ETH Zürich vừa công khai khóa Robot Learning: From Fundamentals to Foundation Models do Oier Mees giảng dạy trong Spring 2026. Đây không phải một playlist robotics rời rạc. Điểm đáng giá là khóa học gom lại đúng con đường mà nhiều người mới vào robot learning thường phải tự vá từ nhiều nguồn: PyTorch cơ bản, robot control, MDP, imitation learning, reinforcement learning, generative policy, sequence modeling, world models, generalist robot policies và cuối cùng là Vision-Language-Action (VLA) / foundation models cho robotics.
Course website chính thức nằm tại cvg.ethz.ch/lectures/Robot-Learning, repo bài tập ở mees-robot-learning-course/ethz-course-2026. Nếu bạn đang học RL basics, imitation learning, Diffusion Policy hoặc VLA models, khóa này có thể dùng như xương sống thực hành.
Bài này không chỉ giới thiệu course. Ta sẽ bóc theo hướng kỹ thuật: course được thiết kế như một architecture học tập ra sao, các paper gốc trong syllabus giải quyết vấn đề gì, repo homework chạy thế nào, train/inference/evaluation ra sao, và beginner nên học theo thứ tự nào để không bị ngợp.

Ý tưởng cốt lõi: học robot learning như một stack
Robot learning rất dễ gây ảo giác rằng chỉ cần chọn một model mới: Diffusion Policy, ACT, OpenVLA, π0, Gato, hoặc một VLA đang hot. Nhưng nếu không hiểu state/action, MDP, control loop, data distribution, reward, offline dataset và inference latency, bạn sẽ không biết vì sao policy fail trên robot thật.
Course của ETH giải quyết bằng cách đi từ thấp lên cao:
| Tầng | Câu hỏi cần hiểu | Homework hoặc paper đại diện |
|---|---|---|
| Tensor & neural network | Tensor, autograd, training loop hoạt động thế nào? | HW1 PyTorch/Numpy, MNIST, GLU |
| Control & MDP | Robot state/action là gì, IK/PID/trajectory tạo chuyển động ra sao? | HW2 SO-100/SO-101 MuJoCo |
| Imitation learning | Làm sao biến demonstration thành dataset và policy? | HW3 teleoperation, zarr, DAgger |
| RL | Làm sao học từ reward và interaction? | HW4 value iteration, DQN, PPO, SAC |
| Generative/sequence models | Vì sao action có thể là trajectory, token, hoặc denoising process? | Diffusion Policy, Decision Transformer |
| Foundation models | Làm sao một model tổng quát dùng vision/language/action? | Gato, π0.6, VLA papers |
Điểm khác biệt của lộ trình này là nó không bắt đầu bằng foundation model. Nó bắt đầu bằng robot nhỏ trong MuJoCo, nơi bạn có thể nhìn thấy mọi lỗi: IK không hội tụ, PID rung, reward sai, policy overfit demonstration, DQN không ổn định, PPO/SAC học chậm. Khi đã thấy những lỗi đó, paper VLA không còn là buzzword nữa; bạn hiểu nó đang cố scale phần nào của stack.
Paper gốc và project gốc cần đọc
Tuần đầu của course đặt nền bằng control và MDP. Các bài như Simple random search provides a competitive approach to reinforcement learning, Deep RL Doesn't Work Yet, và Curiosity-driven Exploration by Self-supervised Prediction nhắc bạn rằng RL không phải phép màu. Một thuật toán đơn giản đôi khi cạnh tranh được với deep RL nếu environment và evaluation chưa đủ chặt; exploration cũng không tự nhiên xuất hiện nếu reward quá nghèo.
Tuần imitation learning đi qua Causal Confusion in Imitation Learning, The Surprising Effectiveness of Representation Learning for Visual Imitation, và Transporter Networks. Ý tưởng chung: behavior cloning không chỉ là MSE giữa observation và action. Nếu policy học nhầm feature tương quan nhưng không nhân quả, robot có thể trông đúng trong validation nhưng fail khi camera, object hoặc background thay đổi.
