What is ACoT-VLA?
ACoT-VLA stands for Action Chain-of-Thought for Vision-Language-Action Models. It is a new robot manipulation policy design that moves reasoning closer to the robot's control space. Instead of asking a VLA model to reason only through text plans or goal images, ACoT-VLA makes the model generate a structured chain of coarse action intents and use that chain to guide the final action head.
The original paper by Linqing Zhong and collaborators from Beihang University and AgiBot appeared on arXiv on January 16, 2026, with v2 posted on March 30, 2026. The CVPR 2026 paper is available through CVF Open Access, and the official implementation is AgibotTech/ACoT-VLA.
If you already understand basic VLA models, have tried LeRobot hands-on, or have read the OpenVLA deep dive, ACoT-VLA is the next question: how can a VLA model produce actions that are not only semantically correct, but also better grounded in robot kinematics?
A common VLA pipeline looks like this:
image + language instruction
|
v
pretrained VLM embeddings
|
v
action head
|
v
robot action chunk
This works because pretrained vision-language models carry strong object, scene, and language representations. The weak point is the gap between semantic understanding and low-level control. A sentence such as "wipe the stain" tells the policy the goal, but it does not directly specify the end-effector path, contact timing, wrist orientation, gripper state, or recovery motion. The ACoT-VLA paper calls this the semantic-kinematic gap.
ACoT-VLA inserts action-level reasoning before the final action prediction:
image + instruction
|
v
VLM backbone
|
+--------------------+
| |
v v
Explicit Action Reasoner Implicit Action Reasoner
(coarse trajectory) (latent action priors)
| |
+---------+----------+
|
v
Action-Guided Prediction
|
v
final robot action chunk
In plain terms, ACoT-VLA does not make the robot write a textual step-by-step plan. It makes the robot produce an action-space draft and extracts action priors from the VLM's internal activations, then uses both signals to condition the final action head.
Why action chain-of-thought matters
Chain-of-thought in language models usually means reasoning in words. Robotics has borrowed the idea in several ways: predicting sub-tasks in language, generating goal images, producing affordance maps, or using world-model rollouts. These signals can help, but they remain indirect. A goal image tells the policy what the world should look like after success; it does not necessarily tell the controller how to move over the next ten steps.
ACoT-VLA changes the reasoning unit from language or images to actions:
| Reasoning type | Example output | Strength | Limitation |
|---|---|---|---|
| Text CoT | "move to sponge, grasp, wipe stain" | Easy to inspect, good for task structure | Far from control, weak at contact and timing |
| Visual subgoal | Goal image or affordance map | Close to perception, useful for target selection | Still needs a policy to infer trajectory |
| Action CoT | Coarse action trajectory | Close to kinematics, directly useful for action prediction | Requires action-format data and a suitable action head |
For a beginner, the easiest way to understand a coarse action intent is to treat it as a motion draft. It is not necessarily the exact command sent to the robot. It gives the model a scaffold: approach the object, descend, close the gripper, lift, translate to the target, rotate the wrist, or return to a stable pose. The final action head still produces the precise action chunk.
