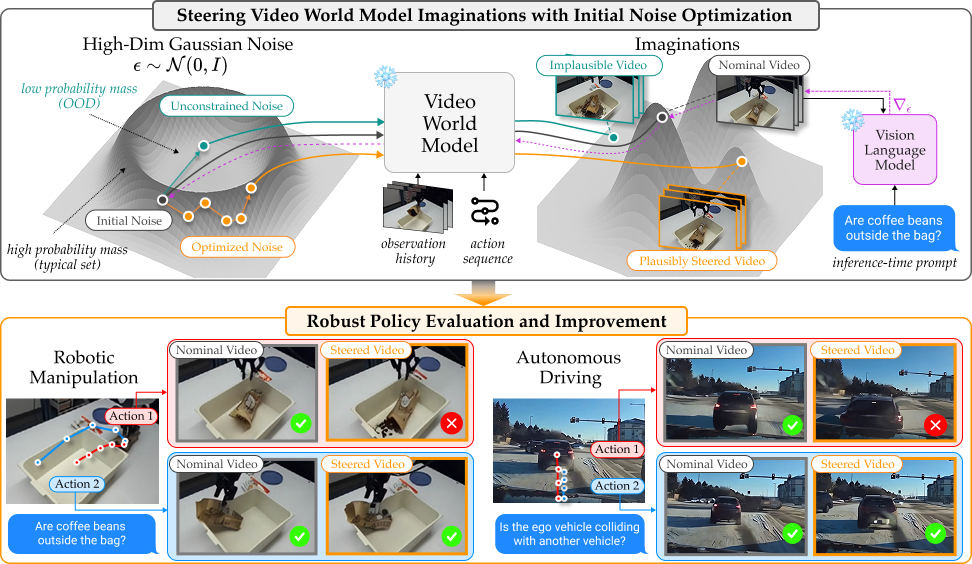
StressDream giải quyết vấn đề gì?
Khi một robot arm học manipulation policy bằng imitation learning hoặc VLA, demo thành công thường che giấu nhiều rủi ro. Một action có thể thành công trong trajectory được ghi lại, nhưng nếu object trượt nhẹ, túi bị nghiêng hơn một chút, hoặc gripper thả cao hơn vài cm, outcome có thể chuyển thành failure. Trước khi deploy policy thật, team thường phải chạy nhiều rollout vật lý để hỏi: action này có ổn không, có làm đổ hạt cà phê không, có làm rơi dao khỏi mép bàn không, có kéo nhầm utensil khiến vật phía trên rơi không?
StressDream đưa câu hỏi đó vào một bước kiểm thử bằng video world model. Paper gốc có tiêu đề StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement, do Junwon Seo, Sushant Veer, Ran Tian, Wenhao Ding, Apoorva Sharma, Karen Leung, Edward Schmerling, Marco Pavone và Andrea Bajcsy công bố trên arXiv ngày 29/05/2026. Project page nằm tại junwon.me/StressDream và code chính thức ở CMU-IntentLab/StressDream.
Ý tưởng rất trực tiếp: thay vì chỉ sampling vài video rollout "nominal" từ world model, StressDream tối ưu initial noise của diffusion video world model để ép model tưởng tượng ra một outcome có impact cao nhưng vẫn plausible. Với manipulation, prompt có thể là:
Is the coffee bean spilled? Respond with a single word: Yes or No.
Nếu action sequence thật sự có rủi ro làm đổ hạt cà phê, world model được steer sẽ tìm thấy một video tương lai trong đó failure xảy ra. Nếu scene không hỗ trợ failure đó, ví dụ túi đóng kín hoặc candy dính không dễ rơi, StressDream không nên bịa ra failure phi lý. Điểm này quan trọng: mục tiêu không phải tạo video xấu bằng mọi giá, mà là tìm worst-case plausible future.
