Mục tiêu của bài này
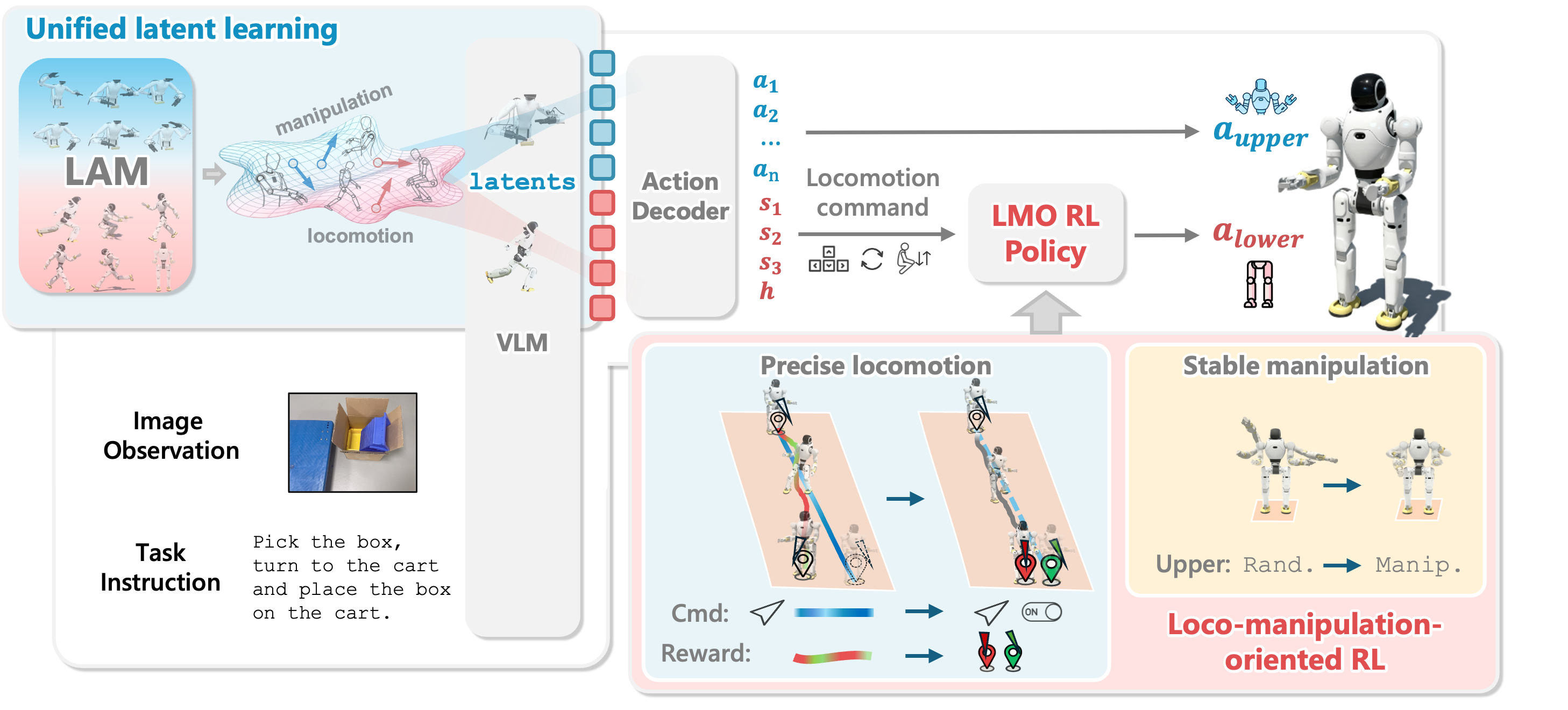
Bốn bài trước đã đi qua bản đồ pipeline, dữ liệu video egocentric, retarget humanoid và teleop toàn thân. Bài 5 chuyển xuống tầng mà người mới thường xem nhẹ nhưng lại quyết định robot có đứng vững hay không: huấn luyện controller thấp tầng bằng reinforcement learning. Trong WholeBodyVLA, tầng VLA không trực tiếp phát torque cho chân. Nó dự đoán action latent, upper-body joint action và lệnh locomotion rời rạc. Lệnh đó được một policy LMO RL thực thi thành chuyển động chân ổn định.