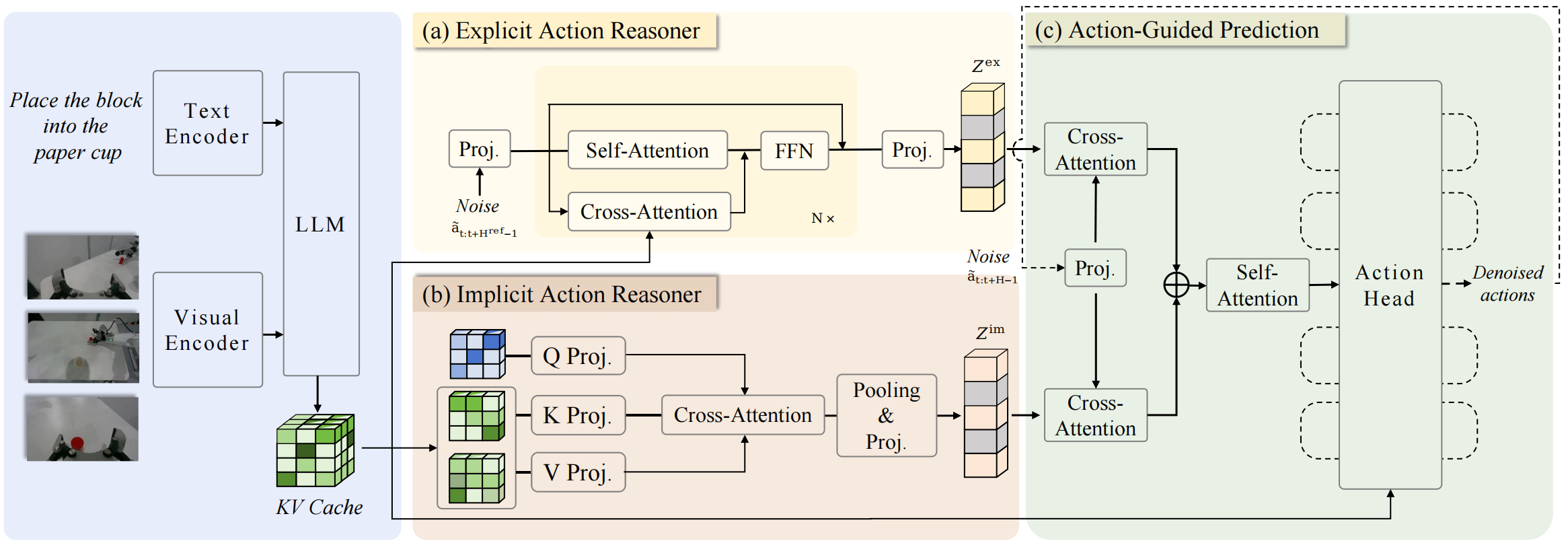
Architecture overview
The paper has three key components: Explicit Action Reasoner (EAR), Implicit Action Reasoner (IAR), and Action-Guided Prediction (AGP). The official repository describes EAR and IAR as the two parts that jointly form Action Chain-of-Thought, allowing the robot to "think" in the language of actions.
1. VLM backbone
ACoT-VLA still begins like many modern VLA policies: the input is a camera observation plus a natural-language instruction. A VLM backbone encodes the scene and instruction into hidden states, key cache, and value cache. These representations contain object information, relations, affordances, and task semantics.
The important point is that ACoT-VLA does not replace the VLM with a separate symbolic planner. It keeps the VLM as the multimodal foundation and adds modules that extract action-level signals from the VLM representations.
Observation cameras: front / wrist / third-person
Robot state: joint positions, gripper, optionally EEF pose
Instruction: "pick up the blue doll"
|
v
VLM tokens + KV cache
2. EAR: Explicit Action Reasoner
EAR generates a coarse reference trajectory. According to the paper, it is a Transformer-based module trained with flow matching to synthesize a reference action sequence. The sequence has its own horizon, called H_ref in the paper, and is projected by an MLP into an explicit action embedding.
Break it down into five steps:
- Encode image and instruction with the VLM.
- Create a noisy action segment.
- Use flow matching / denoising to turn the noisy segment into a reference trajectory.
- Project that trajectory into an embedding
Z_ex. - Use
Z_exas explicit guidance for the final action head.
Conceptual pseudo-code:
# This is not copied from the repo. It illustrates the data flow.
vlm_features = vlm.encode(images, instruction)
noisy_ref_actions = sample_noise(shape=(H_ref, action_dim))
ref_actions = explicit_action_reasoner.denoise(
noisy_ref_actions,
keys=vlm_features.k_cache,
values=vlm_features.v_cache,
)
explicit_guidance = mlp_projector(ref_actions)
Why not execute ref_actions directly? Because they are intentionally coarse. They capture motion direction and intent order, but the final action must also account for current observation, implicit priors, normalization, action scale, and the robot's control convention.
3. IAR: Implicit Action Reasoner
IAR extracts latent action priors from the VLM's key-value cache. The paper argues that the VLM's multimodal latent space already contains motion-related cues: affordances, object relations, graspable regions, and semantic patterns associated with actions such as pouring, wiping, placing, or picking.
