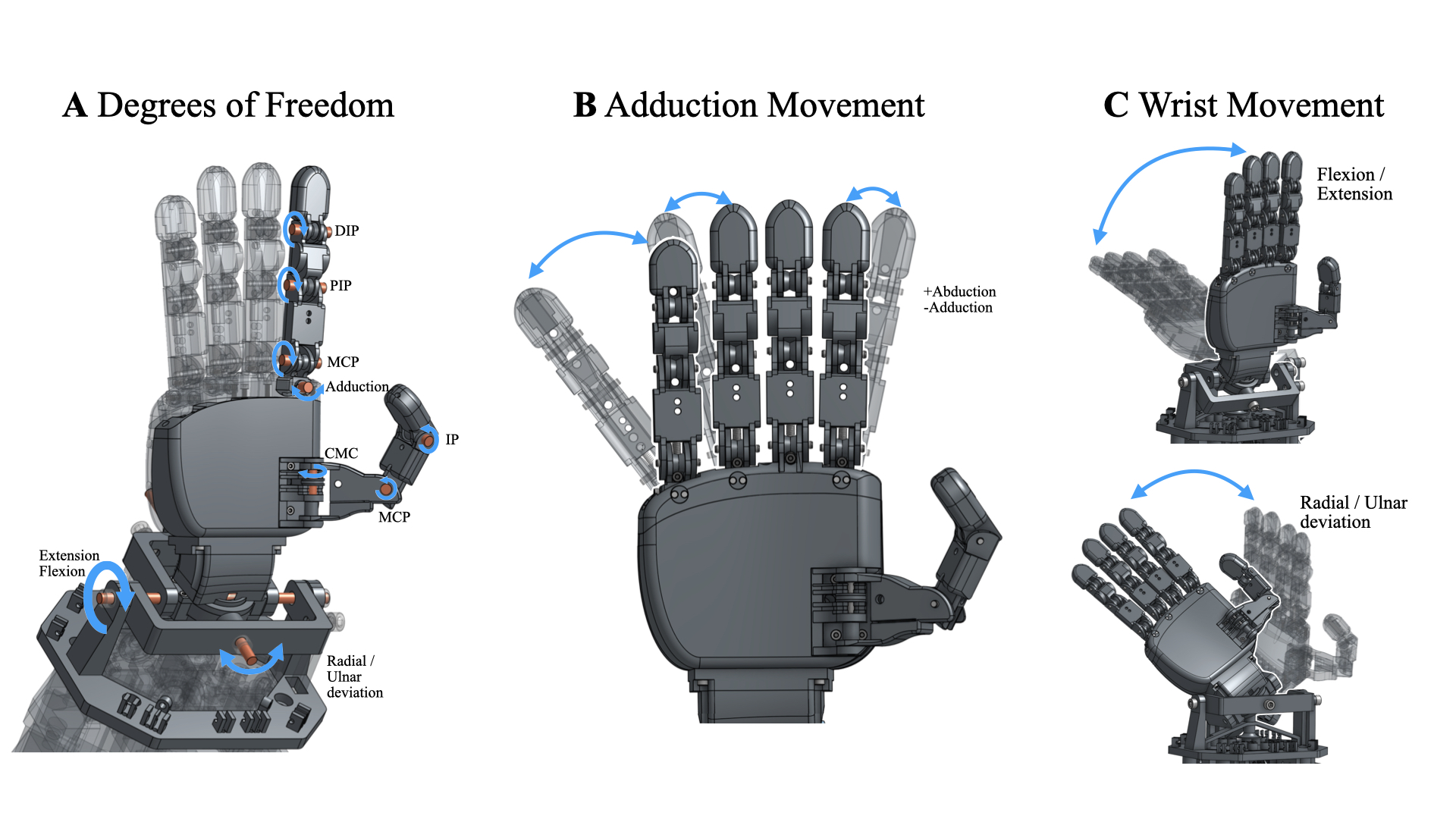
Bimanual dexterous manipulation — two arms moving in concert, ten fingers adjusting independently — remains one of the hardest unsolved problems in robotics. While the latest generation of Vision-Language-Action models (π0, GR00T N1) has proven impressive, they largely target simple parallel-jaw grippers or tasks that do not require genuine finger dexterity.
Dexora, presented at ICRA 2026, is the first open-source VLA designed from the ground up for high-DoF bimanual dexterous manipulation: two robot arms equipped with 36-DoF dexterous hands that can use a pen, peel a banana, twist off a bottle cap, or roll dough. Critically, the entire system — code, dataset, and model weights — is released to the community.
Why Is Bimanual High-DoF Manipulation So Hard?
