What This Article Is For
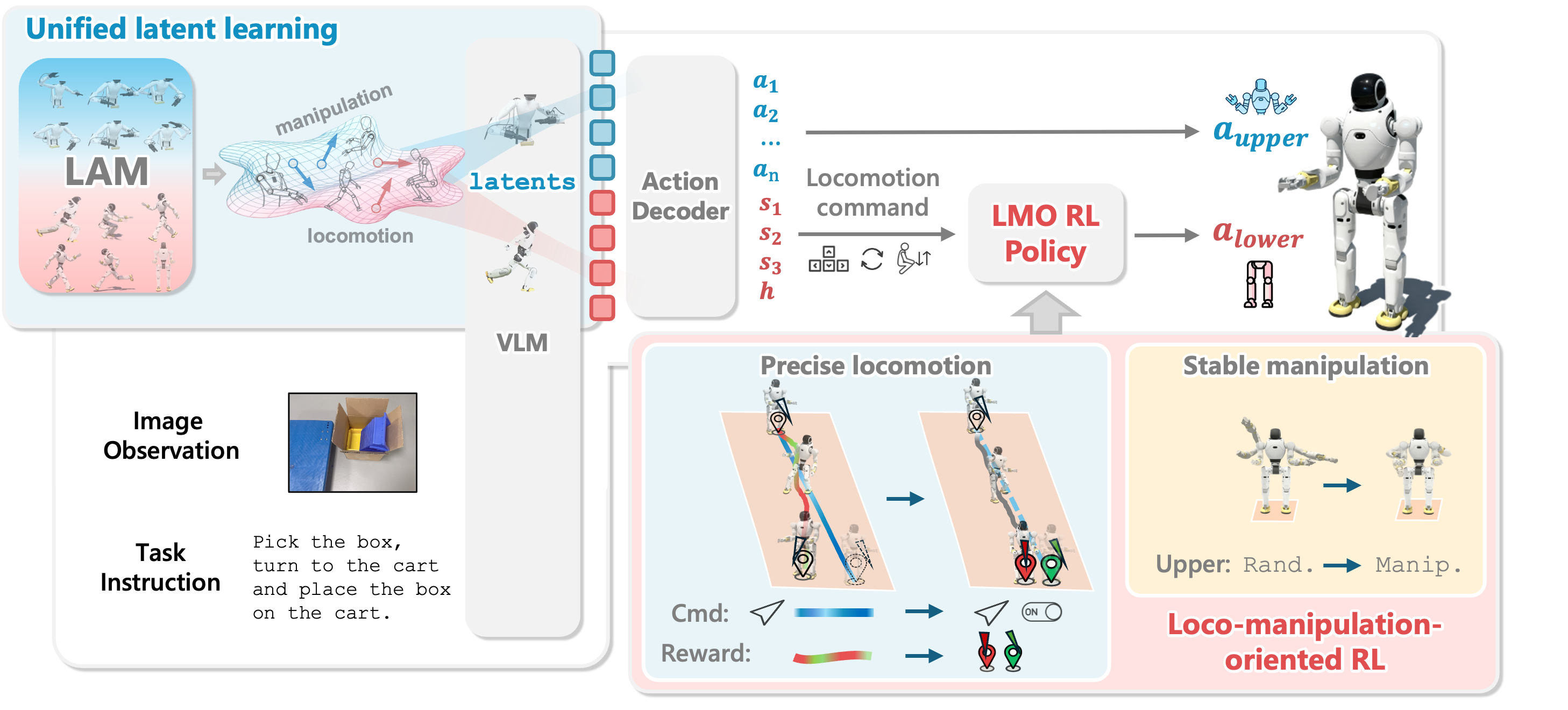
The first four articles mapped the WholeBodyVLA pipeline, collected egocentric video, retargeted humanoid motion, and designed a whole-body teleoperation station. Article 5 moves down to the layer beginners often underestimate but real robots cannot survive without: the low-level reinforcement learning controller. In WholeBodyVLA, the VLA does not directly emit leg torques. It predicts latent actions, upper-body joint actions, and locomotion commands. A Loco-Manipulation-Oriented RL policy, or LMO RL policy, turns those commands into stable lower-body motion.