The IAR process is:
- For each VLM layer, initialize learnable query matrices.
- Downsample the key-value cache to reduce redundancy and compute.
- Apply cross-attention between learnable queries and the downsampled cache.
- Pool the result and pass it through an MLP.
- Aggregate layer-wise features into implicit guidance
Z_im.
Diagram:
VLM layer i KV cache
|
v
downsample K, V
|
learnable queries --cross-attention-->
|
v
pool + MLP
|
v
implicit action feature z_i
IAR does not output an explicit trajectory. It gives the policy a compact behavioral prior: "given this scene and instruction, what action-relevant patterns are already encoded inside the VLM?" In the paper's analysis, downsampling the KV cache works better than simpler alternatives, suggesting that the cache contains redundant information for action prediction.
4. AGP: Action-Guided Prediction
Action-Guided Prediction is where EAR and IAR meet the final action head. Instead of feeding a noisy action embedding directly into the action head, ACoT-VLA treats the noisy action as a query that interacts with explicit and implicit guidance. The final head is therefore conditioned not only on image-language features, but also on a motion draft and latent behavioral priors.
noisy action query
|
+--> attend explicit guidance from EAR
|
+--> attend implicit guidance from IAR
|
v
flow-matching action head
|
v
final action chunk
If you have trained Diffusion Policy or a Pi0-style flow matching action head, think of AGP as richer conditioning for the denoising process. The model no longer needs to infer the whole motion structure from image-language embeddings alone.
What LeRobot-format data should contain
The official ACoT-VLA README states that datasets are processed into LeRobot format, and shows this LIBERO conversion command:
python examples/libero/convert_libero_data_to_lerobot.py
LeRobot format is useful because it standardizes robot learning demonstrations into episodes with observations, actions, timestamps, task metadata, and video. The LeRobot v3 documentation describes three pillars: tabular data such as state/action/timestamp stored in Apache Parquet, visual data stored as MP4 per camera, and metadata describing schema, FPS, statistics, tasks, and episode boundaries. Older v2.1 datasets often use one Parquet file per episode, while v3 aggregates many episodes into larger shards. In both cases, the key requirement is the same: every frame must align image, state, action, and instruction.
A minimal ACoT-VLA-style dataset should include:
| Field | Meaning | Example shape |
|---|---|---|
observation.images.front |
main camera image | [3, H, W] or video frame |
observation.images.wrist |
wrist camera image, if available | [3, H, W] |
observation.state |
joint, EEF, or gripper state | [state_dim] |
action |
target action for the frame | [action_dim] |
timestamp |
frame time | scalar |
episode_index |
episode id | int |
frame_index |
frame inside episode | int |
task_index |
index mapped to task text | int |
| task text | natural-language instruction | "pour water into the cup" |
The most common beginner mistake is mixing action conventions. The paper uses different conventions across settings:
| Setting | Action space | Horizon | State input |
|---|---|---|---|
| LIBERO / LIBERO-Plus | Delta EEF | 10 | no privileged state |
| VLABench | Absolute EEF | benchmark convention | state input |
| Real-world AgiBot G1 / AgileX | Absolute Joint | 30 | structured robot state |
Before training, define exactly what action_dim means. A 7D vector might be delta end-effector pose plus gripper, but it might also be a subset of joint targets. If the dataset and model config interpret the vector differently, the loss may still decrease while the robot executes nonsense.
Installing the official repository
As of June 8, 2026, the official repository includes commands for installation, LIBERO-to-LeRobot conversion, normalization-stat computation, training, and launching a policy server. The README also lists TODO items such as releasing core EAR/IAR training modules, inference code, training configurations, and checkpoints, so check the repository state before depending on it for production.
Installation commands from the repo:
git clone https://github.com/AgibotTech/ACoT-VLA.git
cd ACoT-VLA
git submodule update --init --recursive
# The repo uses uv for Python environment management.
GIT_LFS_SKIP_SMUDGE=1 uv sync
GIT_LFS_SKIP_SMUDGE=1 uv pip install -e .
