
Mục tiêu của bài này
Series này bàn về một câu hỏi rất thực tế: nếu muốn thu thập dữ liệu humanoid cho một hệ WholeBodyVLA, ta phải thu loại dữ liệu nào, ở giai đoạn nào, và vì sao? Trước khi nói về camera, video, retargeting, teleoperation, reinforcement learning hay sim-to-real, ta cần một bản đồ chung của pipeline. Nếu không có bản đồ này, người mới rất dễ lẫn lộn giữa "video không có action", "latent action", "joint target", "lệnh locomotion", và "whole-body control".
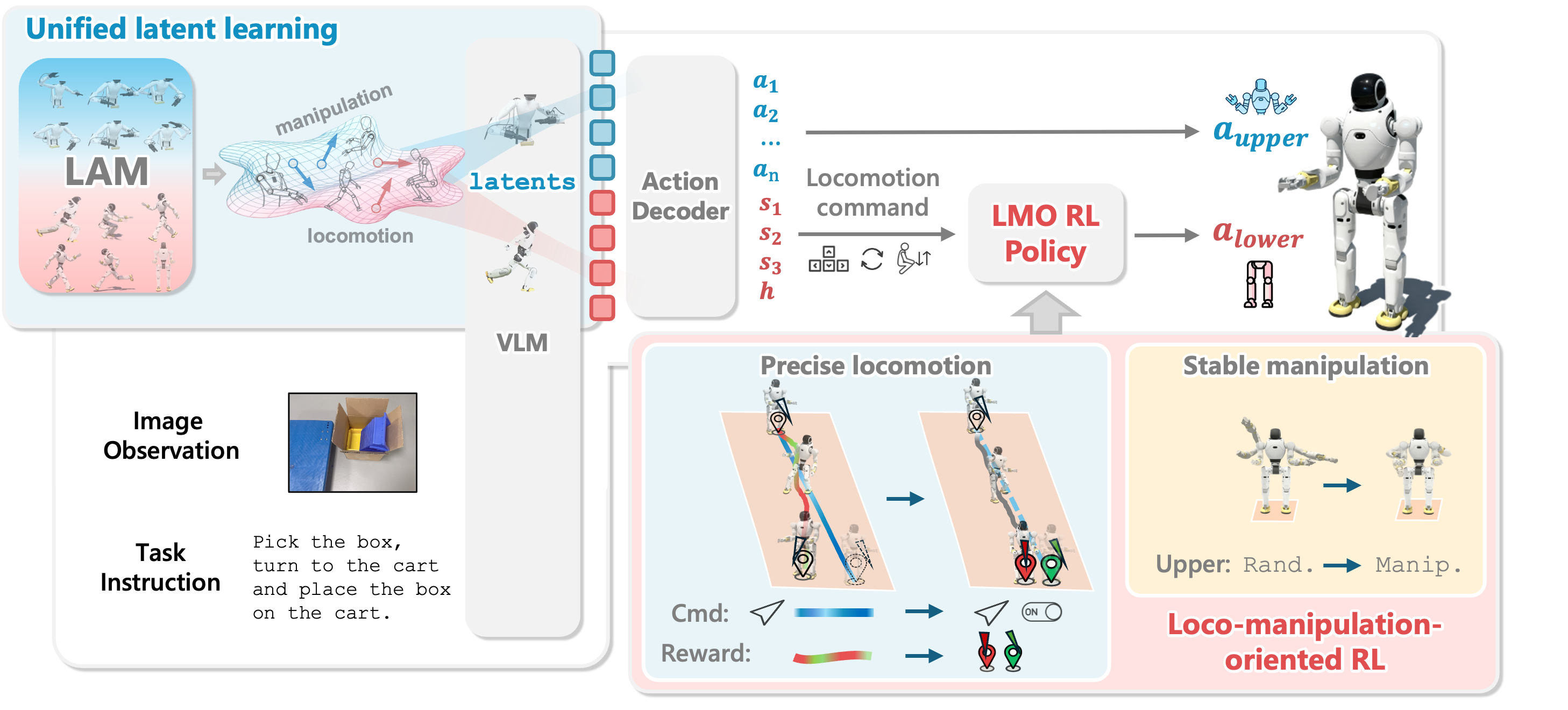
Bài 1 vì vậy không cố dạy cách train model ngay. Mục tiêu là giúp bạn nhìn được dòng chảy kỹ thuật trong WholeBodyVLA: ảnh egocentric và ngôn ngữ đi vào VLM; hai Latent Action Model (LAM) tạo supervision rời rạc cho manipulation và locomotion; một decoder nhẹ chuyển latent thành lệnh robot khoảng 10 Hz; và LMO, tức loco-manipulation-oriented RL policy, thực thi locomotion ở 50 Hz. Khi đã có bản đồ này, mọi quyết định thu dữ liệu ở các bài sau sẽ gắn với một stage cụ thể thay vì chỉ là danh sách mẹo rời rạc.
