Nếu bạn đang theo dõi lĩnh vực Embodied AI, bạn sẽ nhận ra một vấn đề lớn: mỗi paper về Vision-Language-Action (VLA) lại đi kèm một codebase riêng, format dữ liệu riêng, cách đánh giá riêng. Muốn so sánh hai phương pháp? Chuẩn bị tinh thần dành vài tuần chỉ để setup môi trường. StarVLA ra đời để giải quyết chính xác vấn đề này — một framework mô-đun kiểu "Lego" cho phép bạn hoán đổi backbone và action head như lắp ghép các khối, tất cả dùng chung trainer, dataloader và deployment stack.
Paper được trình bày tại ICLR 2026 với hơn 1.500 stars trên GitHub chỉ sau vài tuần phát hành. Trong bài viết này, mình sẽ hướng dẫn bạn từ A đến Z: hiểu kiến trúc, cài đặt, training và chạy inference với StarVLA.
Tại sao cần StarVLA?
Trước StarVLA, nếu bạn muốn thử nghiệm VLA, bạn phải đối mặt với:
- Fragmentation: OpenVLA, Octo, RT-2, π₀ — mỗi cái một repo, một cách train, một cách eval.
- Không thể so sánh công bằng: Khác data pipeline, khác preprocessing → kết quả không so sánh được.
- Tốn thời gian: Muốn thử action head mới trên backbone cũ? Viết lại từ đầu.
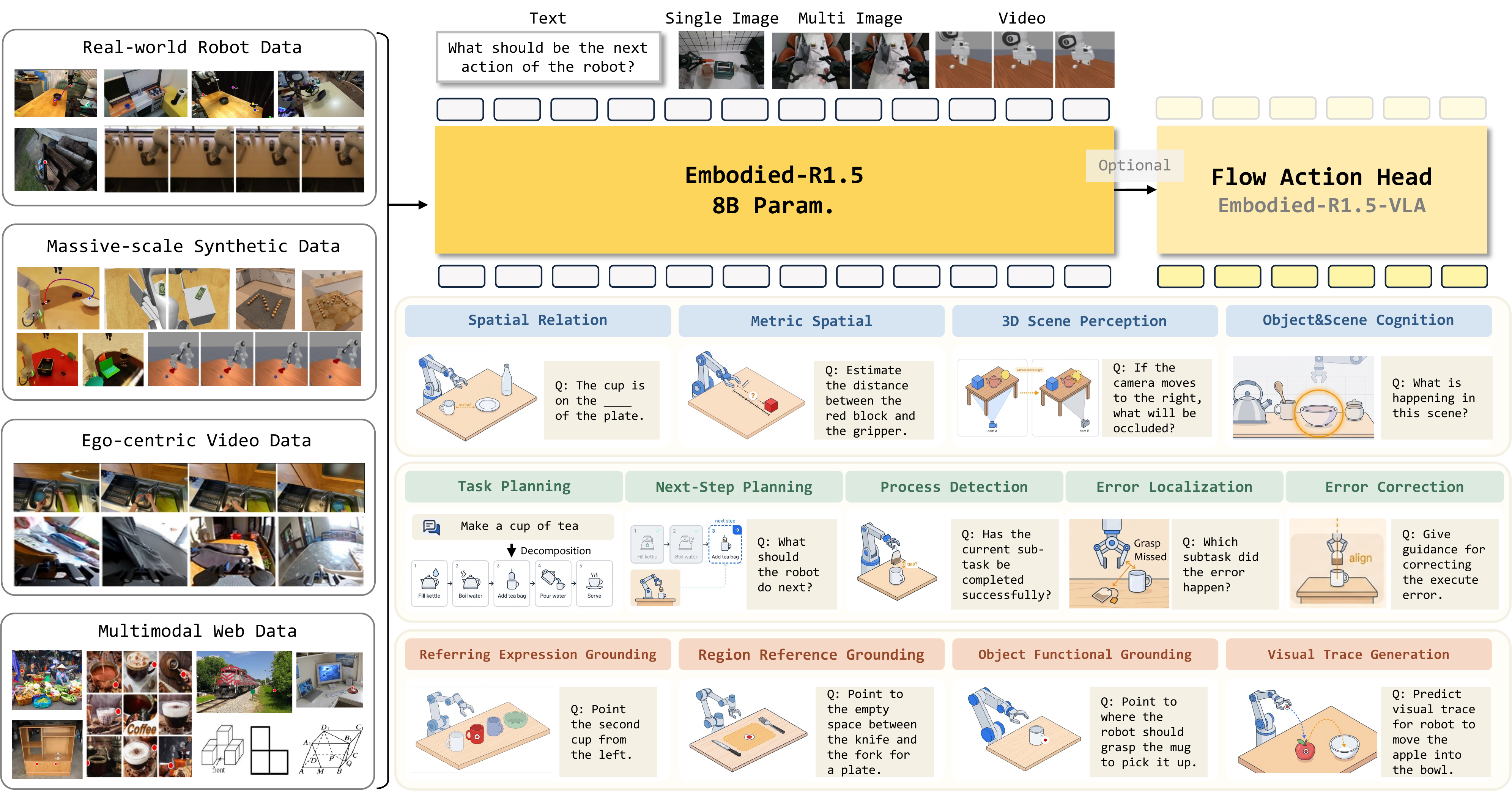
StarVLA giải quyết bằng cách tách biệt backbone (phần "nhìn và hiểu ngôn ngữ") khỏi action head (phần "ra quyết định hành động"). Nếu bạn chưa quen với khái niệm VLA, hãy đọc bài VLA Models — Khi Robot hiểu ngôn ngữ trước. Hai thành phần này có thể hoán đổi độc lập — giống như bạn thay ống kính máy ảnh mà không cần đổi thân máy.