If you are new to uv, treat it as a fast environment and package manager. You still need CUDA, a compatible PyTorch build, and enough VRAM. For VLA work, a 24GB GPU can be enough for small fine-tuning experiments, while multi-GPU or A100/H100-class hardware is more comfortable for large runs.
Verify the environment:
uv run python - <<'PY'
import torch
print("cuda:", torch.cuda.is_available())
if torch.cuda.is_available():
print("gpu:", torch.cuda.get_device_name(0))
PY
Converting data to LeRobot format
For LIBERO, use the converter provided by the ACoT-VLA repo:
python examples/libero/convert_libero_data_to_lerobot.py
For custom robot data, you need your own converter. The basic mapping is:
# Pseudo-code: illustrates the mapping, not a stable API for every LeRobot version.
for episode in raw_episodes:
instruction = episode.task_text
for t, frame in enumerate(episode.frames):
sample = {
"observation.images.front": frame.front_rgb,
"observation.images.wrist": frame.wrist_rgb,
"observation.state": frame.robot_state.astype("float32"),
"action": frame.action.astype("float32"),
"timestamp": frame.timestamp,
"frame_index": t,
"episode_index": episode.index,
"task_index": task_to_id[instruction],
}
dataset.add_frame(sample)
dataset.save_episode()
dataset.finalize()
Pre-training checklist:
| Check | Why it matters |
|---|---|
| Fixed FPS | A horizon of 10 or 30 steps has real-time meaning |
| Image/action sync | A 1-2 frame offset can ruin contact learning |
| Action scale | Delta pose and absolute joint targets need different normalization |
| Gripper encoding | 0/1, -1/1, or width in mm must be consistent |
| Episode end | Long idle tails after success can bias the policy |
| Task text | Same task should be consistent; paraphrases can be added deliberately |
Visualize and inspect a few episodes before training:
from lerobot.datasets import LeRobotDataset
dataset = LeRobotDataset("your-org/your-acot-dataset")
sample = dataset[100]
print(sample.keys())
print(sample["observation.state"].shape)
print(sample["action"].shape)
print(sample["timestamp"])
If you use LeRobot v3, the docs show delta_timestamps for loading temporal windows around the current frame. This is useful when the policy needs short history:
delta_timestamps = {
"observation.images.front": [-0.2, -0.1, 0.0],
"observation.images.wrist": [-0.2, -0.1, 0.0],
}
dataset = LeRobotDataset("your-org/your-dataset", delta_timestamps=delta_timestamps)
Training pipeline
The official repo presents this standard pipeline:
# 1. Compute normalization statistics
uv run scripts/compute_norm_stats.py --config-name <CONFIG_NAME>
# 2. Start training
bash scripts/train.sh <CONFIG_NAME> <EXP_NAME>
The normalization step is not optional. Robot states and actions live on different scales: joint radians, gripper width, end-effector delta in meters, rotations, image pixels, and sometimes force signals. Without correct normalization, the flow matching head learns a poorly conditioned distribution, and one large-range dimension can dominate the loss.
A clear training config should make the following decisions explicit:
dataset:
repo_id: your-org/your-dataset
fps: 30
image_keys:
- observation.images.front
- observation.images.wrist
state_key: observation.state
action_key: action
policy:
backbone: pretrained_vlm
action_dim: 7
action_horizon: 10
reference_horizon: 10
use_ear: true
use_iar: true
freeze_llm_backbone: true
optimization:
global_batch_size: 128
max_steps: 40000
lr: 1.0e-4
precision: bf16
These values are a template for understanding the knobs, not a universal recipe. The supplementary material reports global batch size 128. LIBERO is trained for 40K steps, LIBERO-Plus for 100K, VLABench for 60K, and the real-world tasks for 50K, 240K, and 50K steps depending on the task. If your dataset is small, start by freezing the VLM backbone and training the action modules.
Monitor more than one metric:
| Metric | Interpretation |
|---|---|
| action denoising loss | main action head / flow matching signal |
| EAR loss | whether reference trajectories are learning an action distribution |
| validation rollout success | more important than loss when a simulator is available |
| action magnitude | catches commands that are too large or too small |
| gripper accuracy | often determines pick/place success |
For manipulation, do not trust loss alone. Replay predicted actions on validation episodes or run simulator rollouts. A policy can have a clean loss curve and still fail because the gripper closes 200 ms late or the end-effector stays too high above the object.