Nếu bạn muốn đọc bối cảnh research rộng hơn, xem thêm phân tích WholeBodyVLA ICLR 2026 và hướng dẫn kiến trúc WholebodyVLA. Bài hiện tại đi hẹp hơn: nó chỉ dựng khung để cả series về data collection có một ngôn ngữ chung.
Roadmap series
- Bản đồ pipeline WholeBodyVLA: đọc kiến trúc từ paper/README và xác định dữ liệu nằm ở đâu trong pipeline.
- Video egocentric và LAM: thu video action-free cho manipulation LAM và locomotion LAM.
- Retarget humanoid: biến chuyển động người hoặc robot khác thành target hợp lý cho humanoid đích.
- Teleoperation fine-tuning: thu trajectory robot thật để nối latent action với lệnh điều khiển.
- RL và LMO: train low-level policy cho tiến, lùi, bước ngang, xoay và squat ổn định.
- Sim-to-real: làm cho controller và policy chịu được sai số mô phỏng, latency, tải trọng và tiếp xúc.
- Evaluation: thiết kế benchmark cho loco-manipulation, generalization và failure analysis.
Tóm tắt pipeline trong một hình
Project page của OpenDriveLab mô tả WholeBodyVLA như một hệ VLA thống nhất cho humanoid loco-manipulation diện rộng. README nhấn mạnh ba ý chính: học latent action từ egocentric video không có action label, dùng LMO RL policy để whole-body coordination ổn định, và encode ảnh egocentric cộng language instruction thành latent action token rồi decode thành dual-arm joint action và locomotion command.
Ta có thể viết pipeline thành dạng rất gần với một sơ đồ phần mềm:
egocentric image + task language
|
v
VLM / VLA backbone
|
v
latent action tokens
|
+--> manipulation latent, được supervise bởi manipulation LAM
|
+--> locomotion latent, được supervise bởi locomotion LAM
|
v
lightweight execution decoder, khoảng 10 Hz
|
+--> upper-body / dual-arm joint targets
|
+--> discrete locomotion command
|
v
LMO RL policy, 50 Hz
|
v
lower-body actions / torques / PD targets tùy triển khai
Điểm cần nhớ: WholeBodyVLA không chỉ là một VLM "nhìn ảnh rồi nói robot làm gì". Nó là một hệ nhiều tầng. Tầng cao xử lý perception, language và intention ở tần số thấp hơn. Tầng thấp xử lý thăng bằng, bước chân, squat và nhiễu động ở tần số cao hơn. Đây là cách thiết kế rất tự nhiên cho humanoid: reasoning không cần chạy 50 Hz, nhưng cân bằng và điều khiển chân thì cần phản ứng nhanh hơn nhiều.