Consider the difference between picking up a box (2-finger gripper) and twisting a bottle cap while the other hand stabilizes the bottle. The gap is not just hardware — it cascades through the entire research pipeline:
1. Extremely high-dimensional action space: Controlling two arms plus two dexterous hands simultaneously requires 36 continuous joint commands. That is nine times larger than a standard 2-DoF gripper setup.
2. Tight inter-hand coupling: The left hand's state constrains what the right hand must do at every millisecond. Static policies that treat each arm independently fail on tasks requiring coordinated force transfer.
3. Data collection is a genuine nightmare: Teaching a robot to twist a cap with its thumb requires capturing human finger motion with sub-millimeter accuracy — far beyond what a joystick or SpaceMouse can convey.
Dexora addresses all three problems with an end-to-end open-source solution.
System Architecture
The core policy is a Diffusion Transformer with:
- 28 transformer layers, hidden size 1024, 16 attention heads
- ~300M parameters (comparable to a small GR00T N1)
Observation Space
At each inference step the model receives:
- 4-view RGB cameras (stereo head + left/right wrist), each encoded with SigLIP (Google's image-text contrastive encoder)
- 36-D proprioception: current joint angles for both arms and both hands, logged at 20 Hz
- Language instruction ("use the pen to write the letter A"), encoded with T5
SigLIP is chosen over standard ViT-B/16 because its image-text pretraining yields richer visual features that generalize better across the diverse object categories in Dexora's benchmark.
Action Space
The model outputs a 36-dimensional continuous action chunk:
- Dual 6-DoF arms: 6 joint angles × 2
- Dual XHAND 12-DoF hands: 12 finger joints × 2, including the lateral ab/adduction joints of the thumb and index finger that simpler dexterous hands omit
Instead of single-step prediction, Dexora outputs multi-step action chunks (ACT-style temporal ensembling) and uses DPMSolver++ for fast DDPM denoising — reducing inference latency by ~4× compared to vanilla 100-step DDPM.
Data Collection: Exoskeleton + Vision Pro
This is Dexora's most creative contribution. Rather than a single teleoperation device, the system decouples arm control from finger control:
Arm Control: Custom Exoskeleton Backpack
Operators wear a custom-built dual-arm exoskeleton on their back and shoulders. The exoskeleton captures shoulder, elbow, and wrist angles with direct joint-space mapping — no inverse kinematics, no singularities, ultra-low latency.
Compared to SpaceMouse or 6-DoF haptic devices, the exoskeleton feels natural: operators use their own body kinematics, not an indirect control interface they must learn.
Finger Control: Apple Vision Pro
While the exoskeleton handles the arms, Apple Vision Pro handles the fingers. Vision Pro tracks markerless 3D hand skeletons at high accuracy without data gloves or physical markers.
Dexora retargets the human hand skeleton to the 12-DoF XHAND joint space with full joint-limit enforcement, ensuring the robot never hyperextends a finger.
MuJoCo Digital Twin
Every teleoperation session simultaneously drives both the physical robot and an identical MuJoCo simulation. This unlocks a key efficiency: once a task is designed in simulation, generating 100K synthetic trajectories requires no human operators at all.
Dataset: Scale and Diversity

Dexora releases two complementary datasets on Hugging Face:
Synthetic Dataset (Coming Soon)
- 100,000 episodes in MuJoCo
- 6.5 million frames, 361 hours
- 200 tasks, 297 objects auto-processed from Objaverse-XL
- Focus: basic manipulation families (pick-place, assembly, articulated objects)
Real-World Dataset (Available Now)
- 12,200 teleoperated episodes
- 2.92 million frames, 40.5 hours
- 200 tasks, 347 objects across 17 semantic categories
- 20% of tasks require genuine dexterous finger skills
Task distribution: Pick-and-place 55%, Dexterous manipulation 20%, Assembly 15%, Articulated objects 10%.
All data follows the LIBERO-2.1 standard with multi-view RGB, proprioception, action commands, and 5 natural language variants per task.
Three-Stage Training Pipeline
Dexora's most important technical contribution is its data-quality-aware training recipe:
Stage 1: Pretraining on Synthetic Data
Train the Diffusion Transformer from scratch on 100K MuJoCo trajectories (6.5M frames) for 100,000 steps on 8×A100 80GB GPUs. The synthetic stage gives the model foundational competence: how to reach objects, how to grip, and how to coordinate arm and hand motion — without any real-world data.
