Mục tiêu của bài này
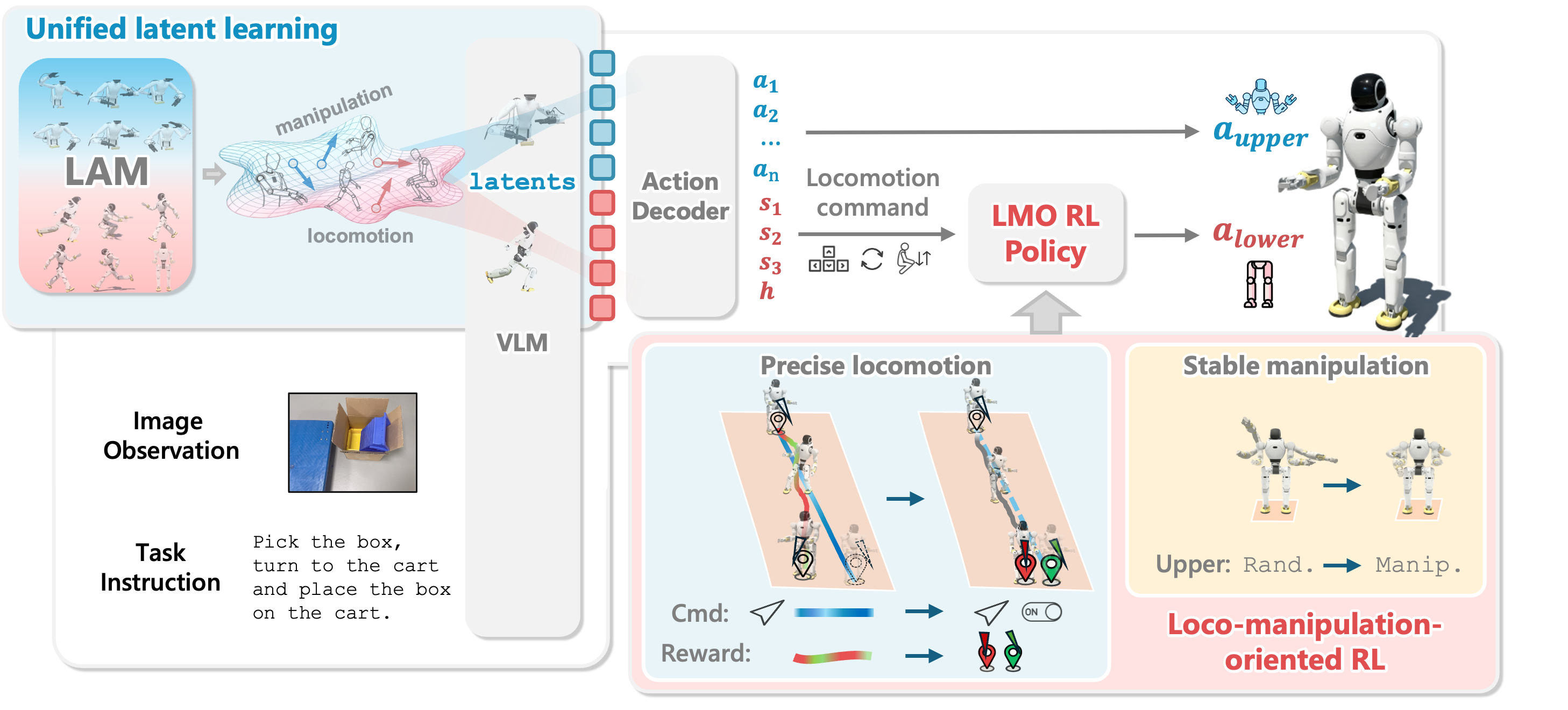
Bài 1 đã dựng bản đồ pipeline WholeBodyVLA: ảnh ego và lệnh ngôn ngữ đi vào VLA, hai Latent Action Model (LAM) tạo supervision rời rạc, decoder nhẹ xuất lệnh robot ở khoảng 10 Hz, rồi LMO policy thực thi locomotion ở 50 Hz. Bài 2 đi vào câu hỏi thực dụng hơn: nếu chưa có hệ MoCap, chưa có humanoid thật để teleop nhiều giờ, ta có thể bắt đầu thu loại dữ liệu nào trước?