Nếu bạn đã quen với Diffusion Policy, VLA models, hoặc RISE world model cho VLA, StressDream là một mảnh ghép rất thực dụng: nó không thay policy chính, cũng không yêu cầu robot thử thêm hàng nghìn lần ngoài đời. Nó thêm một "phòng stress-test" bằng imagination giữa bước training và deploy.
Tóm tắt paper trong 5 phút
Video world model nhận observation history và future action sequence, rồi sinh future observations. Với robot manipulation, observation thường gồm nhiều camera RGB, có thể có wrist camera và proprioceptive state. Action có thể là joint positions, end-effector poses hoặc action chunks. Trong StressDream, module manipulation dùng Ctrl-World, một controllable generative world model cho robot manipulation, trained trong setup DROID. Theo paper, Ctrl-World dự đoán 5 future frames từ 3 camera views ở độ phân giải 192 x 320, conditioned on joint-position actions, với noise dimension 57,600.
Vấn đề của rollout nominal là nó thường quá lạc quan. Một diffusion world model có thể học phân phối nhiều tương lai, nhưng khi ta sampling một noise ngẫu nhiên, ta chỉ thấy một tương lai. Nếu failure hiếm nhưng plausible, random sampling có thể bỏ sót. Sampling nhiều hơn giúp một phần, nhưng chi phí tăng nhanh vì mỗi video generation đắt.
StressDream xem initial Gaussian noise như một biến điều khiển:
observation history + action sequence + initial noise
|
v
diffusion video world model
|
v
future video rollout
Với conditioning cố định, video sinh ra là hàm của initial noise. Vì vậy thay vì lấy noise ngẫu nhiên, StressDream tối ưu noise bằng gradient để video đi về phía target event do text prompt mô tả.
Pipeline đầy đủ:
Initial image(s) + action trajectory
|
v
Sample initial Gaussian noise epsilon
|
v
Video world model generates multi-view rollout
|
v
VLM reads rollout + failure prompt
|
v
Semantic score: log P(Yes) - log P(No)
|
v
Plausibility regularizer keeps epsilon in Gaussian typical set
|
v
Update epsilon and repeat
|
v
Steered plausible failure video, if such failure is supported
Kiến trúc kỹ thuật
StressDream có ba phần chính.
| Thành phần | Vai trò | Trong manipulation demo |
|---|---|---|
| Video world model | Sinh video tương lai conditioned on action | Ctrl-World |
| Semantic objective | Chấm video có chứa target event không | Qwen3-VL-4B-Instruct |
| Plausibility objective | Giữ noise không trôi khỏi phân phối Gaussian plausible | norm, isotropy, spectral whiteness |
1. Video world model
World model trong paper được biểu diễn như:
o_future ~ f_theta(. | o_history, a_future)
Trong đó o_history là observation history, a_future là action sequence sắp kiểm tra, và o_future là video rollout. Với diffusion model, quá trình generation bắt đầu từ noise epsilon ~ N(0, I) rồi denoise dần thành video latent. Khi o_history và a_future đã cố định, epsilon quyết định video nào được sinh ra.
Điểm khác giữa nominal và StressDream:
Nominal:
epsilon = random Gaussian noise
video = world_model(epsilon, observation, action)
StressDream:
epsilon = random Gaussian noise
for i in optimization_steps:
video = world_model(epsilon, observation, action)
reward = VLM(video, failure_prompt) + plausibility(epsilon)
epsilon = epsilon + lr * grad(reward)
Trong repo chính thức, StressDream có ba module: dubins/ cho synthetic Dubins car, vista/ cho autonomous driving, và ctrl_world/ cho robot manipulation. Bài này tập trung vào ctrl_world/.
2. Semantic objective bằng VLM
Paper dùng VLM để tạo objective có thể phân biệt các failure phức tạp trong video. Thay vì train một classifier riêng cho từng task, ta mô tả failure bằng text. VLM được prompt trả lời một token Yes hoặc No. Score semantic là:
C_sem(video, prompt) = log P(Yes | video, prompt) - log P(No | video, prompt)
Với manipulation, prompt có thể là:
Is the coffee bean spilled? Respond with a single word: Yes or No.
