ACoT-VLA là gì?
ACoT-VLA, viết tắt của Action Chain-of-Thought for Vision-Language-Action Models, là một hướng mới cho robot manipulation policy: thay vì để model "suy nghĩ" bằng text plan hoặc goal image, model tạo ra một chuỗi ý định hành động thô trong chính action space. Paper gốc của Linqing Zhong và cộng sự, Beihang University và AgiBot, được đăng trên arXiv ngày 16/01/2026, cập nhật v2 ngày 30/03/2026, và có bản CVPR 2026 open-access tại CVF. Repo chính thức là AgibotTech/ACoT-VLA.
Nếu bạn đã học VLA models cơ bản, LeRobot hands-on, hoặc OpenVLA, ACoT-VLA trả lời một câu hỏi rất thực tế: làm sao để VLA không chỉ hiểu instruction, mà còn có hướng dẫn hành động đủ gần với kinematics để điều khiển robot ổn định hơn?
Trong VLA truyền thống, pipeline thường là:
image + language instruction
|
v
pretrained VLM embeddings
|
v
action head
|
v
robot action chunk
Pipeline này mạnh vì tận dụng vision-language pretraining, nhưng nó có một khoảng cách lớn: VLM hiểu scene ở mức semantic, còn robot cần action liên tục ở mức kinematic. Một câu như "wipe the stain" nói rõ mục tiêu, nhưng không nói rõ end-effector nên đi theo quỹ đạo nào, tiếp xúc ra sao, mở gripper lúc nào, hoặc giữ hướng cổ tay thế nào. Paper gọi vấn đề này là semantic-kinematic gap.
ACoT-VLA thêm một tầng "suy nghĩ bằng action" trước khi action head sinh lệnh cuối:
image + instruction
|
v
VLM backbone
|
+--------------------+
| |
v v
Explicit Action Reasoner Implicit Action Reasoner
(coarse trajectory) (latent action priors)
| |
+---------+----------+
|
v
Action-Guided Prediction
|
v
final robot action chunk
Nói ngắn gọn: ACoT-VLA không bắt robot viết ra "bước 1, bước 2" bằng text. Nó bắt robot tạo một reference action trajectory thô và trích xuất action priors từ nội bộ VLM, sau đó dùng hai tín hiệu này để điều kiện hóa action head.
Vì sao action chain-of-thought quan trọng?
Chain-of-thought trong LLM thường là chuỗi lý luận bằng ngôn ngữ. Trong robotics, nhiều hướng trước ACoT-VLA cũng thêm intermediate reasoning: sub-task bằng text, visual affordance, hoặc goal image. Các tín hiệu này hữu ích, nhưng vẫn gián tiếp. Một goal image cho robot biết cảnh mong muốn trông như thế nào, không nhất thiết cho biết motor command nên đi như thế nào trong 10 bước kế tiếp.
ACoT-VLA đổi đơn vị suy luận từ language/vision sang action. Với robot manipulation, đây là khác biệt lớn:
| Kiểu reasoning | Ví dụ output | Ưu điểm | Hạn chế |
|---|---|---|---|
| Text CoT | "move to sponge, grasp, wipe stain" | Dễ hiểu, tốt cho task structure | Xa action space, khó biểu diễn contact và timing |
| Visual subgoal | Goal image hoặc affordance map | Gần perception, hữu ích cho object target | Vẫn cần policy suy ra trajectory |
| Action CoT | Coarse action trajectory | Gần kinematics, có thể guide action head trực tiếp | Cần action-format data và model head phù hợp |
Beginner nên hiểu "coarse action intent" như một bản nháp motion. Nó không nhất thiết là lệnh cuối cùng gửi xuống robot. Nó giống một trajectory tham chiếu để model biết nên di chuyển theo kiểu nào: tiến tới object, hạ xuống, đóng gripper, nâng lên, dịch sang cup, nghiêng cổ tay, hoặc quay về pose an toàn. Action head cuối vẫn chịu trách nhiệm tạo action chính xác hơn.
