What This Article Is For
The first three articles moved from the WholeBodyVLA pipeline map, to video data for LAMs, to retargeting human motion onto a humanoid robot. Article 4 turns to the more expensive but unavoidable part of a real WholeBodyVLA system: whole-body teleoperation on a humanoid. Action-free video helps train latent actions. Retargeted motion helps train or stress-test a controller. But real robot data still needs a collection station that records operator commands, robot state, policy outputs, and network/deployment state while the robot interacts with real objects.
This article compares two concrete stacks:
- TWIST, a Teleoperated Whole-Body Imitation System for Unitree G1. The most useful deployment pattern is its split between high-level motion servers and low-level controllers through Redis:
deploy_real/server_high_level_motion_lib.py,server_low_level_g1_sim.py,server_low_level_g1_real.py, and the realtime legacy scriptserver_motion_optitrack_v2 (legacy).py. - HOMIE, an isomorphic cockpit for humanoid loco-manipulation. The most useful pattern is its operator hardware, including exoskeleton arms, motion-sensing gloves, and a pedal, plus the deployment path
HomieDeploy/g1_gym_deploy/scripts/deploy_policy.pyusing LCM, ONNX Runtime,StateEstimator,LCMAgent, andDeploymentRunner.
If you are reading the series in order, revisit Mapping the WholeBodyVLA Pipeline, Egocentric Video and LAMs, and Retarget AMASS and GMR to Robots. This article prepares the ground for RL and LMO, because a good teleop station does not only collect VLA demonstrations; it also lets you inspect whether the low-level controller is preserving balance. Outside this series, the WholeBodyVLA ICLR 2026 analysis and WholebodyVLA open-source guide provide broader context.
Why Whole-Body Teleop Is Not Arm Teleop
Arm teleoperation usually controls an end-effector, a gripper, and a camera. The robot may stand on a table or move on a slow base. A humanoid is different. Arm motion changes the center of mass. Footsteps change the view. Squatting changes reachability and contact. The physical robot also has actuator limits, network latency, battery state, safety modes, and damping states. If you only log images and joint targets, you miss the most important part: why the robot did not fall while the hands were doing useful work.
A WholeBodyVLA data station should separate four streams:
| Data stream | TWIST/HOMIE examples | Why it should be separate |
|---|---|---|
| Operator command | Motion retargeting from MoCap, exoskeleton arm pose, glove, pedal, joystick | Captures human intent without mixing it with robot reaction |
| Robot state logging | Joint position, joint velocity, IMU, root orientation, hand state, camera | Used for decoder training, debugging, and replay |
| Policy inference | JIT policy in TWIST, ONNX policy in HOMIE | Records the exact controller input/output |
| Unitree G1 network deployment | Ethernet interface in TWIST real deployment, Wi-Fi/SDK2/LCM in HOMIE | This is often where real-robot sessions fail: IP, interface, control process, safety mode |
Beginners often want one script that reads operator input, runs a policy, sends robot actions, and logs camera frames. That can produce a quick demo, but it is hard to debug. If the robot jitters, you cannot tell whether the issue came from retargeting, policy inference, state estimation, latency, or the Unitree network. TWIST and HOMIE show two different ways to avoid that confusion.
A minimal station should look like:
operator process ---> command bus ---> policy process ---> robot interface
^ |
| v
state logger <--- robot state
TWIST: Splitting High-Level and Low-Level Control With Redis
The TWIST paper presents a system that teleoperates humanoids using realtime whole-body human data and a single neural-network controller. It trains the controller with RL plus behavior cloning, uses retargeted motion and real MoCap data, and deploys on Unitree G1 with 29 DoF for locomotion, whole-body manipulation, legged manipulation, and expressive movement. At the implementation level, the clearest lesson is how the repository separates high-level control from low-level control.
The TWIST README describes sim2sim verification as follows: first run the high-level motion server to warm up Redis, then run the low-level simulation server server_low_level_g1_sim.py with a JIT model. The README explicitly states the reason: high-level control, meaning teleop or motion targets, is separated from low-level control, meaning the RL policy. When the low-level server starts, the robot can simply stand still; then the high-level server streams motion for the policy to track.
