Vì sao OpenVLA đáng học?
OpenVLA là một trong những dự án quan trọng nhất nếu bạn muốn hiểu cách Vision-Language-Action model đi từ ảnh camera và câu lệnh tự nhiên sang hành động robot. Paper gốc, "OpenVLA: An Open-Source Vision-Language-Action Model", được công bố trên arXiv năm 2024 bởi nhóm Stanford, UC Berkeley, Toyota Research Institute, Google DeepMind, Physical Intelligence và MIT. Điểm mạnh của OpenVLA không chỉ là model 7B parameter, mà là toàn bộ hệ sinh thái đi kèm: paper, project page, checkpoint Hugging Face, code PyTorch, script fine-tuning, hướng dẫn inference và benchmark trên robot thật.
Nếu các bài trước trong series giúp bạn hiểu imitation learning, Diffusion Policy, VLA model và LeRobot ở mức thực hành, bài này đi sâu hơn vào một câu hỏi cụ thể: OpenVLA thực sự hoạt động như thế nào, và beginner cần làm gì để chạy nó một cách có kiểm soát?
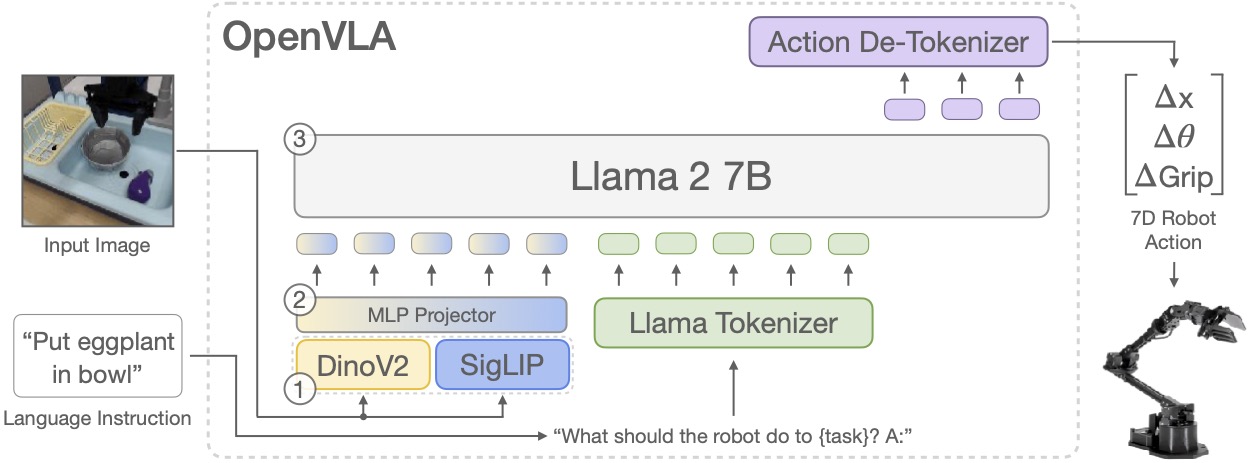
OpenVLA nhận hai loại input chính: một ảnh quan sát từ robot workspace và một instruction bằng ngôn ngữ tự nhiên, ví dụ put the yellow corn on the plate. Output không phải là câu trả lời text như chatbot, mà là action vector cho robot, thường ở dạng delta end-effector 7-DoF: x, y, z, roll, pitch, yaw, gripper. Vì vậy, OpenVLA nằm giữa computer vision, language model và robot control.
Điểm cần nhấn mạnh cho người mới: OpenVLA không phải là "LLM điều khiển robot bằng lời nói" theo nghĩa đơn giản. Nó là một policy học từ demonstration. Language chỉ là một phần điều kiện hóa hành vi. Nếu robot của bạn, camera của bạn, action space của bạn hoặc workspace của bạn khác xa dữ liệu pretraining, bạn vẫn cần collect demonstration và fine-tune.
Paper gốc muốn giải quyết vấn đề gì?
Trước OpenVLA, nhiều VLA mạnh là closed-source hoặc khó tái lập. RT-2 và RT-2-X cho thấy việc kết hợp vision-language pretraining với robot data có thể tạo ra policy tổng quát hơn, nhưng người dùng bên ngoài không dễ tải checkpoint, xem training recipe hoặc fine-tune theo robot riêng. OpenVLA đặt mục tiêu khác: đưa ra một VLA 7B open-source đủ mạnh để nghiên cứu và triển khai thử nghiệm.