Các thành phần chính
| Thành phần | Input | Output | Vai trò trong data collection |
|---|---|---|---|
| Manipulation LAM | Cặp frame manipulation liên tiếp | Discrete manipulation latent | Biến video thao tác thành pseudo-action label cho VLA |
| Locomotion LAM | Cặp frame egocentric khi người/robot di chuyển | Discrete locomotion latent | Biến tiến, bước ngang, xoay, squat thành token học được |
| VLM / VLA backbone | Ảnh egocentric, instruction, latent supervision | Latent action tokens | Học "nhìn gì, đọc gì, chọn latent nào" |
| Lightweight decoder | Latent action, robot state | Joint target thân trên, command locomotion | Ground latent vào robot thật |
| LMO RL policy | Proprioception, history, discrete command | Hành động thân dưới tần số cao | Thực thi locomotion ổn định khi tay thao tác |
Ở mức beginner, bạn có thể tưởng tượng LAM như một bộ dịch video thành "từ vựng hành động". Thay vì bắt người thu dữ liệu ghi rằng frame này tương ứng với "bước sang trái 0,3 m/s" hoặc "nâng khuỷu tay phải 12 độ", LAM nhìn hai frame liên tiếp và học một mã rời rạc mô tả sự thay đổi. Sau đó VLA học dự đoán các mã đó từ ảnh hiện tại và câu lệnh.
Vì sao cần hai LAM riêng?
Paper giải thích rằng manipulation video và locomotion video có kiểu thay đổi hình ảnh rất khác nhau. Trong video manipulation, camera thường gần như đứng yên; sự thay đổi lớn nằm ở tay, vật thể, gripper, contact point và vùng làm việc. Trong video locomotion egocentric, camera di chuyển liên tục; cả khung cảnh trôi qua do đầu hoặc thân người/robot đang tiến, xoay, bước ngang hay squat. Nếu train một LAM chung một cách ngây thơ, model có thể học attention bị mâu thuẫn: lúc thì cần nhìn cục bộ vào tay, lúc thì cần nhìn toàn scene để hiểu chuyển động camera.
Vì vậy WholeBodyVLA train hai LAM riêng: manipulation LAM trên dữ liệu manipulation, locomotion LAM trên dữ liệu locomotion có ý thức thao tác. Paper nói rõ hai LAM này đều được dùng để supervise VLA training. Đây là chi tiết rất quan trọng cho series data collection: bạn không thu "một đống video humanoid" rồi hy vọng model tự tách hết. Bạn cần gắn từng loại video với vai trò học cụ thể.
Một cách kiểm tra nhanh khi thiết kế dataset:
Nếu video chủ yếu cho thấy tay, gripper, vật thể, contact, object affordance:
đưa vào bucket manipulation LAM
Nếu video chủ yếu cho thấy camera/robot tiến tới mục tiêu, xoay, bước ngang, squat:
đưa vào bucket locomotion LAM
Nếu trajectory đã có robot joint target hoặc command thật:
dùng cho teleoperation fine-tuning / decoder grounding, không chỉ cho LAM
Sự tách này cũng giúp giải thích vì sao bài 2 của series sẽ tập trung vào video-LAM, còn bài 4 mới bàn sâu về teleoperation. Hai loại dữ liệu này phục vụ hai mục tiêu khác nhau.
Stage 1: LAM biến video thành latent action rời rạc
Trong paper, LAM được mô tả theo phong cách VQ-VAE: encoder nhận cặp frame liên tiếp, tạo vector latent liên tục, rồi lượng tử hóa vector đó về entry gần nhất trong codebook. Decoder sau đó dùng frame trước và latent đã lượng tử hóa để tái tạo frame sau. Nếu latent chứa thông tin hành động hữu ích, decoder có thể dự đoán sự thay đổi từ frame này sang frame tiếp theo tốt hơn.
Nói đơn giản:
def train_lam(frame_t, frame_t1):
continuous_z = lam_encoder(frame_t, frame_t1)
discrete_code = nearest_codebook_entry(continuous_z)
reconstructed_t1 = lam_decoder(frame_t, discrete_code)
loss = reconstruction_loss(reconstructed_t1, frame_t1) + vq_commitment_loss()
return loss
Trong thực tế paper dùng spatio-temporal transformer và DINOv2 features cho encoder, nhưng ở mức tư duy data collection, điều quan trọng hơn là: LAM không cần action label từ robot. Nó cần video có thứ tự thời gian đủ tốt, góc nhìn phù hợp, và chuyển động liên quan đến task. Đó là lý do paper có thể tận dụng action-free egocentric video để giảm phụ thuộc vào teleoperation đắt đỏ.