Kiến trúc StarVLA
Backbone — "Bộ não" Vision-Language
StarVLA hỗ trợ hai loại backbone chính:
1. VLM Backbone (Vision-Language Model)
- Qwen3-VL (0.8B, 2B, 4B, 9B) — backbone mới nhất, hỗ trợ tốt tiếng Việt
- Qwen2.5-VL — phiên bản ổn định, đã được kiểm chứng rộng rãi
- InternVL — lựa chọn thay thế từ cộng đồng mã nguồn mở
- Florence-2 — backbone nhẹ từ Microsoft
2. World Model Backbone
- Cosmos (NVIDIA) — mô hình thế giới dự đoán trạng thái tiếp theo
- Cho phép VLA "tưởng tượng" kết quả hành động trước khi thực hiện
Action Head — "Cánh tay" Ra Quyết Định
Đây là phần thú vị nhất. StarVLA cung cấp 4 kiểu action head, mỗi kiểu đại diện cho một paradigm khác nhau trong VLA:
| Action Head | Paradigm | Mô tả |
|---|---|---|
| StarVLA-FAST | Autoregressive Discrete | Token hóa action thành discrete tokens, decode tuần tự giống language model |
| StarVLA-OFT | Parallel Continuous | MLP head decode action liên tục song song, nhanh nhất |
| StarVLA-PI | Flow-Matching Diffusion | Dùng flow-matching để generate continuous action, chính xác nhất |
| StarVLA-GR00T | Dual-System | VLM làm "System 2" (suy nghĩ), Flow-Matching làm "System 1" (phản xạ) |
StarVLA-FAST phù hợp khi bạn muốn tận dụng sức mạnh autoregressive của VLM. StarVLA-OFT cho tốc độ inference nhanh nhất vì decode song song. StarVLA-PI cho độ chính xác cao nhất với continuous action space — nếu bạn muốn hiểu sâu về flow-matching, xem bài Diffusion Policy cho Robot Manipulation. StarVLA-GR00T là kiến trúc tiên tiến nhất, kết hợp "suy nghĩ chậm" của VLM với "phản xạ nhanh" của flow-matching — lấy cảm hứng từ lý thuyết Dual Process của Daniel Kahneman.
Điểm mấu chốt: cả 4 action head đều dùng chung trainer, dataloader và deployment stack. Bạn chỉ cần thay đổi config để chuyển đổi giữa chúng.
Cài đặt StarVLA
Yêu cầu hệ thống
- Python 3.10+
- CUDA 12.0 hoặc 12.4 (đã xác nhận tương thích)
- GPU: tối thiểu 24GB VRAM (A5000, RTX 4090, A100)
- RAM: 32GB+
Bước 1: Clone và tạo môi trường
git clone https://github.com/starVLA/starVLA.git
cd starVLA
# Tạo conda environment
conda create -n starvla python=3.10 -y
conda activate starvla
# Cài dependencies
pip install -r requirements.txt
# FlashAttention2 — QUAN TRỌNG: phải khớp CUDA version
pip install flash-attn --no-build-isolation
# Cài StarVLA ở chế độ development
pip install -e .
Lưu ý quan trọng: FlashAttention2 phải tương thích với phiên bản CUDA toolkit và PyTorch của bạn. Framework đã xác nhận hoạt động tốt với
flash-attn==2.7.4.post1trên CUDA 12.0 và 12.4.