Nếu bạn đang đọc theo thứ tự, hãy xem lại Bản đồ pipeline WholeBodyVLA, Retarget humanoid, và Teleoperation fine-tuning. Sau bài này, phần kế tiếp là Sim-to-real, nơi mọi thứ ta train trong mô phỏng phải chịu latency, sai số actuator và mặt sàn thật. Ngoài series, hai bài nền hữu ích là phân tích WholeBodyVLA ICLR 2026 và hướng dẫn WholebodyVLA open-source.
Bài này dùng ba nguồn thực tế để ground ý tưởng:
| Stack | Ta học gì | Vì sao quan trọng cho WholeBodyVLA |
|---|---|---|
| H2O/OmniH2O | legged_gym/scripts/train_hydra.py, teacher policy, distill student, DAgger, history ablation |
Cho thấy một controller humanoid có thể đi từ privileged simulation sang policy deploy được |
| TWIST | train_teacher.sh, train_student.sh, to_jit.sh |
Cho thấy một tracker whole-body được train rồi xuất thành JIT model để chạy realtime |
| WholeBodyVLA | LMO RL thay velocity tracking bằng discrete command s_x, s_y, s_psi, h* |
Cho thấy interface nào nên nối VLA planner với chân humanoid |
Mục tiêu không phải là copy nguyên repo về chạy ngay. Mục tiêu là đọc được cấu hình, hiểu vì sao có teacher/student, biết DAgger khác direct RL ở đâu, biết env.short_history_length ảnh hưởng gì, và giải thích được vì sao WholeBodyVLA không thích lệnh vận tốc liên tục kiểu v_x, v_y, omega_z cho bài toán loco-manipulation.
Motion tracker là gì?
Trong bối cảnh humanoid, motion tracker là policy nhận trạng thái robot và một mục tiêu chuyển động, rồi xuất action thấp tầng để robot bám mục tiêu đó. Mục tiêu có thể là motion retargeted từ AMASS, keypoint từ camera, pose từ VR, trajectory từ teleop, hoặc một command rời rạc như "đi tới", "bước ngang", "xoay", "ngồi thấp xuống".
Một tracker tốt phải thỏa ba điều kiện:
- Robot không ngã khi mục tiêu có tay, thân và chân cùng thay đổi.
- Robot bám ý định đủ chính xác để dữ liệu thu được có thể dùng cho VLA.
- Policy deploy chỉ dùng sensor có trên robot thật, không dựa vào thông tin đặc quyền của simulator.
Điểm thứ ba là lý do teacher/student xuất hiện rất nhiều trong H2O, OmniH2O và TWIST. Trong mô phỏng, ta có thể cho teacher nhìn nhiều thứ: root pose chuẩn, future motion frame, contact state, terrain, reference đầy đủ. Nhưng robot thật không có các biến đó một cách sạch và realtime. Student phải học bắt chước teacher bằng input nghèo hơn: IMU, joint position, joint velocity, previous action, một ít history và command.
Mô hình tinh thần:
reference motion / command
|
v
privileged teacher in sim ---> target action / target distribution
|
v
deployable student policy ---> robot action on real sensor input
Khi đọc paper, beginner dễ hiểu nhầm "RL policy" là một network duy nhất được train xong rồi chạy. Trong thực tế, pipeline thường có nhiều policy ở nhiều vai trò: teacher để khám phá skill trong sim, student để deploy, critic để học value, và đôi khi thêm DAgger expert để sửa các trạng thái student tự gây ra.
H2O/OmniH2O: đọc train_hydra.py như một checklist
Repo H2O/OmniH2O công bố lệnh train trực tiếp bằng Hydra. README khuyến nghị làm quen với Legged Gym/RSL-RL trước, sau đó cài Isaac Gym, rsl_rl, legged_gym, phc và requirements. Phần quan trọng với bài này là các command python legged_gym/scripts/train_hydra.py --config-name=config_teleop ....