Kiến trúc ACoT-VLA
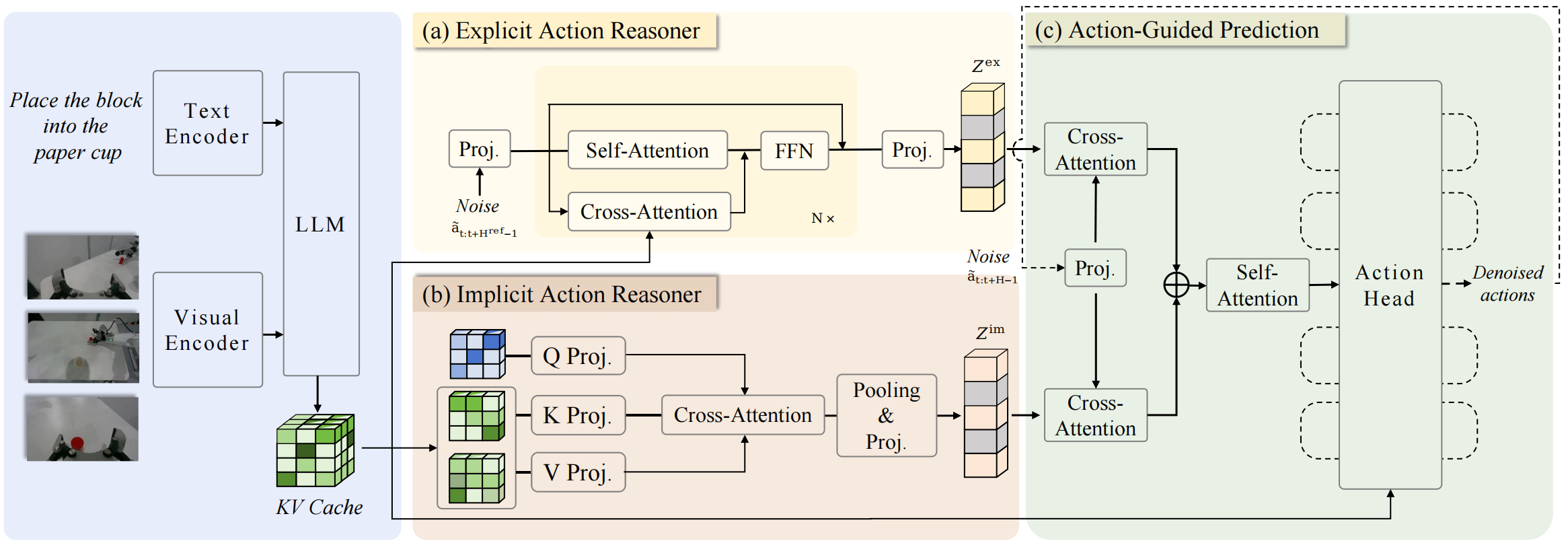
Paper chia kiến trúc thành ba phần chính: Explicit Action Reasoner (EAR), Implicit Action Reasoner (IAR) và Action-Guided Prediction (AGP). Repo chính thức mô tả EAR và IAR cùng tạo thành Action Chain-of-Thought, giúp robot "think in the language of actions".
1. VLM backbone
ACoT-VLA vẫn bắt đầu giống các VLA hiện đại: input gồm camera observation và language instruction. VLM backbone mã hóa scene và instruction thành hidden states, key cache và value cache. Các representation này chứa thông tin object, relation, affordance và task semantics.
Điểm cần nhớ: ACoT-VLA không thay VLM bằng một planner rời. Nó vẫn dùng VLM làm nền, nhưng thêm các module lấy action signal từ representation của VLM.
Observation cameras: front / wrist / third-person
Robot state: joint positions, gripper, optionally EEF pose
Instruction: "pick up the blue doll"
|
v
VLM tokens + KV cache
2. EAR: Explicit Action Reasoner
EAR là module tạo coarse reference trajectory. Theo paper, EAR là Transformer-based module được train bằng flow matching để sinh ra một chuỗi action tham chiếu. Chuỗi này có horizon riêng, ký hiệu trong paper là H_ref, và được chuyển qua MLP projector thành explicit action embedding.
Hãy tách thành các bước dễ hiểu:
- Lấy multimodal representation từ VLM.
- Tạo một noisy action segment.
