What EXPO-FT Solves
EXPO-FT is an online reinforcement learning fine-tuning system for Vision-Language-Action models, introduced by Perry Dong, Kuo-Han Hung, Tian Gao, Dorsa Sadigh, and Chelsea Finn in EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models. The headline result is unusually strong for real-robot learning: across 8 real-world manipulation tasks, EXPO-FT reaches 30/30 successes on every task with an average of 19.1 minutes of online robot data. The implementation is open source at pd-perry/expo-ft, and the project page with rollout videos and visualizations is available at pd-perry.github.io/expo-ft.
The problem is practical reliability. A pretrained VLA such as π0.5 can already look at camera observations, read a language instruction, and output robot action chunks. That is a powerful prior, but "works sometimes" is not enough for deployment. A policy that succeeds 70% of the time may look impressive in a demo, yet it still fails too often for a production cell, warehouse workflow, or service robot. Supervised fine-tuning on more demonstrations can help, but it mostly teaches the model to imitate the demonstrations it saw. Training reinforcement learning from scratch can optimize the real reward, but it spends expensive real-robot interaction and ignores the semantic prior already encoded in the VLA.
EXPO-FT combines the two worlds:
Pretrained π0.5
↓
Small teleoperated task demonstrations
↓
SFT until the policy has a usable starting success rate
↓
Online RL on the real robot
↓
Edit policy + Q-guided action chunk selection + human interventions
↓
Reliable policy: 30/30 evaluation trials
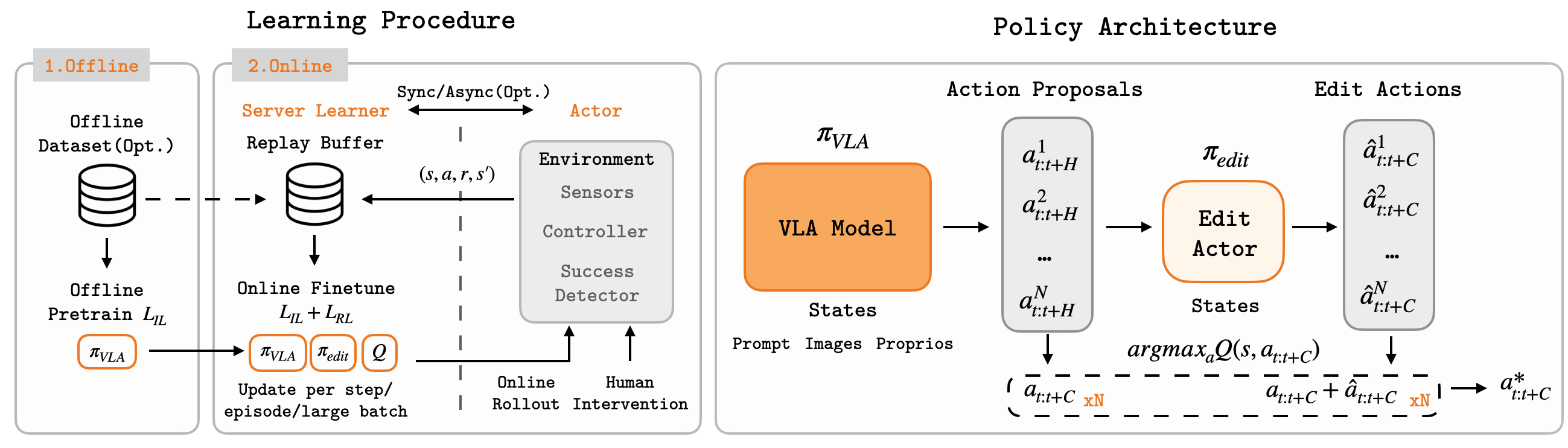
The core idea is not to blindly run standard RL through the entire VLA at every control step. EXPO-FT treats π0.5 as a base policy, trains a small edit policy to produce residual corrections over action chunks, learns a Q-function to rank candidate chunks, and continues fine-tuning the base VLA with its original supervised objective. This preserves the pretrained behavior while allowing task reward to fix the small but critical errors that decide success or failure.