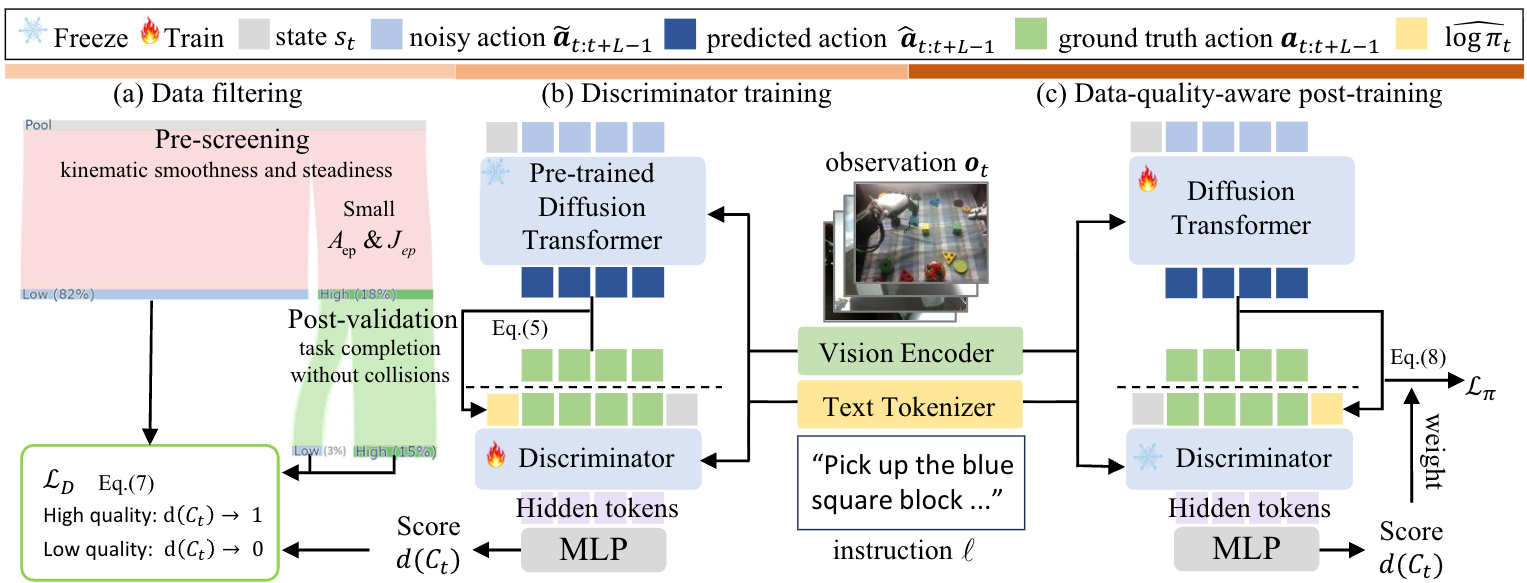
Stage 2: Training an Offline Quality Discriminator
Not all teleoperation episodes are equal. Operators get tired, make mistakes, or simply fail the task. Training naively on raw data teaches the model how to fail gracefully — not what we want.
Dexora trains an offline quality discriminator using a two-step process:
# Step 1: Kinematic smoothness pre-screening
Aep = rms(acceleration(joints_across_all_timesteps)) # 36-D
Jep = rms(jerk(joints_across_all_timesteps))
# Keep the bottom 20% on both metrics (smoothest = best)
S_pre = {τ : τ ∈ Low-20%(Aep) AND τ ∈ Low-20%(Jep)}
# ~18% of episodes pass this filter
# Step 2: Open-loop replay validation on the physical robot
# Positive set: S_pre episodes that replay successfully
# Unlabeled set: everything else
The discriminator is trained with positive-unlabeled (PU) binary cross-entropy (η = 0.5). Its inputs include state observations, language, action chunks, and a log-π proxy from the pretrained policy — enabling it to score episode quality holistically.
Stage 3: Quality-Weighted Fine-Tuning
Fine-tune the pretrained policy on 10K real episodes, but weight each episode by its discriminator score:
ℒπ = Σᵢ wᵢ · ||εθ(oᵢ, aᵢ, t) − ε||²₂
High-quality episodes → high weight → model learns more from them. Low-quality episodes → near-zero weight → minimal influence. The result: trajectory smoothness improves dramatically (jerk RMS: 0.043 → 0.032), and joint oscillations disappear.
Benchmark Results

Basic Task Suite (12 tasks)
| Model | Avg. Success |
|---|---|
| Dexora | 89.6% |
| GR00T N1 | 82.1% |
| π0 | 50.4% |
| Diffusion Policy | 34.2% |
Dexora achieves ≥90% on 7 of 12 basic tasks and outperforms GR00T N1 by ~7.5 percentage points.