Câu trả lời của WholeBodyVLA rất đáng chú ý: ở giai đoạn latent pretraining, locomotion LAM có thể học từ video egocentric không có action label. Paper mô tả một pipeline thu dữ liệu giá thấp: một người vận hành, một camera monocular gắn trên đầu, các motion primitive liên quan tới humanoid như tiến, lùi, bước ngang, xoay tại chỗ và squat, cộng với chuyển động có mục tiêu về phía các điểm sẽ thao tác hoặc tiếp xúc. Manipulation LAM thì được train riêng trên dữ liệu manipulation robot thật, trong paper là AgiBot World, còn locomotion LAM dùng video ego locomotion tự thu.
Mục tiêu của bài này là giúp bạn thiết kế protocol quay video ego cho locomotion LAM mà beginner có thể làm theo. Ta không thay thế toàn bộ teleoperation; phần đó sẽ được bàn riêng trong bài 4. Nhưng ta có thể thu sớm một corpus video đủ sạch, đủ đúng góc nhìn, đủ primitive và đủ gắn với manipulation để model học "từ vựng locomotion" trước khi tốn tiền vào robot trajectory.
Nếu bạn cần bối cảnh research rộng hơn trước khi đi vào protocol, xem thêm phân tích WholeBodyVLA ICLR 2026 và hướng dẫn kiến trúc WholebodyVLA. Bài hiện tại là bước dữ liệu đầu tiên: biến recipe action-free trong paper thành một quy trình quay có thể kiểm tra được.
Vì sao lại là video ego action-free?
Trong robot learning, dữ liệu đắt nhất thường không phải là video, mà là action-aligned trajectory: joint target, gripper command, base command, lực tiếp xúc, trạng thái robot và timestamp được đồng bộ. Thu loại dữ liệu này cần robot, teleoperator, phần mềm điều khiển, người giám sát an toàn, reset scene và nhiều lần thử hỏng. Với humanoid loco-manipulation, chi phí còn cao hơn vì robot phải vừa đi, vừa giữ thăng bằng, vừa dùng tay.
WholeBodyVLA dùng latent action learning để giảm điểm nghẽn đó. LAM nhìn hai frame liên tiếp và học một mã rời rạc mô tả thay đổi hình ảnh giữa frame trước và frame sau. Mã này không phải action motor thật, nhưng nó có thể đóng vai trò pseudo-action label cho VLA trong giai đoạn pretraining. Khi video cho thấy người đội camera tiến về bàn, xoay sang xe đẩy, hạ thấp người để tiếp cận thùng, hoặc dừng trước tay nắm cửa, LAM học các thay đổi thị giác tương ứng với "tiến", "xoay", "squat", "dừng gần mục tiêu".
Điểm quan trọng: "action-free" không có nghĩa là video nào cũng dùng được. Paper nhấn mạnh locomotion data phải là manipulation-aware locomotion, tức người quay không chỉ đi lung tung. Họ phải di chuyển theo cách tạo tiền điều kiện cho thao tác: đến gần vật sẽ cầm, quay người để đối diện contact target, squat xuống để với tới thùng hoặc giỏ, bước ngang để căn vị trí trước khi đặt vật. Video như vậy trực tiếp phục vụ loco-manipulation learning, thay vì chỉ dạy model nhìn cảnh trôi qua.
Tách locomotion LAM và manipulation LAM
WholeBodyVLA không train một LAM chung cho mọi video. Paper giải thích rằng manipulation và locomotion tạo ra pattern thị giác rất khác nhau. Với manipulation video, camera thường gần như tĩnh; thay đổi nằm ở tay, gripper, vật thể và contact point. Với locomotion video, camera di chuyển liên tục; cả scene dịch chuyển vì đầu hoặc thân đang tiến, xoay, bước ngang hoặc squat. Nếu trộn hai loại vào một LAM chung, model dễ học attention mâu thuẫn: lúc cần nhìn rất cục bộ vào tay, lúc cần nhìn toàn scene để hiểu ego-motion.