The flow is:
Retargeted motion file / MoCap stream
|
v
server_high_level_motion_lib.py
|
| Redis keys:
| action_mimic_g1
| action_hand_g1
v
server_low_level_g1_sim.py or server_low_level_g1_real.py
|
| JIT policy + proprio history
v
PD target / robot action
|
v
MuJoCo simulation or real Unitree G1
This is very suitable for data collection. You can replace the high-level source with a motion file, OptiTrack, GMR, PICO, joystick, or a VLA decoder without rewriting the low-level controller. Conversely, you can run the same high-level command through simulation first, then move to the real robot once the command stream is clean.
server_high_level_motion_lib.py: From Motion to mimic_obs
server_high_level_motion_lib.py reads a .pkl motion file through MotionLib, samples future frames according to tar_obs_steps, and builds mimic_obs. In the code, mimic_obs includes fields such as root height, roll/pitch/yaw, root velocity in the root frame, yaw angular velocity, and joint positions. For G1, the script also handles wrist IDs so wrist roll positions are inserted in the expected order.
The main loop runs with control_dt = 0.02, or about 50 Hz. At each step, the server writes two Redis keys:
redis_client.set(f"action_mimic_{args.robot}", json.dumps(mimic_obs_list))
redis_client.set(f"action_hand_{args.robot}", json.dumps(DEFAULT_ACTION_HAND[args.robot].tolist()))
With --vis, the script opens a MuJoCo viewer, sets qpos from the root pose and joint positions, and tracks the pelvis with the camera. On keyboard interrupt or exit, the server interpolates from last_mimic_obs back to DEFAULT_MIMIC_OBS over about two seconds. That small detail is worth keeping in a real station: when operator input stops, the command should return to a safe default instead of freezing at an arbitrary final pose.
For a data logger, the high-level server is where you should record:
| Field | What to log |
|---|---|
motion_file or source stream |
File path, MoCap device, take ID, operator ID |
Raw mimic_obs |
The vector published to Redis |
| Publish timestamp | Use a monotonic clock, not only a frame index |
| Visualization state | Whether --vis was enabled and which XML model was used |
| Fallback/default event | When the server returned to default because of stop or error |
server_low_level_g1_sim.py: Policy Inference in MuJoCo
The low-level simulation server is the easiest version to debug before touching the physical robot. It loads a TorchScript policy with torch.jit.load(policy_path), opens the MuJoCo XML g1_sim2sim_with_wrist_roll.xml, sets sim_dt = 0.001, and uses sim_decimation = 20. Physics can step at 1 kHz, while policy inference happens every 20 steps, or 50 Hz. This is a common whole-body-control pattern: the physics/control loop is fast, while the learned policy loop is slower but still fast enough for locomotion.
At every policy step, the server:
- Reads
qpos,qvel, IMU orientation, and angular velocity from MuJoCo. - Builds proprioception from scaled angular velocity, roll/pitch, joint-position error from default, scaled joint velocity, and
last_action. - Publishes
state_body_g1andstate_hand_g1to Redis. - Reads
action_mimic_g1from Redis. - Concatenates
action_mimic, current proprioception, and a 10-frame history buffer. - Runs the JIT policy, clips the action, scales it, and adds the default pose to obtain PD targets.
- Computes torque from stiffness/damping, clips by torque limits, and writes to
data.ctrl.
Pseudocode:
while sim_running:
robot_state = read_mujoco_state()
proprio = build_proprio(robot_state, last_action)
redis.set("state_body_g1", proprio)
mimic = redis.get("action_mimic_g1")
obs = concat(mimic, proprio, history)
raw_action = policy(obs)
pd_target = default_dof_pos + action_scale * clip(raw_action)
torque = kp * (pd_target - q) - kd * qdot
mujoco.step(torque)
Because the low-level sim also publishes state back to Redis, you can write an independent logger that polls or subscribes to Redis without modifying the controller. For beginners, this is the key design lesson: logging should not sit so deep inside the policy loop that it slows the controller down. If you need to record large data such as camera streams, run a separate process and align streams with timestamps.
server_low_level_g1_real.py: Same Logic, Real Robot
server_low_level_g1_real.py keeps the same structure but replaces MuJoCo with G1RealWorldEnv. It loads robot_control/configs/g1.yaml, accepts --net for the network interface, loads the TorchScript policy, and runs a robot reset sequence. The code contains stages such as zero torque, move to default position, default position state, and a Select button exit condition on the remote.
