What problem does StressDream solve?
Robot manipulation policies often look good until they meet the tail cases. A trajectory may succeed in the logged demonstration, but the same action can fail if the gripper releases a few centimeters too high, the object is closer to the table edge, the bag tilts slightly, or a stacked object starts sliding. Before deploying a policy on real hardware, teams need to ask a practical question: does this action have a plausible future where the robot spills, drops, collides, or otherwise fails?
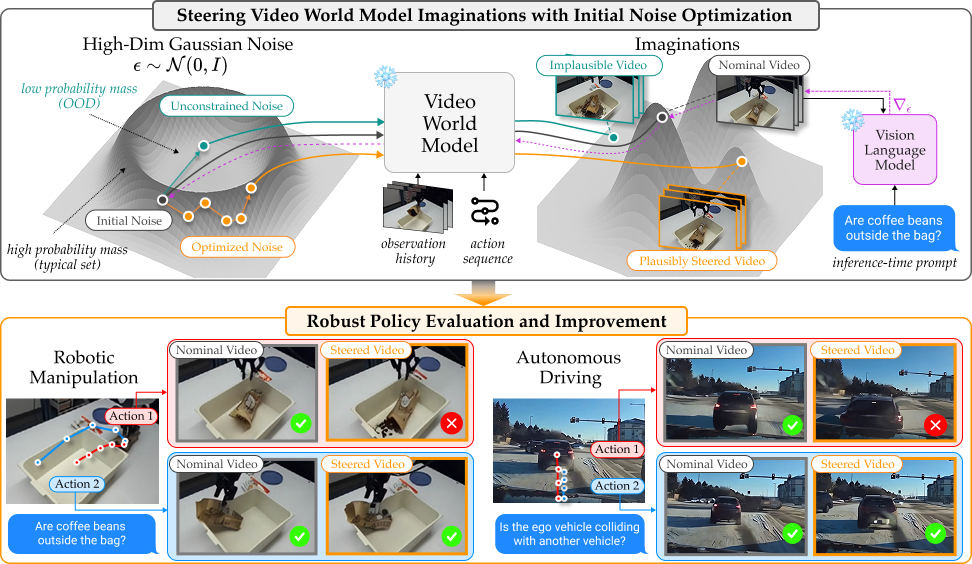
StressDream turns that question into an inference-time test with a video world model. The original paper is StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement, by Junwon Seo, Sushant Veer, Ran Tian, Wenhao Ding, Apoorva Sharma, Karen Leung, Edward Schmerling, Marco Pavone, and Andrea Bajcsy. It was posted to arXiv on May 29, 2026. The project page is junwon.me/StressDream, and the official code is available at CMU-IntentLab/StressDream.
The idea is simple but powerful: instead of sampling a few "normal" rollouts from a video world model, StressDream optimizes the initial noise of a diffusion video world model so the model imagines a high-impact outcome that is still plausible under the learned model distribution. For manipulation, the target event can be written as a text prompt:
Is the coffee bean spilled? Respond with a single word: Yes or No.
If the action sequence really has a plausible spilling failure, the steered world model should find a future video where that failure appears. If the scene does not support that failure, for example a closed bag or sticky candy that should not spill, the method should not invent an absurd failure. That distinction is the core of the paper: StressDream is not trying to generate bad videos at any cost. It is trying to find the worst plausible future for a candidate action.
If you have read our guides on Diffusion Policy, VLA models, or RISE with world-model imagination, StressDream fills a very practical gap. It does not replace the main policy. It does not require thousands of additional real-world trials. It adds a stress-test stage between policy training and physical deployment.
The paper in five minutes
A video world model takes an observation history and a future action sequence, then predicts future observations. In robot manipulation, observations usually include multiple RGB camera views, sometimes including a wrist camera, plus proprioceptive state. Actions may be joint positions, end-effector poses, or action chunks. In the manipulation experiments, StressDream uses Ctrl-World, a controllable generative world model for robot manipulation trained in a DROID-style setup. According to the paper, Ctrl-World predicts 5 future frames from 3 camera views at 192 x 320 resolution, conditioned on joint-position actions, with a noise dimension of 57,600.
