Quick summary
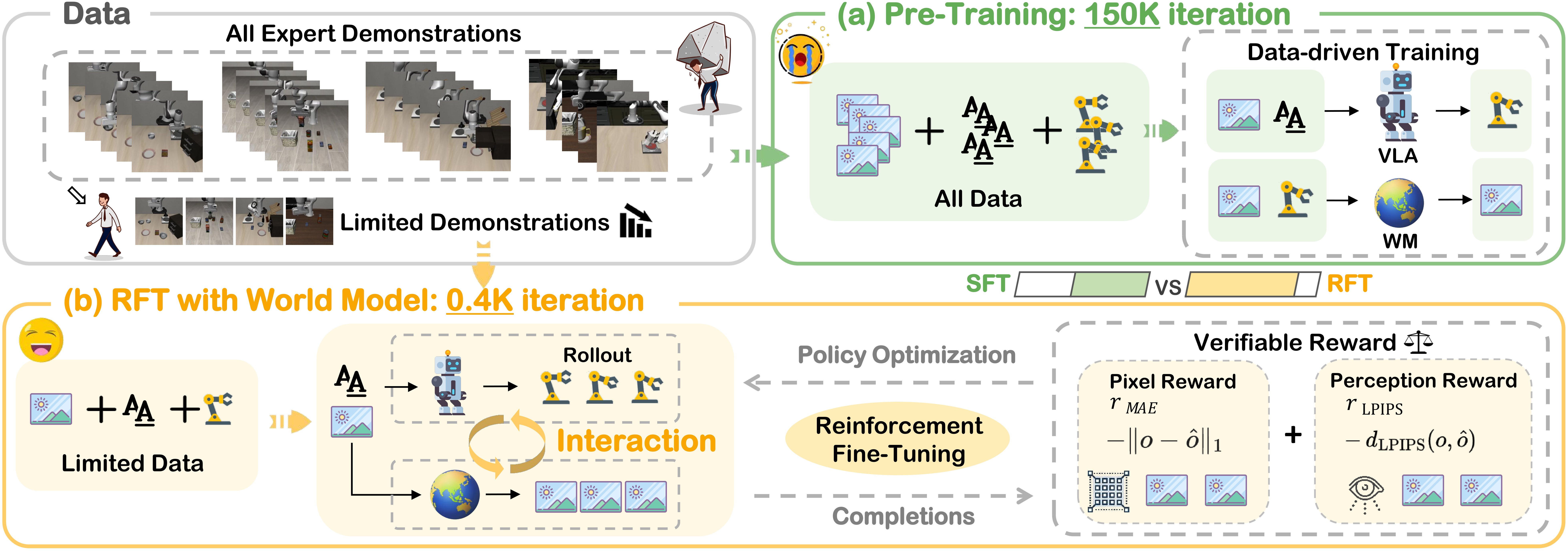
RISE: Self-Improving Robot Policy with Compositional World Model is an RSS 2026 paper from OpenDriveLab, Kinetix AI, CUHK, HKU, Tsinghua, and collaborators. The topic highlighted in Robopapers EP86 matters because it targets a real bottleneck in robot learning: VLA policies can understand instructions and imitate demonstrations, yet still break under contact-rich manipulation, deformable objects, small execution errors, and dynamic scenes.
