0.1
Với beginner, tôi khuyên bắt đầu bằng QwenOFT. OFT dùng MLP action head, decode continuous action song song, dễ debug hơn FAST hoặc flow-matching. Khi đã có baseline, bạn có thể thử QwenPI hoặc QwenGR00T. action_dim: 7 trong LIBERO thường tương ứng delta pose 6 DoF cộng gripper. action_horizon: 8 nghĩa là policy sinh action chunk nhiều bước, giảm số lần phải gọi model.
Nếu GPU ít, chỉnh:
datasets:
vla_data:
data_mix: libero_goal
per_device_batch_size: 2
trainer:
max_train_steps: 10000
save_interval: 2000
Đây không phải cấu hình để đạt SOTA, nhưng đủ để kiểm tra fine-tuning có chạy, loss có giảm và checkpoint có thể evaluate.
Launch fine-tuning
Mở examples/LIBERO/train_files/run_libero_train.sh và sửa các biến:
Framework_name=QwenOFT
freeze_module_list=''
base_vlm=playground/Pretrained_models/Embodied-R1.5
config_yaml=./examples/LIBERO/train_files/starvla_cotrain_libero.yaml
libero_data_root=playground/Datasets/LEROBOT_LIBERO_DATA
data_mix=libero_all
run_root_dir=./results/Checkpoints
run_id=er15_vla_libero_oft
Sau đó chạy:
conda activate starVLA
bash examples/LIBERO/train_files/run_libero_train.sh
Script dùng accelerate launch với DeepSpeed ZeRO-2. Theo guideline của StarVLA, training libero_all trên 8x A100/H800 thường khoảng 30K steps, gần 10 epochs. Nếu dùng 1 GPU, bạn cần giảm batch size, tăng gradient accumulation, và chấp nhận training chậm. Đừng so sánh trực tiếp kết quả 1 GPU toy run với bảng SOTA.
Trong khi train, theo dõi ba tín hiệu:
| Tín hiệu | Kỳ vọng | Nếu bất thường |
|---|---|---|
vla_loss |
giảm dần hoặc dao động quanh mức thấp hơn | kiểm tra action normalization |
| GPU memory | ổn định sau vài step | giảm batch, bật gradient checkpointing |
| checkpoint eval | success rate tăng theo step | kiểm tra language prompt và stats unnormalization |
Một lỗi phổ biến là train xong nhưng evaluate rất thấp vì dùng sai action unnormalization stats. Script eval cần biết stats tương ứng dataset/checkpoint. Nếu bạn fine-tune data mới, hãy đảm bảo stats trong checkpoint hoặc config eval trỏ đúng nơi.
Inference trên robot thật cần thêm gì?
Embodied-R1.5-VLA-LIBERO chỉ là policy cho benchmark LIBERO. Để đưa sang robot thật, bạn cần bridge từ observation robot thật sang format policy:
Real robot cameras + state
|
v
preprocess to StarVLA sample format
|
v
Embodied-R1.5-VLA policy
|
v
action unnormalize
|
v
robot controller / safety layer / rate limiter
Tối thiểu bạn cần:
- Camera RGB hoặc RGB-D được calibrate.
- State vector khớp
state_dimcủa model. - Mapping action từ
[x, y, z, r, p, y, gripper]sang controller thật. - Safety layer giới hạn tốc độ, vùng làm việc, lực và emergency stop.
- Logging để replay lỗi.
Nếu mục tiêu là robot thật, hãy đọc thêm các bài về OpenVLA và VLA0 để hiểu vấn đề triển khai VLA, cũng như so sánh hướng action-as-text với continuous action head.
Checklist debug nhanh
[ ] vLLM/HF inference của Embodied-R1.5 chạy được?
[ ] StarVLA smoke test chạy được?
[ ] LIBERO env render được với MUJOCO_GL=egl?
[ ] Dataloader đọc được LeRobot LIBERO data?
[ ] Policy server mở port 6694?
[ ] eval_libero.sh trỏ đúng checkpoint và stats?
[ ] Video output có robot di chuyển hợp lý?
[ ] Success rate thấp do policy hay do action scaling?
Nếu policy đứng im, thường là action unnormalization hoặc checkpoint path. Nếu robot di chuyển lung tung, kiểm tra action order và gripper convention. Nếu simulator crash, kiểm tra MuJoCo/OpenGL trước khi đổ lỗi cho model.
Kết luận
Embodied-R1.5-VLA đáng chú ý vì nó chuyển câu hỏi từ "cần bao nhiêu action data để train VLA" sang "backbone embodied reasoning tốt giúp giảm action data đến mức nào". Trên LIBERO, kết quả báo cáo 97.3 Overall mà không action pretraining là tín hiệu mạnh: cognition, pointing, planning và correction trong backbone có thể chuyển hóa thành policy manipulation hiệu quả khi gắn action head đúng cách.
Với người mới, lộ trình hợp lý là: chạy Embodied-R1.5 như VLM để hiểu output grounding, chạy checkpoint Embodied-R1.5-VLA-LIBERO trên LIBERO, rồi fine-tune libero_goal trước khi mở rộng sang libero_all. Đừng bắt đầu bằng robot thật. Hãy để simulator giúp bạn bắt lỗi data, action scaling và checkpoint trước.