- Dùng flow matching / denoising để biến noisy segment thành reference action trajectory.
- Project trajectory đó thành embedding
Z_ex. - Dùng
Z_exlàm explicit guidance cho action head cuối.
Pseudo-code ở mức ý tưởng:
# Không phải code nguyên văn repo, chỉ minh họa luồng tính toán.
vlm_features = vlm.encode(images, instruction)
noisy_ref_actions = sample_noise(shape=(H_ref, action_dim))
ref_actions = explicit_action_reasoner.denoise(
noisy_ref_actions,
keys=vlm_features.k_cache,
values=vlm_features.v_cache,
)
explicit_guidance = mlp_projector(ref_actions)
Vì sao không dùng luôn ref_actions làm lệnh robot? Vì nó là trajectory thô. Nó có thể nắm được hướng di chuyển và thứ tự intent, nhưng action cuối cần kết hợp thêm observation hiện tại, implicit priors, normalization, action scale và control convention của robot.
3. IAR: Implicit Action Reasoner
IAR trích xuất latent action priors từ key-value cache của VLM. Paper chỉ ra rằng multimodal latent space của VLM đã chứa cue liên quan đến motion: affordance, object relation, vùng có thể thao tác, hoặc semantic liên quan đến grasp/pour/wipe.
Cách IAR làm việc:
- Với từng layer VLM, tạo learnable query matrix.
- Downsample key-value cache để giảm redundancy và chi phí tính toán.
- Dùng cross-attention giữa learnable queries và KV cache đã downsample.
- Pool kết quả và đưa qua MLP.
- Aggregate qua nhiều layer để tạo implicit guidance
Z_im.
Sơ đồ:
VLM layer i KV cache
|
v
downsample K, V
|
learnable queries --cross-attention-->
|
v
pool + MLP
|
v
implicit action feature z_i
IAR không xuất ra trajectory rõ ràng như EAR. Nó là tín hiệu ngầm: "trong representation này có pattern hành vi nào phù hợp với task hiện tại?" Paper báo cáo chiến lược downsample KV cache cho IAR tốt hơn các biến thể đơn giản hơn, gợi ý rằng KV cache có nhiều thông tin dư thừa đối với action prediction.
4. AGP: Action-Guided Prediction
Action-Guided Prediction là nơi EAR và IAR gặp action head cuối. Thay vì đưa noisy action embedding trực tiếp vào action head, ACoT-VLA dùng noisy action như query để tương tác với explicit guidance và implicit guidance. Kết quả là action head không chỉ nhìn image/language feature, mà còn được dẫn bởi "bản nháp hành động" và "behavioral priors".
noisy action query
|
+--> attend explicit guidance from EAR
|
+--> attend implicit guidance from IAR
|
v
flow-matching action head
|
v
final action chunk
Nếu bạn từng train Diffusion Policy hoặc Pi0-style flow matching action head, hãy nghĩ AGP như một cách làm giàu conditioning cho denoising process. Model không còn phải tự suy ra tất cả motion structure từ image-language embedding trong một bước.
LeRobot-format data cần chuẩn bị gì?
Repo ACoT-VLA ghi rõ dataset được xử lý sang LeRobot format, với script ví dụ:
python examples/libero/convert_libero_data_to_lerobot.py
LeRobot format là lựa chọn hợp lý vì nó chuẩn hóa robot learning data thành các episode có observation, action, timestamp, task metadata và video. Tài liệu LeRobot v3 mô tả ba trụ cột: tabular data như state/action/timestamp trong Apache Parquet, visual data trong MP4 theo camera, và metadata mô tả schema, FPS, stats, task và episode boundaries. Với v2.1, layout thường gần hơn với data/chunk-xxx/episode_xxxxxx.parquet và video theo episode; với v3, nhiều episode được gom thành shard lớn hơn. Dù version nào, tư duy vẫn giống nhau: mỗi frame phải khớp thời gian giữa image, state, action và instruction.