Why RL on VLA Models Is Hard
Modern VLAs are not simple Gaussian policies. π0 and π0.5 use flow/action-chunk style generation: the policy predicts a short sequence of future robot actions, not just a single action. That is useful for robots because manipulation requires smooth temporal structure. A command like "insert the flower into the bottle" is not one motor command; it is a sequence of approach, alignment, contact, and insertion motions.
For RL, this creates three issues. First, many policy-gradient algorithms assume tractable action log probabilities. Diffusion or flow policies do not always provide those log probabilities cheaply in a tight online loop. Second, action chunks create a higher-dimensional decision. If the robot executes 8 steps before replanning, then the selected object is a small trajectory, not a scalar control. Third, real robots impose latency and safety constraints. Every rollout takes wall-clock time, may require a reset, and may create hardware risk if the policy explores too aggressively.
EXPO-FT builds on the earlier EXPO algorithm, which was designed for expressive diffusion or flow policies. The paper extends it to temporally extended actions and adds human-in-the-loop interventions. This guide explains the system as a practical workflow: what to install, what data to collect, how to run SFT, how to run online RL, and how to interpret the reported results.
System Architecture
The open-source repo separates the system into two processes:
GPU server / learner
- train_pi_robo.py
- train_pi_robo_async.py
- eval_droid_policy.py
- π0.5 wrapper through a modified OpenPI fork
- replay buffer, critic, edit actor, checkpointing
↑ WebSocket
↓
Robot client / actor
- client/run_client.py
- DROID real-robot environment
- side-view camera + wrist camera
- SpaceMouse intervention
- task success detector
This split is not cosmetic. The learner needs GPUs for π0.5 inference, Q-learning, and model updates. The actor needs to be close to the robot stack, cameras, DROID SDK, and teleoperation device. The two sides communicate through WebSocket. If the robot laptop and GPU machine are separate, the README recommends an SSH reverse tunnel so that the learner can reach the client through localhost:8102.
At the model level, EXPO-FT has four main pieces:
| Component | Role | Why it matters |
|---|---|---|
| Base VLA π0.5 | Generates action chunks from images, state, and language | Provides the pretrained semantic and manipulation prior |
| Edit policy | Predicts residual corrections for action chunks | Improves behavior without replacing the VLA |
| Q ensemble | Estimates the value of candidate chunks | Chooses the most promising action chunk |
| Replay buffer | Stores demos, rollouts, and interventions | Enables sample-efficient off-policy RL |
The paper appendix gives useful implementation details. EXPO-FT uses a RedQ-style ensemble of 10 Q-networks. For target computation, it samples 2 networks and takes the minimum to reduce overestimation. At each decision point, the base VLA samples 8 stochastic short-horizon action chunks. The edit policy creates 8 edited chunks. The system evaluates all 16 candidates and executes the chunk with the highest Q-value. The critic uses a lightweight ResNet-50 visual backbone instead of reusing the large VLA encoder, because the online actor-learner loop is latency-sensitive.
The action path looks like this:
Observation:
side RGB 224x224
wrist RGB 224x224
robot proprioception
language instruction
π0.5 base policy
├─ sample 8 base action chunks
└─ each chunk contains several low-level actions
Edit actor
└─ add bounded residual edits to chunks
Candidate set
├─ 8 base chunks
└─ 8 edited chunks
Q ensemble
└─ select the highest-value chunk
Robot
└─ execute 4 or 8 steps, then replan
This design is important. The edit policy does not need to rediscover the whole skill. It only needs to learn corrections such as moving a few centimeters lower, rotating the gripper slightly before insertion, applying a stronger pool strike, or reducing scoop depth. In high-precision manipulation, these small residuals are often the difference between a near miss and a clean success.