If you are reading the series in order, revisit Mapping the WholeBodyVLA Pipeline, Humanoid Retargeting, and Teleoperation Fine-Tuning. The next article is Sim-to-Real, where everything trained in simulation has to tolerate latency, actuator error, and real floor contact. Outside this series, the WholeBodyVLA ICLR 2026 analysis and WholebodyVLA open-source guide give broader context.
This article grounds the idea in three concrete sources:
| Stack | What we learn | Why it matters for WholeBodyVLA |
|---|---|---|
| H2O/OmniH2O | legged_gym/scripts/train_hydra.py, teacher policies, student distillation, DAgger, history ablations |
Shows how a humanoid controller can move from privileged simulation to deployable policy |
| TWIST | train_teacher.sh, train_student.sh, to_jit.sh |
Shows how a whole-body tracker is trained and exported as a realtime JIT model |
| WholeBodyVLA | LMO RL replaces velocity tracking with discrete commands s_x, s_y, s_psi, h* |
Shows the right interface between a VLA planner and humanoid legs |
The goal is not to clone a repository and run it blindly. The goal is to read the configs, understand why teacher/student training exists, explain how DAgger differs from direct RL, reason about env.short_history_length, and understand why WholeBodyVLA avoids continuous velocity commands as the main interface for loco-manipulation.
What Is a Motion Tracker?
For a humanoid, a motion tracker is a policy that receives robot state plus a motion objective, then outputs low-level actions that make the robot follow that objective. The objective may be an AMASS-retargeted motion, camera keypoints, VR poses, teleoperation trajectories, or a discrete command such as "move forward", "sidestep", "turn", or "squat".
A useful tracker must satisfy three conditions:
- The robot stays upright when the arms, torso, and legs move together.
- The robot follows intent accurately enough that the collected data can train a VLA.
- The deployed policy only uses sensors available on the real robot, not privileged simulator state.
The third condition is why teacher/student training appears throughout H2O, OmniH2O, and TWIST. In simulation, the teacher can observe many things: clean root pose, future motion frames, contact state, terrain, and full reference motion. The real robot cannot access those variables cleanly and in realtime. The student must imitate the teacher with poorer but deployable input: IMU, joint position, joint velocity, previous action, a short history, and the command.
Mental model:
reference motion / command
|
v
privileged teacher in sim ---> target action / target distribution
|
v
deployable student policy ---> robot action on real sensor input
Beginners often read "RL policy" as a single network that is trained once and deployed. In practice, a training pipeline may contain several policies with different roles: a teacher for skill discovery in simulation, a student for deployment, a critic for value learning, and sometimes a DAgger expert used to correct states created by the student itself.
H2O/OmniH2O: Reading train_hydra.py as a Checklist
The H2O/OmniH2O repository publishes direct Hydra commands for training. Its README recommends first getting familiar with Legged Gym and RSL-RL, then installing Isaac Gym, rsl_rl, legged_gym, phc, and the remaining requirements. The important part for this article is the command pattern: python legged_gym/scripts/train_hydra.py --config-name=config_teleop ....
A teacher command from the OmniH2O README looks like this:
python legged_gym/scripts/train_hydra.py \
--config-name=config_teleop \
task=h1:teleop \
run_name=OmniH2O_TEACHER \
env.num_observations=913 \
env.num_privileged_obs=990 \
motion.teleop_obs_version=v-teleop-extend-max-full \
motion=motion_full \
motion.extend_head=True \
num_envs=4096 \
asset.zero_out_far=False \
asset.termination_scales.max_ref_motion_distance=1.5 \
sim_device=cuda:0 \
motion.motion_file=resources/motions/h1/stable_punch.pkl \
rewards=rewards_teleop_omnih2o_teacher \
rewards.penalty_curriculum=True \
rewards.penalty_scale=0.5
Do not read this as a random string of overrides. It is an experiment specification.
| Key | Practical meaning | Question to ask |
|---|---|---|
task=h1:teleop |
Selects the H1 teleoperation task | Does your robot share the same morphology? |
env.num_observations |
Size of the deployable observation vector | Does it match the policy input? |
env.num_privileged_obs |
Observation for the critic or teacher in simulation | Does it include variables unavailable on the real robot? |
motion.teleop_obs_version |
Motion observation schema | Does your retargeted data produce the same schema? |
motion.extend_head=True |
Extends observations with head or related keypoints | Does the teleop setting need head/camera pose? |
motion.motion_file |
Motion clip used for imitation | Is the clip clean, feasible, and robot-specific? |
rewards.penalty_curriculum |
Gradually increases penalties | Is the policy learning a skill first, or being punished too early? |
For a beginner, a good debugging practice is to rewrite the command into a short experiment note before running it. Every key should have a hypothesis. If the robot falls or the loss behaves badly, you need to know whether to suspect the motion file, reward, observation schema, or termination condition.