Tuy nhiên "action-free" không có nghĩa là "quality-free". Video mờ, rung quá mạnh, thiếu frame trước/sau, bị cắt lung tung, hoặc không liên quan đến các primitive cần học sẽ tạo latent kém. Với manipulation LAM, bạn muốn video có object interaction rõ, tay/vật thể nằm trong field of view, và thay đổi frame phản ánh thao tác thật. Với locomotion LAM, bạn muốn sequence thể hiện tiến, lùi, bước ngang, xoay, squat, tiếp cận vật thể, dừng trước mục tiêu và điều chỉnh pose.
Stage 2: VLA học dự đoán latent từ ảnh và ngôn ngữ
Sau khi có LAM, cùng một corpus video được dùng để supervise VLA. LAM tạo pseudo-label dạng discrete code; VLA nhận image observation và task language; mục tiêu là dự đoán đúng manipulation latent và locomotion latent. Đây là điểm "VLA" thật sự xuất hiện: model không chỉ reconstruct frame, mà học liên hệ giữa ngôn ngữ, nhận thức thị giác và hành động tiềm ẩn.
Ví dụ một instruction là:
"Pick the box, turn to the cart, and place the box on the cart."
Với instruction này, VLA phải học một chuỗi quyết định:
nhìn thấy box và cart
-> chọn latent tiếp cận box
-> chọn latent squat hoặc điều chỉnh stance nếu cần
-> chọn latent dual-arm grasp
-> chọn latent rise / turn
-> chọn latent place
Đây chưa phải là điều khiển joint trực tiếp ở mọi timestep. Nó giống một lớp "ngữ nghĩa hành động" rời rạc, giúp model học từ nhiều embodiment và nhiều nguồn video hơn. Appendix của paper nói rằng Stage I train VQ-VAE LAM như inverse dynamics model từ video thuần thị giác; Stage II dùng các LAM đó để supervise VLA; Stage III dùng teleoperation Agibot X2 để liên kết latent với joint target và locomotion command. Chính ba stage này làm cho latent có thể chung giữa human video và robot data, vì code phụ thuộc vào thay đổi hình ảnh frame-to-frame hơn là joint value cụ thể của một robot.
Stage 3: Decoder nhẹ ground latent vào robot
Nếu chỉ có latent token, robot chưa thể chạy. Humanoid thật cần lệnh cụ thể: góc khớp tay, command cho chân, target stance height, hoặc tín hiệu điều khiển khác tùy hệ. Vì vậy WholeBodyVLA gắn thêm một lightweight execution decoder sau pretraining. Decoder này được fine-tune bằng teleoperation trajectory để chuyển latent action thành robot-executable commands.
Theo paper, output của decoder gồm hai nhánh:
| Nhánh decoder | Output | Dùng cho |
|---|---|---|
| Upper body | Upper-body joint angles / dual-arm joint actions | Grasp, lift, place, push, giữ vật |
| Lower body command | Locomotion command | Tiến, lùi, bước ngang, xoay, squat qua LMO |
Tần số ở đây cũng quan trọng. Project page và appendix triển khai nói VLA backbone chạy khoảng 10 Hz cho perception/reasoning, còn LMO policy chạy 50 Hz trên proprioceptive inputs. Nghĩa là decoder không cố xuất mọi chi tiết cân bằng chân ở 50 Hz. Nó chỉ gửi ý định ở tầng cao hơn. LMO chịu trách nhiệm biến ý định đó thành chuyển động thân dưới mượt và ổn định.
Nếu bạn đang xây pipeline dữ liệu riêng, hãy tách rõ hai loại target:
teleop_sample:
observation:
image: head_rgb
language: "pick the bag and place it into the box"
robot_state: qpos, qvel, imu
supervision:
upper_body:
left_arm_joint_targets: [7 dof]
right_arm_joint_targets: [7 dof]
waist_target: optional
lower_body:
locomotion_command:
forward_flag: -1 | 0 | 1
lateral_flag: -1 | 0 | 1
yaw_flag: -1 | 0 | 1
stance_height: float
Schema trên không phải schema chính thức của repo; nó là cách diễn giải tối giản để người mới hiểu interface. Ý tưởng cốt lõi là upper-body có thể cần joint target liên tục, còn lower-body nhận command rời rạc hoặc bán rời rạc để LMO thực thi.