Ví dụ teacher OmniH2O trong README có dạng:
python legged_gym/scripts/train_hydra.py \
--config-name=config_teleop \
task=h1:teleop \
run_name=OmniH2O_TEACHER \
env.num_observations=913 \
env.num_privileged_obs=990 \
motion.teleop_obs_version=v-teleop-extend-max-full \
motion=motion_full \
motion.extend_head=True \
num_envs=4096 \
asset.zero_out_far=False \
asset.termination_scales.max_ref_motion_distance=1.5 \
sim_device=cuda:0 \
motion.motion_file=resources/motions/h1/stable_punch.pkl \
rewards=rewards_teleop_omnih2o_teacher \
rewards.penalty_curriculum=True \
rewards.penalty_scale=0.5
Đừng đọc command này như một chuỗi tham số ngẫu nhiên. Nó là một bản mô tả thí nghiệm.
| Key | Ý nghĩa thực dụng | Câu hỏi cần tự trả lời |
|---|---|---|
task=h1:teleop |
Chọn robot/task teleop cho H1 | Robot của mình có cùng morphology không? |
env.num_observations |
Kích thước observation deploy được | Có khớp với vector input của policy không? |
env.num_privileged_obs |
Observation cho critic/teacher trong sim | Có dùng biến mà robot thật không đo được không? |
motion.teleop_obs_version |
Schema motion observation | Data retargeted đang xuất đúng schema chưa? |
motion.extend_head=True |
Mở rộng observation bằng head/keypoint liên quan | Camera/head pose có cần cho teleop không? |
motion.motion_file |
Motion clip để imitate | Clip có sạch, feasible và đúng robot không? |
rewards.penalty_curriculum |
Tăng dần penalty để ổn định học | Policy đang học skill trước hay bị phạt quá sớm? |
Với beginner, cách debug tốt là viết lại command thành file ghi chú trước khi chạy. Mỗi key phải có một giả thuyết. Nếu loss xấu hoặc robot ngã, bạn cần biết nên nghi ngờ motion file, reward, observation schema hay termination.
Teacher và student: vì sao phải distill?
OmniH2O mô tả pipeline sim-to-real gồm retargeting/augmentation motion quy mô lớn, học policy deploy được bằng cách imitate privileged teacher, và reward để tăng robustness/stability. Lệnh student trong README bật các key rất đáng chú ý:
python legged_gym/scripts/train_hydra.py \
--config-name=config_teleop \
task=h1:teleop \
run_name=OmniH2O_STUDENT \
env.num_observations=1665 \
env.num_privileged_obs=1742 \
motion.teleop_obs_version=v-teleop-extend-vr-max-nolinvel \
motion.teleop_selected_keypoints_names=[] \
motion.extend_head=True \
env.add_short_history=True \
env.short_history_length=25 \
train.distill=True \
train.policy.init_noise_std=0.001 \
train.dagger.load_run_dagger=TEACHER_RUN_NAME \
train.dagger.checkpoint_dagger=XXX \
train.dagger.dagger_only=True
train.distill=True nói rằng student không chỉ tối ưu reward như một policy RL độc lập. Nó đang học từ teacher. Trong policy distillation, teacher thường mạnh hơn nhưng đắt hơn hoặc cần observation đặc quyền; student nhỏ hơn hoặc bị giới hạn input để chạy trên robot thật. Student có thể học hành động trung bình, phân phối hành động, hoặc latent target của teacher tùy implementation.
train.dagger.load_run_dagger=TEACHER_RUN_NAME cho biết teacher run nào được dùng làm expert. DAgger, viết tắt của Dataset Aggregation, giải quyết một lỗi kinh điển của imitation learning: nếu student chỉ học trên trạng thái teacher từng đi qua, khi deploy student mắc lỗi nhỏ và rơi vào trạng thái lạ, nó không biết sửa. DAgger cho student chạy, ghi lại các trạng thái student tự tạo ra, hỏi expert nên làm gì tại các trạng thái đó, rồi gộp dữ liệu mới vào tập train. Vì vậy DAgger gần với "học sửa lỗi của chính mình" hơn là behavior cloning offline đơn giản.
So sánh nhanh:
| Cách train | Policy thấy trạng thái nào? | Ưu điểm | Rủi ro |
|---|---|---|---|
| Direct RL | Trạng thái do policy hiện tại tạo ra trong simulator | Có thể khám phá skill, không cần teacher tốt | Reward design khó, dễ học gait xấu nếu reward thiếu |
| Behavior cloning offline | Trạng thái trong dataset/expert trajectory | Đơn giản, ổn cho imitation sạch | Covariate shift: student lệch nhỏ là vào vùng chưa học |
| Distillation | Trạng thái teacher hoặc replay buffer, label từ teacher | Chuyển skill từ policy mạnh sang policy deploy được | Student có thể bắt chước cả bias của teacher |
| DAgger | Trạng thái student tự gặp, expert gán nhãn | Giảm lỗi tích lũy khi deploy | Cần expert/teacher trả lời nhiều lần, pipeline phức tạp hơn |
Trong controller humanoid, DAgger đặc biệt hữu ích vì một lỗi nhỏ ở chân không chỉ làm pose lệch; nó đổi toàn bộ phân phối trạng thái. Joint velocity tăng, IMU nghiêng, contact phase sai, tay tạo moment khác, rồi policy nhìn thấy input mà nó chưa từng học. Direct RL có thể tự khám phá các trạng thái đó, nhưng nếu mục tiêu là deploy một tracker bám motion đã có, dùng teacher để gán nhãn các trạng thái student lạc khỏi quỹ đạo thường tiết kiệm hơn.