Tuần generative models đưa vào Diffusion Policy và paper Visuomotor Policy Learning via Action Diffusion. Diffusion Policy xem một chuỗi action như sample từ distribution, rồi sinh action bằng denoising. Kết quả được công bố trên 12-15 tasks từ 4 benchmark manipulation, với cải thiện trung bình khoảng 46.9% so với các baseline state-of-the-art. Nếu bạn đã đọc bài Diffusion Policy: Cách mạng robot manipulation, hãy xem tuần này như cầu nối từ behavior cloning sang generative action model.
Tuần sequence modeling dùng Decision Transformer, ý tưởng xem RL như conditional sequence modeling: input là return-to-go, state, action token; output là action tiếp theo. Thay vì học Q-function hoặc policy gradient trực tiếp, model học phân phối trajectory kiểu Transformer.
Tuần generalist policies dùng Gato, một single Transformer xử lý Atari, captioning, chat, block stacking và nhiều task bằng cùng một bộ weights. Đây là nền tảng tư duy cho VLA: action có thể được token hóa và nằm cùng không gian sequence với observation, text và reward context.
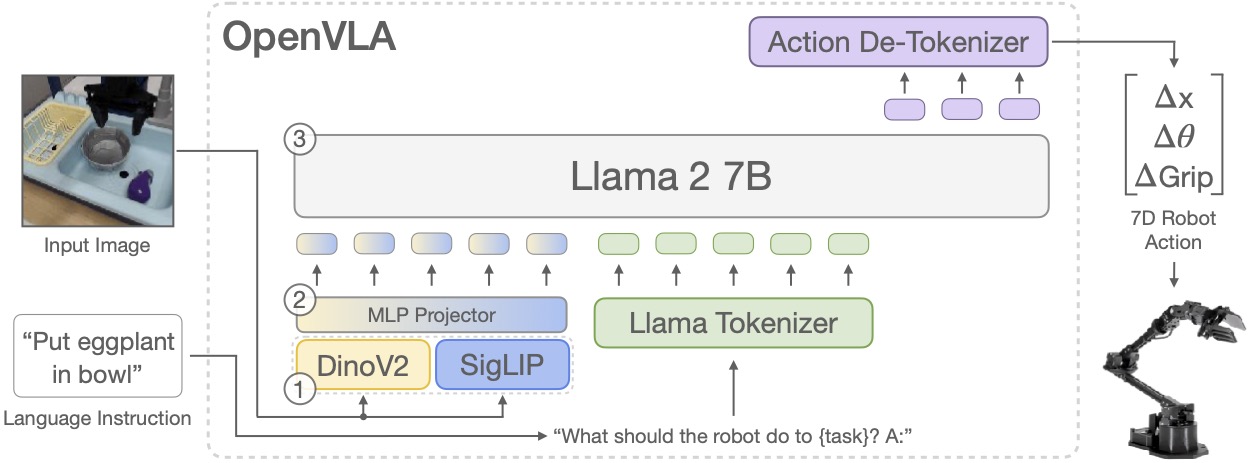
Tuần VLA/foundation models có π*0.6: a VLA That Learns From Experience, nơi Physical Intelligence nghiên cứu cách VLA cải thiện qua deployment thực tế bằng RL và advantage-conditioned policies. Đây là bước nối giữa imitation từ dataset lớn và robot tự cải thiện bằng experience.
Architecture của repo homework
Repo ETH hiện có 4 thư mục homework:
ethz-course-2026/
├── hw1_pytorch_tutorial/
├── hw2_robot_control_mdps/
├── hw3_imitation_learning/
└── hw4_reinforcement_learning/
HW1 là nền PyTorch: tensor basics, core ops, neural networks, MNIST training/test loss, và GLU. Mục tiêu không phải train model lớn, mà là buộc bạn hiểu dtype, device, autograd, loss curve và reproducibility.