Nếu video càng giống cảnh hạt cà phê bị đổ, P(Yes) càng cao. Gradient từ score này được dùng để update noise. Trong implementation ctrl_world, Qwen3-VL đọc multi-view clip và trả về reward dựa trên margin giữa token Yes và No.
3. Plausibility objective
Nếu chỉ tối ưu reward VLM, noise rất dễ bị đẩy ra khỏi vùng mà diffusion model đã học. Video có thể trở nên artifact, vô lý, hoặc "hack" VLM. Paper gọi vấn đề này là noise đi ra khỏi typical set của Gaussian high-dimensional prior.
StressDream dùng regularizer để giữ noise giống noise Gaussian thật:
| Regularizer | Ý nghĩa trực giác |
|---|---|
| Norm concentration | Norm của noise nên gần sqrt(D) với D là số chiều |
| Isotropy | Các block noise sau permutation không nên có correlation lạ |
| Spectral whiteness | Power spectrum không nên sinh pattern tần số bất thường |
Trong ctrl_world/steering_config.yaml, các hệ số quan trọng gồm kl_coeff, kl_coeff_spherical, std_coeff, spectral_coeff, và std_permutation_coeff. Đây là phần giúp StressDream khác với "adversarial video generation". Nó không cố lừa VLM bằng mọi cách, mà cố tìm outcome xấu còn nằm trong distribution world model hỗ trợ.
Cài đặt StressDream cho manipulation
Repo chính thức tách mỗi domain thành environment riêng. Với manipulation:
conda env create -f ctrl_world/environment.yml
conda activate stressdream-ctrlworld
Theo README của ctrl_world, environment dùng Python 3.11, PyTorch 2.9.1 + CUDA 12.8, Diffusers 0.36, Transformers 4.57 và cần NVIDIA driver từ 520 trở lên. Full optimization với Qwen3-VL reward và noise optimization cần khoảng 20 GB VRAM. Trên máy ít VRAM hơn, bạn nên giảm interact_num, giảm iters, hoặc chạy nominal trước để debug data path.
Ba checkpoint chính cần tải:
| Checkpoint | Vai trò | Dung lượng tương đối |
|---|---|---|
ckpts/Ctrl-World/coffee_bag.pt |
Ctrl-World checkpoint cho demo StressDream | nhỏ hơn SVD |
ckpts/stable-video-diffusion-img2vid/ |
pretrained Stable Video Diffusion backbone | khoảng nhiều GB |
ckpts/clip-vit-base-patch32/ |
CLIP encoder | khoảng 600M |
Các lệnh theo README:
pip install -U huggingface_hub
mkdir -p ckpts/Ctrl-World
hf download junwon-seo/StressDream \
coffee_bag.pt --local-dir ckpts/Ctrl-World
hf download stabilityai/stable-video-diffusion-img2vid \
--local-dir ckpts/stable-video-diffusion-img2vid
hf download openai/clip-vit-base-patch32 \
--local-dir ckpts/clip-vit-base-patch32
Qwen3-VL-4B-Instruct sẽ được transformers tải tự động trong lần chạy đầu tiên, nên hãy chuẩn bị thêm vài GB disk và thời gian download.
Chạy demo đầu tiên
Repo có sẵn một trajectory mẫu:
ctrl_world/example_data/traj_0001.hdf5
Đây là task kiểu candy-coffee, gồm trajectory thật, end-effector states và 3 camera views đã được loader xử lý. Chạy steered imagination:
python ctrl_world/run_steering.py \
--hdf5_path ctrl_world/example_data/traj_0001.hdf5
Chạy baseline nominal để so sánh:
python ctrl_world/generate_nominal.py \
--hdf5_path ctrl_world/example_data/traj_0001.hdf5
Output của steered run nằm dưới:
outputs/ctrl_world_steering/<timestamp>/
├── step_0001_best.mp4
├── step_0002_best.mp4
├── ...