env.short_history_length: tại sao history quan trọng?
Một humanoid không thể quyết định action tốt nếu chỉ nhìn snapshot hiện tại. Cùng một joint position có thể thuộc hai tình huống khác nhau: robot đang chuẩn bị nhấc chân hoặc vừa đặt chân xuống; thân đang quay trái hay đang phanh; tay đang tăng tốc hay dừng lại. Vì vậy nhiều policy thêm history ngắn của proprioception/action.
OmniH2O README có phần "Different Configurations on History Steps" với 0-step MLP, 5-step MLP, LSTM/GRU và student dùng env.short_history_length=25. Đây không phải chi tiết phụ. Nó là một ablation về bộ nhớ.
| Cấu hình | Ý nghĩa | Khi nào hợp |
|---|---|---|
env.add_short_history=False |
Policy chỉ thấy observation hiện tại | Baseline đơn giản, dễ debug kích thước input |
env.short_history_length=5 |
Có vài frame quá khứ | Đủ cho contact phase ngắn, input không quá lớn |
env.short_history_length=25 |
History dài hơn cho teleop/motion tracking | Hợp khi upper body và motion target gây nhiễu quán tính |
| LSTM/GRU | Bộ nhớ học được, không chỉ concatenate frame | Hợp khi muốn deploy input gọn hơn nhưng vẫn cần temporal state |
Với người mới, cách đọc ablation là: nếu 0-step MLP đi được nhưng tracking xấu, policy thiếu vận tốc/ngữ cảnh thời gian. Nếu 25-step MLP tốt trong sim nhưng deploy rung, có thể history bị lệch do latency hoặc frame drop. Nếu RNN tốt nhưng khó debug, hãy log hidden state reset, timestep, và episode boundary thật kỹ.
Một checklist tối thiểu:
Khi đổi history length:
1. Cập nhật env.num_observations đúng với kích thước vector mới.
2. Kiểm tra play script dùng cùng env.add_short_history và env.short_history_length.
3. Log observation normalization, vì history làm phân phối input đổi mạnh.
4. Test zero command, start/stop, turn, squat trước khi chạy motion dài.
5. Khi deploy thật, đảm bảo control loop không bị miss frame làm history trượt.
TWIST: teacher, student, rồi xuất JIT
TWIST là stack rất hữu ích để hiểu vòng đời một tracker whole-body. README công bố ba bước gọn:
# 1. Train teacher policy bằng RL
bash train_teacher.sh 0927_twist_teacher cuda:0
# 2. Train student policy bằng RL + BC, dùng cùng teacher expid
bash train_student.sh 0927_twist_rlbcstu 0927_twist_teacher cuda:0
# 3. Xuất student policy thành JIT model
bash to_jit.sh 0927_twist_rlbcstu
Điểm đáng học không nằm ở tên script, mà ở separation of concerns. Teacher được train để học tracking mạnh trong simulation. Student được train bằng RL+BC để chạy ổn hơn với input deploy. Cuối cùng to_jit.sh xuất model TorchScript để low-level server có thể load bằng torch.jit.load và inference realtime.
