EXPO-FT giải quyết vấn đề gì?
EXPO-FT là hệ thống fine-tuning bằng online reinforcement learning cho Vision-Language-Action model, được Perry Dong, Kuo-Han Hung, Tian Gao, Dorsa Sadigh và Chelsea Finn công bố trong paper EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models. Điểm gây chú ý là kết quả: trên 8 task manipulation thật, hệ thống đạt 30/30 success cho mọi task, với trung bình 19.1 phút online robot data. Code được mở tại repo pd-perry/expo-ft, project page có video rollout và visualization tại pd-perry.github.io/expo-ft.
Vấn đề thực tế phía sau con số này rất quen thuộc. VLA như π0.5 có prior rất mạnh: nhìn ảnh, đọc instruction, sinh action chunk cho robot. Nhưng "làm được vài lần" chưa đủ cho deployment. Một robot trong lab có thể thành công 60-80%, nhưng nhà máy, kho hàng hoặc hệ thống dịch vụ cần mức tin cậy gần 95-99% tùy task. Nếu chỉ thu thêm demonstration rồi supervised fine-tuning, model thường học tốt các tình huống giống demo, nhưng vẫn dễ lỗi khi object lệch vị trí, contact hơi khác, hoặc thao tác cần force/timing chính xác. Nếu train RL từ đầu, policy có thể học reward, nhưng mất nhiều data robot thật và không tận dụng được prior ngữ nghĩa của VLA.
EXPO-FT nằm ở giữa hai hướng đó:
Pretrained π0.5
↓
Task demos nhỏ bằng teleoperation
↓
SFT để policy đạt mức khởi động khoảng 40%+
↓
Online RL trên robot thật
↓
Edit policy + Q-guided sampling + human interventions
↓
Reliable policy: 30/30 evaluation trials
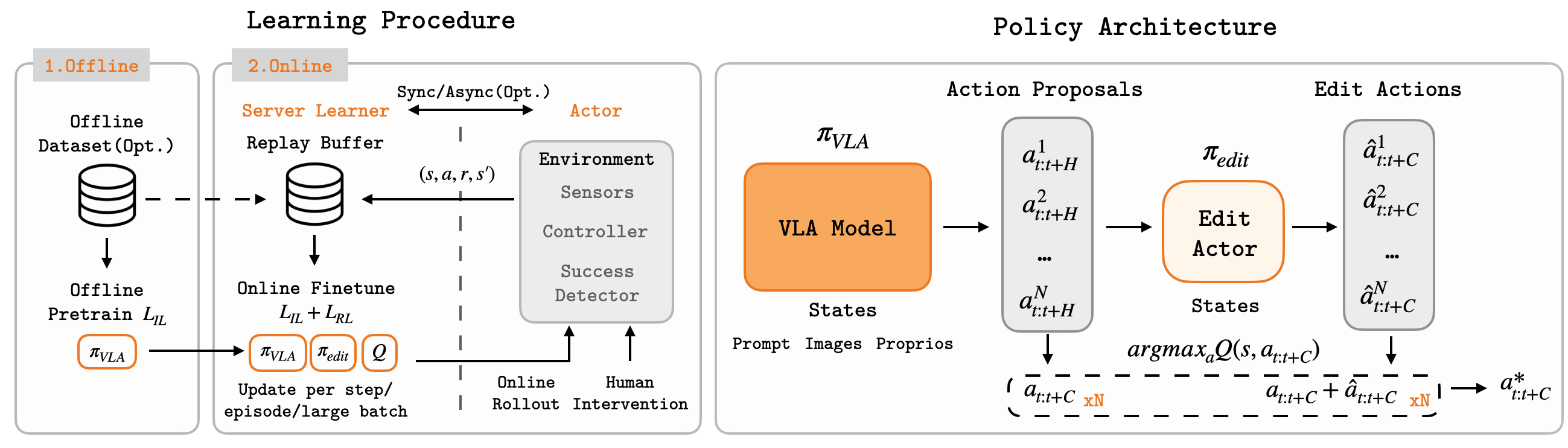
Ý tưởng cốt lõi không phải là "backprop RL trực tiếp qua toàn bộ VLA ở mọi bước". EXPO-FT giữ VLA làm base policy, thêm một edit policy nhỏ để sửa residual trên action chunk, học một Q-function để chọn action chunk tốt nhất, rồi tiếp tục distill/finetune base VLA bằng objective gốc. Nhờ vậy hệ thống vừa bám prior đã học từ π0.5, vừa dùng reward thật để cải thiện những lỗi nhỏ nhưng quan trọng.
Bối cảnh: vì sao RL trên VLA khó?
VLA hiện đại không giống policy Gaussian cổ điển trong SAC/PPO. π0/π0.5 dùng flow-matching/action-chunking style: model sinh một chuỗi hành động liên tiếp thay vì một action đơn. Điều này rất hợp lý cho robot, vì một command "insert flower into bottle" cần nhiều bước liên tục và mượt. Nhưng với RL, nó tạo ra ba khó khăn.