Ý tưởng paper có thể tóm tắt bằng ba điểm:
| Vấn đề | Cách OpenVLA xử lý | Ý nghĩa cho người học |
|---|---|---|
| VLA trước đó khó truy cập | Release code, checkpoint, model card | Có thể chạy inference và fine-tune |
| Robot task đa dạng | Train trên Open X-Embodiment 970k trajectories | Model học từ nhiều embodiment và scene |
| Fine-tune 7B tốn compute | Hỗ trợ LoRA và quantization | Có thể thử trên GPU nhỏ hơn full training |
Theo project page, OpenVLA được pretrained trên 970k robot episodes từ Open X-Embodiment. Theo paper abstract, OpenVLA vượt RT-2-X 55B ở mức 16.5% absolute task success rate trên 29 task và nhiều robot embodiment, dù chỉ có khoảng 7x fewer parameters. Paper cũng báo cáo fine-tuning cho setting mới vượt Diffusion Policy trained-from-scratch 20.4% trong các môi trường multi-task, multi-object cần language grounding. Những con số này không có nghĩa OpenVLA luôn thắng mọi policy nhỏ hơn; chúng nói rằng pretraining đa dạng giúp OpenVLA mạnh trong các task cần hiểu câu lệnh, nhiều object và generalization.
Kiến trúc OpenVLA
OpenVLA được xây trên Prismatic VLM. Thay vì train mọi thứ từ đầu, nhóm tác giả fine-tune một pretrained vision-language model để output action token. Kiến trúc có ba khối chính:
Camera image
|
v
+-----------------------------+
| Fused visual encoder |
| DINOv2 + SigLIP |
+-----------------------------+
|
v
+-----------------------------+
| Projector |
| image embeddings -> LLM dim |
+-----------------------------+
|
v
+-----------------------------+
| Llama 2 7B backbone |
| instruction + image tokens |
+-----------------------------+
|
v
Tokenized robot actions
|
v
Continuous robot command
1. Fused visual encoder
OpenVLA dùng hai vision backbone: DINOv2 và SigLIP. DINOv2 mạnh về visual representation tự giám sát, còn SigLIP mạnh trong alignment ảnh-ngôn ngữ. Khi kết hợp hai nguồn feature, model có khả năng nhận biết object, pose, màu sắc, background và mối liên hệ với instruction tốt hơn so với chỉ dùng một encoder.
Với beginner, hãy nghĩ đơn giản: camera image được biến thành một chuỗi embedding. Mỗi embedding giống như một "token thị giác" chứa thông tin về patch hoặc vùng ảnh. LLM phía sau không đọc pixel trực tiếp; nó đọc embedding đã được visual encoder nén lại.
2. Projector
Projector là cầu nối giữa visual encoder và LLM. Visual feature ban đầu có dimension và distribution khác với token embedding mà Llama 2 mong đợi. Projector học cách map image embeddings vào không gian mà LLM có thể xử lý cùng language tokens.
Nếu bạn từng dùng CLIP hoặc BLIP, projector có vai trò tương tự adapter giữa modality. Trong robot learning, projector còn quan trọng hơn vì output cuối cùng không phải caption mà là action.
3. Llama 2 7B backbone
Llama 2 7B xử lý prompt dạng:
In: What action should the robot take to {instruction}?
Out:
Thay vì sinh câu tiếng Anh, LLM sinh action tokens. Các token này được decode thành continuous action vector để gửi xuống robot controller. Đây là điểm tinh tế: về mặt kiến trúc, OpenVLA tận dụng cơ chế autoregressive token prediction của language model; về mặt robot, nó đang làm visuomotor policy.
Action tokenization hoạt động ra sao?
Robot action liên tục thường có dạng:
action = [
delta_x,
delta_y,
delta_z,
delta_roll,
delta_pitch,
delta_yaw,
gripper
]
Language model lại sinh token rời rạc. Vì vậy OpenVLA cần discretize action. Cách thường được mô tả trong OpenVLA-style policy là chia mỗi chiều action thành các bin, ví dụ 256 bin, rồi encode thành token. Khi inference, model sinh token, tokenizer chuyển token về bin, sau đó unnormalize theo statistics của dataset/robot cụ thể.