Understanding the 19.1-Minute Claim
The 19.1-minute number refers to online robot data during the RL phase. It does not mean the system starts from an empty robot policy with no demonstrations. In the paper setup, if the pretrained VLA is not good enough zero-shot, the researchers collect a small teleoperated demonstration set, supervised fine-tune π0.5, and then run online RL. The appendix mentions different demonstration counts for different tasks: for example, Candy Scoop and Cube Pick use 10 pre-collected demonstrations, Flower Insert uses 25, and Pool Shot uses 30.
A beginner-friendly pipeline is:
- Test π0.5 zero-shot or with your available checkpoint.
- If the policy is too weak, collect successful teleoperated demonstrations.
- Convert those demonstrations into LeRobot format.
- Compute normalization statistics for your robot and action space.
- Supervised fine-tune π0.5 for the task.
- Run EXPO-FT online with human interventions enabled.
- Evaluate with enough randomized trials to measure reliability.
The reward used in the paper is mostly a sparse binary task-completion reward: success gives 1, otherwise 0. The authors avoid dense reward engineering by writing rule-based success detectors for each task. For Candy Scoop, the detector checks whether candies are in the spoon above a height threshold and whether the candy count changes in the target container region. For Pool Shot, success requires the black ball to reach a pocket, the white cue ball to avoid the pocket, and the cue stick not to directly contact the black ball. The paper reports detector accuracy above 95%, and final evaluation success is judged by a human observer.
Installing EXPO-FT
The repo uses two independent Python environments. This is the first detail that new users should not skip.
# Requires Python 3.11+ and uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# Main repo plus the two required forks
git clone https://github.com/pd-perry/expo-ft.git
cd expo-ft
git clone -b expo_ft https://github.com/pd-perry/openpi.git expo_ft/agents/vla/openpi
git clone https://github.com/pd-perry/droid.git client/droid
Install the server environment at the repo root:
# Server / learner
uv sync
Install the client environment under client/:
# Client / actor
cd client
uv sync
cd ..
# Optional, only if you use ZED cameras
bash client/install_pyzed.sh
Before running the robot, configure hardware-specific values. In the DROID fork, update client/droid/droid/misc/parameters.py for values such as nuc_ip. In your task config, for example configs/task/real_base.py or configs/task/pick.py, set side_camera_id, wrist_camera_id, reset joints, workspace bounds, and the language instruction. On the NUC controlling the robot, the DROID setup must have the correct robot_type, robot_serial_number, robot_ip, and Polymetis/hardware configuration.
For a first pass, use the included pick task. The README states that only scripts/pick/ is fully wired as a complete working example. For a new task, copy that script directory and update dataset paths, task config, checkpoint paths, and OpenPI asset IDs.
Creating a New Task
A minimal EXPO-FT task has three pieces:
client/envs/droid_env.py
- reset()
- step(action)
- observation with images + proprioception
- detect() calls the success detector
configs/task/my_task.py
- language instruction
- camera ids
- action bounds
- reset pose
- episode horizon
client/real_utils/detector.py
- rule-based or learned binary success detector
For a cable insertion task, the detector might use connector pose, LED state, or color thresholds in a target region. For a cube pick task, it might use gripper height and object visibility. For a scoop task, it may require more visual logic. Do not start by designing a complicated dense reward unless the binary detector is already reliable. A sparse success detector is easier to debug because it forces a precise definition of completion.
Use this checklist before collecting data:
| Item | Question |
|---|---|
| Cameras | Do side and wrist views cover the whole manipulation region? |
| Action scale | Are Cartesian velocities safe and expressive enough? |
| Reset | Can the robot return to a safe start state after every episode? |
| Detector | Does the success detector avoid false positives? |
| Intervention | Does SpaceMouse override the policy smoothly? |
| Network | Can the learner reach the client port? |
Collecting Demonstrations and Converting Data
Start the DROID server on the NUC:
# On the NUC
python scripts/server/run_server.py
Collect demonstrations on the robot client:
# On the client / robot machine
bash scripts/${TASK_NAME}/collect_data.sh
The parameters to update are:
--save_root # output directory for raw episodes
--num_episodes # number of demonstrations to collect
--task_config # task config for this robot environment
After collecting successful demonstrations, convert them into LeRobot format on the server/GPU machine:
bash scripts/${TASK_NAME}/convert_data.sh
Update MAX_EPISODES, TASK_CONFIG, DATA_DIR, and REPO_NAME. If the robot client and GPU server do not share the same filesystem, copy or sync the data to the server before conversion, normalization, SFT, RL training, and evaluation. Many real training failures come from mismatched dataset paths between the robot laptop and the GPU machine.