Vì vậy protocol của bạn nên có hai bucket ngay từ đầu:
| Bucket | Dữ liệu chính | Mục tiêu học | Không nên trộn bừa |
|---|---|---|---|
| Locomotion LAM | Video ego khi người/robot di chuyển trong scene | Tiến, lùi, bước ngang, xoay, squat, dừng gần target | Clip chỉ quay tay thao tác tại bàn |
| Manipulation LAM | Video thao tác vật thể, tốt nhất từ robot dataset hoặc robot thật | Grasp, lift, place, push, pull, contact affordance | Clip đi bộ dài không có thao tác rõ |
| Teleop fine-tuning | Trajectory có robot state và command thật | Ground latent thành joint target và locomotion command | Video action-free chưa đồng bộ action |
Với bài này, ta tập trung vào bucket locomotion LAM. Tuy nhiên protocol quay vẫn phải "aware" về manipulation. Mục tiêu không phải tạo dataset đi bộ thể thao; mục tiêu là tạo dataset về cách cơ thể tiến đến vị trí thao tác.
Thiết bị tối thiểu
Paper nói pipeline locomotion có thể dùng một operator với camera monocular gắn trên đầu, tránh MoCap hoặc teleoperation đắt đỏ. Trong lab nhỏ, bạn có thể bắt đầu với cấu hình rất đơn giản:
| Thành phần | Khuyến nghị tối thiểu | Ghi chú thực tế |
|---|---|---|
| Camera | Action cam, điện thoại gắn head strap, hoặc RGB camera nhẹ | Ưu tiên hình ổn định, góc nhìn gần eye-level |
| Mount | Head strap, helmet mount, chest-to-head adapter nếu cần | Head-mounted tốt hơn chest-mounted cho ego view giống robot head |
| Video | 1080p, 30 fps là điểm khởi đầu hợp lý | 60 fps tốt hơn nếu chuyển động nhanh, nhưng tốn storage |
| Audio | Không bắt buộc | Có thể dùng để đọc instruction, nhưng cần xử lý privacy |
| Time sync | Đồng hồ hệ thống hoặc clap marker ở đầu clip | Hữu ích khi sau này nối metadata, instruction, scene log |
| Scene props | Bàn, kệ, hộp, giỏ, xe đẩy, tay nắm, vật cần nhặt | Chọn vật có ý nghĩa contact rõ |
Camera đội đầu không cần RGB-D cho giai đoạn locomotion LAM, vì công thức action-free của paper nhấn mạnh monocular camera. Nếu bạn có RGB-D như RealSense D435i thì tốt, nhưng đừng biến yêu cầu phần cứng thành rào cản. Với beginner, điều quan trọng hơn là giữ video có thứ tự thời gian sạch, góc nhìn tương tự robot head và kịch bản chuyển động đúng.
