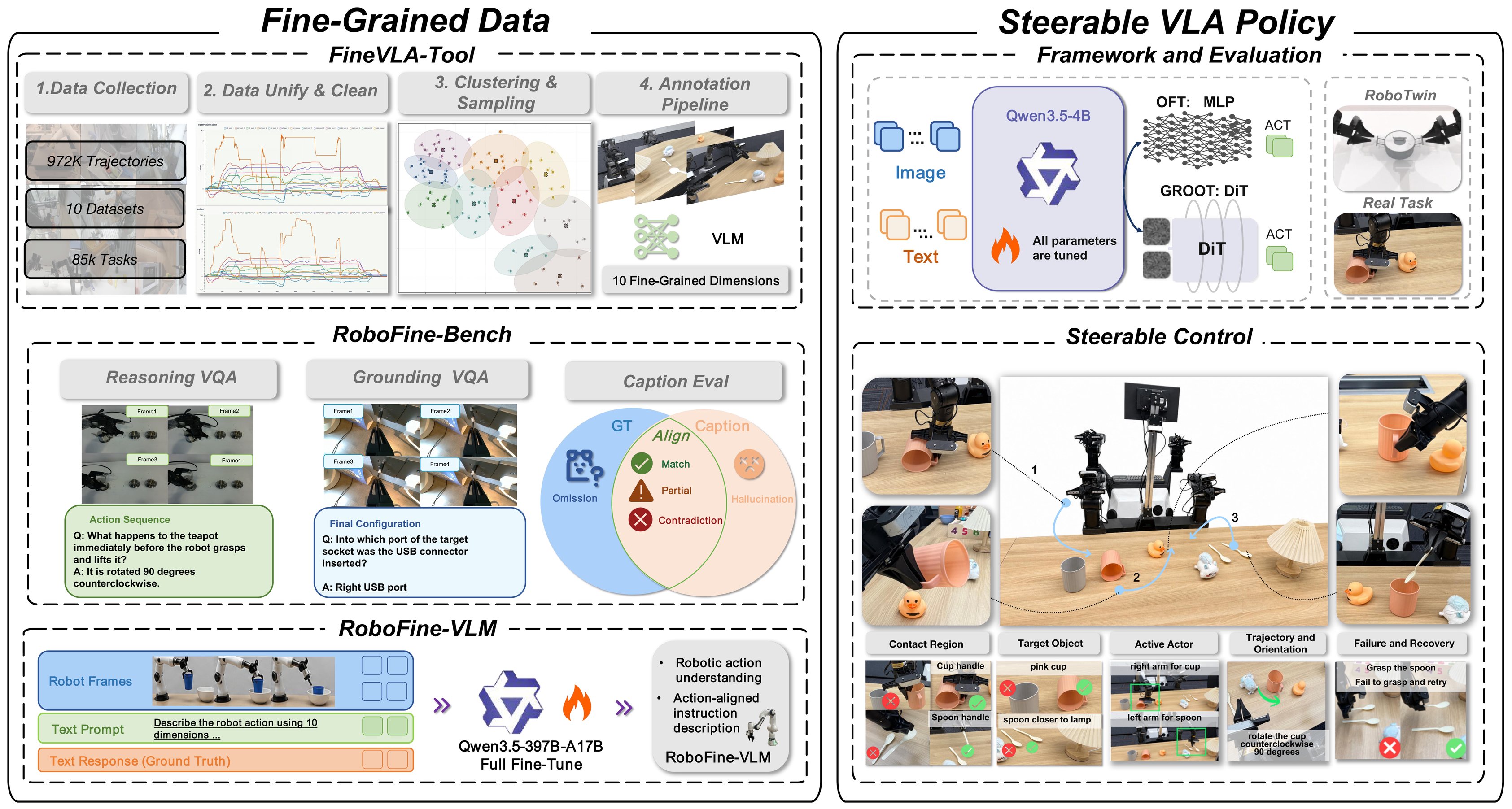
FineVLA is an open framework for fine-grained instruction alignment in Vision-Language-Action (VLA) learning. The core idea is simple but important: robot policies should not only learn what task to complete, but also how the task should be executed. A coarse instruction such as "pick up the cup" does not tell a dual-arm robot which arm to use, where to contact the object, how to approach it, how to orient the gripper, or how to recover if the object slips.