Với data collection WholeBodyVLA, bước JIT/ONNX/export không phải việc "sau cùng mới tính". Ngay từ khi design observation, bạn phải nghĩ đến deploy:
| Câu hỏi deploy | Nếu bỏ qua sẽ hỏng ở đâu |
|---|---|
| Input policy có phụ thuộc Python object hoặc simulator object không? | Không export được sang JIT/ONNX sạch |
| Normalization statistics được lưu cùng checkpoint chưa? | Sim chạy tốt, real chạy lệch vì scale input sai |
| History buffer nằm trong policy hay trong runner? | Deployment server dễ feed sai thứ tự frame |
| Action scale/default pose nằm ở đâu? | JIT output đúng nhưng PD target sai |
| Control frequency có cố định không? | Policy học 50 Hz nhưng real chạy jitter 30-70 Hz |
TWIST còn cho thấy một thực hành tốt: sau khi xuất JIT, chạy sim2sim trước khi lên robot. High-level motion server publish command qua Redis, low-level sim server load JIT model và điều khiển MuJoCo. Nếu JIT model đã hỏng trong sim2sim, đừng đưa nó lên robot thật.
Từ motion tracking sang LMO của WholeBodyVLA
Các tracker như H2O/OmniH2O/TWIST chủ yếu bám motion hoặc keypoint. WholeBodyVLA cần một interface khác cho locomotion trong nhiệm vụ dài: VLA phải ra quyết định như "tiến tới kệ", "bước ngang để căn vị trí", "xoay người", "squat để đặt vật". Nếu bắt VLA phát vận tốc liên tục ở mỗi timestep, planner và controller rất dễ lệch nhau.
WholeBodyVLA gọi policy này là Loco-Manipulation-Oriented RL. Paper chỉ ra rằng nhiều controller locomotion trước đó dùng velocity tracking liên tục. Cách này phù hợp khi robot cần đi nhiều kiểu vận tốc trên địa hình, nhưng với loco-manipulation nó tạo ba vấn đề:
- Start/stop không rõ ràng. Một chuỗi velocity nhỏ có thể nghĩa là đang bắt đầu đi, đang phanh, hoặc noise của planner.
- Gait bị phân mảnh theo vận tốc. Policy phải học nhiều biến thể gait cho nhiều speed thay vì học intent sạch.
- High-level VLA khó đánh giá lỗi. Nếu nhiệm vụ là "bước sang trái rồi squat", sai số vận tốc tức thời không nói rõ robot có dừng đúng vị trí không.
LMO thay interface bằng command rời rạc:
u_t = [s_x, s_y, s_psi, h_star]
# Diễn giải trực quan:
# s_x : intent tiến/lùi, thường là {-1, 0, 1}
# s_y : intent bước ngang trái/phải, thường là {-1, 0, 1}
# s_psi : intent xoay trái/phải, thường là {-1, 0, 1}
# h_star: stance height hoặc mục tiêu squat/đứng
Paper mô tả policy dùng proprioceptive egocentric state với short history: base angular velocity, gravity vector, joint state và previous action. Planner phát command rời rạc; policy thực thi command trong khi giữ thăng bằng. Để tránh giật khi flag bật/tắt, paper dùng reference shaping: intent rời rạc được làm mượt trước khi thành tốc độ mục tiêu nội bộ. Nói cách khác, interface với VLA là rời rạc, nhưng controller vẫn có smoothing bên trong để actuator không nhận bước nhảy thô.
Vì sao discrete command hợp với beginner hơn?
Với người mới xây pipeline, discrete command dễ kiểm thử hơn nhiều so với velocity tracking. Bạn có thể viết test theo episode:
Test LMO cơ bản:
1. stand: [0, 0, 0, h_stand] trong 10 giây
2. forward: [1, 0, 0, h_stand] trong 2 mét rồi stop
3. lateral: [0, 1, 0, h_stand] trong 1 mét rồi stop
4. turn: [0, 0, 1, h_stand] tới 90 độ rồi stop
5. squat: [0, 0, 0, h_low] rồi trở lại h_stand
6. carry+walk: tay giữ pose nặng, chân forward rồi stop
7. place: lateral nhỏ, turn nhỏ, squat, đứng lại
Mỗi test có tiêu chí rõ: có ngã không, overshoot bao nhiêu, heading drift bao nhiêu, sau stop còn bước thừa không, tay có làm robot lắc quá mức không. Đây chính là thứ WholeBodyVLA cần cho bag packing, box loading và cart pushing: không phải "đi với vận tốc 0.37 m/s", mà là thiết lập tư thế để thao tác.
