
What This Article Is For
This series is about a practical question: if you want to collect humanoid data for a WholeBodyVLA-style system, what data should you collect, where does each dataset enter the stack, and why does it matter? Before discussing cameras, egocentric videos, retargeting, teleoperation, reinforcement learning, or sim-to-real, we need a shared map of the pipeline. Without that map, it is easy to mix up "videos without action labels", "latent actions", "joint targets", "locomotion commands", and "whole-body control".
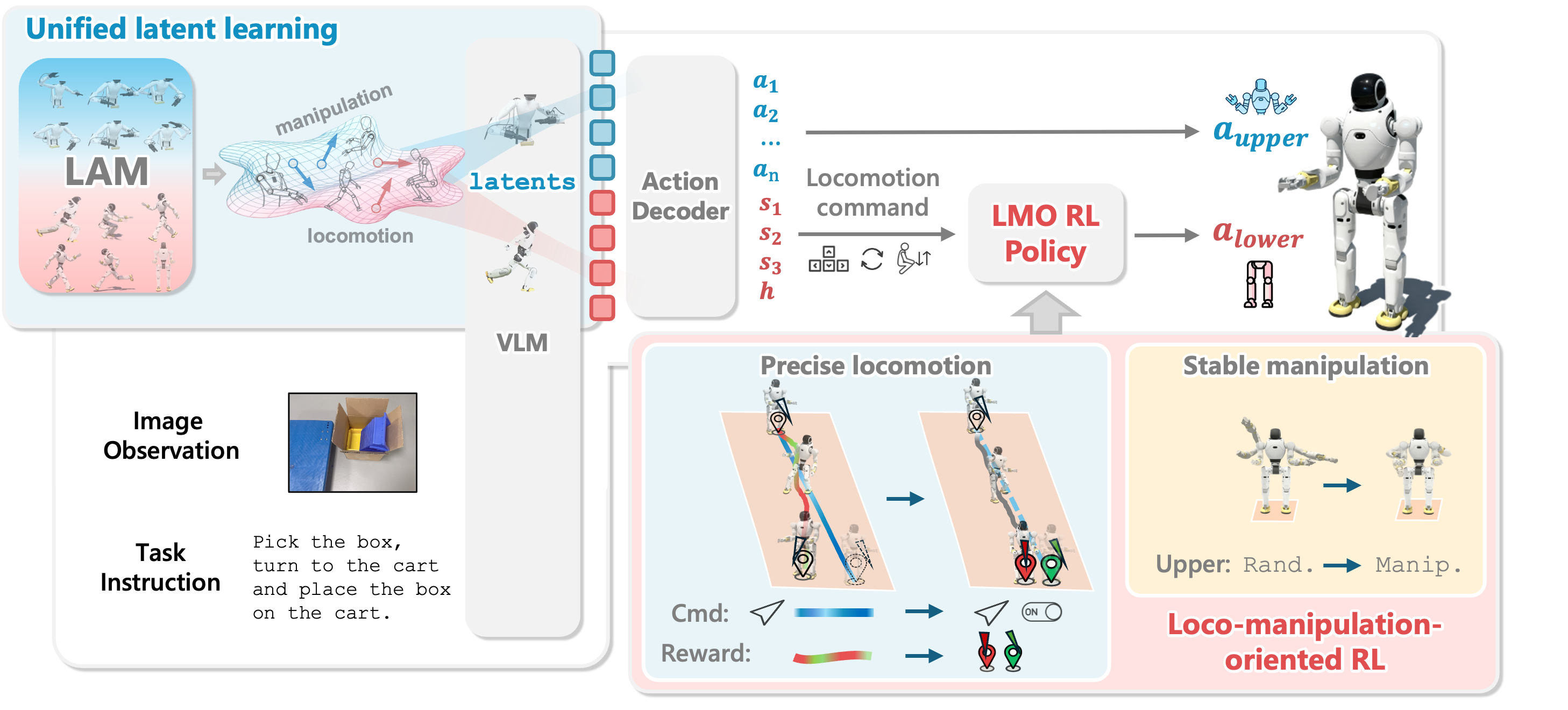
Article 1 therefore does not try to teach model training immediately. Its job is to walk through the actual stack described in the WholeBodyVLA paper, project page, and README: egocentric images plus language enter a VLM; two Latent Action Models (LAMs) provide discrete latent supervision for manipulation and locomotion; a lightweight decoder turns those latents into robot commands at about 10 Hz; and the LMO, or loco-manipulation-oriented RL policy, executes locomotion at 50 Hz. Once this map is clear, every later data-collection choice can be tied to a concrete stage instead of floating around as generic advice.