Stage 4: LMO chạy locomotion ở 50 Hz
LMO là phần nhiều người bỏ qua khi đọc VLA, nhưng nó là điều làm pipeline WholeBodyVLA khác với một policy chỉ xuất action end-to-end. Paper chỉ ra rằng nhiều locomotion controller truyền thống dùng velocity-tracking liên tục. Cách đó phù hợp cho đi bộ chung chung, nhưng không hẳn phù hợp với loco-manipulation, nơi robot cần start/stop rõ, xoay đúng hướng, dừng đúng vị trí, squat ổn định, và giữ cân bằng khi tay đang tạo nhiễu động.
LMO thay interface velocity liên tục bằng discrete command interface. Planner hoặc decoder phát các flag cho forward/backward, lateral, yaw rotation và stance height. Policy thân dưới dùng proprioception với short history stack như base angular velocity, gravity vector, joint positions/velocities và previous action. Nó không cần nhìn RGB; nó cần giữ robot không ngã và thực thi command chính xác.
So sánh hai kiểu interface:
| Tiêu chí | Velocity tracking truyền thống | LMO discrete command |
|---|---|---|
| Lệnh | Vận tốc liên tục theo trục | Flag tiến/lùi, bước ngang, xoay, chiều cao stance |
| Điểm mạnh | Linh hoạt cho locomotion tổng quát | Start/stop rõ, hợp với thao tác |
| Rủi ro | Dễ lệch hướng, dừng không gọn, gait phân mảnh | Cần thiết kế primitive đủ phủ task |
| Phù hợp với VLA | VLA phải dự đoán giá trị liên tục khó ổn định | VLA/decoder dự đoán command rời rạc dễ học hơn |
Trong data collection, điều này có hậu quả trực tiếp: bạn phải log được discrete locomotion command hoặc ít nhất có cách suy ra nó từ joystick/trajectory. Nếu teleoperator điều khiển bằng joystick, đừng chỉ lưu video và joint. Hãy lưu cả command stream, timestamp, robot state, và mapping từ command sang primitive. Bài 4 và bài 5 sẽ đi sâu hơn vào phần này.
Dữ liệu nào đi vào đâu?
Một pipeline WholeBodyVLA có ít nhất bốn "kho dữ liệu" khác nhau:
| Loại dữ liệu | Có action label? | Nguồn điển hình | Stage dùng |
|---|---|---|---|
| Egocentric manipulation video | Không hoặc không cần | Robot dataset, human/robot manipulation video | Manipulation LAM |
| Egocentric locomotion video | Không hoặc không cần | Người đội camera, robot head camera, GoPro/Realsense | Locomotion LAM |
| Teleoperation trajectory | Có | VR headset, joystick, robot thật | Decoder grounding, VLA fine-tuning |
| Simulation rollout cho LMO | Có state/action/reward | MuJoCo, Isaac Lab hoặc sim tương tự | RL training cho low-level locomotion |
Appendix của paper cho biết locomotion LAM được train từ khoảng 300 giờ video egocentric locomotion tự thu, manipulation LAM dùng real-robot bimanual manipulation datasets như AgiBot World; VLA train từ Prismatic-7B, rồi fine-tune bằng LoRA trên dữ liệu task-specific. Khi triển khai, VLA chạy trên workstation RTX 4090, RL policy chạy trên NanoPi onboard, giao tiếp qua ZeroMQ/Ethernet. Các chi tiết phần cứng có thể thay đổi nếu bạn xây hệ khác, nhưng separation giữa high-level VLA và low-level LMO nên được giữ.