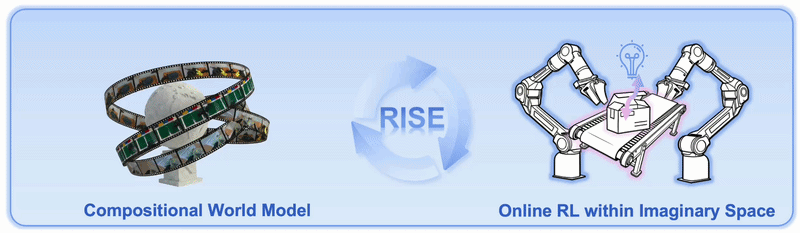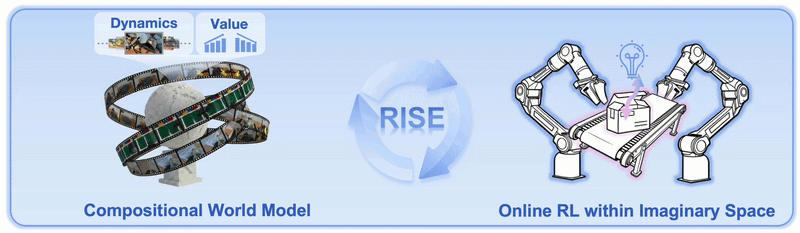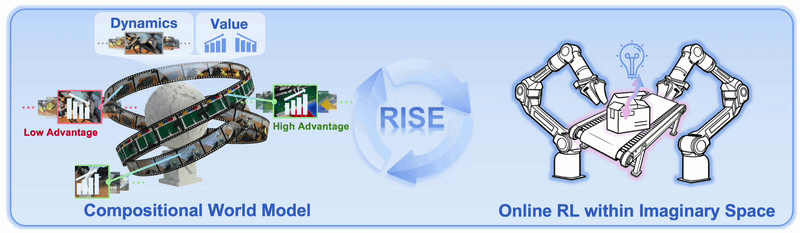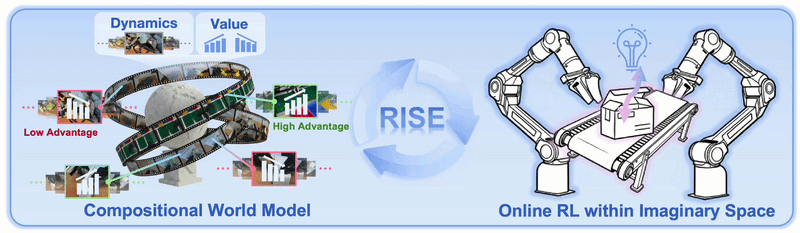
Running reinforcement learning directly on real robot hardware is expensive. Every rollout consumes hardware time, camera bandwidth, environment resets, human safety monitoring, and sometimes replacement objects. RISE proposes a different path: let the robot policy improve inside the imagination of a learned world model. The policy proposes an action chunk, the world model imagines future multi-view observations, the value model scores progress, and the policy is updated from the estimated advantage.
Primary sources:
| Source | Link | Notes |
|---|---|---|
| Paper | arxiv.org/abs/2602.11075 | arXiv paper for RISE |
| Project page | opendrivelab.com/RISE | Demos, method, results, video presentation |
| Code | github.com/OpenDriveLab/RISE | Apache 2.0 code, docs, deployment |
| Assets | rise_assets | Real robot GIFs used in this article |
The problem RISE solves
A beginner often hears "VLA model" and assumes a robot can now look at the scene, read a language command, and behave like a physical assistant. Reality is harsher. VLA policies such as π0, π0.5, OpenVLA-style policies, and related robot foundation models are usually trained heavily with imitation learning: watch many demonstrations, then learn the action distribution. This works well when test states stay close to the training demonstrations. It becomes brittle when the robot drifts away from the expert trajectory.
In Dynamic Brick Sorting, the robot must pick bricks from a moving conveyor and place them into color-matched bins. If the gripper is half a second late, the brick has already moved. In Backpack Packing, the robot handles soft objects and a zipper. In Box Closing, the robot must coordinate two arms, fold a flap, and tuck a tab into a narrow slot. These tasks require more than object recognition. They require contact-rich control, recovery, timing, and precision.
Reinforcement learning seems like the natural answer: let the robot try actions, receive reward, and improve. But real-world on-policy RL runs into three hard constraints:
- Serial interaction: one physical robot usually executes one rollout at a time.
- Reset cost: after failure, the scene must be reset, checked, or repaired.
- Safety risk: exploration can drop objects, jam grippers, hit cameras, or wear actuators.
RISE asks a more practical question: if a handcrafted simulator is not realistic enough, can we learn a world model from real robot data and use it as the RL environment?
The paper idea in one sentence
RISE stands for Reinforcement learning via Imagination for SElf-improving robots. The central loop is:
offline robot data
|
v
train dynamics model + value model
|
v
policy proposes action chunk
|
v
world model imagines future observations
|
v
value model estimates progress and advantage
|
v
policy improves from imagined rollouts
The key is that RISE does not try to build a full physics simulator like MuJoCo, Isaac Sim, or Genesis. It learns to predict future observations directly from multi-view camera images, conditioned on robot actions. In simple terms, the model answers: "if the robot sees this scene and executes this action chunk, what will the cameras see next?"