For broader context, see our WholeBodyVLA ICLR 2026 research analysis and WholebodyVLA architecture guide. This article is narrower: it builds the mental model needed for the rest of the data-collection series.
Roadmap Series
- Mapping the WholeBodyVLA Pipeline: read the paper/README architecture and locate where each data type enters the stack.
- Egocentric Video and LAMs: collect action-free video for the manipulation LAM and locomotion LAM.
- Humanoid Retargeting: convert human or cross-robot motion into targets suitable for the destination humanoid.
- Teleoperation Fine-Tuning: collect real-robot trajectories that connect latent actions to executable commands.
- RL and LMO: train the low-level policy for forward motion, lateral stepping, turning, and squatting.
- Sim-to-Real: make the controller and policy tolerate simulation error, latency, payload variation, and contact.
- Evaluation: design benchmarks for loco-manipulation, generalization, and failure analysis.
The Pipeline in One Diagram
The OpenDriveLab project page describes WholeBodyVLA as a unified VLA system for large-space humanoid loco-manipulation. The README emphasizes three core ideas: learning latent actions from egocentric videos without action labels, using an LMO RL policy for stable whole-body coordination, and encoding egocentric images plus language instructions into latent action tokens that are decoded into dual-arm joint actions and locomotion commands.
We can write the pipeline in a software-like form:
egocentric image + task language
|
v
VLM / VLA backbone
|
v
latent action tokens
|
+--> manipulation latent, supervised by manipulation LAM
|
+--> locomotion latent, supervised by locomotion LAM
|
v
lightweight execution decoder, about 10 Hz
|
+--> upper-body / dual-arm joint targets
|
+--> discrete locomotion command
|
v
LMO RL policy, 50 Hz
|
v
lower-body actions / torques / PD targets depending on implementation
The key point is that WholeBodyVLA is not just a VLM that "looks at an image and tells the robot what to do." It is a layered system. The high-level layer handles perception, language, and intent at a lower frequency. The low-level layer handles balance, footsteps, squatting, and physical disturbances at a higher frequency. That split is natural for humanoids: reasoning does not need to run at 50 Hz, but balance and leg control often do.
The Main Components
| Component | Input | Output | Role in data collection |
|---|---|---|---|
| Manipulation LAM | Consecutive manipulation frames | Discrete manipulation latent | Turns manipulation videos into pseudo-action labels for the VLA |
| Locomotion LAM | Egocentric frames during motion | Discrete locomotion latent | Turns advancing, lateral stepping, turning, and squatting into learnable tokens |
| VLM / VLA backbone | Egocentric image, instruction, latent supervision | Latent action tokens | Learns "what to see, what to read, which latent to choose" |
| Lightweight decoder | Latent action, robot state | Upper-body joint target, locomotion command | Grounds latents into commands for the real robot |
| LMO RL policy | Proprioception, history, discrete command | High-frequency lower-body action | Executes stable locomotion while the arms manipulate |
At a beginner level, you can think of a LAM as a translator from video into an "action vocabulary." Instead of asking data collectors to label one frame as "step left at 0.3 m/s" or "raise the right elbow by 12 degrees," the LAM looks at consecutive frames and learns a discrete code describing the visual change. Then the VLA learns to predict those codes from the current image and instruction.
Why Two Separate LAMs?