The main loop reads real robot state:
dof_pos, dof_vel, quat, ang_vel = env.get_robot_state()
It then builds obs_proprio, publishes state_body_g1, reads action_mimic_g1, concatenates history, runs the policy, computes target_dof_pos, and calls:
env.send_robot_action(
target_dof_pos,
kp_scale,
kd_scale,
left_wrist_roll=wrist_dof_pos[0],
right_wrist_roll=wrist_dof_pos[1],
)
The TWIST README adds the G1 sim2real path: connect the robot and laptop by Ethernet, set the laptop IP to 192.168.123.222 with netmask 255.255.255.0, ping the robot at 192.168.123.164, enter dev mode with L2+R2, then run server_low_level_g1_real.py --policy_path ... --net YOUR_NET_INTERFACE_TO_UNITREE_ROBOT. The order matches simulation: start the low-level controller first, then control the robot through the high-level motion server.
In a real station, log the network interface and robot mode:
robot:
model: unitree_g1
net_interface: eno1
laptop_ip: 192.168.123.222
robot_ip: 192.168.123.164
mode_entry: L2+R2 dev mode
low_level_script: server_low_level_g1_real.py
policy:
format: torchscript
path: assets/twist_general_motion_tracker.pt
frequency_hz: 50
If a trajectory looks stable in simulation but fails on the robot, this log helps separate policy issues from deployment issues.
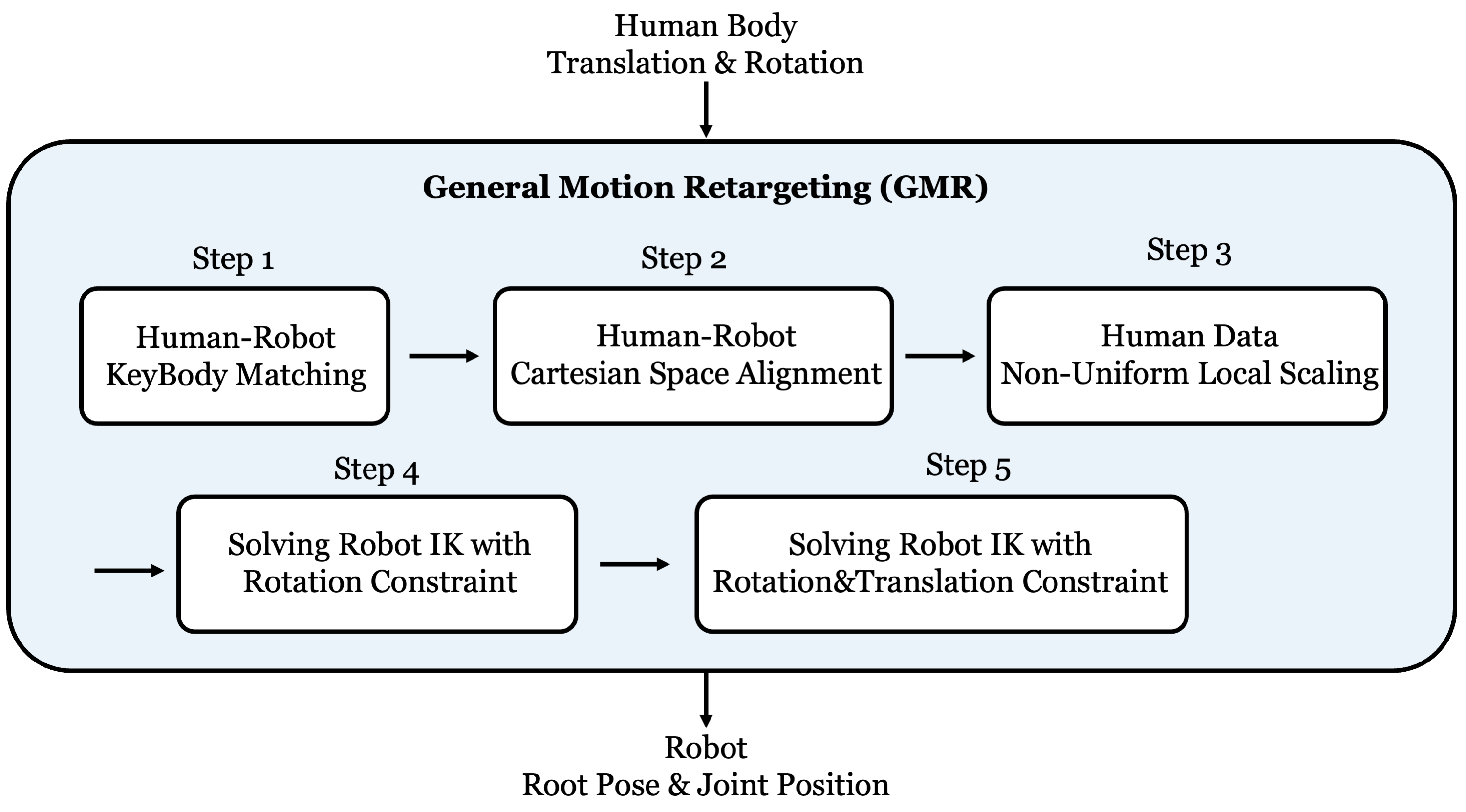
The Legacy OptiTrack Script: Realtime Retargeting Before the New GMR Path
The TWIST README mentions a legacy realtime script from May 2025: deploy_real/server_motion_optitrack_v2 (legacy).py. It also says the authors later upgraded to GMR for realtime teleop, so the older script is mainly a reference. It is still valuable because it shows what a realtime high-level server must do.