Thiết kế primitive cần quay
WholeBodyVLA nhắc đến các primitive lõi cho loco-manipulation: advancing, turning và squatting. Appendix còn nói task evaluation kết hợp forward/backward walking, lateral stepping, in-place turning và squatting với manipulation một tay hoặc hai tay. Vì vậy protocol quay nên phủ ít nhất các nhóm sau:
| Primitive | Ví dụ clip | Dấu hiệu clip tốt | Lỗi thường gặp |
|---|---|---|---|
| Advance | Tiến từ cửa phòng tới bàn có hộp | Target lớn dần, đường đi rõ, dừng trước vùng thao tác | Đi quá nhanh, dừng quá xa hoặc quá sát |
| Backward | Lùi khỏi bàn sau khi đặt vật | Camera vẫn thấy context, không quay lưng vô nghĩa | Lùi dài trong cảnh trống |
| Lateral step | Bước ngang để căn với giỏ hoặc carton | Target dịch theo chiều ngang, sau đó nằm giữa FOV | Bước ngang không có mục tiêu |
| Turn | Xoay tại chỗ để đối diện xe đẩy hoặc kệ | Heading đổi rõ, dừng khi target ở giữa ảnh | Vừa xoay vừa đi quá nhiều khiến label mơ hồ |
| Squat | Hạ người để tiếp cận thùng thấp | Camera hạ độ cao, target thấp rõ hơn, có pha đứng lên | Squat không gắn với vật cần thao tác |
| Approach-to-contact | Tiến tới tay nắm, hộp, handle, edge bàn | Dừng ở khoảng cách cánh tay với tới | Chỉ đi ngang qua target |
Không cần mỗi clip chỉ có một primitive. Trên thực tế, loco-manipulation là chuỗi: tiến tới bàn, bước ngang để căn vị trí, squat xuống, xoay nhẹ, dừng. Nhưng trong giai đoạn đầu, hãy quay cả clip đơn primitive và clip chuỗi. Clip đơn giúp kiểm tra LAM có phân biệt được chuyển động cơ bản; clip chuỗi giúp VLA học task context.
Một kế hoạch quay tối thiểu cho một buổi 2 giờ:
Scene A: bàn + hộp + giỏ dưới sàn
20 clip tiến tới bàn từ 3 khoảng cách
20 clip bước ngang trái/phải để căn với giỏ
20 clip squat xuống trước giỏ
20 clip chuỗi: tiến -> bước ngang -> squat -> dừng
Scene B: kệ + xe đẩy có handle
20 clip xoay trái/phải để đối diện handle
20 clip tiến tới handle và dừng trong tầm với
20 clip đẩy giả lập 1-2 bước, không cần lực thật
20 clip chuỗi: tiến -> xoay -> approach handle
Scene C: vật trên sàn hoặc thùng thấp
20 clip squat từ nhiều góc vào
20 clip lùi ra sau khi squat
20 clip đổi heading rồi squat
Số lượng trên chỉ là điểm bắt đầu để kiểm thử pipeline. Paper thu khoảng 300 giờ video locomotion ego cho thí nghiệm đầy đủ, nên một lab nghiêm túc sẽ cần mở rộng nhiều scene, nhiều operator, nhiều layout, nhiều ánh sáng và nhiều target hơn.
Goal-directed: đi tới mục tiêu có thể thao tác
Phần hay nhất trong recipe của WholeBodyVLA là yêu cầu goal-directed execution. Người vận hành phải đi tới các mục tiêu có khả năng trở thành contact target. Nói cách khác, mỗi clip locomotion nên trả lời được câu hỏi: "Sau khi dừng ở đây, humanoid có thể dùng tay làm gì?"
Các target tốt:
| Contact target | Vì sao hữu ích |
|---|---|
| Mép bàn hoặc mặt bàn | Robot cần dừng đúng khoảng cách trước khi pick/place |
| Giỏ, carton, thùng thấp | Kết hợp approach, lateral alignment và squat |
| Handle xe đẩy | Kết hợp xoay, đặt hai tay và đẩy về phía trước |
| Tay nắm cửa/ngăn kéo | Cần orientation chính xác trước khi thao tác |
| Kệ nhiều tầng | Cần thay đổi chiều cao nhìn và khoảng cách |
| Vật trên sàn | Cần squat sâu và giữ target trong FOV |
Các clip kém hơn:
Đi bộ quanh phòng không dừng trước target.
Xoay camera bằng cổ tay thay vì xoay thân.
Squat giữa không gian trống.
Chạy nhanh qua scene khiến object chỉ xuất hiện thoáng qua.
Quay clip từ tay cầm camera thấp hơn đầu quá nhiều.
Khi label thủ công, đừng chỉ ghi walk. Hãy ghi quan hệ với target: approach_table, align_to_basket, turn_to_cart_handle, squat_to_low_box. LAM không cần label này để train theo kiểu reconstruct frame, nhưng metadata tốt giúp bạn lọc dataset, audit failure và sau này tạo instruction cho VLA.