The problem with nominal rollout is optimism. A diffusion world model may represent many possible futures, but one random noise sample only gives you one future. If the failure is rare but plausible, random sampling can easily miss it. Sampling many videos helps, but each video generation is expensive.
StressDream treats the initial Gaussian noise as a control variable:
observation history + action sequence + initial noise
|
v
diffusion video world model
|
v
future video rollout
With fixed observation and action conditioning, the generated video is determined by the initial noise. StressDream therefore optimizes that noise with gradients so the generated video moves toward the target event described by an inference-time text prompt.
The full loop looks like this:
Initial image(s) + action trajectory
|
v
Sample initial Gaussian noise epsilon
|
v
Video world model generates a multi-view rollout
|
v
VLM reads rollout + failure prompt
|
v
Semantic score: log P(Yes) - log P(No)
|
v
Plausibility regularizer keeps epsilon in the Gaussian typical set
|
v
Update epsilon and repeat
|
v
Steered plausible failure video, if such a failure is supported
Technical architecture
StressDream has three main pieces.
| Component | Role | In the manipulation demo |
|---|---|---|
| Video world model | Generate future video conditioned on actions | Ctrl-World |
| Semantic objective | Score whether the target event appears | Qwen3-VL-4B-Instruct |
| Plausibility objective | Keep optimized noise close to a valid Gaussian sample | norm, isotropy, spectral whiteness |
1. The video world model
The world model can be written as:
o_future ~ f_theta(. | o_history, a_future)
Here o_history is the observation history, a_future is the action sequence to test, and o_future is the generated rollout. In a diffusion world model, generation starts from noise epsilon ~ N(0, I) and gradually denoises into a video latent. Once o_history and a_future are fixed, epsilon controls which future is generated.
The difference between nominal generation and StressDream is:
Nominal:
epsilon = random Gaussian noise
video = world_model(epsilon, observation, action)
StressDream:
epsilon = random Gaussian noise
for i in optimization_steps:
video = world_model(epsilon, observation, action)
reward = VLM(video, failure_prompt) + plausibility(epsilon)
epsilon = epsilon + lr * grad(reward)
The official repository contains three modules: dubins/ for a synthetic Dubins car, vista/ for autonomous driving, and ctrl_world/ for robot manipulation. This tutorial focuses on ctrl_world/.
2. Semantic objective with a VLM
The paper uses a Vision-Language Model to score complex failures in generated video. Instead of training a separate classifier for every task, you describe the failure in text. The VLM is prompted to answer with a single token, Yes or No. The semantic score is:
C_sem(video, prompt) = log P(Yes | video, prompt) - log P(No | video, prompt)
For manipulation, a prompt can be:
Is the coffee bean spilled? Respond with a single word: Yes or No.
If the video increasingly looks like spilled coffee beans, P(Yes) rises. That score provides a gradient signal for the noise optimizer. In the ctrl_world implementation, Qwen3-VL reads a multi-view clip and returns a reward based on the margin between the Yes and No token probabilities.
3. Plausibility objective
If we only optimize the VLM reward, the noise can leave the region where the diffusion model was trained. The generated videos may become artifact-heavy, physically strange, or simply exploit the VLM. The paper frames this as leaving the typical set of the high-dimensional Gaussian prior.
StressDream uses regularizers that keep the optimized noise statistically similar to real Gaussian noise:
| Regularizer | Intuition |
|---|---|
| Norm concentration | The noise norm should stay close to sqrt(D) |
| Isotropy | Random blocks of noise should not show unusual correlations |
| Spectral whiteness | The power spectrum should not contain structured frequency artifacts |
In ctrl_world/steering_config.yaml, the relevant coefficients include kl_coeff, kl_coeff_spherical, std_coeff, spectral_coeff, and std_permutation_coeff. This is what makes StressDream different from plain adversarial generation. It is not just trying to fool a VLM. It is trying to locate a bad outcome that remains inside the world model's supported distribution.