The legacy script connects to OptiTrack, uses MinkRetarget, keeps a Vicon/OptiTrack buffer, retargets each frame to robot qpos, uses an inverse-dynamics helper to obtain qdot, and converts qpos/qdot into command vectors through _get_mimic_obs(qpos, qdot). It also includes a JoyConController, a Speaker, qdot smoothing with a deque, a short seed buffer to avoid unstable startup frames, and Redis publishing.
The takeaway is not "use the legacy script in production." The takeaway is that a realtime teleop high-level server should contain these layers:
| Layer | Role |
|---|---|
| Sensor client | Read OptiTrack/Vicon/PICO/exoskeleton data |
| Retargeter | Map human pose to valid robot qpos |
| Derivative estimator | Estimate qdot/root velocity with smoothing |
| Safety input | JoyCon/remote stop/reset, voice cue, or UI cue |
| Command publisher | Write timestamped mimic_obs to the command bus |
| Preview | MuJoCo viewer so the operator can inspect targets before the robot moves |
If you replace the legacy script with GMR, the architecture remains the same. Only the retargeter and input adapter change.
HOMIE: Isomorphic Cockpit Instead of Pure MoCap Retargeting
HOMIE solves the same whole-body teleoperation problem, but chooses a different operator interface. The paper describes a cockpit composed of a loco-manipulation policy and exoskeleton-based hardware. The hardware includes isomorphic exoskeleton arms, motion-sensing gloves, and a pedal. The operator does not need to physically walk with the robot to command locomotion; the pedal captures locomotion commands, while the operator's upper body controls upper-body pose. The paper emphasizes that the policy can walk and squat to specified heights while accommodating continuously changing upper-body poses.