├── full_steered.mp4
├── history.json
└── optimized_noise.pt
Output của nominal run nằm dưới:
outputs/ctrl_world_nominal/<timestamp>/
├── step_0001_nominal.mp4
├── ...
├── full_nominal.mp4
└── history.json
Khi review kết quả, hãy mở full_nominal.mp4 và full_steered.mp4 cạnh nhau. Nominal cho bạn câu trả lời "một rollout bình thường trông như thế nào". Steered cho bạn câu trả lời "nếu tìm failure plausible theo prompt, world model có tìm được không".
Tùy chỉnh prompt cho task của bạn
Bạn có thể override instruction và Qwen prompt trực tiếp bằng CLI:
python ctrl_world/run_steering.py \
--hdf5_path ctrl_world/example_data/traj_0001.hdf5 \
--instruction "put the coffee bag into the container without spilling" \
--qwen_prompt "Is the coffee bean spilled? Respond with a single word: Yes or No."
Prompt tốt nên có ba đặc điểm:
| Nên làm | Không nên làm |
|---|---|
| Hỏi một failure cụ thể | Hỏi chung chung "task có fail không?" |
| Bắt VLM trả lời Yes/No | Yêu cầu VLM giải thích dài |
| Mô tả object đúng tên trong scene | Dùng từ mơ hồ khiến VLM đoán sai |
Ví dụ prompt theo task:
Is the knife dropped off the table edge? Respond with a single word: Yes or No.
Are the coffee beans outside the bag? Respond with a single word: Yes or No.
Does the top utensil fall while the bottom utensil is pulled? Respond with a single word: Yes or No.
Trong paper, nhóm tác giả dùng sáu task contact-rich: block stack, knife put, stacked utensil pick, coffee bean pour, open coffee bag, và open candy bag. Các failure text tương ứng xoay quanh rơi, đổ, trượt, thả cao, hoặc action quá gần mép.
Đọc steering_config.yaml
Config mặc định của ctrl_world có cấu trúc:
task:
instruction: "put the coffee bag into the container without spilling"
qwen_prompt: "Is the coffee bean spilled? Respond with a single word: Yes or No."
target_success: true
model:
task_type: replay
num_frames: 5
optim:
iters: 5
interact_num: 20
lr: 1.0
grad_scale: 100.0
noise_norm_threshold: 3.0
detach_latents: true
seed: 33
Các tham số beginner nên hiểu trước:
| Tham số | Tác dụng | Gợi ý |
|---|---|---|
num_frames |
Số frame world model sinh mỗi window | Giữ mặc định khi mới chạy |
interact_num |
Số rollout window autoregressive | Giảm để debug nhanh |
iters |
Số bước tối ưu noise mỗi window | Tăng nếu steering yếu, nhưng tốn VRAM/thời gian |
lr |
Learning rate cho noise | Quá cao dễ artifact |
grad_scale |
Scale gradient từ VLM reward | Tăng quá mức dễ reward hacking |
noise_norm_threshold |
Ngưỡng renormalize noise | Giúp noise không drift quá xa |
Trong run_steering.py, mỗi interact step lấy action chunk từ HDF5, normalize theo statistics, build conditioning latent 3 views, sinh noise mới, tối ưu noise qua nhiều iteration, lưu video tốt nhất, rồi lấy latent frame cuối làm conditioning cho step kế tiếp. Đây là lý do rollout có thể đi dài hơn một prediction window.