HW2 dùng SO-100/SO-101 arm trong MuJoCo. Bạn implement keypoints trên Lemniscate of Bernoulli, inverse kinematics bằng Damped Least Squares, quintic spline waypoint generation, PID control, rồi train PPO policy để track random waypoints. Control loop được thiết kế rất thực tế: policy ra action ở 10 Hz, MuJoCo step ở 500 Hz, ctrl_decimation = 50, reward dựa trên end-effector tracking error. Bài tập yêu cầu average final EE tracking error dưới 0.05 để đạt full score cho policy tracking.

HW3 là imitation learning pipeline kiểu research/business hiện đại. Bạn teleoperate SO-101 trong simulation, lưu raw observations vào zarr, compute actions dưới dạng delta giữa states, train policy, evaluate success rate, rồi dùng DAgger để thu thêm expert actions khi policy ra khỏi distribution. Exercise 1/2 dùng ObstaclePolicy; exercise 3 là multicube goal-conditioned imitation learning với MultiTaskPolicy, ba cube đỏ/xanh lá/xanh dương, bin random, và one-hot state_goal.
HW4 đi sâu RL: tabular policy/value iteration trên Cliff Walking, DQN trên CartPole, PPO và SAC trên SO100 continuous control. Observation của SO100 trong HW4 là vector 19 chiều gồm joint positions, end-effector pose, target position và position error trong robot base frame. Action là vector 6 chiều trong [-1, 1]^6, sau đó map tuyến tính sang joint ranges vật lý.
Cài đặt môi trường
Beginner nên chạy từng homework trong virtual environment riêng. Repo dùng Python 3.12 cho nhiều bài và khuyến nghị uv hoặc venv. Ví dụ với HW3:
cd hw3_imitation_learning
uv venv --python 3.12
source .venv/bin/activate
uv pip install -e .
Các dependency quan trọng:
| Package | Dùng để làm gì |
|---|---|
torch, torchvision |
neural network, training loop, supervised policy |
mujoco, dm-control |
physics simulation và robot viewer |
gymnasium |
RL environment API |
stable-baselines3 |
PPO trong HW2 |
tensorboard |
visualize reward/loss/training curve |
zarr |
lưu demonstration dataset |
opencv-python |
xử lý frame/recording |
Với Linux, nếu MuJoCo viewer lỗi EGL/OpenGL, README HW2 khuyến nghị cài libegl1-mesa-dev, libgl1-mesa-dri, libglvnd-dev. Smoke test cơ bản là mở viewer:
python scripts/interactive.py
Với HW4, smoke test MuJoCo/SO100 có thể chạy headless:
python -c "from pathlib import Path; import numpy as np; from envs.so100_rl_env import SO100RLEnv; env=SO100RLEnv(xml_path=Path('assets/mujoco/so100_pos_ctrl.xml').resolve(), render_mode=None); obs,_=env.reset(seed=0); obs2,reward,term,trunc,info=env.step(np.zeros(env.action_dim, dtype=np.float32)); env.close(); print('OK ex3/ex4:', obs.shape, float(reward))"
Nếu bạn mới học, đừng bắt đầu bằng VLA. Hãy chạy được viewer, hiểu qpos, qvel, data.ctrl, mj_step, rồi mới train policy.
Training: từ supervised learning đến PPO/SAC
Ở HW1, training đơn giản nhất là MNIST hoặc GLU experiment. Bạn cần nhìn training loss và test loss, sau đó giải thích overfitting/reproducibility. Đây là bài kiểm tra tư duy: kết quả không chỉ là accuracy, mà là bạn có biết đọc curve không.
Ở HW2, training PPO tracking policy diễn ra sau khi environment đã định nghĩa observation, action processing và reward. Luồng cơ bản:
cd hw2_robot_control_mdps
python scripts/train.py --max_iterations 500 --save_checkpt_freq 50
tensorboard --logdir=logs --port=6006
Trong training, policy nhận observation gồm robot state và target, output normalized action, environment scale action về joint target, MuJoCo chạy nhiều step vật lý, rồi reward được tính từ tracking error. Nếu reward chỉ âm distance, policy sẽ học tiến gần target; nếu reward scale quá nhỏ, learning signal yếu; nếu action range quá rộng, policy dễ rung hoặc chạm giới hạn khớp.