This article is a practical guide to reading and running FineVLA for dual-arm VLA work. FineVLA is not just a single model checkpoint. It is a system with FineVLA-Tool for data construction, RoboFine-Bench for fine-grained robotic video understanding, RoboFine-VLM for scalable annotation, and FineVLA-Policy for training steerable VLA policies. If you are new to VLA models, read the paper idea and smoke-test sections before attempting distributed training.
Primary sources used for this guide:
- Paper: FineVLA: Fine-Grained Instruction Alignment for Steerable Vision-Language-Action Policies
- Project page: finevla.xlang.ai
- GitHub: xlang-ai/FineVLA
- Benchmark: xlangai/RoboFine-bench
- VLM annotator: xlangai/RoboFine-VLM-397B-A17B
The problem FineVLA tackles
A VLA policy consumes visual observations, language instructions, and sometimes robot state, then outputs robot actions. In many open robotics datasets, each trajectory is paired with a short goal-level instruction:
"Pick up the red block."
That may be enough for a basic single-arm task. It is not enough for many dual-arm tasks. Consider the difference between these two labels:
Coarse instruction:
"Pick up the cup."
Fine-grained instruction:
"Use the right arm to approach the cup from the front-right side,
close the gripper around the upper body of the cup, lift vertically
until it clears the table, then keep the cup upright while moving it
to the target area."
Both labels describe the same high-level task, but they provide very different learning signals. The first says what to do. The second says what to do and how to do it. In dual-arm manipulation, the "how" often determines whether the behavior is usable: active arm, approach direction, contact region, trajectory shape, orientation, object relationship, and recovery behavior.
FineVLA asks a clean research question: if the trajectory, visual observation, state, and action labels stay the same, but the language label becomes more action-aligned, does the policy become more steerable? The answer in the paper is yes, with an important nuance. The best results usually come from mixing fine-grained instructions with raw goal-level instructions, not from replacing all raw language with long process descriptions.
The FineVLA system
FineVLA has four main pieces:
Raw robot datasets
BridgeData-V2, BC-Z, RT-1, Galaxea, RoboMIND, RoboCOIN, RH20T, RDT, DROID
|
v
FineVLA-Tool
1. Convert to a unified format
2. Canonicalize state and action
3. Cluster trajectories with DTW
4. Annotate 10 fine-grained dimensions
|
v
FineVLA-Data
47,159 human-verified fine-grained trajectories
|
+--> RoboFine-Bench
| 500 videos, 10,816 atomic facts, 1,030 VQA questions
|
+--> RoboFine-VLM
| Qwen3.5-397B-A17B fine-tuned as a robotic video annotator
|
+--> FineVLA-Policy
StarVLA-OFT / StarVLA-GR00T policies
trained with Raw, FG, or mixed instructions
This design matters because FineVLA is not mainly an architecture paper. The authors deliberately instantiate FineVLA-Policy with existing StarVLA-style action decoders to isolate the role of instruction supervision. The experiment is not "we invented a new action head." The stronger claim is "with the same actions and visual data, richer language changes what the policy learns."
The ten fine-grained dimensions
FineVLA-Tool annotates each selected trajectory with ten control-relevant dimensions. For a beginner, treat these dimensions as a checklist for writing useful robot instructions.
| Dimension | What it captures in dual-arm robotics | Example |
|---|---|---|
| Action Sequence | Ordered manipulation steps | reach, grasp, lift, move, place |
| Active Actor | Which arm or end-effector acts | left arm, right arm, both arms |
| Target Object | Object disambiguation | red block on the left |
| Initial Configuration | Starting scene state | cup upright near the tray |
| Final Configuration | Desired end state | cup placed upright on target |
| Contact & Approach | Where and how contact happens | grasp upper side, approach from front |
| Trajectory & Orientation | Motion path and tool orientation | lift vertically, rotate clockwise |
| Body Motion | Whole-body or joint-level motion | keep torso fixed, move wrist only |
| Object Interaction | Relationships between objects | stack block on top of another |
| Failure & Recovery | Error handling behavior | re-grasp if slipping |
The practical lesson is direct: if your policy often completes the task but violates execution preferences, your language may be too coarse. A dual-arm policy cannot reliably infer "use the left arm" or "approach from the side" from a label that only says "pick up the object."