Inference and deployment
The official README shows a policy-server launch command:
bash scripts/server.sh <GPU_ID> <PORT>
A typical inference loop is:
robot cameras + state
|
v
preprocess: resize, normalize, pack prompt
|
v
ACoT-VLA policy server
|
v
action chunk: [a_t, a_{t+1}, ..., a_{t+H-1}]
|
v
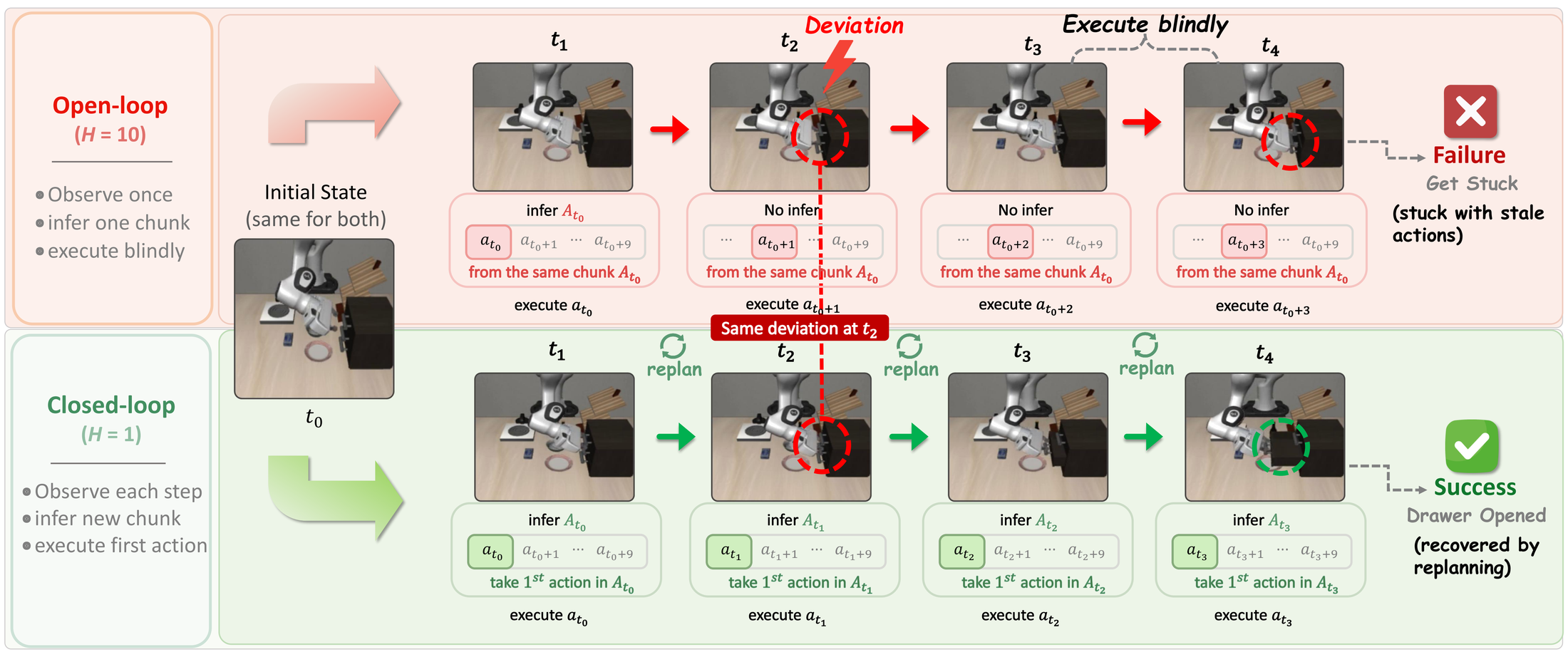
client executes first k actions, then replans
Client-side pseudo-code:
while robot.is_running():
obs = {
"images": {
"front": front_camera.read(),
"wrist": wrist_camera.read(),
},
"state": robot.get_state(),
"instruction": current_instruction,
}
action_chunk = policy_client.predict(obs)
for action in action_chunk[:recede_steps]:
robot.send_action(action)
sleep(control_dt)
Deployment considerations:
| Issue | Recommendation |
|---|---|
| Latency | Use receding horizon: predict a chunk, execute the first few steps |
| Safety | Clamp joint velocity, EEF deltas, and gripper commands |
| Camera shift | Calibrate camera pose or augment camera viewpoints during training |
| Contact-rich tasks | Add force/torque limits and stop conditions when available |
| Instruction mismatch | Log the exact instruction string used during data collection |
ACoT-VLA inference can be heavier than a baseline action head because EAR and IAR add computation. The tradeoff is improved robustness in the paper's experiments. On a real robot, measure end-to-end latency, not only model forward time. Camera capture, image decoding, resizing, network RPC, and the robot controller cycle all contribute to delay.