Ở HW3, training imitation policy bắt đầu từ data collection:
python scripts/configure_keys.py
python scripts/record_teleop_demos.py
python scripts/compute_actions.py
python scripts/train.py --state-keys state_ee_xyz state_gripper "state_cube[:5]" --action-keys action_ee_xyz action_gripper --policy obstacle
Điểm beginner cần hiểu: action trong imitation không nhất thiết là absolute joint target. Repo khuyến khích chọn action space giúp bài toán dễ hơn, ví dụ end-effector delta thay vì full joint angle. Dataset lưu states như state_ee_xyz, state_ee_full, state_joints, state_gripper, state_cube, state_obstacle, goal_pos. Với multicube, dataset có thêm original_pos_cube_red, original_pos_cube_green, original_pos_cube_blue, state_goal.
Ở HW4, DQN dùng replay buffer, epsilon-greedy và target network; PPO dùng clipped surrogate, value loss, entropy; SAC dùng twin critics, entropy bonus và automatic temperature tuning. Beginner không cần thuộc công thức ngay, nhưng phải biết khác biệt:
| Thuật toán | Loại action | Dùng data cũ? | Điểm cần chú ý |
|---|---|---|---|
| DQN | discrete | replay buffer | target network, overestimation |
| PPO | continuous/discrete | gần như on-policy | clipping, GAE, KL drift |
| SAC | continuous | off-policy | entropy, twin Q, temperature |
Inference và evaluation
Inference trong robot learning không giống inference text. Một policy không chỉ output một câu trả lời; nó output action lặp lại theo control frequency, và mỗi action thay đổi state tiếp theo. Vì vậy evaluation phải xem cả rollout.
HW2 evaluation random target:
python scripts/evaluate_rand_targets.py --load_run=1 --checkpoint=500
Script chạy 10 episodes, mỗi episode 2 giây, in final EE tracking error và average. Mốc full score là Average final EE tracking error < 0.05. Đây là metric tốt cho beginner vì nó trực tiếp đo robot có đưa end-effector tới target không.
HW3 evaluation imitation:
python scripts/eval.py --checkpoint <path_to_checkpoint.pt> --num-episodes 100 --headless
python student_eval/run_eval --exercise 1 --checkpoint <path_to_checkpoint.pt>
Scoring exercise 1/2: success rate từ 85% trở lên đạt full score; 75%, 65%, 55%, 45% tương ứng các mức thấp hơn. Exercise multicube khó hơn nhiều; README nói success rate gần 50% đã là rất mạnh. Đây là bài học quan trọng: multi-task goal-conditioned policy khó hơn một task cố định, không chỉ vì model, mà vì data coverage và task ambiguity.
HW4 PPO/SAC evaluation:
python scripts/eval_ppo.py
python scripts/eval_ppo.py --play
python scripts/eval_sac.py
python scripts/eval_sac.py --play
Evaluation summary gồm mean return, std return, min/max return, mean length và mean tracking error. Khi xem policy playback, hãy để ý ba lỗi: policy dao động quanh target, policy chạm joint limit, hoặc policy học shortcut reward nhưng end-effector không ổn định.
Kết quả và ý nghĩa thực tế
Kết quả của course không phải một benchmark mới để so với SOTA. Giá trị nằm ở việc mỗi homework có metric đủ rõ để bạn biết mình đang học đúng hay chỉ chạy code:
| Phần | Output cần có | Kết quả mong muốn |
|---|---|---|
| HW1 | loss curves, GLU discussion | hiểu training/test và significance |
| HW2 IK/PID | video robot track Lemniscate/keypoints | motion mượt, ít rung |
| HW2 PPO | average final EE error | dưới 0.05 |
| HW3 IL | success rate | 85%+ cho exercise 1/2 là full score |
| HW3 multicube | goal-conditioned SR | gần 50% đã mạnh |
| HW4 PPO/SAC | return/tracking error summary | policy ổn định trong rollout |
Khi nối với paper lớn, bạn thấy một progression tự nhiên. Diffusion Policy giải quyết multimodal action distribution mà MSE behavior cloning xử lý kém. Decision Transformer biến RL thành sequence modeling để tận dụng Transformer. Gato chứng minh một network có thể xử lý nhiều modality và embodiment bằng tokenization. π*0.6 đưa VLA quay lại vòng lặp real-world deployment và RL từ experience. Course giúp bạn hiểu tại sao các bước đó hợp lý, thay vì chỉ nhớ tên model.