Bước 2: Tải pretrained backbone
# Tạo thư mục chứa model
mkdir -p playground/Pretrained_models
# Tải Qwen3-VL-4B (khuyến nghị cho bắt đầu)
# Bạn có thể dùng huggingface-cli hoặc tải thủ công
huggingface-cli download Qwen/Qwen3-VL-4B-Instruct \
--local-dir playground/Pretrained_models/Qwen3-VL-4B-Instruct
Bước 3: Kiểm tra cài đặt
# Test nhanh — chạy minimal forward pass
python starVLA/model/framework/QwenGR00T.py
Nếu không có lỗi, bạn đã sẵn sàng.

Training VLA Model
Chuẩn bị dữ liệu
StarVLA sử dụng format dữ liệu chuẩn hóa. Mỗi sample gồm:
- Observation: Hình ảnh từ camera (có thể multi-view)
- Language instruction: Câu lệnh mô tả task (ví dụ: "pick up the red cup")
- Action: Chuỗi action tương ứng (position, rotation, gripper state)
Framework hỗ trợ các dataset lớn sẵn có:
- Open X-Embodiment — dataset đa robot lớn nhất
- LIBERO — benchmark manipulation phổ biến
- RoboTwin 2.0 — benchmark song sinh (digital twin)
- RoboCasa — benchmark tương tác gia đình
Training trên LIBERO (ví dụ cụ thể)
LIBERO là điểm khởi đầu tốt nhất vì dataset nhỏ, dễ tải và kết quả kiểm chứng được nhanh.
# Training StarVLA-OFT trên LIBERO
bash examples/LIBERO/train_files/run_libero_train.sh
Nội dung script training bao gồm:
# Các tham số chính trong training script
python -m starVLA.train \
--backbone qwen3-vl-4b \
--action_head oft \
--dataset libero \
--batch_size 16 \
--learning_rate 1e-4 \
--num_epochs 50 \
--output_dir ./checkpoints/libero-oft
Giải thích các tham số quan trọng:
--backbone: Chọn VLM backbone (qwen3-vl-4b, qwen2.5-vl-3b, ...)--action_head: Chọn paradigm (fast, oft, pi, gr00t)--dataset: Dataset dùng để train--batch_size: Tùy thuộc VRAM — 16 cho A100 80GB, 4-8 cho RTX 4090
Chuyển đổi giữa các Action Head
Đây là sức mạnh thực sự của StarVLA. Muốn thử action head khác? Chỉ cần đổi một dòng:
# Thử StarVLA-FAST (autoregressive discrete)
python -m starVLA.train --action_head fast ...
# Thử StarVLA-PI (flow-matching diffusion)
python -m starVLA.train --action_head pi ...
# Thử StarVLA-GR00T (dual-system)
python -m starVLA.train --action_head gr00t ...
Tất cả dùng chung data pipeline, chung trainer — bạn chỉ thay đổi cách model decode action.
Evaluation và Benchmark
Kiến trúc 2 Terminal
StarVLA dùng mô hình policy server + simulator client để tránh xung đột dependency:
# Terminal 1: Chạy policy server (model inference)
bash examples/LIBERO/eval_files/run_policy_server.sh &
# Terminal 2: Chạy simulator environment
bash examples/LIBERO/eval_files/eval_libero.sh
Thiết kế này có ưu điểm: model serving và simulation chạy trong process riêng biệt, giao tiếp qua WebSocket. Điều này cho phép bạn deploy cùng một model lên cả simulation lẫn real robot mà không cần viết lại code serving.
Kết quả Benchmark
Dưới đây là kết quả được công bố trong paper:
| Benchmark | StarVLA-OFT | StarVLA-GR00T | Ghi chú |
|---|---|---|---|
| LIBERO | 96.6% | — | Average success rate |
| SimplerEnv | — | 71.4% | WidowX success rate |
| RoboCasa | 48.8% | — | Average success |
| RoboTwin 2.0 | 88.32 | — | Hard average score |
Đáng chú ý: những kết quả này đạt được với minimal data engineering — tức là chỉ dùng training recipe đơn giản, không có trick phức tạp. Framework đã match hoặc vượt qua các phương pháp trước đó trên nhiều benchmark.