Một dataset tối thiểu cho ACoT-VLA-style training nên có:
| Field | Ý nghĩa | Ví dụ shape |
|---|---|---|
observation.images.front |
ảnh camera chính | [3, H, W] hoặc video frame |
observation.images.wrist |
ảnh wrist camera, nếu có | [3, H, W] |
observation.state |
joint/EEF/gripper state | [state_dim] |
action |
action target tại frame | [action_dim] |
timestamp |
thời gian frame | scalar |
episode_index |
episode id | int |
frame_index |
frame trong episode | int |
task_index |
map tới instruction | int |
| task text | câu lệnh tự nhiên | "pour water into the cup" |
Điểm beginner hay sai là action convention. ACoT-VLA paper dùng các convention khác nhau theo benchmark:
| Setting | Action space | Horizon | State input |
|---|---|---|---|
| LIBERO / LIBERO-Plus | Delta EEF | 10 | không dùng privileged state |
| VLABench | Absolute EEF | theo benchmark | có state input |
| Real-world AgiBot G1 / AgileX | Absolute Joint | 30 | có structured robot state |
Vì vậy, trước khi train, bạn phải quyết định rõ action_dim nghĩa là gì. Một vector 7D có thể là delta end-effector pose cộng gripper, nhưng cũng có thể là joint target cho một tay robot. Nếu dataset và config hiểu khác nhau, loss vẫn giảm nhưng policy có thể điều khiển sai hoàn toàn.
Cài đặt repo chính thức
Tại thời điểm bài viết ngày 08/06/2026, repo chính thức đã có hướng dẫn cài đặt, convert LIBERO sang LeRobot, compute normalization stats, train và launch policy server. README cũng có TODO cho một số phần như release core EAR/IAR modules, inference code, configs và checkpoints, nên bạn nên kiểm tra repo trước khi chạy production.
Các lệnh cài đặt từ repo:
git clone https://github.com/AgibotTech/ACoT-VLA.git
cd ACoT-VLA
git submodule update --init --recursive
# Repo dùng uv để quản lý environment.
GIT_LFS_SKIP_SMUDGE=1 uv sync
GIT_LFS_SKIP_SMUDGE=1 uv pip install -e .
Nếu bạn mới dùng uv, hãy coi nó như công cụ tạo environment và install package nhanh hơn pip/venv truyền thống. Bạn vẫn cần CUDA, PyTorch tương thích GPU và đủ VRAM. Với VLA training, cấu hình thực tế thường cần GPU 24GB trở lên cho fine-tune nhỏ; nhiều GPU hoặc A100/H100 sẽ thoải mái hơn cho full training.
Kiểm tra môi trường:
uv run python - <<'PY'
import torch
print("cuda:", torch.cuda.is_available())
if torch.cuda.is_available():
print("gpu:", torch.cuda.get_device_name(0))
PY
Chuyển dữ liệu sang LeRobot format
Với LIBERO, repo cung cấp script:
python examples/libero/convert_libero_data_to_lerobot.py
Với custom robot data, bạn cần viết converter riêng. Logic cơ bản là:
