Vì sao Wall-OSS-0.5 đáng chú ý?
Wall-OSS-0.5 là một Vision-Language-Action (VLA) model open-source từ X Square Robot, được công bố trong technical report trên arXiv với mục tiêu rất rõ: kiểm tra xem pretraining VLA có tạo ra hành vi robot có thể chạy ngay trên phần cứng thật hay không, hay chỉ là một initialization tốt cho fine-tuning về sau.
Điểm khác biệt nằm ở cách đánh giá. Nhiều VLA trước đây báo cáo kết quả sau khi đã fine-tune trên task, embodiment, camera setup, hoặc dữ liệu gần với môi trường test. Điều đó có ích về mặt ứng dụng, nhưng khiến ta khó biết model foundation thực sự đã học được gì. Wall-OSS-0.5 báo cáo cả hai lớp kết quả: zero-shot trên real robot trước khi fine-tune, và kết quả sau fine-tuning trên bộ task robot thật.
Theo paper gốc, model có hơn 4B parameters, được xây trên Qwen2.5-VL-3B-Instruct làm VLM backbone, sau đó bổ sung action-generation components. Model được pretrain trên hơn 20 embodiments, xử lý hơn một triệu robot trajectories mỗi epoch, đồng thời học cùng một grounded multimodal corpus khoảng 90 triệu samples. Checkpoint pretrained đạt behavior zero-shot đáng kể trên 17 real-robot tasks; sau fine-tuning, model đạt 60.5 average task progress trên 15 tasks và hơn pi0.5 17.5 percentage points.
Với cộng đồng LeRobot, điểm đáng quan tâm không chỉ là con số. Wall-OSS đã được đưa vào tài liệu LeRobot với policy.type=wall_x, repo wall-x cung cấp pipeline training/inference, và model weights được public trên Hugging Face. Điều này biến Wall-OSS-0.5 thành một case study tốt cho người mới muốn hiểu VLA hiện đại: model không chỉ "nhìn ảnh và sinh action", mà phải giải quyết nhiều mâu thuẫn giữa language token, visual grounding, continuous control, dữ liệu nhiều robot, và latency inference.
Tóm tắt nhanh
| Hạng mục | Wall-OSS-0.5 |
|---|---|
| Loại model | Vision-Language-Action foundation model |
| Quy mô | Hơn 4B parameters |
| Backbone | Qwen2.5-VL-3B-Instruct |
| Kiến trúc chính | Mixture-of-Transformers với VL Expert và Action Expert |
| Training recipe | Gradient-bridged co-training |
| Action interface khi deploy | Continuous flow matching |
| Dữ liệu pretraining | Self-collected manipulation, open-source multi-embodiment trajectories, 90M multimodal samples |
| LeRobot | Có implementation trong ecosystem LeRobot |
| License | Apache 2.0 theo tài liệu LeRobot/Hugging Face |
Các nguồn chính nên đọc:
- Paper: https://arxiv.org/abs/2605.30877
- GitHub: https://github.com/X-Square-Robot/wall-x
- Hugging Face model: https://huggingface.co/x-square-robot/wall-oss-0.5
- LeRobot docs: https://huggingface.co/docs/lerobot/main/en/walloss
Ý tưởng cốt lõi của paper
Paper đặt ra một câu hỏi rất thực dụng: nếu ta pretrain một VLA đủ lớn trên nhiều robot và nhiều dạng dữ liệu, checkpoint đó có thể điều khiển robot thật ngay lập tức không?
Để trả lời, tác giả tránh chỉ báo cáo post-training result. Họ deploy checkpoint pretrained trực tiếp lên real robot và chấm điểm task progress trên 17 tasks. Metric này không phải binary success rate đơn giản. Thay vì chỉ hỏi "thành công hay thất bại", task progress cho điểm từng phần: robot đã nhận đúng object chưa, đã grasp chưa, đã di chuyển đúng hướng chưa, đã hoàn thành final placement chưa. Với foundation model còn đang ở giai đoạn đầu, cách chấm này hữu ích hơn vì nó cho thấy capability đang hình thành ở đâu.
Ý tưởng kỹ thuật trung tâm là gradient-bridged co-training. Vấn đề là robot action là continuous signal, còn VLM backbone ban đầu được train bằng next-token prediction trên text/image tokens. Nếu chỉ gắn một flow-matching action head vào VLM, action head có thể học phần nào, nhưng gradient quay lại backbone yếu. Nếu biến action thành discrete tokens và train bằng cross-entropy, gradient vào backbone mạnh hơn, nhưng discrete action thường quá thô để điều khiển robot chính xác.