The paper explains that manipulation videos and locomotion videos produce very different visual changes. In manipulation videos, the camera is often almost static; the important changes happen around the hands, grippers, objects, contact points, and workspace. In egocentric locomotion videos, the camera moves continuously; the whole scene shifts because the head or body is moving forward, turning, stepping sideways, or squatting. If one shared LAM is trained naively on both sources, the model may learn conflicting attention patterns: sometimes it must focus locally on arms and objects, while at other times it must attend to the whole scene to understand camera motion.
WholeBodyVLA therefore trains two LAMs separately: a manipulation LAM on manipulation data and a locomotion LAM on manipulation-aware locomotion data. Both LAMs are then used together to supervise VLA training. This detail matters for a data-collection series: you should not collect "a pile of humanoid videos" and hope the model sorts everything out. Each video type should be tied to a learning role.
A quick design rule:
If the video mainly shows hands, grippers, objects, contact, and affordances:
put it in the manipulation LAM bucket
If the video mainly shows the camera/robot moving toward a goal, turning, sidestepping, or squatting:
put it in the locomotion LAM bucket
If the trajectory already contains robot joint targets or real commands:
use it for teleoperation fine-tuning / decoder grounding, not only for LAM training
This separation also explains why article 2 focuses on video and LAMs, while article 4 focuses on teleoperation. The datasets serve different purposes.
Stage 1: LAMs Turn Video Into Discrete Latent Actions
In the paper, the LAM follows a VQ-VAE style pipeline: the encoder receives consecutive frames, produces a continuous latent vector, and quantizes that vector to the nearest entry in a learned codebook. The decoder then uses the previous frame and the quantized latent to reconstruct the next frame. If the latent contains useful action information, the decoder can predict the frame-to-frame change more accurately.
In simple pseudocode:
def train_lam(frame_t, frame_t1):
continuous_z = lam_encoder(frame_t, frame_t1)
discrete_code = nearest_codebook_entry(continuous_z)
reconstructed_t1 = lam_decoder(frame_t, discrete_code)
loss = reconstruction_loss(reconstructed_t1, frame_t1) + vq_commitment_loss()
return loss
The actual paper uses a spatio-temporal transformer and DINOv2 features for the encoder, but for data-collection thinking the more important point is that a LAM does not require robot action labels. It needs temporally ordered videos with the right viewpoint and task-relevant motion. This is why WholeBodyVLA can use action-free egocentric videos to reduce dependence on expensive teleoperation.
"Action-free," however, does not mean "quality-free." Blurry clips, excessive shake, missing temporal continuity, aggressive cuts, and off-task movement produce weak latents. For the manipulation LAM, you want clear object interaction, hands or grippers in view, and frame changes that reflect real manipulation. For the locomotion LAM, you want sequences showing forward motion, backward motion, lateral stepping, turning, squatting, approaching objects, stopping near targets, and adjusting body pose.
Stage 2: The VLA Learns to Predict Latents From Images and Language
After the LAMs are pretrained, the same video corpus can supervise the VLA. The LAMs generate pseudo-labels as discrete codes; the VLA receives visual observations and task language; the objective is to predict both manipulation and locomotion latents. This is where the "VLA" part becomes central: the model is no longer just reconstructing frames, but learning the relationship between language, perception, and latent action.
Consider an instruction such as:
"Pick the box, turn to the cart, and place the box on the cart."
For this instruction, the VLA must learn a sequence of choices:
see the box and cart
-> choose an approach-the-box latent
-> choose a squat or stance-adjustment latent if needed
-> choose a dual-arm grasp latent
-> choose a rise / turn latent
-> choose a place latent
This is not direct joint control at every timestep yet. It is closer to a discrete semantic action layer, which lets the model learn from more embodiments and more video sources. The appendix says the three-stage pipeline creates a shared latent action space: Stage I trains VQ-VAE LAMs as inverse-dynamics models from purely visual videos; Stage II reuses those videos and LAM codes to supervise the VLA; Stage III introduces Agibot X2 teleoperation data to associate latents with robot joint targets and locomotion commands. That is why the latent can align human video and robot data: it depends on frame-to-frame visual change rather than the exact joint values of one robot.