FineVLA-Policy architecture
FineVLA-Policy currently uses a modular StarVLA codebase. In the paper, the main policy experiments use two action-decoding designs:
| Framework | Backbone | Action head | Idea |
|---|---|---|---|
| StarVLA-OFT | Qwen3.5-VL-4B | MLP regression | Reads hidden states at action tokens and predicts continuous action chunks |
| StarVLA-GR00T | Qwen3.5-VL-4B | DiT + flow matching | Uses the VLM as a slow reasoning system and a DiT module for continuous action generation |
The data path looks like this:
Camera frames + language instruction
|
v
Qwen3.5-VL-4B backbone
|
+-----------------------------+
| |
v v
StarVLA-OFT StarVLA-GR00T
MLP action regression DiT flow-matching action generator
| |
v v
continuous action chunk continuous action chunk
The dual-arm part is mostly encoded in the dataset and action representation. The paper uses AlohaMix, an ALOHA-compatible dual-arm mixture built from sources such as RDT, RoboCOIN, and RoboMIND. AlohaMix contains 86,662 episodes across 598 tasks, which gives the policy enough variation to test whether detailed language can steer different manipulation strategies on a consistent dual-arm embodiment.
Install FineVLA-Policy
You need Linux, Python 3.10, a compatible PyTorch/CUDA stack, and NVIDIA GPUs. FineVLA-Policy uses Accelerate and DeepSpeed for distributed training. For a first run, your goal should be simple: install dependencies, load the backbone, and pass the smoke test.
git clone https://github.com/xlang-ai/FineVLA.git
cd FineVLA/FineVLA-Policy
conda create -n finevla python=3.10 -y
conda activate finevla
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
pip install -e .
Check CUDA and package versions:
nvcc -V
pip list | grep -E 'torch|transformers|flash-attn|accelerate|deepspeed'
The official README notes that flash-attn==2.7.4.post1 works with CUDA 12.0 and 12.4. If FlashAttention fails to build, the common cause is a PyTorch/CUDA mismatch. Install the correct PyTorch build first, then install FlashAttention.
Download the Qwen3.5-VL-4B-Instruct backbone and place it where the example script expects it:
mkdir -p playground/Pretrained_models
# Download Qwen/Qwen3.5-VL-4B-Instruct from Hugging Face.
# Place the checkpoint at:
# ./playground/Pretrained_models/Qwen3.5-VL-4B-Instruct
Run the smoke test:
python starVLA/model/framework/QwenGR00T.py
If the model builds and prints its architecture, the policy code path is working. If you hit GPU memory errors later, reduce batch size, use fewer camera views, shorten action chunks, or move to larger GPUs.
Prepare data
FineVLA-Tool reads the dataset root from VLA_DATA_ROOT. The tool converts heterogeneous robot demonstrations into a unified format, canonicalizes state/action representation, clusters trajectories, and then annotates representative episodes.
cd FineVLA/FineVLA-Tool
export VLA_DATA_ROOT="/path/to/your/Lerobot_v21"
The data pipeline has four stages:
CanonicalizeAndClean
- convert source datasets into a LeRobot-style format
- canonicalize absolute coordinates and quaternion rotations
- filter invalid videos, empty tasks, and corrupted trajectories
ClusteringAndSampling
- compute trajectory similarity with dynamic time warping
- cluster trajectories within each task
- select representative episodes for annotation
AnnotationPipeline
- use VLMs to describe each manipulation step
- fill slots such as actor, target, contact, trajectory, and state change
RealANNO-Guidance
- human annotators review video-grounded descriptions
- factual and temporal alignment errors are corrected
You do not need to reconstruct the entire FineVLA-Data corpus to learn the training workflow. Start with released assets and example scripts. For your own robot, the best first milestone is to convert logs into a clean LeRobot-style dataset. This makes it easier to reuse dataloaders and visualization tools from the broader robot learning ecosystem.