Wall-OSS-0.5 không chọn một trong hai. Model dùng cả hai pathway:
- Discrete action tokens để tạo gradient mạnh, tương thích với cách VLM học.
- Multimodal text/image prediction để giữ grounding và instruction following.
- Continuous flow matching để sinh action chunk dùng thật khi deploy.
Nói ngắn gọn: discrete action pathway chủ yếu để dạy backbone hiểu hành động; continuous pathway chủ yếu để điều khiển robot thật.
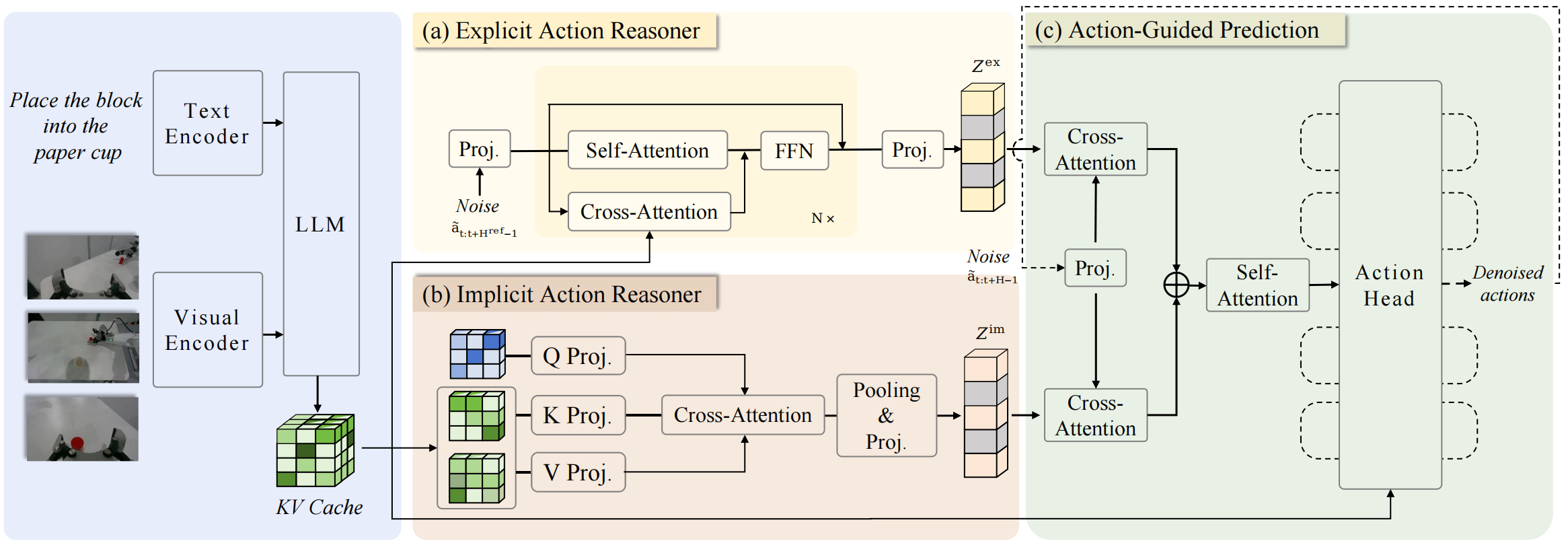
Kiến trúc: từ VLM thành VLA
Wall-OSS-0.5 bắt đầu từ Qwen2.5-VL-3B-Instruct. Backbone này vốn mạnh về vision-language understanding: nhìn ảnh, hiểu instruction, trả lời câu hỏi, reasoning trên scene. Để biến nó thành VLA, nhóm tác giả thêm một Mixture-of-Transformers (MoT) layout.
Sơ đồ đơn giản:
Camera images + instruction + proprioception
|
v
VLM-style token sequence
|
v
+-------------------------------+
| Mixture-of-Transformers |
| |
| VL Expert |
| - vision tokens |
| - language tokens |
| - proprioception tokens |
| - discrete action tokens |
| |
| Action Expert |
| - noisy continuous actions |
| - flow-matching denoising |
+-------------------------------+
|
v
Continuous action chunk for robot
VL Expert giữ lại phần lớn năng lực của VLM gốc. Action Expert chịu trách nhiệm xử lý continuous-action computation. Hai expert không bị tách cứng kiểu "frozen backbone + action head". Chúng chia sẻ sequence-level attention context, nên Action Expert vẫn attend được vào thông tin visual/language, và gradient vẫn có đường đi end-to-end.