Supervised Fine-Tuning π0.5 Before RL
Before EXPO-FT, run supervised fine-tuning. The repo wraps OpenPI scripts from the modified fork:
# Compute normalization stats once for a new task
bash scripts/${TASK_NAME}/calculate_norm.sh
# Fine-tune π0.5 with task demonstrations
bash scripts/${TASK_NAME}/finetune_droid.sh
The included pick example runs around 4001 training steps and saves every 2000 steps:
uv run expo_ft/agents/vla/openpi/scripts/train.py \
expo_pi05_droid_lora_finetune_sft_cartesian_state \
--exp-name="${DATA_ID}_lora_sft" \
--resume \
--data.repo_id="$REPO_ID" \
--data.assets.assets_dir="$ASSETS_DIR" \
--data.assets.asset_id="$ASSET_ID" \
--num_train_steps=4001 \
--save_interval=2000 \
--fsdp_devices=1
The goal of SFT is not necessarily perfection. The paper describes using demonstrations when zero-shot performance is not sufficient and fine-tuning until the policy reaches a usable starting success rate, roughly 40% or above. Think of SFT as producing a safe, meaningful initial policy. Online RL then optimizes task reliability.
Running EXPO-FT Online
Start the DROID server on the NUC:
python scripts/server/run_server.py
Start the rollout client:
bash scripts/${TASK_NAME}/run_policy.sh
If the learner and client are on different machines, set up the reverse tunnel:
bash scripts/set_server.sh <server-hostname> 8102 <your-username>
Then start the learner on the GPU server:
# Synchronous
bash scripts/${TASK_NAME}/run_server.sh
# Asynchronous, requires at least 2 GPUs
bash scripts/${TASK_NAME}/run_server_async.sh
The pick example exposes the key training parameters:
python train_pi_robo.py \
--config_task=configs/task/pick.py \
--dataset_path=./data/pick_cube_balance/success \
--num_data=10 \
--update_type=episode \
--num_updates=3 \
--offline_ratio=0 \
--config=configs/model/expo_ft_pi_config.py \
--config.N=8 \
--config.n_edit_samples=8 \
--config.edit_scale=0.2 \
--config.pi05_weight_loader_path="./checkpoints/.../params" \
--config.pi05_assets_dir="./assets/expo_pi05_droid_lora_finetune_sft_cartesian_state" \
--config.pi05_asset_id="expo_ft/droid_pick_cube_10" \
--client_host=localhost \
--client_port=8102 \
--checkpoint_model \
--checkpoint_buffer
N=8 samples 8 base chunks. n_edit_samples=8 adds 8 edited chunks. edit_scale=0.2 is a recommended starting value from the README, although precise tasks may need smaller edits. update_type=episode updates after each episode, which is often easier to operate safely on real robots. Per-step updates can be more sample-efficient if the compute and safety loop are robust.
Human-in-the-loop intervention works as follows: an operator watches the robot, and when the policy enters a failure-prone state, the operator overrides actions through the SpaceMouse. The corrected action steps are stored in the replay buffer. In the paper, intervention rates are higher early in training and fall toward zero as the policy improves. If the intervention rate remains high, check the reward detector, action scale, SFT checkpoint, and initial-state randomization range.
Inference and Evaluation
After training, evaluate with the same DROID server and rollout client:
bash scripts/${TASK_NAME}/eval_policy.sh
Evaluation parameters must match training: task config, checkpoint, normalization assets, edit_scale, replan interval, and camera setup. The paper evaluates each task on 30 trials, with randomized initial states from scripted motions or human resets, and human confirmation of success. This is a good habit to copy. Do not report only one good video; report trial count, randomization range, online minutes, and remaining failure modes.