Stage 3: A Lightweight Decoder Grounds Latents Into Robot Commands
Latent tokens alone cannot run a robot. A real humanoid needs concrete commands: arm joint angles, lower-body commands, stance height targets, or other control signals depending on the platform. WholeBodyVLA therefore attaches a lightweight execution decoder after pretraining. This decoder is fine-tuned using teleoperation trajectories so it can convert latent actions into robot-executable commands.
According to the paper, the decoder has two output branches:
| Decoder branch | Output | Used for |
|---|---|---|
| Upper body | Upper-body joint angles / dual-arm joint actions | Grasping, lifting, placing, pushing, holding objects |
| Lower-body command | Locomotion command | Forward/backward motion, lateral stepping, turning, squatting through LMO |
The frequency matters. The project page and deployment appendix report that the VLA backbone runs at about 10 Hz for perception and reasoning, while the LMO policy runs at 50 Hz on proprioceptive inputs. This means the decoder is not trying to output every leg-control detail at 50 Hz. It sends higher-level intent. The LMO is responsible for turning that intent into smooth, stable lower-body motion.
If you are building a data pipeline, separate the two target types clearly:
teleop_sample:
observation:
image: head_rgb
language: "pick the bag and place it into the box"
robot_state: qpos, qvel, imu
supervision:
upper_body:
left_arm_joint_targets: [7 dof]
right_arm_joint_targets: [7 dof]
waist_target: optional
lower_body:
locomotion_command:
forward_flag: -1 | 0 | 1
lateral_flag: -1 | 0 | 1
yaw_flag: -1 | 0 | 1
stance_height: float
This is not an official repository schema; it is a minimal interpretation for beginners. The core idea is that the upper body may need continuous joint targets, while the lower body receives a discrete or semi-discrete command for the LMO to execute.
Stage 4: LMO Executes Locomotion at 50 Hz
The LMO is easy to overlook when reading about VLA, but it is one of the main reasons WholeBodyVLA differs from a plain end-to-end action policy. The paper argues that many traditional locomotion controllers use continuous velocity tracking. That is useful for general walking, but not ideal for loco-manipulation, where the robot needs clear start/stop semantics, accurate heading, precise stopping, stable squatting, and balance while the arms create disturbances.
LMO replaces the continuous velocity interface with a discrete command interface. The planner or decoder emits flags for forward/backward motion, lateral motion, yaw rotation, and stance height. The lower-body policy receives proprioception with a short history stack, including base angular velocity, gravity vector, joint positions and velocities, and the previous action. It does not need RGB vision. Its job is to keep the robot upright and execute the command faithfully.
Compare the two interfaces:
| Criterion | Traditional velocity tracking | LMO discrete command |
|---|---|---|
| Command | Continuous velocity along axes | Forward/backward, lateral, yaw, stance-height intent |
| Strength | Flexible for generic locomotion | Clear start/stop behavior, well matched to manipulation |
| Risk | Path drift, weak stopping, fragmented gaits | Requires primitives that cover the task distribution |
| Fit for VLA | VLA must predict continuous values robustly | VLA/decoder predicts easier discrete commands |
This has a direct data-collection consequence: you must log discrete locomotion commands, or at least enough joystick/trajectory data to reconstruct them. If the teleoperator drives with a joystick, do not save only video and joints. Save the command stream, timestamps, robot state, and the mapping from command values to motion primitives. Articles 4 and 5 will go deeper into this part.
Which Data Goes Where?