# Pseudo-code: minh họa mapping, không thay thế API chính thức từng version.
for episode in raw_episodes:
instruction = episode.task_text
for t, frame in enumerate(episode.frames):
sample = {
"observation.images.front": frame.front_rgb,
"observation.images.wrist": frame.wrist_rgb,
"observation.state": frame.robot_state.astype("float32"),
"action": frame.action.astype("float32"),
"timestamp": frame.timestamp,
"frame_index": t,
"episode_index": episode.index,
"task_index": task_to_id[instruction],
}
dataset.add_frame(sample)
dataset.save_episode()
dataset.finalize()
Checklist trước khi train:
| Kiểm tra | Lý do |
|---|---|
| FPS cố định | Action horizon 10 hoặc 30 phụ thuộc vào thời gian thực |
| Image/action sync | Lệch 1-2 frame có thể làm policy học sai contact |
| Action scale | Delta pose phải normalize khác absolute joint |
| Gripper encoding | 0/1, -1/1, hoặc width mm phải nhất quán |
| Episode end | Không để action sau khi task đã xong kéo dài quá nhiều |
| Task text | Cùng task nên có câu lệnh nhất quán, nhưng có thể augment paraphrase |
Một kiểm tra rất hữu ích là visualize vài episode:
from lerobot.datasets import LeRobotDataset
dataset = LeRobotDataset("your-org/your-acot-dataset")
sample = dataset[100]
print(sample.keys())
print(sample["observation.state"].shape)
print(sample["action"].shape)
print(sample["timestamp"])
Nếu bạn dùng v3, LeRobot docs cho phép load dataset với delta_timestamps để lấy window ảnh quanh frame hiện tại. Điều này hữu ích khi policy cần temporal context:
delta_timestamps = {
"observation.images.front": [-0.2, -0.1, 0.0],
"observation.images.wrist": [-0.2, -0.1, 0.0],
}
dataset = LeRobotDataset("your-org/your-dataset", delta_timestamps=delta_timestamps)
Training pipeline
Repo chính thức đưa ra pipeline chuẩn:
# 1. Compute normalization statistics
uv run scripts/compute_norm_stats.py --config-name <CONFIG_NAME>
# 2. Start training
bash scripts/train.sh <CONFIG_NAME> <EXP_NAME>
compute_norm_stats.py rất quan trọng. Robot actions và states có scale khác nhau: joint radian, gripper width, EEF delta mét, rotation radian, image pixel. Nếu action normalization sai, flow matching head sẽ học phân phối khó hoặc bị dominated bởi dimension có range lớn.
Một config training ACoT-VLA nên làm rõ:
dataset:
repo_id: your-org/your-dataset
fps: 30
image_keys:
- observation.images.front
- observation.images.wrist
state_key: observation.state
action_key: action
policy:
backbone: pretrained_vlm
action_dim: 7
action_horizon: 10
reference_horizon: 10
use_ear: true
use_iar: true
freeze_llm_backbone: true
optimization:
global_batch_size: 128
max_steps: 40000
lr: 1.0e-4
precision: bf16
Các con số trên là template để beginner hiểu ý nghĩa config, không phải đảm bảo tối ưu cho mọi robot. Paper dùng global batch size 128. Trong supplementary, LIBERO train 40K steps, LIBERO-Plus 100K steps, VLABench 60K steps; real-world tasks train 50K, 240K và 50K steps tùy task. Nếu bạn có ít dữ liệu hơn, nên bắt đầu bằng frozen VLM backbone và train action modules trước.
Quan sát training:
| Metric | Diễn giải |
|---|---|
| action denoising loss | loss chính của action head / flow matching |
| EAR loss | reference trajectory có học được phân phối action không |
| validation rollout success | metric quan trọng hơn loss nếu có simulator |
| action magnitude | phát hiện policy phát lệnh quá lớn hoặc quá nhỏ |
| gripper accuracy | thường quyết định success trong pick/place |
Với manipulation, đừng chỉ nhìn loss. Hãy replay predicted action trên dữ liệu validation hoặc trong simulator. Một policy có loss đẹp vẫn có thể fail vì gripper đóng muộn 200 ms hoặc EEF hover quá cao.
Inference và deploy
Repo hướng dẫn launch policy server:
bash scripts/server.sh <GPU_ID> <PORT>
Một vòng inference điển hình:
robot cameras + state
|
v
preprocess: resize, normalize, pack prompt
|
v
ACoT-VLA policy server
|
v
action chunk: [a_t, a_{t+1}, ..., a_{t+H-1}]
|
v
client executes first k actions, then replans
Pseudo-code client:
while robot.is_running():
obs = {
"images": {
"front": front_camera.read(),
"wrist": wrist_camera.read(),
},
"state": robot.get_state(),
"instruction": current_instruction,
}
action_chunk = policy_client.predict(obs)
for action in action_chunk[:recede_steps]:
robot.send_action(action)
sleep(control_dt)
Một số lưu ý triển khai:
| Vấn đề | Khuyến nghị |
|---|---|
| Latency | Dùng receding horizon: predict chunk dài, execute vài step đầu |
| Safety | Clamp joint velocity, EEF delta và gripper command |
| Camera shift | Calibrate camera pose, hoặc augment camera viewpoint trong training |
| Contact-rich task | Giới hạn force/torque, thêm stop condition nếu có F/T sensor |
| Instruction mismatch | Log instruction string chính xác đã dùng khi collect data |
Với ACoT-VLA, inference có thể tốn hơn baseline action head vì thêm EAR/IAR. Đổi lại, paper cho thấy robustness tốt hơn dưới perturbation. Với robot thật, bạn nên đo end-to-end latency, không chỉ model forward time: camera capture, JPEG/MP4 decode, resize, network RPC, robot controller cycle đều góp phần vào delay.