Pipeline conceptual:
continuous action in dataset
|
v
normalize per dataset / robot
|
v
discretize into action bins
|
v
train LLM to predict action tokens
|
v
at inference: decode tokens -> unnormalize -> robot.act()
Điều này giải thích vì sao unnorm_key trong inference rất quan trọng. Nếu bạn dùng sai normalization statistics, action có thể cùng "ý nghĩa token" nhưng sai scale vật lý. Robot có thể di chuyển quá xa, quá chậm hoặc mở gripper sai thời điểm.
Cài đặt môi trường
OpenVLA có hai mức cài đặt: minimal inference và full training/fine-tuning. Với beginner, nên bắt đầu bằng inference trước để kiểm tra GPU, dependency và checkpoint.
Minimal inference
conda create -n openvla python=3.10 -y
conda activate openvla
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install transformers timm tokenizers pillow accelerate
pip install flash-attn --no-build-isolation
Nếu flash-attn lỗi build, bạn vẫn có thể thử chạy không bật attn_implementation="flash_attention_2", nhưng inference sẽ chậm và tốn memory hơn. Với GPU 24GB, bạn nên cân nhắc quantization hoặc chạy model server trên GPU lớn hơn.
Cài repo để fine-tune
conda create -n openvla-train python=3.10 -y
conda activate openvla-train
conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia -y
git clone https://github.com/openvla/openvla.git
cd openvla
pip install -e .
pip install packaging ninja
pip install "flash-attn==2.5.5" --no-build-isolation
Repo gốc ghi rõ code được phát triển với Python 3.10, PyTorch 2.2.x, transformers 4.40.1, tokenizers 0.19.1, timm 0.9.10 và flash-attn 2.5.5. Khi làm robotics, dependency drift là nguồn lỗi rất phổ biến. Nếu model load lỗi hoặc output bất thường, hãy kiểm tra version trước khi nghi ngờ paper.
Chạy inference cơ bản
Ví dụ dưới đây minh họa flow từ ảnh camera sang action. Đây không phải controller hoàn chỉnh, nhưng đủ để bạn hiểu interface.
from PIL import Image
import torch
from transformers import AutoModelForVision2Seq, AutoProcessor
processor = AutoProcessor.from_pretrained(
"openvla/openvla-7b",
trust_remote_code=True,
)
vla = AutoModelForVision2Seq.from_pretrained(
"openvla/openvla-7b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
).to("cuda:0")
image = Image.open("workspace.jpg").convert("RGB")
instruction = "put the yellow corn on the plate"
prompt = f"In: What action should the robot take to {instruction}?\nOut:"
inputs = processor(prompt, image).to("cuda:0", dtype=torch.bfloat16)
action = vla.predict_action(
**inputs,
unnorm_key="bridge_orig",
do_sample=False,
)
print(action)
Trong robot thật, image đến từ camera, còn robot.act(action) gửi command xuống low-level controller. Bạn cần đảm bảo năm điều:
| Thành phần | Câu hỏi kiểm tra |
|---|---|
| Camera pose | Góc nhìn có giống dataset hoặc fine-tune data không? |
| Action space | Robot nhận end-effector delta hay joint command? |
| Control frequency | Policy chạy 5 Hz, 10 Hz hay 15 Hz? |
| Normalization | unnorm_key có đúng dataset không? |
| Safety | Có workspace limit, emergency stop và velocity clamp không? |
OpenVLA model card nói rõ model output normalized 7-DoF end-effector deltas và cần unnormalize theo statistics của từng robot/dataset trước khi execute. Đây không phải chi tiết nhỏ; đây là ranh giới giữa demo chạy được và robot hành xử nguy hiểm.
Fine-tuning bằng LoRA
Full fine-tuning một model 7B cần nhiều GPU. Project page nói pretraining dùng cụm 64 A100 trong 15 ngày. Repo GitHub cung cấp recipe LoRA vì đây là lựa chọn thực tế hơn cho nhiều lab nhỏ.
LoRA thêm các low-rank adapter vào một số layer, chỉ train phần adapter thay vì cập nhật toàn bộ weight. Theo project page, LoRA đạt trade-off tốt giữa performance và memory, match full fine-tuning trong thí nghiệm của họ trong khi chỉ fine-tune khoảng 1.4% parameters.