Train FineVLA-Policy
FineVLA-Policy uses Accelerate and DeepSpeed. The general launch pattern is:
cd FineVLA/FineVLA-Policy
accelerate launch \
--config_file starVLA/config/deepseeds/deepspeed_zero2.yaml \
--num_processes 8 \
starVLA/training/train_starvla.py \
--config_yaml ./starVLA/config/training/your_config.yaml
The repo provides benchmark-specific scripts:
examples/Aloha/ ALOHA dual-arm tasks and FG:Raw mixing ratios
examples/Robotwin/ RoboTwin simulation benchmark
examples/LIBERO/ LIBERO benchmark
examples/Robocasa_tabletop/
examples/SimplerEnv/
Example: train the GR00T-style ALOHA setup with FG:Raw = 1:1.
bash examples/Aloha/run_qwen35_GR00T_aloha_multi_FG1_1_dlc.sh
The FG:Raw ratio controls how often a sampled trajectory is paired with a fine-grained instruction versus the original raw goal-level instruction.
| Setting | Instruction sampling | When to use |
|---|---|---|
| Raw-only | Only original goal-level instructions | Baseline |
| FG-only | Only fine-grained process instructions | Tests whether detailed "how" language helps |
| FG:Raw = 1:4 | 20% FG, 80% Raw | Conservative fine-tuning |
| FG:Raw = 1:2 | About 33% FG, 67% Raw | Strong setting in the paper |
| FG:Raw = 1:1 | 50% FG, 50% Raw | Best average real-world result in the paper |
| FG:Raw = 2:1 or 4:1 | Mostly FG | Useful for ablations, but can overemphasize long descriptions |
The important detail is that FineVLA keeps the same trajectories, actions, and visual observations while varying the paired language. This isolates the effect of action-aligned supervision from data scale or embodiment changes.
Inference and evaluation
As of this article date, the official GitHub README says pretrained and fine-tuned policy checkpoints are still "coming soon", while code, FineVLA-Tool, RoboFine-Bench, and RoboFine-VLM are released. That means you have two practical paths:
- Train a policy with the example scripts and evaluate your own checkpoint.
- When official policy checkpoints appear on Hugging Face, replace the model path in the eval config with the released checkpoint.
For LIBERO, the quick start is a policy server plus evaluator:
cd FineVLA/FineVLA-Policy
bash examples/LIBERO/eval_files/run_policy_server.sh &
bash examples/LIBERO/eval_files/eval_libero.sh
For a custom dual-arm robot, the inference loop conceptually looks like this:
observation = {
"images": {
"cam_high": high_rgb,
"cam_left_wrist": left_wrist_rgb,
"cam_right_wrist": right_wrist_rgb,
},
"state": robot_state,
}
instruction = (
"Use the right arm to grasp the red block from its right side, "
"lift it vertically, then place it on top of the blue block."
)
action_chunk = policy.predict_action(observation, instruction)
robot.execute(action_chunk)
You still need an embodiment-specific execution layer. Map the predicted action chunk to joint commands, end-effector deltas, gripper commands, or the ALOHA-style action format used by your controller. Fine-grained language does not replace calibration, camera extrinsics, time synchronization, action scaling, workspace limits, collision checks, or emergency stop logic.