A useful evaluation log looks like:
Task: cable insertion
Base π0.5 zero-shot: 6/30
SFT after 20 demos: 14/30
EXPO-FT online data: 22 minutes
Final eval: 29/30
Intervention rate: 35% early → 0% final
Main failure: connector yaw > 20 degrees
Paper Results
EXPO-FT is evaluated on 8 real-world manipulation tasks: Egg Flip, String Light Routing Route I, Route II, Insert, Candy Scoop, Cube Pick, Flower Insert, and Pool Shot. These tasks cover contact-rich manipulation, precision insertion, flexible object handling, dynamic striking, and large scene randomization.
| Task | Online data | SFT | HG-DAgger | EXPO-FT |
|---|---|---|---|---|
| Egg Flip | 18 min | 16/30 | 18/30 | 30/30 |
| String Light Route I | 18 min | 23/30 | 18/30 | 30/30 |
| String Light Route II | 35 min | 21/30 | 25/30 | 30/30 |
| String Light Insert | 16 min | 23/30 | 24/30 | 30/30 |
| Candy Scoop | 20 min | 22/30 | 28/30 | 30/30 |
| Cube Pick | 14 min | 22/30 | 26/30 | 30/30 |
| Flower Insert | 14 min | 14/30 | 24/30 | 30/30 |
| Pool Shot | 18 min | 23/30 | 14/30 | 30/30 |
| Average | 19.1 min | 20.5/30 | 22.1/30 | 30/30 |
On a 4-task subset, the paper also compares against DSRL and HIL-SERL. EXPO-FT reaches a 30/30 average, while DSRL averages about 19/30 and standard-budget HIL-SERL averages about 5.5/30. HIL-SERL is strong for training smaller policies from scratch in suitable settings, but it lacks the broad visual and semantic prior of a VLA. DSRL starts from a pretrained policy, but its optimization is constrained by modes already represented in the prior. EXPO-FT combines both advantages: VLA initialization plus reward-driven online improvement with human corrections.
When Should You Use EXPO-FT?
EXPO-FT is a good fit when you already have a working real-robot stack, cameras, teleoperation, a manipulation task with a clear success condition, and a need to increase reliability from "pretty good" to deployment-level. It is not the first thing to use if your robot calibration, camera streams, action bounds, or reset procedure are still unstable.
Use it when:
| Situation | Why EXPO-FT fits |
|---|---|
| SFT reaches 40-80% but fails edge cases | RL optimizes task success directly |
| The task needs precision, contact, or timing | Q-guided residual edits can refine actions |
| Demonstrations are expensive | Off-policy replay improves sample efficiency |
| A human operator can intervene safely | Interventions reduce useless exploration |
Be cautious when:
| Situation | Risk |
|---|---|
| The reward detector has false positives | The policy may learn to exploit the detector |
| Camera views are unstable | The critic and VLA receive noisy observations |
| Manual reset is very slow | 19 minutes of online data can still take hours wall-clock |
| Action bounds are unsafe | RL corrections may become risky |
Takeaway
EXPO-FT matters because it turns a generalist VLA into a policy that can be post-trained for high reliability on a real robot. The recipe is clear: supervised fine-tune π0.5 with a small task dataset, run online off-policy RL with residual edits, use a Q ensemble to select action chunks, allow timely human interventions, and evaluate with a serious trial protocol.
The most important lesson is not only the 19.1-minute number. It is the combination of three signals: the broad prior of π0.5, the real task reward, and human correction at the moments where exploration would otherwise be wasteful. For robotics, this is a pragmatic direction: keep the foundation model, avoid relying only on imitation, and do not force the robot to learn everything from scratch.
Sources
- Paper: EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models
- Project page: pd-perry.github.io/expo-ft
- Code: github.com/pd-perry/expo-ft