Ví dụ command từ workflow của repo:
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path "openvla/openvla-7b" \
--data_root_dir /data/robot_datasets \
--dataset_name bridge_orig \
--run_root_dir /runs/openvla_lora \
--adapter_tmp_dir /tmp/openvla_adapter \
--lora_rank 32 \
--batch_size 16 \
--grad_accumulation_steps 1 \
--learning_rate 5e-4 \
--image_aug True \
--wandb_project openvla \
--wandb_entity your_team \
--save_steps 5000
Repo ghi chú rằng batch size 16 có thể cần khoảng 72GB GPU memory trong ví dụ BridgeData V2; nếu GPU nhỏ hơn, giảm batch_size và tăng grad_accumulation_steps để giữ effective batch size. Với GPU 24GB, bạn cần thử batch nhỏ, gradient accumulation, quantization, hoặc chuyển sang recipe mới hơn như OpenVLA-OFT nếu phù hợp.
Chuẩn bị dataset custom
OpenVLA hỗ trợ tốt RLDS vì pretraining/fine-tuning của họ dùng Open X-Embodiment. Nếu bạn có dataset robot riêng, pipeline nên là:
teleoperation demos
|
v
store images + actions + language instructions
|
v
convert to RLDS or write PyTorch Dataset wrapper
|
v
register dataset config + transform
|
v
LoRA fine-tune
|
v
evaluate on held-out tasks
Một episode tối thiểu nên có:
episode/
observations/
image_primary[t]
image_wrist[t] # optional
proprio[t] # optional
actions/
world_vector[t]
rotation_delta[t]
gripper_closedness[t]
language_instruction
metadata/
robot_id
control_frequency
camera_intrinsics
Với beginner, đừng bắt đầu bằng 50 task. Hãy chọn 2-3 task có success definition rõ ràng, ví dụ pick red block, place block in bowl, open drawer. Collect 50-100 demonstrations mỗi task, chia train/validation, kiểm tra action replay trước khi train. Nếu replay từ dataset đã sai, VLA sẽ học sai rất nhanh.
Training cần quan sát metric nào?
Trong training log, bạn sẽ thấy các metric như loss và action accuracy. Nhưng robotics không thể chỉ nhìn token accuracy. Một model predict đúng token trên validation chưa chắc execute tốt, vì sai một vài step quan trọng có thể làm cả rollout thất bại.
Nên theo dõi:
| Metric | Ý nghĩa | Lưu ý |
|---|---|---|
| Training loss | Model fit demonstration | Loss thấp quá nhanh có thể overfit |
| Action token accuracy | Độ đúng token rời rạc | Không thay thế real rollout |
| Validation rollout success | Task hoàn thành hay không | Cần protocol cố định |
| Intervention count | Người vận hành phải cứu mấy lần | Hữu ích khi debug |
| Latency | Thời gian từ frame đến action | Robot control cần ổn định |
Một evaluation protocol đơn giản:
For each task:
run 20 trials
randomize object position within safe region
use the same natural-language instruction template
record success/failure
record failure reason:
perception miss
wrong object
bad grasp
collision / safety stop
task sequencing error
Khi OpenVLA fail, hãy phân loại lỗi. Nếu model nhìn nhầm object, hãy kiểm tra camera, lighting, augmentation và language labels. Nếu action scale sai, kiểm tra normalization. Nếu policy đúng hướng nhưng chậm, kiểm tra control frequency và action clipping. Nếu robot gắp đúng object nhưng không hoàn thành sequence, task có thể cần nhiều data hơn hoặc action chunking/OFT.
Kết quả thực nghiệm nói gì?
OpenVLA có ba nhóm kết quả đáng chú ý.
Thứ nhất, direct evaluation trên nhiều robot platform. Project page mô tả đánh giá trên WidowX/Bridge V2 và Google Robot từ RT-series. OpenVLA vượt RT-1-X, Octo và thậm chí vượt RT-2-X 55B trong benchmark tổng hợp, dù RT-2-X vẫn mạnh hơn ở một số semantic task cần kiến thức Internet ngoài robot data.