Then the value model answers a second question: "does that imagined future move the task closer to completion?" RISE separates these two questions into two modules, which is why the paper calls the system a Compositional World Model.
Overall architecture
The official repository is organized into three major parts:
OpenDriveLab/RISE
├── policy_and_value/
│ ├── policy_offline_and_value/ # OpenPI-based offline policy + value training
│ └── policy_online/ # online RL in imagination
├── dynamics/
│ └── dynamics_model/ # action-conditioned dynamics model
└── deploy/ # deployment on AgileX/Piper
You can understand the pipeline through four blocks.
1. Base VLA policy
The robot policy starts from π0.5, a pretrained VLA policy. It consumes multi-view RGB observations and a language instruction, then generates an action chunk. RISE does not learn from scratch because manipulation RL from scratch is usually too data hungry and too unsafe. Instead, the policy is warmed up on real offline data: expert demonstrations, policy rollouts with successes and failures, and a portion of human corrections similar to DAgger.
In the repository, policy and value training live under policy_and_value/policy_offline_and_value. The release docs mention three main configs:
| Config | Purpose |
|---|---|
Compute_norm |
Compute dataset normalization statistics |
Policy_offline_release |
Train the offline warm-up policy |
value_release |
Train the value model |
2. Controllable dynamics model
The dynamics model is the "imagination" component. It predicts future observations from visual history and an action chunk. The paper initializes it from Genie Envisioner GE-base, a video diffusion model that inherits design choices from LTX-Video. According to the paper, Cosmos can take more than 10 minutes to synthesize 25 multi-view observations, while GE takes less than 2 seconds for the same horizon, making it far more suitable for RL throughput.
RISE still needs to convert GE-base from a text-conditioned video model into an action-conditioned robot dynamics model. The authors add a lightweight action encoder and pretrain on large action-labeled robot datasets such as AgiBot World Alpha and Galaxea Open World Dataset. They also use Task-Centric Batching: a batch focuses on many samples from a small number of tasks, with diverse actions under similar scenes, so the model learns action-to-motion relationships more clearly.

3. Progress value model
Generating video is not enough. The robot also needs to know whether the imagined video is good or bad. RISE therefore uses a Progress Value Model to assign a scalar value to observations. This model is also initialized from a pretrained VLA backbone, because that backbone already contains robot-centric visual understanding and supports multi-view input better than a generic single-image VLM.
The value model is trained with two signals:
| Signal | Role |
|---|---|
| Progress estimate loss | Teaches the model where the robot is in task progress |
| Temporal-Difference learning | Makes the model sensitive to success, failure, and subtle errors |
The paper reports that progress loss is used for the first 10k steps. TD learning is added for the remaining 40k steps. Total value-model training is about 50k steps for each task.
4. Self-improving loop
After warm-up, RISE runs the self-improving loop:
- Sample an initial state from the offline dataset.
- Prompt the rollout policy with an "optimal advantage" so it proposes a good action.
- Use the dynamics model to generate future multi-view states.
- Use the value model to score the actual advantage of that action.
- Discretize the advantage into 10 bins.
- Train the policy to generate the action under the evaluated advantage condition.
- Mix offline data back into training to avoid catastrophic forgetting.
One important detail: RISE does not need the world model to simulate all the way to a terminal state to obtain reward. It uses chunk-wise advantage for the current proposed action. Since generative video models accumulate error over long rollouts, the paper limits consecutive interaction from each offline state to at most two imagined steps.
Installing the repository
RISE has released training code and a pretrained dynamics model. The basic setup from the docs is:
git clone https://github.com/OpenDriveLab/RISE.git
cd RISE
conda create -n rise python=3.11.14 -y
conda activate rise
bash install.sh
install.sh installs several pieces:
| Component | Role |
|---|---|
policy_offline_and_value |
OpenPI-based offline policy and value training |
lerobot |
Robot dataset format and tooling |
rlinf[embodied] |
Online RL infrastructure |
mini_lerobot |
Lightweight data conversion utilities |
dynamics |
Dynamics model package |
torchcodec |
Video IO |
Because the paper uses large-scale training, a beginner should not expect to run the full pipeline on a laptop. The reported setup includes 16 NVIDIA H100 GPUs for dynamics pretraining for about seven days, 8 H100 GPUs for task-specific fine-tuning for about three days, and 8 GPUs for policy/value training. Still, the repository is useful for learning the structure, trying dynamics-model inference, or fine-tuning smaller task models on a lab dataset.