Một protocol quay cụ thể
Dưới đây là protocol đủ rõ để giao cho người thu dữ liệu mới.
1. Chuẩn bị scene
Chọn một scene nhỏ, không quá đông người, có ánh sáng ổn định. Đặt 3-5 contact target: một bàn, một hộp trên bàn, một giỏ dưới sàn, một xe đẩy hoặc vật có handle, và một kệ. Đánh dấu vài vị trí bắt đầu bằng băng dính trên sàn: gần, trung bình, xa; lệch trái, lệch phải; quay lệch 30-60 độ so với target.
Mục tiêu là tạo thay đổi có kiểm soát. Nếu mọi clip bắt đầu từ cùng một vị trí, model học kém generalization. Nếu scene thay đổi quá loạn ngay từ đầu, bạn khó debug. Hãy bắt đầu có cấu trúc, rồi tăng độ đa dạng.
2. Gắn camera và kiểm tra FOV
Camera nên nằm gần mắt người, hướng hơi xuống để thấy cả target thấp và vùng tay có thể xuất hiện. Nếu hướng quá cao, video chỉ thấy tường và kệ; nếu quá thấp, nó giống chest cam hơn head cam. Trước khi quay thật, đi thử một sequence và kiểm tra:
Target có ở giữa ảnh khi người dừng không?
Mặt bàn, giỏ hoặc handle có đủ rõ để nhận ra không?
Khi squat, target thấp có còn trong FOV không?
Video có bị rung đến mức motion blur liên tục không?
Timestamp file có theo thứ tự không?
Nếu camera có chống rung, bật ở mức vừa phải. Chống rung quá mạnh đôi khi làm mất cue ego-motion, nhưng rung quá nặng làm reconstruction khó. Với LAM, bạn muốn chuyển động camera thật nhưng không muốn hình bị nhòe.
3. Đọc hoặc hiển thị instruction
Mỗi clip nên có một intent ngắn. Bạn có thể đọc thành tiếng ở đầu clip, hiển thị trên điện thoại cho operator, hoặc lưu trong file CSV. Ví dụ:
clip_id,instruction,start_pose,target,primitive_sequence
A_001,"go to the table and stop within reach",far_center,table_edge,advance
A_014,"sidestep right to align with the basket",near_left,basket,lateral_right
B_008,"turn left to face the cart handle",near_angle_right,cart_handle,turn_left
C_022,"squat to reach the low box",near_center,low_box,squat
Instruction không cần phức tạp. Điều quan trọng là nhất quán giữa video và mục tiêu. Nếu nói "turn to the cart" nhưng operator lại tiến thẳng tới bàn, metadata sẽ gây nhiễu cho training hoặc evaluation sau này.
4. Quay clip ngắn, có đầu-cuối rõ
Mỗi clip nên dài khoảng 3-12 giây cho primitive đơn, 10-30 giây cho chuỗi. Bắt đầu khi camera đã ổn định, kết thúc sau khi người dừng 1-2 giây ở pose cuối. Pha dừng rất quan trọng: loco-manipulation cần robot không chỉ đến gần target, mà còn ổn định ở stance có thể thao tác.
Một format đơn giản:
0.0-1.0 s: đứng yên ở start pose
1.0-5.0 s: thực hiện primitive chính
5.0-7.0 s: dừng, target nằm trong tầm thao tác
Với clip chuỗi:
0.0-1.0 s: đứng yên
1.0-5.0 s: advance
5.0-8.0 s: turn hoặc lateral step
8.0-11.0 s: squat hoặc align
11.0-13.0 s: dừng ổn định trước target
5. Ghi metadata ngay trong buổi quay
Đừng đợi vài ngày mới nhớ clip nào là clip nào. Tạo file manifest.csv hoặc manifest.jsonl ngay trong session. Schema tối thiểu:
{
"clip_id": "B_008",
"video_path": "raw/session_2026_06_10/B_008.mp4",
"scene_id": "shelf_cart_lab",
"operator_id": "op_03",
"camera_mount": "head",
"camera_model": "action_cam_1080p30",
"instruction": "turn left to face the cart handle",
"target": "cart_handle",
"primitive_sequence": ["turn_left", "stop"],
"start_pose_bucket": "near_angle_right",
"quality": "unchecked"
}
Bạn chưa cần pose 6D chính xác. Nhưng bạn cần đủ metadata để sau này lọc: chỉ lấy clip squat, bỏ clip rung, chia train/val theo scene, hoặc kiểm tra model có học quá thuộc một operator không.