Thứ hai, fine-tuning sang robot setup mới. Paper thử Franka-Tabletop và Franka-DROID. Kết quả quan trọng không phải OpenVLA luôn thắng Diffusion Policy ở mọi task. Diffusion Policy vẫn rất mạnh trong task hẹp, chính xác, single-instruction. OpenVLA nổi bật hơn ở task multi-object, multi-task, cần language grounding. Điều này cho bạn heuristic triển khai: nếu task chỉ là một motion rất hẹp, policy nhỏ có thể đủ; nếu task có nhiều object và instruction đa dạng, VLA đáng cân nhắc.
Thứ ba, parameter-efficient fine-tuning. LoRA cho thấy có thể đạt performance gần full fine-tuning với memory thấp hơn nhiều. Đây là lý do OpenVLA trở thành baseline phổ biến cho lab và startup robotics: bạn không cần tái tạo pretraining 64 A100, mà có thể bắt đầu từ checkpoint và adapter.
Hạn chế thực tế
OpenVLA mạnh nhưng không phải giải pháp plug-and-play cho mọi robot.
| Hạn chế | Tác động | Cách giảm rủi ro |
|---|---|---|
| Không zero-shot tốt cho embodiment chưa thấy | Robot khác kinematics/action space sẽ fail | Collect demos và fine-tune |
| Latency của 7B model | Control loop có thể chậm | Quantization, server GPU, OFT |
| Cần action normalization đúng | Sai scale gây hành vi nguy hiểm | Validate unnorm_key, clamp action |
| Camera/domain shift | Nhìn nhầm object hoặc pose | Camera calibration, augmentation |
| Semantic gap | Một số concept Internet không giữ tốt | Fine-tune instruction đa dạng |
Với triển khai nghiêm túc, hãy đặt OpenVLA ở tầng high-level policy và luôn có safety layer bên dưới:
OpenVLA action
|
v
action unnormalization
|
v
safety filter: workspace, velocity, force, collision
|
v
low-level controller
|
v
robot hardware
Không nên để model 7B gửi command trực tiếp xuống actuator mà không qua giới hạn workspace và emergency stop. Robotics khác chatbot ở chỗ output sai có thể làm hỏng thiết bị.
Khi nào nên chọn OpenVLA?
Chọn OpenVLA nếu bạn muốn nghiên cứu hoặc prototype robot manipulation có language instruction, nhiều object, camera-based policy và có kế hoạch fine-tune. Không nên chọn OpenVLA nếu bạn chỉ cần một task công nghiệp cực hẹp, yêu cầu cycle time thấp, hoặc không có GPU/server đủ mạnh.
So sánh nhanh:
| Lựa chọn | Phù hợp nhất | Điểm yếu |
|---|---|---|
| Hand-coded motion + perception | Task cố định, yêu cầu ổn định | Khó mở rộng instruction |
| ACT | Imitation learning đơn giản, inference nhanh | Ít generalization |
| Diffusion Policy | Contact-rich, precise manipulation | Training từ đầu, language yếu hơn |
| OpenVLA | Multi-task, multi-object, language grounding | 7B model, cần fine-tune đúng |
| OpenVLA-OFT | Fine-tune VLA nhanh hơn, action chunking | Cần theo recipe mới |
Checklist cho beginner
Nếu bạn muốn bắt đầu trong 1-2 tuần, hãy đi theo thứ tự này:
Day 1-2:
read paper abstract + project page
run minimal inference on a static image
Day 3-4:
connect camera stream
verify prompt format and output shape
do not connect robot actuator yet
Day 5-7:
collect small demonstrations
replay actions offline
convert dataset
Day 8-10:
LoRA fine-tune
monitor loss, action accuracy, validation samples
Day 11-14:
run slow, bounded robot rollouts
log failures
improve data and normalization
Khi đọc OpenVLA, điều quan trọng nhất là hiểu ranh giới giữa foundation model và robot system. Model giúp bạn có prior mạnh từ 970k trajectories, nhưng system vẫn cần data sạch, camera ổn định, controller an toàn, evaluation protocol và debug kỷ luật.
Nguồn tham khảo
- Paper: OpenVLA: An Open-Source Vision-Language-Action Model
- Project page: openvla.github.io
- GitHub repo: openvla/openvla
- Model card: openvla/openvla-7b on Hugging Face