Results reported in the paper
The paper evaluates ACoT-VLA on LIBERO, LIBERO-Plus, VLABench, and real-world AgiBot G1 / AgileX tasks. Key results include:
| Benchmark | Reported highlight |
|---|---|
| LIBERO | Baseline 96.9% average, EAR+IAR reaches 98.5% average in ablation |
| LIBERO-Plus Zero-Shot | ACoT-VLA reaches 86.6% average in the README comparison |
| LIBERO-Plus SFT | ACoT-VLA reaches 88.0% average; frozen variant reaches 84.1% |
| VLABench | Frozen ACoT-VLA reaches 63.5 IS / 47.4 PS average, best in the paper's comparison table |
| Real-world | ACoT-VLA reaches 66.7% average success, compared with 61.0% for Pi0.5 and 33.8% for Pi0 |
LIBERO-Plus is especially useful because it tests seven controlled distribution shifts: camera viewpoint, robot initial state, language variations, lighting, background, sensor noise, and object layout. These are exactly the kinds of changes that make real robot deployment difficult.
The ablation study is also important:
| Module | Meaning | LIBERO avg |
|---|---|---|
| Baseline | action head without EAR/IAR | 96.9 |
| EAR only | adds explicit reference trajectory | 98.3 |
| IAR only | adds implicit action priors | 98.1 |
| EAR + IAR | combines both modules | 98.5 |
The takeaway is not that ACoT-VLA will beat every smaller policy in every setting. The technical lesson is that explicit trajectory guidance and implicit action cues are complementary. EAR gives the model a motion scaffold; IAR extracts action-relevant semantics already present in the VLM.
When should you use ACoT-VLA?
ACoT-VLA is a good fit when your project has one of these needs:
| Need | Fit |
|---|---|
| Long-horizon tabletop manipulation | Good |
| Language variation | Good |
| Contact-rich tasks such as wiping or pouring | Good, with a safety layer |
| Dataset already in LeRobot format | Very good |
| Simple single-task pick/place | Possibly too heavy |
| Edge inference on a small GPU | Benchmark latency first |
If you are new to robot learning, start smaller: train ACT or Diffusion Policy on one task, then learn LeRobot-format data, then move to VLA fine-tuning. ACoT-VLA is most useful once you understand action chunking, normalization, camera synchronization, and rollout evaluation.
Beginner practice path
A practical path with lower risk:
- Read the paper and README to understand EAR, IAR, and AGP.
- Convert LIBERO data to LeRobot format.
- Load the dataset with
LeRobotDatasetand inspect keys, shapes, and FPS. - Compute normalization statistics.
- Train a baseline config before enabling every module.
- Enable EAR only and compare validation rollouts.
- Enable IAR, then EAR+IAR.
- Run the inference server in simulation.
- Deploy to a real robot only after action clamps, emergency stop, and workspace boundaries are ready.
Recommended sources:
| Source | Link |
|---|---|
| arXiv paper | arxiv.org/abs/2601.11404 |
| CVPR 2026 PDF | openaccess.thecvf.com |
| Supplemental | CVPR supplemental PDF |
| Official repo | github.com/AgibotTech/ACoT-VLA |
| LeRobot dataset v3 docs | github.com/huggingface/lerobot |