Preparing data
The training code expects LeRobot-style data. If you collect data on Piper in HDF5 format, the repository provides a conversion script:
cd policy_and_value/policy_offline_and_value
python examples/aloha_real/convert_to_lerobot.py \
--data-dir /path/to/raw_dataset \
--repo-ids aloha_mobile_dummy \
--prompt "Pick and sort bricks on the conveyor." \
--save-dir /path/to/lerobot_output_root \
--save_repoid brick_sorting_rise
Expected layout:
<dataset_name>/
├── data/chunk-000/episode_*.parquet
├── meta/
│ ├── info.json
│ ├── episodes.jsonl
│ ├── episodes_stats.jsonl
│ └── tasks.jsonl
└── videos/chunk-000/*.mp4
For the dynamics model, the docs recommend resizing videos to 256x192 for each view. RISE uses three views: one head view and two wrist views. This practical detail matters. If camera calibration, frame synchronization, or view naming is unstable, the dynamics model can learn the wrong motion, and the value model will score the wrong imagined future.
The paper reports this task-specific data:
| Task | Data in the paper |
|---|---|
| Dynamic Brick Sorting | 3063 human demonstrations, 610 policy rollouts |
| Backpack Packing | 2478 human demonstrations, 507 policy rollouts |
| Box Closing | 2286 human demonstrations, 524 policy rollouts, 540 DAgger corrections |
Training step by step
Step 1: Compute normalization statistics
From policy_and_value/policy_offline_and_value:
python scripts/compute_norm_stats_fast.py --config-name Compute_norm
Normalization matters because robot actions can have very different scales: joint angle, gripper command, Cartesian delta, velocity, or action token. If action normalization is wrong, the policy can learn the wrong action scale even with a strong image encoder.
Step 2: Train the offline policy and value model
bash train.sh Policy_offline_release 8
bash train.sh value_release 8
To resume:
bash train.sh Policy_offline_release 8 --resume
After obtaining a value checkpoint, label value and advantage for rollout data:
bash label_value.sh vis_value_release_joint_T /path/to/checkpoints/value_release_joint/<exp>/<step>
Conceptually, this turns the dataset from "observation, action" into "observation, action, estimated advantage." The policy then learns not only to imitate actions, but also to associate actions with high or low advantage bins.
Step 3: Train the dynamics model
Inside dynamics/dynamics_model, download the LTX backbone and pretrained dynamics model:
./download.sh
Pretrain if you have a large dataset:
bash train_task_centric.sh
Fine-tune for your own task:
python norm.py --datasets <your_finetune_dataset> --save-config data/utils/action_norm.json
bash task_finetune.sh
For a small lab, the practical path is to start from the pretrained RISE dynamics model, fine-tune for a small number of epochs, and carefully inspect qualitative rollouts. If video prediction does not follow action changes, the self-improving loop will learn from a misleading imagination.
Step 4: Online training in imagination
RISE uses an embodiment script:
bash policy_and_value/policy_online/examples/embodiment/run_embodiment.sh rl_release
The online training config lets you allocate GPUs across three components:
| Component | Role |
|---|---|
env |
Runs the world-model environment |
rollout |
Generates imagined rollouts |
actor |
Updates the policy |
Default-style placement:
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout: 4-7
actor: 0-7
The docs note that the first run can take about 10 minutes because it loads the dynamics and reward models and builds torch compile acceleration graphs. For debugging, you can disable actor.model.openpi.use_torch_compile.
Inference and deployment on Piper
The elegant part of RISE is that the world model is used only during training. At deployment time, the physical robot runs only the improved policy. The paper explicitly notes that the world model adds zero inference overhead.
Before deployment, convert the distributed checkpoint to a PyTorch state dict:
python toolkits/ckpt_convertor/convert_dcp_to_state_dict.py \
--dcp_path <YOUR_DCP_CKPT_DIR> \
--output_path <YOUR_EXPECTED_PT_CKPT_DIR>
The repository targets AgileX Piper dual-arm robots with Ubuntu 20.04, ROS Noetic, RealSense cameras, and an OpenPI policy server. On the robot side, run three terminals:
# Terminal 1: cameras
roslaunch realsense2_camera multi_camera.launch
# Terminal 2: robot arms
bash deploy/Piper_ros_private-ros-noetic/can_config.sh
roslaunch piper start_ms_piper.launch mode:=1 auto_enable:=true
# Terminal 3: inference
conda activate deploy
python deploy/piper_deploy.py \
--host 172.16.99.11 \
--port 8000 \
--ctrl_type joint \
--use_temporal_smoothing \
--chunk_size 50 \
--lang_embeddings "Pick and sort bricks on the conveyor."