Dexterous Manipulation Suite (6 tasks)
The six dexterous tasks — Use Pen, Fetch Book, Cut Leek, Place Plates, Rough Dough, and Twist Cap — require coordinated finger control that grippers simply cannot perform.

| Model | Avg. Success |
|---|---|
| Dexora | 66.7% |
| GR00T N1 | 51.7% |
| π0 | 26.7% |
| Diffusion Policy | 6.7% |
The performance gap over GR00T N1 widens from ~7.5 pp on basic tasks to +15 pp on dexterous tasks — clear evidence that Dexora's training recipe is specifically beneficial for high-DoF finger coordination.
Ablation: Does the Quality Discriminator Matter?
| Configuration | Success Rate | Jerk RMS |
|---|---|---|
| Without discriminator | 85% | 0.043 |
| With discriminator | 95% | 0.032 |
+10 pp success rate and measurably smoother trajectories — the discriminator is not optional; it is a core architectural component.
Cross-Embodiment Generalization
One of Dexora's most practical strengths is its ability to transfer to other platforms via simple action dimension projection — no retraining:
- Franka Panda (single-arm gripper): project 36D → 7D arm
- ALOHA (dual-arm gripper): project 36D → 2×6D arms
- Unitree G1 + Inspire Hand (single-arm + 12-DoF hand): project 36D → 6D arm + 12D hand
Across all three embodiments, Dexora maintains >85% of its native performance — a strong result compared to prior VLAs that required full retraining for each new robot.
For a deeper look at cross-embodiment transfer in bimanual settings, see RDT2: Zero-Shot Cross-Embodiment Bimanual.
Installation and Usage
Hardware Requirements
- Inference: 1× A100 40GB (or 2× A6000 48GB)
- Training: 8× A100 80GB for the pretraining stage
- Robot platform: Dual-arm robot with XHAND or compatible dexterous hands
Setup
# Clone the repository
git clone https://github.com/ZZongzheng0918/Dexora.git
cd Dexora
# Create conda environment
conda create -n dexora python=3.10
conda activate dexora
pip install -r requirements.txt
Downloading the Dataset
The real-world dataset (12.2K episodes) is hosted on Hugging Face:
pip install huggingface_hub
python -c "
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='Dexora/real-world-dataset',
repo_type='dataset',
local_dir='./data/real'
)
"
Each episode contains:
- Multi-view RGB frames (4 cameras, HDF5 format)
- 36-D proprioception logs at 20 Hz
- Five language annotation variants
- Ground-truth action sequences
Running Inference
from dexora import DexoraPolicy
import torch
# Load pretrained model
policy = DexoraPolicy.from_pretrained("Dexora/dexora-base")
policy.eval().cuda()
# Observation dictionary
obs = {
"images": camera_frames, # dict of 4 views, each (H, W, 3)
"proprioception": joint_angles, # (36,) float32 tensor
"language": "pick up the pen and write the letter A"
}
# Predict action chunk
with torch.no_grad():
actions = policy.predict(obs) # (T, 36) action sequence
For setting up a full VLA training pipeline from scratch, see FineVLA: Dual-Arm VLA Training Tutorial.
Comparison with Other Bimanual VLAs
| System | DoF | Open Source | Dataset | Dexterous Score |
|---|---|---|---|---|
| Dexora | 36 | ✅ Full | 12.2K real + 100K sim | 66.7% |
| GR00T N1 | Variable | ⚠️ Weights | Proprietary | 51.7% |
| π0 | Up to 52 | ✅ | ~5K | 26.7% |
| Diffusion Policy | Varies | ✅ | Task-specific | 6.7% |
Dexora's differentiation is the combination: high DoF + fully open source + large-scale dataset + SOTA results.
For the broader landscape of bimanual manipulation approaches, read Bimanual Manipulation Series.
Summary
Dexora marks a genuine milestone: the first open-source VLA with a large real-world dataset and credible benchmarks for bimanual dexterous manipulation. Three takeaways worth remembering:
- Hybrid teleoperation (exoskeleton + Vision Pro) is currently the most practical way to collect high-quality dexterous manipulation data at scale
- Quality-weighted training — not all data is equal; discriminator-guided weighting yields meaningful gains in both success rate and trajectory smoothness
- Cross-embodiment projection — a single Dexora model transfers to Franka, ALOHA, and G1+Inspire with minimal effort, demonstrating strong embodiment-agnostic representations
With dataset, weights, and code already released, Dexora is the best starting point in 2026 for anyone building or researching bimanual dexterous robotic systems.
Paper: Dexora: Open-source VLA for High-DoF Bimanual Dexterity — ICRA 2026
GitHub: github.com/ZZongzheng0918/Dexora
Project: dexoravla.github.io
Dataset: huggingface.co/Dexora