A WholeBodyVLA-style pipeline has at least four different data stores:
| Data type | Action labels? | Typical source | Used by |
|---|---|---|---|
| Egocentric manipulation video | No, or not required | Robot datasets, human/robot manipulation video | Manipulation LAM |
| Egocentric locomotion video | No, or not required | Head-mounted camera, robot head camera, GoPro/Realsense | Locomotion LAM |
| Teleoperation trajectory | Yes | VR headset, joystick, real robot | Decoder grounding, VLA fine-tuning |
| Simulation rollout for LMO | State/action/reward available | MuJoCo, Isaac Lab, or similar simulator | RL training for low-level locomotion |
The appendix reports that the locomotion LAM is trained on about 300 hours of collected low-cost egocentric locomotion video, while the manipulation LAM uses real-robot bimanual manipulation datasets such as AgiBot World. The VLA is trained from Prismatic-7B and then fine-tuned with LoRA on task-specific data. At deployment, the VLA runs on an RTX 4090 workstation, the RL policy runs on a NanoPi onboard computer, and ZeroMQ over Ethernet handles command streaming. Those exact hardware choices can change in your own system, but the separation between high-level VLA and low-level LMO should remain.
One practical point: LAM data reduces the need for teleoperation, but it does not eliminate teleoperation. LAMs learn an action vocabulary from video. Teleoperation is still needed to ground that vocabulary into a specific robot. Agibot X2 has 7 DoF per arm, a 1 DoF waist, and 6 DoF per leg; another humanoid will have different joint limits, grippers, latency, mass distribution, and actuator behavior. Without Stage III, the latent may be semantically useful but not sufficient for safe real-robot execution.
Why 10 Hz and 50 Hz Matter
In robotics, control frequency is not just an implementation detail; it defines where responsibilities should live. WholeBodyVLA runs the VLA backbone at about 10 Hz for perception and reasoning. At 10 Hz, every cycle is roughly 100 ms. That is enough to update high-level intent: keep moving forward, start turning, squat, switch to grasp, or place the object. For a large VLM-based model, this is far more realistic than requiring it to control every joint at high frequency.
The LMO runs at 50 Hz, or about one cycle every 20 ms. That layer is fast enough to handle balance, contact, foot slip, body sway, and disturbances caused by lifting, placing, or pushing objects. If the robot is pushing a heavy cart, the upper body generates changing forces and shifts the center of mass. You do not want to wait for the VLM to reason again before stabilizing the legs. The low-level controller must react locally and quickly.
The split can be summarized this way:
10 Hz VLA / decoder:
"Which primitive should I do next?"
"Where should the left/right arm joint targets go?"
"Should I request turning, lateral stepping, or squatting?"
50 Hz LMO:
"How do I execute that primitive without falling?"
"Which foot/contact/torque/PD target should be applied now?"
"How do I keep yaw, stance height, CoM, and contacts stable?"
When designing the logger, timestamps must align these two layers. One 10 Hz image frame can correspond to five 50 Hz LMO steps. If timestamps drift, the teleoperation sample teaches the decoder the wrong association: the image and instruction may indicate "stop and grasp," while the command stream still belongs to the previous turning phase.
A Map for the Next Articles
The rest of the series will not start from "collect as much as possible." Each article answers one data question tied to one stage:
| Article | Data question | Related stage |
|---|---|---|
| Article 2 | Which videos are good enough to create latent actions? | Manipulation LAM, locomotion LAM |
| Article 3 | How do we convert motion from another embodiment to the target humanoid? | Retargeting, teleop bootstrap |
| Article 4 | What should teleoperation log besides RGB? | Decoder grounding, VLA fine-tuning |
| Article 5 | How should discrete locomotion commands be designed? | LMO RL |
| Article 6 | Which sim-to-real errors break the pipeline? | LMO deployment, latency, dynamics |
| Article 7 | How should success and failure be evaluated? | Full-system evaluation |
If you remember one thing from this article, make it this: WholeBodyVLA organizes data by learning function. Action-free video creates the latent vocabulary; the VLA learns to predict that vocabulary from images and language; teleoperation grounds the vocabulary into a real robot; and the LMO turns locomotion commands into stable lower-body motion. A dataset is useful only when it serves the correct link in that chain.
Sources
- WholeBodyVLA paper on arXiv
- WholeBodyVLA project page
- OpenDriveLab/WholebodyVLA README
- WholeBodyVLA PDF