Installing StressDream for manipulation
The official repo gives each domain its own environment. For manipulation:
conda env create -f ctrl_world/environment.yml
conda activate stressdream-ctrlworld
The ctrl_world README lists Python 3.11, PyTorch 2.9.1 with CUDA 12.8, Diffusers 0.36, Transformers 4.57, and an NVIDIA driver version of at least 520. Full optimization with the Qwen3-VL reward and noise optimization needs roughly 20 GB of VRAM. If your GPU is smaller, reduce interact_num, reduce iters, or first run the nominal generator to debug the data path.
You need three main checkpoints:
| Checkpoint | Role | Relative size |
|---|---|---|
ckpts/Ctrl-World/coffee_bag.pt |
Ctrl-World checkpoint for the StressDream demo | smaller than SVD |
ckpts/stable-video-diffusion-img2vid/ |
pretrained Stable Video Diffusion backbone | several GB |
ckpts/clip-vit-base-patch32/ |
CLIP encoder | around 600M |
The README uses the current hf CLI:
pip install -U huggingface_hub
mkdir -p ckpts/Ctrl-World
hf download junwon-seo/StressDream \
coffee_bag.pt --local-dir ckpts/Ctrl-World
hf download stabilityai/stable-video-diffusion-img2vid \
--local-dir ckpts/stable-video-diffusion-img2vid
hf download openai/clip-vit-base-patch32 \
--local-dir ckpts/clip-vit-base-patch32
Qwen3-VL-4B-Instruct is fetched automatically by transformers on the first run, so leave enough disk space and download time.
Running the first demo
The repo includes a sample trajectory:
ctrl_world/example_data/traj_0001.hdf5
It contains a candy-coffee style task with real trajectory data, end-effector states, and three camera views. To run steered imagination:
python ctrl_world/run_steering.py \
--hdf5_path ctrl_world/example_data/traj_0001.hdf5
To run the nominal baseline:
python ctrl_world/generate_nominal.py \
--hdf5_path ctrl_world/example_data/traj_0001.hdf5
The steered output is written under:
outputs/ctrl_world_steering/<timestamp>/
├── step_0001_best.mp4
├── step_0002_best.mp4
├── ...
├── full_steered.mp4
├── history.json
└── optimized_noise.pt
The nominal output is written under:
outputs/ctrl_world_nominal/<timestamp>/
├── step_0001_nominal.mp4
├── ...
├── full_nominal.mp4
└── history.json
Open full_nominal.mp4 and full_steered.mp4 side by side. Nominal answers: "what does a typical rollout look like?" Steered answers: "can the world model find a plausible failure for this same action sequence?"
Customizing prompts for your task
You can override the instruction and Qwen prompt from the CLI:
python ctrl_world/run_steering.py \
--hdf5_path ctrl_world/example_data/traj_0001.hdf5 \
--instruction "put the coffee bag into the container without spilling" \
--qwen_prompt "Is the coffee bean spilled? Respond with a single word: Yes or No."
A good prompt has three properties:
| Do | Avoid |
|---|---|
| Ask for one concrete failure | Ask a vague question like "did the task fail?" |
| Force a Yes/No answer | Ask for a long explanation |
| Name the object as it appears in the scene | Use ambiguous references that make the VLM guess |
Example prompts:
Is the knife dropped off the table edge? Respond with a single word: Yes or No.
Are the coffee beans outside the bag? Respond with a single word: Yes or No.
Does the top utensil fall while the bottom utensil is pulled? Respond with a single word: Yes or No.
The paper studies six contact-rich manipulation tasks: block stack, knife put, stacked utensil pick, coffee bean pour, open coffee bag, and open candy bag. The failure descriptions include dropping, spilling, sliding, releasing too high, and acting too close to an edge.