Tuy vậy, paper dùng attention mask để discrete action tokens và continuous action tokens không nhìn thấy nhau trực tiếp trong forward pass. Điều này cho phép hai pathway được train và đánh giá tương đối độc lập:
- Discrete pathway: phục vụ action-token cross-entropy trong training.
- Continuous pathway: phục vụ flow matching và inference.
Action input/output cũng được chuẩn hóa kỹ. Model dùng relative action representation, rotation 6D thay vì Euler angles/quaternion để tránh discontinuity. Action space được mô tả là 26D: mỗi arm có relative 3D position, relative 6D rotation và gripper state; thêm mobile base velocity, lift height và head actuation. Cả hai pathway dự đoán action horizon khoảng một giây, sau đó số frame phụ thuộc control frequency của từng data source.
Vision-Aligned RVQ Action Tokenizer
Một điểm quan trọng của Wall-OSS-0.5 là không dùng action tokenizer chỉ để nén số. Paper thay FAST tokenizer bằng Vision-Aligned Residual Vector Quantization (RVQ) Action Tokenizer.
Beginner có thể hiểu RVQ như một bộ từ điển nhiều tầng. Tầng đầu encode chuyển động thô, các tầng sau encode residual correction mịn hơn. Nhưng trong robotics, chỉ reconstruction loss chưa đủ. Một token action tốt phải mang ý nghĩa: action này khiến object dịch chuyển thế nào, robot nên nhìn vùng nào, trạng thái tiếp theo ra sao.
Vì vậy tokenizer được train với nhiều mục tiêu:
| Mục tiêu | Vai trò |
|---|---|
| Reconstruction | Giữ khả năng tái tạo action chunk |
| Visual-action alignment | Kéo action latent gần visual features tương ứng |
| Next-frame prediction | Buộc token encode hậu quả của action |
| DCT-domain reconstruction | Giảm high-frequency jitter trong trajectory |
Kết quả là discrete action token không chỉ là mã số cho motor delta, mà là training signal có liên hệ với visual state và physical consequence. Paper báo cáo ablation tokenizer: Vision-Aligned RVQ tăng average task progress từ 29.3 lên 48.1 trên 4 real-robot tasks, đồng thời VQA tăng nhẹ từ 75.7 lên 77.5. Điều thú vị là real-robot evaluation vẫn dùng continuous flow actions, nên tokenizer tốt hơn đã cải thiện cả pathway continuous thông qua co-training.
Training recipe: ba loss cùng chạy
Wall-OSS-0.5 được train một stage với composite objective:
L_total = L_flow + 0.01 * L_act_CE + 0.01 * L_mm_CE
Trong đó:
L_flow: flow-matching loss cho continuous action generation.L_act_CE: cross-entropy để dự đoán discrete RVQ action tokens.L_mm_CE: cross-entropy cho multimodal text/image prediction.
Tại sao weight của hai CE loss là 0.01? Paper giải thích rằng flow loss nhỏ hơn cross-entropy loss khoảng hai bậc độ lớn dưới action-space supervision. Nếu không scale, language-style CE có thể lấn át action learning. Tác giả cũng mix action và multimodal data theo tỷ lệ batch 9:1, nghĩa là action data vẫn là phần chính nhưng multimodal data đóng vai trò anchor.
Dữ liệu pretraining gồm ba nhóm:
- Self-collected manipulation data: tabletop bimanual systems, mobile manipulators, và thiết bị XRZero-G0 để thu thập dữ liệu không gắn chặt với một morphology cụ thể.
- Curated open-source multi-embodiment data: các nguồn như RoboMIND, AgiBotWorld, DROID, Bridge v2, Fractal/Google Robot và một số dataset khác được chuẩn hóa format/action.
- Multimodal corpus khoảng 90M samples: 78M open-source multimodal samples và 12M embodied bridge samples tạo từ robot trajectories.
Pipeline preprocessing phải xử lý các điểm rất thực tế: action definition khác nhau, coordinate frame khác nhau, gripper polarity khác nhau, camera timestamp không khớp, dataset imbalance, stationary frames, và long-tail task distribution. Paper dùng square-root sampling (p = 0.5) để tránh nguồn dữ liệu lớn áp đảo các nhóm nhỏ. Sau sampling, một epoch có hơn một triệu trajectories, khoảng 60% self-collected và 40% open-source.
Cài đặt với LeRobot và Wall-X
Nếu bạn muốn thử theo hướng research, có hai đường: dùng LeRobot integration hoặc dùng repo Wall-X trực tiếp. Với beginner, nên bắt đầu từ LeRobot vì command training quen thuộc hơn.