Teacher and Student: Why Distill?
OmniH2O describes a sim-to-real pipeline with large-scale retargeting and augmentation of human motion, learning a deployable policy by imitating a privileged teacher, and reward design for robustness and stability. The student command in the README enables several important keys:
python legged_gym/scripts/train_hydra.py \
--config-name=config_teleop \
task=h1:teleop \
run_name=OmniH2O_STUDENT \
env.num_observations=1665 \
env.num_privileged_obs=1742 \
motion.teleop_obs_version=v-teleop-extend-vr-max-nolinvel \
motion.teleop_selected_keypoints_names=[] \
motion.extend_head=True \
env.add_short_history=True \
env.short_history_length=25 \
train.distill=True \
train.policy.init_noise_std=0.001 \
train.dagger.load_run_dagger=TEACHER_RUN_NAME \
train.dagger.checkpoint_dagger=XXX \
train.dagger.dagger_only=True
train.distill=True tells us that the student is not merely optimizing a reward like a standalone RL policy. It is learning from a teacher. In policy distillation, the teacher is usually stronger but expensive or privileged; the student is smaller or constrained to deployable observations. Depending on implementation, the student may learn the teacher's mean action, action distribution, or latent target.
train.dagger.load_run_dagger=TEACHER_RUN_NAME identifies which teacher run is used as the expert. DAgger, short for Dataset Aggregation, fixes a classic imitation learning failure. If a student only trains on states visited by the teacher, then a small deployment mistake can push it into an unfamiliar state where it does not know how to recover. DAgger runs the student, records the states the student actually creates, queries the expert for the correct action at those states, and aggregates the new data into training. It is closer to "learning to recover from your own mistakes" than to plain offline behavior cloning.
Quick comparison:
| Training method | Which states does the policy see? | Advantage | Risk |
|---|---|---|---|
| Direct RL | States induced by the current policy in simulation | Can discover skills without a good teacher | Reward design is hard; bad rewards can produce bad gaits |
| Offline behavior cloning | States in the expert dataset | Simple and effective for clean imitation | Covariate shift when the student drifts from the dataset |
| Distillation | Teacher states or replay states, labeled by the teacher | Transfers a strong policy into a deployable one | The student can inherit teacher bias |
| DAgger | States visited by the student, labeled by the expert | Reduces accumulated deployment errors | Requires repeated expert or teacher queries |
For humanoid control, DAgger is especially useful because a small leg error does more than shift pose. It changes the entire state distribution: joint velocities rise, the IMU tilts, contact phase changes, the arms create different moments, and the policy sees observations it may never have trained on. Direct RL can explore those states, but if the goal is to deploy a tracker for known motion, using a teacher to label student-induced states is often more efficient.
env.short_history_length: Why Memory Matters
A humanoid cannot choose good actions from a single snapshot alone. The same joint position can belong to two different situations: the robot is about to lift a foot, or it has just placed it down; the torso is turning left, or braking; the arm is accelerating, or stopping. That is why many policies add a short history of proprioception and actions.
The OmniH2O README includes "Different Configurations on History Steps", including a 0-step MLP, a 5-step MLP, LSTM/GRU variants, and a student using env.short_history_length=25. This is not a small detail. It is a memory ablation.
| Configuration | Meaning | When it helps |
|---|---|---|
env.add_short_history=False |
The policy sees only the current observation | Simple baseline and easy shape debugging |
env.short_history_length=5 |
A few past frames are concatenated | Captures short contact phase without huge input |
env.short_history_length=25 |
Longer history for teleop or motion tracking | Useful when upper-body motion creates inertial disturbance |
| LSTM/GRU | Learned memory instead of concatenated frames | Useful when you want compact input but temporal state |
For beginners, the ablation should be interpreted practically. If a 0-step MLP can walk but tracks poorly, the policy may lack temporal context. If a 25-step MLP works in simulation but jitters in deployment, history may be corrupted by latency or dropped frames. If an RNN works but is hard to debug, carefully log hidden-state resets, timestep alignment, and episode boundaries.