Lộ trình 6 tuần cho beginner
Nếu bạn tự học, đừng cố xem hết 12 tuần trong một weekend. Một kế hoạch hợp lý:
Tuần 1: Xem lecture Introduction, làm HW1 tensor/PyTorch. Mục tiêu là viết được training loop nhỏ và đọc loss curve.
Tuần 2: Làm HW2 IK, quintic spline, PID. Mục tiêu là hiểu workspace, joint space, Damped Least Squares, và vì sao control loop phải chạy nhanh hơn policy loop.
Tuần 3: Làm HW2 PPO waypoint tracking. Mục tiêu là chạy TensorBoard, hiểu reward, action scaling, checkpoint và evaluation.
Tuần 4: Làm HW3 imitation learning một cube. Mục tiêu là thu demonstration sạch, compute action, train ObstaclePolicy, evaluate success rate.
Tuần 5: Làm DAgger và multicube. Mục tiêu là thấy distribution shift: policy tốt trong train distribution nhưng fail khi obstacle/bin/cube thay đổi.
Tuần 6: Đọc Diffusion Policy, Decision Transformer, Gato, π*0.6. Mục tiêu là nối các architecture hiện đại với lỗi thực tế bạn đã thấy trong homework.
Nếu bạn làm trong lab Việt Nam, có thể thay SO-101 bằng arm rẻ hơn hoặc simulation-only trước. Quan trọng là giữ đúng interface: observation, action, dataset, training, inference, evaluation.
Những lỗi beginner hay mắc
Lỗi đầu tiên là nhảy thẳng vào VLA. VLA rất hấp dẫn, nhưng nếu bạn chưa biết action space của robot là joint target, end-effector delta hay gripper command, bạn sẽ không debug được model.
Lỗi thứ hai là thu data quá dài nhưng chất lượng thấp. Trong HW3, README nhắc rằng nếu teleoperator đứng yên nhiều giây, dataset sẽ chứa nhiều action "do nothing", làm policy bias về đứng im. Data robotics không chỉ cần nhiều; cần đúng distribution.
Lỗi thứ ba là chỉ xem video rollout thành công. Hãy luôn chạy headless nhiều episodes, lưu success rate, tracking error, và xem failure cases. Một policy fail 15% có thể vẫn trông rất đẹp nếu bạn chỉ chọn video tốt nhất.
Lỗi thứ tư là không tách training và inference. Trong training, policy có thể dùng randomization, exploration noise, replay buffer hoặc teacher correction. Trong inference, robot chỉ có observation hiện tại và checkpoint. Mọi dependency ẩn sẽ lộ ra khi deploy.
Kết luận
Khóa ETH Robot Learning 2026 đáng học vì nó không bán một câu chuyện "foundation model giải quyết mọi thứ". Nó dạy đúng stack: tensor, control, MDP, imitation, RL, generative policies, sequence models, world models, rồi mới tới VLA/foundation models. Với beginner, đây là cách học ít lạc hướng nhất: mỗi paper hiện đại đều được đặt sau một lỗi thực tế mà bạn đã tự gặp trong homework.
Nếu bạn muốn đi xa hơn sau khóa này, hãy đọc tiếp các chủ đề về LeRobot ecosystem, OpenVLA deep dive và whole-body VLA training pipeline. Khi đó, các khái niệm như dataset schema, action chunking, diffusion head, policy rollout và sim2real sẽ không còn mơ hồ.