Compared with TWIST, HOMIE is less like "capture a full human body and retarget every frame" and more like a cockpit with divided responsibilities:
exoskeleton arms ---> upper-body pose command
motion gloves ---> dexterous hand command
pedal ---> locomotion / height command
RL policy ---> lower-body balance, walking, squatting
Unitree SDK2 ---> robot actuation
Because the hardware is isomorphic, HOMIE aims to reduce retargeting error compared with pure vision/IK systems. The paper also reports that data collected by the cockpit can be used for imitation learning. That is exactly the WholeBodyVLA use case: you do not only remote-control the robot for a demo; you create a dataset with cleaner command/state/action streams for later autonomy.
deploy_policy.py: ONNX Inference in HOMIE
In HomieDeploy/g1_gym_deploy/scripts/deploy_policy.py, the script creates an LCM bus:
lc = lcm.LCM("udpm://239.255.76.67:7667?ttl=255")
Then load_and_run_policy() loads an ONNX checkpoint:
ckpt_path = "/home/unitree/deploy/deploy.onnx"
The main components are:
| Component | Role |
|---|---|
StateEstimator(lc) |
Reads and estimates robot state through LCM |
RCControllerProfile(dt=1/50, state_estimator=se) |
Produces a 50 Hz command profile |
LCMAgent(se, command_profile) |
Connects command/state to hardware |
HistoryWrapper(hardware_agent) |
Adds observation history |
onnxruntime.InferenceSession |
Runs the ONNX policy |
DeploymentRunner |
Registers agent, policy, command profile, and runs the loop |
The inference wrapper is short:
def load_onnx_policy(path):
model = ort.InferenceSession(path)
def run_inference(input_tensor):
ort_inputs = {model.get_inputs()[0].name: input_tensor.cpu().numpy()}
ort_outs = model.run(None, ort_inputs)
return torch.tensor(ort_outs[0], device="cuda:0")
return run_inference
For a data station, deploy_policy.py is HOMIE's low-level policy runner. The cockpit and robot-control binaries create command/state in other processes. The policy runner should not own heavy logging; it should expose or mirror observations and actions to a separate recorder.
HOMIE Deployment: PC, G1, Dex-3, and SDK2
The HomieDeploy README says deployment requires a Unitree G1 with Dex-3 hands and a PC; communication between robot and PC uses Wi-Fi. On the robot, the authors recommend connecting a monitor, keyboard, and mouse to the G1 board, installing PyTorch for Nvidia Jetson Orin, installing requirements, building the Unitree SDK2 C++ binaries for g1_control.cpp and hand_control.cpp, and installing g1_gym_deploy with pip install -e.
The README deployment sequence is:
# robot terminal 3
cd unitree_sdk2/build/bin && ./hand_control
# robot terminal 4
cd unitree_sdk2/build/bin && ./g1_control eth0 # or eth1
# robot terminal 5
python g1_gym_deploy/scripts/deploy_policy.py
Before deployment, the README asks users to close G1's initial control process with L1+A, L2+R2, L2+A, L2+B; then place the robot on the ground and press R2 to make it stand, then press R2 again. These operational details belong in the station runbook. If they are not recorded, two sessions with the same policy but different robot modes can produce different results.
A simple runbook:
1. Confirm the workspace is clear and cables cannot catch the robot's feet.
2. Confirm PC and robot can reach each other over Wi-Fi or the selected interface.
3. Close the initial control process with the required remote sequence.
4. Start hand_control.
5. Start g1_control with the correct interface.
6. Start deploy_policy.py.
7. Put the robot on the ground and use R2 to stand.
8. Start the cockpit session and logger.
9. On failure: stop operator commands first, then return the robot to zero torque/default by runbook.
Comparing TWIST and HOMIE for Data Collection
| Criterion | TWIST | HOMIE |
|---|---|---|
| Main operator interface | Motion file, MoCap/OptiTrack legacy, GMR realtime according to README | Exoskeleton arms, gloves, pedal, joystick/control profile |
| Bus/process split | Redis between high-level command and low-level policy | LCM, SDK2 binaries, ONNX policy runner |
| Deployment policy format | TorchScript JIT .pt |
ONNX deploy.onnx |
| Typical frequency | control_dt = 0.02, low-level inference at 50 Hz |
control_dt = 1/50, policy runner at 50 Hz |
| Simulation debugging | MuJoCo low-level sim server and high-level motion visualization | Isaac Gym training; deployment README focuses on real robot |
| Robot target in instructions | Unitree G1, sim2real over Ethernet | Unitree G1 + Dex-3, PC/robot over Wi-Fi |
| Strength for WholeBodyVLA | Clear split for swapping command sources: motion lib, GMR, VLA decoder | Ergonomic cockpit for long loco-manipulation tasks |
| Main risk | Local Redis, retargeting latency, sim-real mismatch, default command management | Complex cockpit hardware, multiple robot processes, SDK2/LCM/ONNX dependencies |
If your goal is controller and retargeting research, TWIST is a very clear template because high-level and low-level components are separated by Redis and the sim server is concrete. If your goal is long task demonstrations with real objects and simultaneous hand/foot operation, HOMIE suggests a more ergonomic operator interface: the pedal frees the upper body, the exoskeleton arms reduce IK ambiguity, and gloves handle hand commands.