Training và inference: cần phân biệt rõ
StressDream không phải một recipe train world model từ đầu. Paper dùng các world model đã có hoặc đã fine-tune:
| Domain | World model | Dữ liệu/thiết lập |
|---|---|---|
| Dubins car | diffusion WM nhỏ | 4,000 random trajectories |
| Driving | Vista | PAI-AV và Nexar Collision Prediction Dataset |
| Robot manipulation | Ctrl-World | DROID setup, khoảng 150 teleoperation trajectories mỗi task, có success và failure |
Với người triển khai, có ba mức sử dụng:
Mức 1: chạy demo có sẵn
Dùng checkpoint + traj_0001.hdf5 để hiểu output.
Mức 2: stress-test trajectory nội bộ
Convert dữ liệu robot của bạn sang format HDF5 mà loader đọc được:
multi-view RGB, eef_states hoặc joint actions, gripper state.
Mức 3: fine-tune world model
Thu data success/failure cho task riêng, fine-tune Ctrl-World,
sau đó dùng StressDream để đánh giá action/policy.
Inference trong StressDream là quá trình steering. Bạn đưa vào observation/action, prompt failure, và nhận video steered. Training policy improvement là bước sau: dùng kết quả steering để reweight demonstrations. Paper fine-tune π0.5-DROID với 40 successful demonstrations mỗi task. Trajectory vẫn success dưới steering được weight 1.0; trajectory bị failure trong steered imagination bị weight 0.1. Cách này khuyến khích policy học action robust hơn, không chỉ action từng thành công trong một rollout may mắn.
Kết quả chính trong paper
Các kết quả đáng nhớ:
| Thí nghiệm | Kết quả |
|---|---|
| Robust policy evaluation | failure detection recall tăng từ 54% lên 94% |
| Policy improvement | success rate của π0.5 tăng từ 39% lên 71% |
| Plausibility | StressDream không ép closed bag hoặc sticky candy tạo spill phi lý |
| Baseline | Best-of-N random sampling vẫn bỏ sót nhiều failure hiếm |
Diễn giải thực dụng: StressDream không chứng minh policy chắc chắn an toàn ngoài đời. Nó chứng minh rằng nếu world model đã học một failure plausible, steering sẽ tìm failure đó hiệu quả hơn rollout nominal. Đây là một lớp kiểm thử hữu ích trước khi robot thật chạm object.
Checklist deploy an toàn hơn
Trước khi đưa StressDream vào workflow nội bộ, hãy dùng checklist sau:
[ ] World model đã nhìn thấy đủ scene, object, camera view gần giống deploy
[ ] Có failure data hoặc ít nhất outcome distribution có support cho failure cần tìm
[ ] Prompt failure cụ thể, trả lời Yes/No
[ ] Chạy nominal và steered song song
[ ] Human review một subset video để phát hiện VLM reward hacking
[ ] Log history.json: reward, p_yes, p_no, noise_norm, regularizer
[ ] Không dùng StressDream như safety proof duy nhất
[ ] Chỉ deploy policy sau khi qua thêm test thật có giám sát
Hãy nhớ limitation paper nêu rõ: "plausible" ở đây nghĩa là plausible theo world model, không tự động bằng physically plausible ngoài đời. Nếu world model thiếu data về chất lỏng, deformable object, contact nhỏ, occlusion hoặc gripper slip, StressDream không thể tạo ra rủi ro mà model chưa học.
Kết luận
StressDream là một cách rất đáng chú ý để biến video world model thành công cụ kiểm thử policy. Thay vì hỏi "policy làm gì trong rollout trung bình?", nó hỏi "với cùng action đó, có plausible future nào gây failure không?". Câu hỏi thứ hai gần với tư duy deploy robot hơn nhiều, vì production failure thường nằm ở tail case.
Với robot manipulation, workflow hợp lý là: train hoặc dùng sẵn policy, thu một tập action trajectories đại diện, chạy nominal world-model rollout, chạy StressDream với prompt failure, review video và history.json, sau đó reweight hoặc loại bỏ action dễ fail trước khi deploy. Đây không thay thế real-world validation, nhưng có thể giảm số lần robot thật phải thử những action đã lộ rủi ro trong imagination.