Yêu cầu thực tế:
- Linux, ưu tiên Ubuntu 22.04.
- Python 3.10 theo repo Wall-X.
- GPU NVIDIA có CUDA; training/fine-tuning model 4B cần GPU lớn hơn nhiều so với tutorial ACT/SmolVLA.
bf16nên chạy trên Ampere/Ada/Blackwell hoặc GPU data center.- Robot thật phải có camera calibration, safety stop, low-level controller ổn định.
Cài LeRobot source và Wall-X extras:
conda create --name wallx python=3.10
conda activate wallx
pip install torch torchvision transformers
pip install huggingface_hub
# Trong checkout LeRobot source:
pip install -e ".[wallx]"
Nếu làm theo repo Wall-X trực tiếp, README gốc yêu cầu requirements.txt, flash-attn==2.7.4.post1, LeRobot tại một commit cụ thể, sau đó install package ở editable mode. Đừng bỏ qua version pinning: với VLA lớn, lỗi nhỏ ở CUDA, FlashAttention hoặc Transformers có thể làm inference sai dtype, chậm hơn nhiều, hoặc fail khi load checkpoint.
Trong LeRobot, policy type là:
policy.type=wall_x
Một command fine-tune tối giản theo docs:
lerobot-train \
--dataset.repo_id=your_dataset \
--policy.type=wall_x \
--output_dir=./outputs/wallx_training \
--job_name=wallx_training \
--policy.repo_id=your_repo_id \
--policy.pretrained_name_or_path=x-square-robot/wall-oss-flow \
--policy.prediction_mode=diffusion \
--policy.attn_implementation=eager \
--steps=3000 \
--policy.device=cuda \
--batch_size=32
Trong thực tế, bạn cần chỉnh batch_size, gradient accumulation, camera names, action dimension, normalization key, robot DOF và dataset schema. Nếu dataset chưa ở LeRobot format, bước đầu tiên không phải training mà là chuẩn hóa episode:
episode/
observation.images.front
observation.images.wrist
observation.state
action
task
timestamp
Fine-tuning trên dataset robot của bạn
Fine-tuning Wall-OSS-0.5 không giống fine-tune một image classifier. Dataset cần đúng semantics:
| Trường | Cần kiểm tra |
|---|---|
| Camera | View cố định, timestamp sync, exposure ổn định |
| State | End-effector pose hoặc joint state nhất quán |
| Action | Relative action, gripper convention, control rate |
| Language | Goal instruction và step instruction không mâu thuẫn |
| Episode | Không chứa quá nhiều idle frames |
| Safety | Action bounds, collision zone, emergency stop |
Một cấu hình training nên bắt đầu nhỏ:
lerobot-train \
--dataset.repo_id=my-org/my-wallx-task \
--policy.type=wall_x \
--policy.pretrained_name_or_path=x-square-robot/wall-oss-0.5 \
--output_dir=./outputs/wallx_pick_place \
--job_name=wallx_pick_place_sft \
--steps=1000 \
--batch_size=4 \
--policy.device=cuda \
--policy.attn_implementation=sdpa
Sau khi pipeline chạy ổn, mới tăng steps và batch. Với robot thật, nên đánh giá theo từng tầng:
- Offline sanity check: model load được, output action shape đúng.
- Open-loop replay: action chunk có scale hợp lý, không saturate.
- Low-speed closed-loop: giới hạn velocity và workspace.
- Full-speed evaluation: chạy nhiều episode, log cả success lẫn partial progress.
Inference: chạy action chunk liên tục
Hugging Face model card có ví dụ inference fake input: load checkpoint x-square-robot/wall-oss-0.5, tạo observation gồm end-effector position, axis-angle, gripper, camera images 448x448, sau đó gọi generate_flow_action để nhận predict_action có shape [horizon, action_dim].
Luồng inference khái niệm:
while robot_is_running:
images = read_cameras()
proprio = read_robot_state()
instruction = current_task_text
action_chunk = wall_oss.generate_flow_action(
images=images,
proprio=proprio,
instruction=instruction,
horizon=1_second
)
execute_first_k_actions(action_chunk)
replan_with_new_observation()
Không nên execute toàn bộ chunk một cách mù quáng nếu môi trường thay đổi nhanh. Với manipulation, cách an toàn hơn là receding horizon: sinh chunk, execute một phần ngắn, đọc camera mới, rồi sinh lại. Paper nhấn mạnh inference optimization vì real-time control rất nhạy với latency. Trên RTX 5090, stack optimized đạt khoảng 21 Hz với input 224x224 và khoảng 15 Hz với 448x448, dùng 10 denoising steps, nhanh hơn khoảng 4 lần so với PyTorch eager baseline.