In practice, you can combine the ideas. For example, use a HOMIE-like cockpit/operator UI but publish commands through a TWIST-like bus; or use a TWIST-style low-level policy runner and replace the high-level motion library with an exoskeleton adapter. The important point is to keep process boundaries clear.
Blueprint: A Minimal WholeBodyVLA Data Station
A beginner-friendly station can start like this:
Machine A: operator PC
- MoCap/GMR or exoskeleton/glove adapter
- preview viewer
- command publisher
Machine B: robot/control laptop or G1 onboard
- low-level policy runner
- Unitree SDK2/G1 interface
- robot safety monitor
Machine C: logger/NAS
- camera recorder
- Redis/LCM mirror recorder
- metadata writer
Each episode should have a manifest:
episode_id: 2026-06-10-g1-cabinet-0007
task: open_cabinet_and_pick_box
operator:
interface: twist_gmr_mocap
operator_id: op_02
robot:
model: unitree_g1
hands: dex3
network: ethernet_eno1
policy:
stack: twist
low_level: server_low_level_g1_real.py
checkpoint: twist_general_motion_tracker.pt
streams:
command: action_mimic_g1
robot_state: state_body_g1
hand_state: state_hand_g1
cameras:
- head_rgb
- wrist_left_rgb
- wrist_right_rgb
timing:
policy_hz: 50
camera_hz: 30
quality_flags:
success: true
falls: false
operator_reset: false
You do not need to build everything in the first week. But if you do not define the manifest early, the dataset becomes hard to use after 100 episodes. For WholeBodyVLA, the goal is not only to replay video. You will eventually need to join images, language instructions, operator commands, robot proprioception, action outputs, and outcomes to train decoders or analyze failure.
Safety and Data-Quality Checklist
Before collection:
[ ] The robot has a clear fall zone; people stand outside the arm/leg sweep area.
[ ] A stop button or remote stop has been tested for real.
[ ] The low-level controller runs in simulation with the same command stream.
[ ] The logger does not slow down the policy loop.
[ ] Machine clocks are synchronized or every stream has a monotonic timestamp.
[ ] The episode manifest is written before the robot starts moving.
During collection:
[ ] The command bus updates steadily without long gaps.
[ ] Robot state is published at the expected frequency.
[ ] Cameras do not drop too many frames.
[ ] Operator reset/default events are marked.
[ ] Network/interface errors are written to metadata.
After collection:
[ ] Command and state can be replayed on the same timeline.
[ ] Success, failure, and reset episodes can be separated.
[ ] Operator command can be compared with policy output.
[ ] The dataset can be converted into a training format without guessing field names.
Conclusion
TWIST and HOMIE are not only impressive teleoperation demos. They are architecture templates for humanoid data collection. TWIST teaches a clean split between motion/high-level command and low-level RL policy through Redis, with MuJoCo verification before Unitree G1 deployment. HOMIE teaches how to think about the operator cockpit: exoskeleton arms, gloves, pedal, ONNX policy runner, LCM, and Unitree SDK2 working together as a practical loco-manipulation teleop system.
If you are building data for WholeBodyVLA, the main lesson is simple: do not mix operator command, robot state, policy inference, and deployment network into one opaque block. Separate them, log each stream with timestamps, maintain a safety runbook, and always keep a simulation or preview path before the real robot receives commands. Then teleop data becomes more than a demo. It becomes the foundation for decoder training, VLA fine-tuning, LMO evaluation, and sim-to-real failure analysis in the next parts of the series.