Inference và Deployment
Chạy Inference trên Simulation
# Khởi động policy server với checkpoint đã train
python -m starVLA.serve \
--checkpoint ./checkpoints/libero-oft/best.pt \
--backbone qwen3-vl-4b \
--action_head oft \
--port 8765
# Kết nối từ simulator
python -m starVLA.eval.libero_client \
--policy_url ws://localhost:8765 \
--task_suite libero_spatial
Deploy lên Real Robot
StarVLA cung cấp ví dụ đầy đủ cho Franka Panda robot:
# Pseudo-code cho real robot deployment
from starVLA.deploy import PolicyClient
# Kết nối đến policy server
client = PolicyClient("ws://localhost:8765")
# Vòng lặp control
while not done:
# Lấy observation từ camera
image = camera.capture()
# Gửi observation + instruction, nhận action
action = client.predict(
image=image,
instruction="pick up the red cup"
)
# Thực thi action trên robot
robot.execute(action)
Giao diện WebSocket thống nhất là điểm mạnh lớn: bạn viết code deploy một lần, chạy được trên cả simulation lẫn real robot.

Mở rộng StarVLA — Viết Action Head Tùy Chỉnh
Một trong những điểm mạnh nhất của StarVLA là khả năng mở rộng. Muốn thêm action head mới? Bạn chỉ cần:
- Implement action head module — kế thừa từ base class
- Register module — đăng ký vào registry
- Done — framework tự động tích hợp với trainer và deployment
from starVLA.model.action_heads import BaseActionHead, register_head
@register_head("my_custom_head")
class MyCustomActionHead(BaseActionHead):
def __init__(self, config):
super().__init__(config)
# Định nghĩa layers
self.action_mlp = nn.Sequential(
nn.Linear(config.hidden_dim, 512),
nn.ReLU(),
nn.Linear(512, config.action_dim)
)
def forward(self, backbone_features, **kwargs):
# Decode action từ backbone features
return self.action_mlp(backbone_features)
def compute_loss(self, pred_actions, gt_actions):
return F.mse_loss(pred_actions, gt_actions)
Tương tự, thêm backbone mới cũng chỉ cần implement một lightweight adapter.
So sánh với các Framework khác
| Tiêu chí | StarVLA | LeRobot | OpenVLA |
|---|---|---|---|
| Modular backbone | ✅ Swap tự do | ❌ Cố định | ❌ Cố định |
| Nhiều action head | ✅ 4 paradigm | ✅ 2-3 paradigm | ❌ 1 paradigm |
| Benchmark tích hợp | ✅ 5+ benchmarks | ✅ 3-4 | ❌ Tự setup |
| Real robot deploy | ✅ WebSocket API | ✅ Native | ❌ Cần adapter |
| World model | ✅ Cosmos | ❌ | ❌ |
| Community | 1.5k+ stars | 10k+ stars | 5k+ stars |
StarVLA không thay thế LeRobot hay OpenVLA — chúng phục vụ mục đích khác nhau. LeRobot xuất sắc cho việc thu thập dữ liệu và training end-to-end trên hardware thực (xem hướng dẫn LeRobot hands-on của chúng mình). OpenVLA tiên phong về VLA đơn giản. StarVLA tỏa sáng khi bạn cần so sánh nhiều kiến trúc hoặc phát triển phương pháp mới — đó là công cụ dành cho researcher.
Lời khuyên thực tế
Bắt đầu từ đâu?
- Dùng StarVLA-OFT + Qwen3-VL-4B cho lần đầu — inference nhanh, kết quả tốt
- Train trên LIBERO trước — dataset nhỏ, dễ debug
- Khi đã quen, thử StarVLA-GR00T — kiến trúc dual-system cho hiểu biết sâu hơn
Pitfalls cần tránh:
- Không dùng FlashAttention version sai CUDA — sẽ crash im lặng
- Batch size quá lớn sẽ gây OOM — bắt đầu nhỏ rồi tăng dần
- Khi so sánh action head, giữ nguyên mọi thứ khác (backbone, data, hyperparams)
Tổng kết
StarVLA là bước tiến quan trọng trong việc chuẩn hóa nghiên cứu VLA. Thay vì mỗi lab tự xây framework riêng, cộng đồng có một nền tảng chung để xây dựng, so sánh và tái sản xuất kết quả. Với thiết kế mô-đun "Lego-like", bạn có thể tập trung vào ý tưởng nghiên cứu thay vì viết boilerplate code.
Tài nguyên:
- Paper: StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing — Jinhui Ye et al., arXiv 2026
- GitHub: github.com/starVLA/starVLA
- Documentation: starvla.github.io
- Model Zoo: Hugging Face (Qwen3-VL-4B-Action, Qwen2.5-VL-3B-Action)
Bài viết liên quan
- VLA Models — Khi Robot hiểu ngôn ngữ — Tổng quan về Vision-Language-Action models và cách chúng hoạt động
- Diffusion Policy cho Robot Manipulation — Hiểu flow-matching và diffusion-based action generation
- SpatialVLA — Nâng cấp VLA với nhận thức không gian — Framework VLA với spatial understanding nâng cao