Kết quả chính
Zero-shot real-robot
Zero-shot suite gồm 17 tasks: 12 seen tasks từ phân phối pretraining và 5 unseen task configurations chưa được thu thập y hệt trên embodiment hiện tại. Mỗi task được đánh giá 10 trajectories và chấm task progress tối đa 100.
| Task ở checkpoint 400k | Category | Seen/Unseen | Task progress |
|---|---|---|---|
| Block Sorting | Semantic understanding | Seen | 100 |
| Fruit Sorting | Semantic understanding | Seen | 96 |
| Ring Stacking | Rigid manipulation | Seen | 86 |
| Rope Tightening | Deformable manipulation | Unseen | 82 |
| Cup Grasping | Rigid manipulation | Seen | 64 |
| Bean Pouring | Deformable manipulation | Unseen | 60 |
Average progress cũng tăng theo pretraining. Ở checkpoint 50k, overall average là 25.5; đến 400k là 51.1. Seen tasks tăng từ 26.1 lên 50.0, unseen tasks tăng từ 24.2 lên 53.6. Paper lưu ý seen/unseen không difficulty-matched, nên xu hướng tăng quan trọng hơn việc unseen cao hơn seen ở checkpoint cuối.
Những task còn khó zero-shot là Towel Folding, Table Setting, Charger Plugging. Chúng đòi hỏi deformable handling, insertion precision, long-horizon planning hoặc fine-grained contact. Đây là reminder quan trọng: Wall-OSS-0.5 không biến robot thành general household worker ngay lập tức. Nó cho thấy pretraining đã tạo foundation behavior có thể đo được.
Fine-tuning real-robot
Sau fine-tuning, Wall-OSS-0.5 được so với pi0.5 và DreamZero trên 15 real-robot tasks, cùng khoảng 500 demonstration trajectories mỗi task.
| Model | Manipulation (10) | Reasoning (5) | Overall (15) |
|---|---|---|---|
| Wall-OSS-0.5 | 61.1 | 59.3 | 60.5 |
| pi0.5 | 35.0 | 58.9 | 43.0 |
| DreamZero | 33.7 | 32.7 | 33.4 |
Wall-OSS-0.5 dẫn đầu overall và đặc biệt mạnh ở manipulation subset. Ví dụ Color Block Sorting 96 vs 42 của pi0.5, Ring Stacking 91 vs 60, Drawer Organization 52 vs 7, Spoon-in-Bowl 80 vs 43. Tuy nhiên pi0.5 vẫn thắng một số task như Glasses Rack Placement, Fruit Basket Placement và Object Matching. Điều này giúp đọc kết quả tỉnh táo hơn: model mạnh hơn trung bình, nhưng không thắng tuyệt đối mọi dạng task.
Hạn chế cần nhớ
Paper tự nêu một số giới hạn. Backbone mới ở cỡ 3B VLM, chưa chứng minh scaling trên model lớn hơn. Input chủ yếu single-frame, nên temporal memory còn hạn chế so với các task cần quan sát lịch sử dài. Action space 26D là thiết kế cụ thể, không phải action representation phổ quát cho mọi robot. Task progress dựa trên rubric thủ công, tốt hơn binary success nhưng vẫn phụ thuộc cách thiết kế benchmark.
Với người triển khai, giới hạn lớn nhất là hardware và robot safety. Một checkpoint VLA open-source không thay thế calibration, controller, force limits, collision checking và quy trình test có giám sát. Hãy xem Wall-OSS-0.5 như một foundation policy để nghiên cứu và fine-tune, không phải một package cắm vào robot là chạy production ngay.
Kết luận
Wall-OSS-0.5 quan trọng vì nó đẩy chuẩn đánh giá VLA về hướng thực tế hơn: công bố pretrained zero-shot behavior trên robot thật, open weights, open training/inference stack, và tích hợp với LeRobot. Về kỹ thuật, đóng góp đáng học nhất là gradient-bridged co-training: dùng discrete action CE để dạy backbone hiểu action, dùng multimodal CE để giữ grounded VLM capability, và dùng continuous flow matching để deploy.
Nếu bạn mới học VLA, hãy nhớ mô hình tinh thần này: VLA không chỉ là "LLM thêm robot head". Một VLA tốt cần bridge giữa semantic reasoning và continuous control. Wall-OSS-0.5 là một ví dụ rõ ràng về cách bridge đó được thiết kế, train, đo lường và đưa vào ecosystem open-source.