For a beginner, the important point is that piper_deploy.py does not train anything. It receives camera observations, sends requests to the policy server, receives action chunks, and controls the robot. If the policy server, camera serials, ROS topics, or action scale are wrong, the behavior will be wrong even with a good checkpoint.

Main results
RISE is evaluated on three real tasks, with each result averaged over 20 autonomous trials. The table below is condensed from the paper:
| Method | Brick success | Backpack success | Box success |
|---|---|---|---|
| π0.5 | 35% | 30% | 35% |
| π0.5 + DAgger | 15% | 50% | 40% |
| π0.5 + PPO | 10% | 35% | 10% |
| π0.5 + DSRL | 10% | 10% | 10% |
| RECAP | 50% | 40% | 60% |
| RISE | 85% | 85% | 95% |
The abstract summarizes the absolute gains as more than +35% on dynamic brick sorting, +45% on backpack packing, and +35% on box closing. Notice that PPO and DSRL are not automatically better than imitation learning. In the paper, online adaptation can degrade performance, for example from 35% to 10% on brick sorting. This is a useful reminder: RL is not free. If reward, state distribution, or training stability is wrong, RL can damage a strong base policy.
RISE also includes important ablations:
| Ablation | Lesson |
|---|---|
| Best offline ratio is around 0.6 | Keeping enough offline data helps avoid catastrophic forgetting |
| Online action alone is not enough | Online states from the dynamics model expand the training distribution |
| Removing dynamics pretraining | Sorting accuracy drops sharply |
| Removing progress loss or TD learning | The value model becomes less sensitive to progress and failure |
In dynamics-model evaluation, RISE reports PSNR 23.90, LPIPS 0.07, SSIM 0.82, FVD 66.84, and EPE 0.54 on real-world tasks, outperforming key variants on motion controllability. Low EPE is especially important because it reflects action-conditioned motion, not just video appearance.
How beginners should read RISE
If you are new to robot learning, do not start by training full RISE. Read it in this order:
- Understand imitation learning: the policy learns
observation -> actionfrom demonstrations. - Understand exposure bias: when the robot drifts from demonstrations, the policy lacks recovery behavior.
- Understand value and advantage: actions better than average should become more likely.
- Understand world models: a model predicts future state given action.
- Understand RISE: use a world model to create on-policy-like data in imagination.
A simple mental model:
Imitation learning: "do what the human did"
Real-world RL: "try on the robot, receive reward, improve"
RISE: "try in the world model, score with a value model, deploy the improved policy"
RISE does not replace traditional simulators. It adds a learned layer from real data, which is especially useful when the task is too hard to hand-model in a physics engine but you have enough camera/action logs to learn dynamics.
When should a lab try RISE?
RISE is a fit when you have:
| Requirement | Why it matters |
|---|---|
| Stable multi-view cameras | The dynamics model needs consistent observations |
| Synchronized action logs | The model must know which action caused which motion |
| Data with success and failure | The value model must distinguish real progress |
| Strong GPUs | Video diffusion and online RL are heavy |
| Contact-rich robot tasks | This is where imitation-only policies often struggle |
RISE is not the best first step if you only have a few dozen episodes, unsynchronized cameras, or a simple static pick-and-place task. In that situation, LeRobot plus imitation learning or a basic diffusion policy will be easier to debug.
Conclusion
RISE is important because it does more than say "world models for robots" at the idea level. The repository includes structure for offline policy/value training, an action-conditioned dynamics model, online RL in imagination, and Piper deployment. The paper also demonstrates gains on real tasks rather than only simulation benchmarks.
The engineering message is direct: a self-improving robot policy does not necessarily need thousands of risky real-world trials. With good camera/action data, you can learn a fast imagination environment, use a value model to produce denser advantage signals than terminal success, and improve the policy before sending it back to real hardware.