Run RoboFine-Bench
RoboFine-Bench evaluates whether a VLM understands manipulation videos at the execution-detail level. It does not control the robot directly, but it is useful for testing annotators and video-language models before using them to generate training labels.
cd FineVLA/RoboFine-Bench
git lfs install
git clone https://huggingface.co/datasets/xlangai/RoboFine-bench EvalData/
pip install openai httpx tqdm pydantic Pillow av
export OPENAI_API_KEY="your-api-key"
Run VQA evaluation:
python RoboFine-Bench/vqa_eval/run_vqa.py \
--model qwen3-vl-plus \
--qa EvalData/QAEvalSets.json \
--input EvalData/EvalSets.json \
--num-workers 16
Run caption generation in hard mode, where the model does not receive the task instruction:
python RoboFine-Bench/caption_eval/annotate/run_annotate.py \
--model qwen3.5-plus \
--evalsets EvalData/EvalSets.json \
--frame-index EvalData/frame_index.jsonl \
--output-dir results/CaptionResult/hard/ \
--num-workers 16 \
--no-instruction
Score captions with Direct Alignment:
python -m caption_eval.atomic_eval.atomic_eval direct-align \
--gt-facts EvalData/GT_AtomicFacts.jsonl \
--caption results/CaptionResult/qwen3_5-plus_CaptionResult.jsonl \
--output-dir results/AtomicResult/qwen3_5-plus/ \
--num-workers 8 \
--enable-thinking
The benchmark reports these core metrics:
| Metric | What it measures |
|---|---|
| Consistency | Whether the caption matches the facts it claims |
| Coverage | Whether the caption covers the ground-truth facts |
| Anti-Hallucination | Whether the caption avoids invented actions |
| CaptionScore | Average of the three metric groups |
Results to remember
FineVLA-Data starts from 972,247 raw trajectories across 85K tasks and produces 47,159 human-verified fine-grained trajectories. The average instruction length grows from 9.3 words to 96.8 words, roughly a 10.4x increase.
On RoboTwin simulation, the strongest mixed settings reach:
| Setting | Raw-only | Best mixed |
|---|---|---|
| RDT-OFT Easy/Hard | 61.5 / 60.0 | 74.1 / 72.4 |
| RDT-GR00T Easy/Hard | 55.1 / 53.4 | 69.4 / 68.2 |
| AlohaMix-OFT Easy/Hard | 71.8 / 71.4 | 86.8 / 82.5 |
In real-world dual-arm manipulation, Raw-only reaches 49.9/100 average ID score, while FG:Raw = 1:1 reaches 62.7/100. The project page also reports instruction violations dropping from 34% to 12% for the best mixed setting. The largest gains appear in pose, color, and approach direction, which are exactly the factors that short goal-level instructions fail to specify.
RoboFine-VLM is another important result. It is fine-tuned from Qwen3.5-397B-A17B on FineVLA-Data and reaches 71.0% VQA accuracy and around 83.6% captioning score in the hard setting reported by the paper/project page. The training cost is large: the appendix reports RoboFine-VLM SFT on 256 H200 GPUs for about 40 hours. Most labs should use the released annotator, review a subset manually, and spend their compute budget on policy fine-tuning rather than reproducing the full annotator training run.
A small-lab implementation checklist
If you have a dual-arm robot, do not start with a 64-A100 pretraining run. Start with a narrow, verifiable loop:
1. Standardize robot logs
camera timestamps, action/state format, gripper state, episode metadata
2. Convert to a LeRobot-style dataset
the closer you are to FineVLA/LeRobot conventions, the easier reuse becomes
3. Write raw task instructions
example: "stack the red block on the blue block"
4. Annotate 50-200 episodes with fine-grained instructions
prioritize active actor, target object, contact, approach, and final configuration
5. Fine-tune a small policy or adapter first
validate the data path before scaling training
6. Compare Raw-only, FG-only, FG:Raw = 1:2, and FG:Raw = 1:1
keep trajectories and actions fixed to isolate the language effect
7. Deploy behind a safety wrapper
action clipping, workspace limits, emergency stop, gripper force limits
FineVLA is most valuable when the same task can be executed in multiple valid ways. If all episodes are nearly identical, long instructions will add less. If your tasks vary by arm choice, approach direction, object pose, contact region, tool orientation, or recovery behavior, fine-grained instruction alignment gives the policy a clearer way to bind language to behavior.