Reading steering_config.yaml
The default ctrl_world config looks like this:
task:
instruction: "put the coffee bag into the container without spilling"
qwen_prompt: "Is the coffee bean spilled? Respond with a single word: Yes or No."
target_success: true
model:
task_type: replay
num_frames: 5
optim:
iters: 5
interact_num: 20
lr: 1.0
grad_scale: 100.0
noise_norm_threshold: 3.0
detach_latents: true
seed: 33
The beginner-friendly interpretation:
| Parameter | What it controls | Practical note |
|---|---|---|
num_frames |
Frames generated per world-model window | Keep default at first |
interact_num |
Number of autoregressive rollout windows | Reduce for faster debugging |
iters |
Noise optimization steps per window | Increase if steering is weak, but it costs time |
lr |
Learning rate for noise | Too high can cause artifacts |
grad_scale |
Scale for VLM reward gradients | Too high can encourage reward hacking |
noise_norm_threshold |
Hard renormalization threshold | Helps prevent excessive noise drift |
In run_steering.py, each interaction step loads the next action chunk from the HDF5 file, normalizes it with dataset statistics, builds a three-view conditioning latent, samples fresh noise, optimizes that noise for several iterations, saves the best video, then uses the last generated latent frame as conditioning for the next step. That is how the rollout can continue beyond one short prediction window.
Training vs. inference
StressDream is not primarily a recipe for training a world model from scratch. The paper uses existing or fine-tuned world models:
| Domain | World model | Data/setup |
|---|---|---|
| Dubins car | small diffusion WM | 4,000 random trajectories |
| Driving | Vista | PAI-AV and Nexar Collision Prediction Dataset |
| Robot manipulation | Ctrl-World | DROID-style setup, about 150 teleoperation trajectories per task, including successes and failures |
For a deployment team, there are three levels of use:
Level 1: run the included demo
Use the provided checkpoint and traj_0001.hdf5 to understand outputs.
Level 2: stress-test internal trajectories
Convert your robot logs into an HDF5 format the loader can read:
multi-view RGB, eef_states or joint actions, and gripper state.
Level 3: fine-tune the world model
Collect success and failure data for your task, fine-tune Ctrl-World,
then run StressDream for policy/action evaluation.
Inference in StressDream is the steering process. You provide observation, action, and a failure prompt, and you receive a steered video. Policy improvement is a later step: use the steering result to reweight demonstrations. In the paper, the authors fine-tune π0.5-DROID with 40 successful demonstrations per task. Trajectories that remain successful under failure steering receive weight 1.0; trajectories that fail in steered imagination receive weight 0.1. This encourages the policy to imitate robust actions rather than actions that happened to succeed once.
Main results from the paper
The headline numbers are:
| Experiment | Result |
|---|---|
| Robust policy evaluation | failure detection recall improves from 54% to 94% |
| Policy improvement | π0.5 success rate improves from 39% to 71% |
| Plausibility | StressDream does not force a closed bag or sticky candy into implausible spilling |
| Baseline | Best-of-N random sampling still misses many rare failures |
The practical interpretation is narrow but valuable: StressDream does not prove that a policy is safe in the real world. It shows that if the world model has learned a plausible failure mode, inference-time steering can find that failure more efficiently than nominal rollouts. That makes it a useful pre-deployment test layer.
A safer deployment checklist
Use this checklist before making StressDream part of your internal workflow:
[ ] The world model has seen scenes, objects, and camera views close to deployment
[ ] Failure data exists, or the target failure is at least supported by the model
[ ] Failure prompt is concrete and uses a Yes/No answer
[ ] Nominal and steered rollouts are generated side by side
[ ] Humans review a subset of videos for VLM reward hacking
[ ] history.json is logged: reward, p_yes, p_no, noise_norm, regularizer
[ ] StressDream is not treated as the only safety proof
[ ] Real-world supervised validation still happens before deployment
The limitation is important. In this paper, "plausible" means plausible under the world model, not guaranteed physically plausible in the real world. If the world model lacks data for liquids, deformable objects, subtle contact, occlusion, or gripper slip, StressDream cannot reliably discover risks that the model never learned.
Conclusion
StressDream is a practical way to turn a video world model into a policy stress-testing tool. Instead of only asking "what does the policy do in a typical rollout?", it asks "does this same action have any plausible future where something important fails?" That second question is much closer to real deployment thinking, because production failures often live in the tail of the outcome distribution.
For robot manipulation, a reasonable workflow is: train or select a policy, collect representative action trajectories, run nominal world-model rollouts, run StressDream with task-specific failure prompts, review videos and history.json, then downweight or remove risky actions before real-world deployment. It does not replace real robot validation, but it can reduce the number of obviously risky actions that reach the hardware.