Discrete command cũng giúp dataset sạch hơn. Khi log teleop hoặc VLA rollout, ta có thể annotate theo primitive:
| Primitive | Command | Label dễ hiểu |
|---|---|---|
| Tiến tới vật | [1, 0, 0, h_stand] |
approach |
| Căn ngang trước thùng | [0, ±1, 0, h_stand] |
sidestep_align |
| Quay về hướng cart | [0, 0, ±1, h_stand] |
turn_to_target |
| Hạ thấp để đặt vật | [0, 0, 0, h_low] |
squat_place |
| Đứng im giữ thăng bằng | [0, 0, 0, h_stand] |
stabilize |
Khi VLA dự đoán sai, ta dễ biết sai ở đâu: chọn sai primitive, dừng sai thời điểm, hay LMO thực thi kém. Với velocity tracking, lỗi thường bị trộn thành một chuỗi số khó đọc.
Một recipe tái lập cho bài 5
Nếu muốn biến bài này thành thí nghiệm thật, hãy đi theo thứ tự sau thay vì nhảy thẳng lên robot:
Phase 0 - Chốt interface
observation = proprio + previous_action + short_history + command
command = [s_x, s_y, s_psi, h_star]
action = lower-body joint target hoặc torque target
Phase 1 - Train teacher trong sim
dùng privileged obs nếu cần
train gait tối thiểu: stand, forward, lateral, turn
thêm squat và upper-body perturbation sau
Phase 2 - Distill student
giới hạn input về sensor deploy được
bật short history hoặc RNN
dùng teacher checkpoint làm expert
Phase 3 - DAgger/hard-state collection
cho student chạy trong sim
lưu trạng thái student làm sai
hỏi teacher action tại trạng thái đó
retrain student trên dataset gộp
Phase 4 - Export và sim2sim
export JIT/ONNX
chạy cùng normalization, history, action scale
test start/stop/turn/squat bằng command rời rạc
Phase 5 - Real robot dry run
torque limit thấp, vùng an toàn
zero command trước
bật từng primitive
log IMU, joint, action, command, latency
Quan trọng nhất: đừng đánh giá policy chỉ bằng reward training. Với WholeBodyVLA, metric phải gắn với nhiệm vụ. Một LMO tốt là policy giúp high-level planner đặt robot đúng precondition cho thao tác: đứng đủ gần, quay đúng hướng, hạ thấp đúng lúc, dừng chắc, không làm vật đang cầm lắc quá mức.
Những lỗi thường gặp
Lỗi đầu tiên là train teacher quá mạnh nhưng student deploy quá nghèo. Teacher nhìn future reference và privileged state nên tracking đẹp; student chỉ nhìn IMU/joint/history nên không khôi phục được. Khi đó hãy giảm khoảng cách teacher-student: thêm observation deploy được, tăng history, hoặc dùng DAgger thay vì chỉ distill offline.
Lỗi thứ hai là đổi motion.teleop_obs_version mà không đổi env.num_observations. Hydra cho phép override nhanh, nhưng network input không tha thứ cho vector sai kích thước. Mỗi lần đổi keypoint, head extension hoặc history, hãy in shape observation ở train và play.
Lỗi thứ ba là history tốt trong sim nhưng xấu ngoài đời. Nguyên nhân thường là control loop không đều, timestamp không được dùng, hoặc deployment server lặp lại frame cũ khi sensor chậm. History chỉ hữu ích nếu thứ tự thời gian đúng.
Lỗi thứ tư là dùng velocity command cho mọi thứ. Với walking benchmark thì được, nhưng với loco-manipulation, VLA cần các động tác có nghĩa: tiến, dừng, bước ngang, xoay, squat. LMO không phủ nhận velocity tracking hoàn toàn; nó chọn interface rời rạc ở biên giữa high-level planner và low-level controller, rồi làm mượt bên trong.
Kết luận
H2O/OmniH2O và TWIST cho ta bài học thực dụng: controller humanoid đáng tin cậy thường không phải một lần train duy nhất. Nó là pipeline gồm teacher, student, distillation, DAgger hoặc RL+BC, ablation history, export model và sim2sim verification. WholeBodyVLA lấy tinh thần đó nhưng đổi interface cho phù hợp với loco-manipulation: thay vì bắt VLA phát vận tốc liên tục, LMO nhận command rời rạc s_x, s_y, s_psi, h* để thực thi các primitive có nghĩa.
Nếu bạn chỉ nhớ một câu, hãy nhớ câu này: VLA nên quyết định "robot cần làm primitive nào để thao tác được", còn LMO RL chịu trách nhiệm biến primitive đó thành chuyển động chân ổn định, có start/stop rõ ràng và chịu được nhiễu từ tay.