Một điểm rất thực tế: dữ liệu LAM giúp giảm nhu cầu teleoperation, nhưng không thay thế hoàn toàn teleoperation. LAM học "mã hành động" từ video. Teleoperation vẫn cần để ground mã đó vào robot cụ thể: Agibot X2 có arm 7 DoF mỗi bên, waist 1 DoF, leg 6 DoF mỗi bên; robot khác sẽ có joint limit, gripper, latency, mass distribution và actuator khác. Nếu bỏ Stage III, latent có thể hợp lý về ngữ nghĩa nhưng không đủ để robot thật chạy an toàn.
Vì sao tần số 10 Hz và 50 Hz quan trọng?
Trong robotics, tần số điều khiển không chỉ là thông số kỹ thuật; nó quyết định nơi đặt trách nhiệm. WholeBodyVLA để VLA backbone hoạt động ở khoảng 10 Hz cho perception/reasoning. 10 Hz nghĩa là mỗi 100 ms model có thể cập nhật ý định: tiếp tục tiến, bắt đầu xoay, squat, chuyển sang grasp, hoặc place. Với mô hình lớn có VLM, đây là mức hợp lý hơn so với yêu cầu chạy hàng chục Hz trên mọi joint.
LMO chạy 50 Hz, tức chu kỳ khoảng 20 ms. Tầng này đủ nhanh để xử lý balance, contact, trượt chân, dao động thân, và nhiễu do tay nâng vật hoặc đẩy xe. Nếu robot đang đẩy cart nặng, thân trên tạo lực kéo/đẩy làm trọng tâm thay đổi liên tục; bạn không muốn chờ VLM suy luận lại mới sửa chân. Low-level controller phải phản ứng cục bộ và nhanh.
Ta có thể tóm tắt như sau:
10 Hz VLA / decoder:
"Tôi nên làm primitive nào tiếp theo?"
"Tay trái/phải nên đi về joint target nào?"
"Có nên yêu cầu xoay, bước ngang, squat không?"
50 Hz LMO:
"Làm sao để thực thi primitive đó mà không ngã?"
"Chân nào đặt ở đâu, torque/PD target ra sao?"
"Làm sao giữ yaw, stance height, CoM và contact ổn định?"
Khi thiết kế logger, timestamp phải đủ tốt để align hai tầng này. Một frame ảnh ở 10 Hz có thể tương ứng với năm bước LMO ở 50 Hz. Nếu timestamp bị lệch, teleoperation sample sẽ dạy decoder sai: ảnh và language nói "đang dừng để grasp", nhưng command stream lại đang thuộc pha xoay trước đó.
Bản đồ cho các bài sau
Các bài sau trong series sẽ không xuất phát từ câu hỏi "thu càng nhiều càng tốt". Thay vào đó, mỗi bài trả lời một câu hỏi gắn với stage:
| Bài | Câu hỏi data | Stage liên quan |
|---|---|---|
| Bài 2 | Video nào đủ tốt để tạo latent action? | Manipulation LAM, locomotion LAM |
| Bài 3 | Làm sao biến motion từ embodiment khác về humanoid đích? | Retarget, teleop bootstrap |
| Bài 4 | Teleoperation cần log gì ngoài RGB? | Decoder grounding, VLA fine-tuning |
| Bài 5 | Command locomotion rời rạc nên thiết kế thế nào? | LMO RL |
| Bài 6 | Sai số sim-to-real nào phá pipeline? | LMO deployment, latency, dynamics |
| Bài 7 | Đánh giá success/failure ra sao? | Full system evaluation |
Nếu chỉ nhớ một câu sau bài này, hãy nhớ: WholeBodyVLA chia data theo chức năng học. Video action-free tạo latent vocabulary; VLA học dự đoán vocabulary từ ảnh và ngôn ngữ; teleoperation ground vocabulary vào robot; LMO biến locomotion command thành chuyển động thân dưới ổn định. Mỗi loại dữ liệu chỉ tốt khi nó phục vụ đúng một mắt xích trong chuỗi đó.
Nguồn tham khảo
- WholeBodyVLA paper trên arXiv
- WholeBodyVLA project page
- OpenDriveLab/WholebodyVLA README
- WholeBodyVLA PDF