Quy tắc chất lượng dữ liệu
Một protocol tốt không chỉ định nghĩa cách quay; nó còn định nghĩa khi nào phải bỏ clip. Với video action-free, lỗi dữ liệu rất dễ ẩn vì không có action label để kiểm tra. Hãy dùng checklist:
| Tiêu chí | Pass | Fail |
|---|---|---|
| Temporal continuity | Clip liền mạch, không jump cut | Cắt ghép giữa chừng, mất frame nặng |
| Viewpoint | Gần head-mounted ego view | Handheld lắc tay, góc nhìn quá thấp |
| Target visibility | Target xuất hiện rõ trước khi dừng | Target bị che hoặc chỉ lướt qua |
| Primitive clarity | Chuyển động chính nhận ra được | Vừa tiến vừa xoay vừa cúi không có mục tiêu rõ |
| Final stance | Có 1-2 giây dừng ổn định | Kết thúc khi camera còn đang quay loạn |
| Manipulation relevance | Dừng trong tầm với hoặc trước contact point | Đi bộ không liên quan tới thao tác |
| Privacy/safety | Không lộ mặt người ngoài, không có rủi ro va chạm | Quay khu vực nhạy cảm hoặc nguy hiểm |
Một mẹo đơn giản là tạo ba nhãn QA: keep, maybe, drop. Đừng cố cứu mọi clip. Với LAM, nhiều clip xấu có thể làm codebook học nhiễu: rung camera, blur, thay đổi ánh sáng đột ngột, hoặc chuyển động không liên quan.
Chia dataset để tránh leakage
Beginner thường chia train/val ngẫu nhiên theo clip. Cách đó dễ tạo leakage: cùng scene, cùng operator, cùng target và cùng lộ trình xuất hiện ở cả train lẫn validation. Validation nhìn đẹp nhưng khi đổi phòng hoặc đổi camera thì model kém.
Chia tốt hơn:
| Split | Cách chia | Mục tiêu |
|---|---|---|
| Train | Nhiều clip từ phần lớn scene/operator | Học primitive chính |
| Validation in-scene | Scene giống train nhưng clip khác | Debug reconstruction và latent quality |
| Validation held-out scene | Giữ lại một phòng hoặc layout | Kiểm tra generalization thị giác |
| Validation held-out operator | Giữ lại một người quay | Kiểm tra bias dáng đi/góc đầu |
| Stress set | Ánh sáng khác, target thấp/cao, đường đi lệch | Tìm failure trước khi train lớn |
Nếu chỉ có một phòng lab, vẫn có thể tạo held-out layout: đổi vị trí bàn, đổi màu hộp, đổi giỏ, đổi khoảng cách start. Paper WholeBodyVLA đánh giá generalization trên thay đổi start pose, object, layout và appearance; dataset locomotion của bạn cũng nên có tinh thần đó.
Preprocess tối thiểu trước khi đưa vào LAM
LAM học từ frame liên tiếp, nên preprocessing phải bảo toàn thời gian. Đừng shuffle frame riêng lẻ. Đừng crop quá mạnh khiến target biến mất. Một pipeline nhẹ:
def preprocess_clip(video):
frames = decode_video(video, fps=10) # hoặc sample từ 30 fps xuống 10 fps
frames = trim_static_intro_outro(frames, keep_final_stop=True)
frames = resize_short_side(frames, 256)
frames = center_or_letterbox_crop(frames, size=224)
pairs = [(frames[i], frames[i + 1]) for i in range(len(frames) - 1)]
return pairs
Tốc độ sample phụ thuộc model và compute. Nếu sample quá thưa, frame-to-frame change quá lớn; nếu quá dày, nhiều pair gần như giống nhau. Với VLA chạy khoảng 10 Hz trong WholeBodyVLA, việc nghĩ về video ở mức 10 fps là điểm khởi đầu hợp lý. Tuy nhiên, bạn nên thử vài tốc độ và đo reconstruction/relative gain thay vì chọn theo cảm giác.