A minimal checklist:
When changing history length:
1. Update env.num_observations to match the new vector size.
2. Ensure the play script uses the same env.add_short_history and env.short_history_length.
3. Log observation normalization because history changes the input distribution.
4. Test zero command, start/stop, turn, and squat before long motions.
5. In real deployment, make sure the control loop does not miss frames and shift history.
TWIST: Teacher, Student, Then JIT Export
TWIST is a useful stack for understanding the lifecycle of a whole-body tracker. Its README publishes three compact steps:
# 1. Train the teacher policy with RL
bash train_teacher.sh 0927_twist_teacher cuda:0
# 2. Train the student policy with RL + BC, using the same teacher expid
bash train_student.sh 0927_twist_rlbcstu 0927_twist_teacher cuda:0
# 3. Export the student policy as a JIT model
bash to_jit.sh 0927_twist_rlbcstu
The lesson is not the script names themselves. The lesson is separation of concerns. The teacher is trained to become a strong tracking policy in simulation. The student is trained with RL+BC so it can run robustly with deployable input. Finally, to_jit.sh exports a TorchScript model so a low-level server can load it with torch.jit.load and run realtime inference.
For WholeBodyVLA data collection, JIT/ONNX export is not a final afterthought. You should think about deployment while designing observations:
| Deployment question | What breaks if ignored |
|---|---|
| Does the policy input depend on Python objects or simulator-only objects? | Clean JIT/ONNX export fails |
| Are normalization statistics saved with the checkpoint? | Simulation works, real deployment sees wrong input scale |
| Is the history buffer inside the policy or inside the runner? | The deployment server may feed frames in the wrong order |
| Where are action scale and default pose stored? | JIT output is valid, but PD targets are wrong |
| Is control frequency fixed? | A policy trained at 50 Hz may jitter at 30-70 Hz |
TWIST also illustrates a good practice: after exporting JIT, verify with sim2sim before using the real robot. The high-level motion server publishes commands through Redis; the low-level simulation server loads the JIT model and controls MuJoCo. If the JIT model already fails in sim2sim, it should not be moved to hardware.
From Motion Tracking to WholeBodyVLA's LMO
Trackers such as H2O, OmniH2O, and TWIST mainly follow motion or keypoints. WholeBodyVLA needs a different locomotion interface for long-horizon tasks. The VLA needs to decide things like "approach the shelf", "sidestep to align", "turn toward the target", and "squat to place the object". If the VLA must output continuous velocity at every timestep, the planner and controller can easily disagree.
WholeBodyVLA calls its controller Loco-Manipulation-Oriented RL. The paper argues that many previous locomotion controllers use continuous velocity tracking. That works for broad walking benchmarks, but it creates three problems in loco-manipulation:
- Start and stop are implicit. A short sequence of small velocities could mean starting, braking, or planner noise.
- Gaits fragment across velocities. The policy must learn many gait variants for many speeds instead of clean intent.
- High-level error is hard to diagnose. If the task is "sidestep, then squat", instantaneous velocity error does not reveal whether the robot stopped in the right place.
LMO changes the interface to discrete commands:
u_t = [s_x, s_y, s_psi, h_star]
# Intuitive meaning:
# s_x : forward/backward intent, often {-1, 0, 1}
# s_y : left/right lateral intent, often {-1, 0, 1}
# s_psi : left/right turning intent, often {-1, 0, 1}
# h_star: stance height or squat/stand target
The paper describes a policy that uses proprioceptive egocentric state with a short history: base angular velocity, gravity vector, joint states, and previous action. The planner emits a discrete command; the policy executes that command while maintaining balance. To avoid abrupt motion when flags turn on or off, the paper uses reference shaping: discrete intent is smoothed before becoming an internal target speed. In other words, the VLA-facing interface is discrete, while the controller still performs smoothing internally so actuators do not receive raw discontinuities.