Kết quả trong paper
Paper đánh giá trên LIBERO, LIBERO-Plus, VLABench và real-world AgiBot G1 / AgileX. Các kết quả chính:
| Benchmark | Kết quả nổi bật |
|---|---|
| LIBERO | Baseline 96.9% avg, EAR+IAR đạt 98.5% avg trong ablation |
| LIBERO-Plus Zero-Shot | ACoT-VLA đạt 86.6% avg, cao hơn các baseline được so sánh trong README |
| LIBERO-Plus SFT | ACoT-VLA đạt 88.0% avg; bản frozen đạt 84.1% |
| VLABench | ACoT-VLA frozen đạt 63.5 IS / 47.4 PS avg, tốt nhất trong bảng so sánh của paper |
| Real-world | ACoT-VLA đạt 66.7% average success, so với 61.0% của Pi0.5 và 33.8% của Pi0 |
LIBERO-Plus đặc biệt đáng chú ý vì nó không chỉ test task chuẩn mà còn test 7 dạng distribution shift: camera viewpoint, robot initial state, language variations, lighting, background, sensor noise và object layout. Đây là đúng loại stress test mà robot thực tế gặp thường xuyên.
Ablation cũng quan trọng:
| Module | Ý nghĩa | LIBERO avg |
|---|---|---|
| Baseline | action head không có EAR/IAR | 96.9 |
| EAR only | thêm explicit reference trajectory | 98.3 |
| IAR only | thêm implicit action priors | 98.1 |
| EAR + IAR | kết hợp cả hai | 98.5 |
Thông điệp không phải là "ACoT-VLA luôn thắng mọi model". Thông điệp kỹ thuật là explicit trajectory guidance và implicit action cue có tính bổ sung. EAR giúp policy có motion scaffold rõ ràng; IAR giúp khai thác action-relevant semantics sẵn có trong VLM.
Khi nào nên dùng ACoT-VLA?
ACoT-VLA phù hợp khi bạn có một trong các nhu cầu sau:
| Nhu cầu | ACoT-VLA có hợp không? |
|---|---|
| Long-horizon tabletop manipulation | Có |
| Task có language variation | Có |
| Contact-rich như wiping/pouring | Có, nhưng cần safety layer |
| Dataset đã ở LeRobot format | Rất hợp |
| Chỉ cần single-task pick/place đơn giản | Có thể quá nặng |
| Edge inference trên GPU nhỏ | Cần benchmark latency trước |
Nếu bạn mới bắt đầu robot learning, nên học pipeline nhỏ trước: ACT hoặc Diffusion Policy trên một task, sau đó LeRobot-format data, rồi VLA fine-tuning. ACoT-VLA đáng học khi bạn đã hiểu action chunking, normalization, camera sync và evaluation rollout.
Lộ trình thực hành cho beginner
Một lộ trình ít rủi ro:
- Đọc paper và README để nắm EAR/IAR/AGP.
- Chạy converter LIBERO sang LeRobot format.
- Load dataset bằng
LeRobotDataset, kiểm tra keys, shape, FPS. - Compute normalization stats.
- Train baseline config trước, không bật cả biến thể phức tạp ngay.
- Bật EAR only, so sánh validation rollout.
- Bật IAR, sau đó EAR+IAR.
- Chạy inference server trong simulator.
- Chỉ deploy robot thật khi action clamp, emergency stop và workspace boundary đã sẵn sàng.
Nguồn nên đọc:
| Nguồn | Link |
|---|---|
| Paper arXiv | arxiv.org/abs/2601.11404 |
| CVPR 2026 PDF | openaccess.thecvf.com |
| Supplemental | CVPR supplemental PDF |
| Official repo | github.com/AgibotTech/ACoT-VLA |
| LeRobot dataset v3 docs | github.com/huggingface/lerobot |