Metadata cũng nên được giữ song song:
processed/
frames/
B_008/
000000.jpg
000001.jpg
pairs.jsonl
manifest.jsonl
qa_report.csv
Đừng thu MoCap đầu tiên nếu mục tiêu là LAM
MoCap rất hữu ích cho retargeting, imitation và đánh giá chuyển động toàn thân. Nhưng nếu câu hỏi trước mắt là train locomotion LAM theo recipe action-free của WholeBodyVLA, MoCap không phải bước đầu bắt buộc. LAM cần thay đổi thị giác có cấu trúc từ ego video; nó không cần skeleton 3D cho mọi frame.
So sánh nhanh:
| Hướng thu dữ liệu | Chi phí | Phù hợp với giai đoạn | Rủi ro |
|---|---|---|---|
| Head-mounted monocular video | Thấp | Locomotion LAM pretraining | Cần QA tốt để tránh clip nhiễu |
| Robot manipulation dataset | Trung bình đến cao nếu tự thu, thấp nếu dùng dataset mở | Manipulation LAM | Domain khác robot đích |
| Teleoperation robot thật | Cao | Decoder grounding, fine-tuning | Tốn robot time và operator |
| MoCap whole-body | Rất cao | Retargeting, motion prior, evaluation | Không tự động cho ra ego visual latent |
Nói ngắn gọn: nếu bạn đang ở ngày đầu của dự án, hãy quay video ego đúng protocol trước. Khi pipeline LAM chạy được, bạn mới quyết định cần MoCap cho phần nào: retarget, reward, hoặc benchmark. Cách này phù hợp với tinh thần của paper: dùng video action-free giá thấp để mở rộng pretraining, rồi dùng teleoperation có chọn lọc để ground latent vào robot thật.
Checklist trước khi bắt đầu buổi quay
[ ] Đã chọn scene có target thao tác rõ: bàn, giỏ, thùng, handle, kệ.
[ ] Camera gắn trên đầu, FOV thấy target thấp khi squat.
[ ] Có danh sách primitive: advance, backward, lateral, turn, squat, approach-to-contact.
[ ] Mỗi clip có instruction hoặc metadata intent.
[ ] Mỗi clip bắt đầu và kết thúc bằng 1-2 giây đứng yên.
[ ] Có manifest để ghi clip_id, scene_id, operator_id, target, primitive.
[ ] Có quy tắc QA: keep/maybe/drop.
[ ] Có split held-out scene hoặc held-out operator.
[ ] Không quay thông tin riêng tư hoặc khu vực nguy hiểm.
Kết luận
Video ego cho locomotion LAM là một bước dữ liệu rẻ nhưng không hề tùy tiện. Muốn bám đúng WholeBodyVLA, bạn cần giữ ba nguyên tắc: một là action-free nhưng phải temporally clean; hai là locomotion phải manipulation-aware, tức đi, xoay, bước ngang và squat để tới contact target; ba là tách locomotion LAM khỏi manipulation LAM vì hai loại video có pattern thị giác khác nhau.
Khi làm đúng, dataset này giúp VLA học trước các latent liên quan đến tiến, xoay, căn vị trí và hạ thấp người, trước khi bạn phải thu nhiều trajectory robot thật. Đó là ý nghĩa thực tế của recipe: không bỏ qua teleoperation, mà dùng video giá thấp để giảm lượng teleoperation cần thiết và làm cho giai đoạn fine-tuning có nền tảng tốt hơn.
Nguồn kỹ thuật chính
- WholeBodyVLA paper trên arXiv
- WholeBodyVLA project page
- WholeBodyVLA GitHub README
- AgiBot World GitHub