Why Discrete Commands Are Easier for Beginners
For a beginner building the pipeline, discrete commands are much easier to test than velocity tracking. You can design episode-level tests:
Basic LMO tests:
1. stand: [0, 0, 0, h_stand] for 10 seconds
2. forward: [1, 0, 0, h_stand] for 2 meters, then stop
3. lateral: [0, 1, 0, h_stand] for 1 meter, then stop
4. turn: [0, 0, 1, h_stand] until 90 degrees, then stop
5. squat: [0, 0, 0, h_low], then return to h_stand
6. carry+walk: arms hold a payload pose, legs move forward and stop
7. place: small lateral move, small turn, squat, stabilize
Each test has clear criteria: did the robot fall, how much did it overshoot, how much heading drift remained, did it take extra steps after stop, and did arm motion shake the body too much? That is exactly what WholeBodyVLA needs for bag packing, box loading, and cart pushing. The low-level controller is not being asked to track "0.37 m/s forever"; it is being asked to establish the right body precondition for manipulation.
Discrete commands also make logs cleaner. During teleop or VLA rollout, the locomotion stream can be annotated by primitive:
| Primitive | Command | Readable label |
|---|---|---|
| Approach object | [1, 0, 0, h_stand] |
approach |
| Align beside box | [0, ±1, 0, h_stand] |
sidestep_align |
| Face cart | [0, 0, ±1, h_stand] |
turn_to_target |
| Lower to place object | [0, 0, 0, h_low] |
squat_place |
| Stand and stabilize | [0, 0, 0, h_stand] |
stabilize |
When the VLA fails, the failure is easier to classify: wrong primitive, wrong stopping time, or poor LMO execution. With velocity tracking, the same failure is often hidden inside a long numeric sequence.
A Reproducible Recipe for Article 5
If you want to turn this article into a real experiment, follow this order instead of jumping directly to hardware:
Phase 0 - Fix the interface
observation = proprio + previous_action + short_history + command
command = [s_x, s_y, s_psi, h_star]
action = lower-body joint target or torque target
Phase 1 - Train the teacher in simulation
use privileged observation if needed
train minimal gait: stand, forward, lateral, turn
add squat and upper-body perturbation later
Phase 2 - Distill the student
limit input to deployable robot sensors
enable short history or an RNN
use the teacher checkpoint as expert
Phase 3 - DAgger / hard-state collection
run the student in simulation
save states where the student fails
query the teacher for actions at those states
retrain the student on the aggregated dataset
Phase 4 - Export and sim2sim
export JIT or ONNX
run with identical normalization, history, and action scale
test start/stop/turn/squat using discrete commands
Phase 5 - Real-robot dry run
use low torque limits and a safe area
start with zero command
enable one primitive at a time
log IMU, joints, action, command, and latency
Most importantly, do not evaluate the policy only with training reward. For WholeBodyVLA, metrics must be task-facing. A good LMO policy helps the high-level planner place the robot in the correct precondition for manipulation: close enough, facing the right direction, at the right height, stopped cleanly, and not shaking the object in the hands.
Common Failure Modes
The first failure mode is a teacher that is too privileged and a student that is too poor. The teacher sees future reference and privileged state, so tracking looks excellent. The student only sees IMU, joints, and history, so it cannot reconstruct the same control signal. Reduce the gap by adding deployable observations, increasing history, or using DAgger instead of offline distillation alone.
The second failure mode is changing motion.teleop_obs_version without changing env.num_observations. Hydra makes overrides easy, but the network input size is unforgiving. Every time you change keypoints, head extension, or history, print the observation shape in both train and play.
The third failure mode is history that works in simulation but fails on hardware. The cause is often an uneven control loop, missing timestamps, or a deployment server that repeats stale frames when sensors lag. History only helps if time order is correct.
The fourth failure mode is using velocity commands for everything. That is fine for a walking benchmark, but loco-manipulation needs meaningful primitives: approach, stop, sidestep, turn, squat. LMO does not reject velocity tracking entirely. It chooses a discrete interface at the boundary between high-level planner and low-level controller, then smooths internally.
Conclusion
H2O/OmniH2O and TWIST teach a practical lesson: a reliable humanoid controller is rarely a single training run. It is a pipeline with a teacher, a student, distillation, DAgger or RL+BC, history ablations, model export, and sim2sim verification. WholeBodyVLA keeps that engineering spirit but changes the interface for loco-manipulation. Instead of asking the VLA to emit continuous velocities, LMO receives discrete commands s_x, s_y, s_psi, and h* for meaningful primitives.
If you remember one sentence, remember this: the VLA should decide which primitive the robot needs for manipulation, while LMO RL turns that primitive into stable lower-body motion with clear start/stop behavior and robustness to upper-body disturbance.