Thứ nhất, nhiều thuật toán RL cần log probability của action. Với diffusion hoặc flow policy, log-likelihood không luôn dễ tính hoặc rẻ để tính trong online loop. Thứ hai, action chunk có chiều lớn: nếu mỗi chunk chứa 8 bước, mỗi bước gồm Cartesian velocity và gripper command, action space hiệu dụng lớn hơn nhiều so với single-step control. Thứ ba, robot thật có latency và safety constraint. Mỗi lần rollout không chỉ là một sample trong simulator; đó là thời gian thật, có nguy cơ va chạm, có reset, có camera, có operator.
EXPO-FT dựa trên thuật toán EXPO trước đó, vốn được thiết kế cho policy biểu đạt mạnh như diffusion/flow. Trong paper, nhóm tác giả mở rộng EXPO cho temporally extended actions và thêm human-in-the-loop interventions. Bài này tập trung vào cách đọc hệ thống đó như một pipeline thực hành: bạn cần chuẩn bị gì, chạy bước nào, và nên hiểu kết quả ra sao.
Kiến trúc hệ thống
Repo EXPO-FT chia hệ thống thành hai phía:
GPU server / learner
- train_pi_robo.py
- train_pi_robo_async.py
- eval_droid_policy.py
- π0.5 wrapper qua modified OpenPI
- replay buffer, critic, edit actor, checkpoint
↑ WebSocket
↓
Robot client / actor
- client/run_client.py
- DROID robot environment
- camera side view + wrist view
- SpaceMouse intervention
- success detector
Thiết kế server-client rất thực dụng. Learner cần GPU mạnh để chạy π0.5, critic và update. Actor cần gần robot, camera, DROID SDK và input device cho teleoperation. Hai bên nói chuyện qua WebSocket. Nếu GPU server và robot laptop không cùng máy, repo hỗ trợ SSH reverse tunnel để server kết nối tới client qua localhost:8102.
Ở mức model, EXPO-FT có bốn thành phần chính:
| Thành phần | Vai trò | Vì sao cần |
|---|---|---|
| Base VLA π0.5 | Sinh action chunks từ ảnh, state và instruction | Mang prior ngữ nghĩa và manipulation từ pretraining |
| Edit policy | Dự đoán residual correction cho action chunk | Sửa hành vi mà không phá prior của VLA |
| Q ensemble | Ước lượng giá trị của action chunk | Chọn candidate có khả năng thành công cao nhất |
| Replay buffer | Lưu demo, rollout, intervention | Cho off-policy RL sample-efficient |
Trong appendix của paper, implementation cụ thể dùng RedQ-style ensemble 10 Q-networks, chọn ngẫu nhiên 2 Q để lấy minimum khi tạo target nhằm giảm overestimation. Mỗi decision, base model sample 8 action chunks; edit policy tạo thêm 8 edited chunks; tổng cộng 16 candidate được đưa qua Q-function và hệ thống execute candidate có Q cao nhất. Critic dùng ResNet-50 nhẹ hơn thay vì dùng lại visual encoder lớn của VLA, vì online loop cần latency thấp.
Sơ đồ luồng action:
Observation:
side RGB 224x224
wrist RGB 224x224
robot proprioception
language instruction
π0.5 base policy
├─ sample 8 base action chunks
└─ mỗi chunk gồm nhiều action bước ngắn
Edit actor
└─ thêm residual edit vào từng chunk
Candidate set
├─ 8 base chunks
└─ 8 edited chunks
Q ensemble
└─ chọn chunk có Q-value cao nhất
Robot
└─ execute 4 hoặc 8 bước rồi replan
Điểm hay là edit không cần "phát minh lại" toàn bộ action. Nó chỉ cần học các correction nhỏ như thấp thêm vài cm, xoay gripper một chút, đánh pool mạnh hơn, hoặc chỉnh hướng stem trước khi insert. Với task precision, các correction nhỏ này quyết định thành công.
Dữ liệu đầu vào: không phải chỉ 19 phút từ con số 0
Cần đọc kỹ claim 19.1 phút. Đây là online robot data dùng trong RL phase, không có nghĩa bạn bật robot rỗng và không cần demo. Trong setup của paper, nếu pretrained VLA chưa đạt zero-shot đủ tốt, nhóm tác giả thu một tập demonstration nhỏ bằng teleoperation, SFT π0.5 trước, rồi mới online RL. Ví dụ appendix ghi các task có số demo pre-collect khác nhau: Candy Scoop 10 demos, Cube Pick 10 demos, Flower Insert 25 demos, Pool Shot 30 demos. Sau SFT, policy khởi động chưa hoàn hảo nhưng đủ để RL có tín hiệu.
Quy trình beginner nên hiểu như sau:
- Nếu π0.5 zero-shot làm task của bạn trên robot đạt mức chấp nhận được, bạn có thể dùng nó làm base cho RL.
- Nếu không, thu demo thành công bằng teleoperation.
- Convert data sang LeRobot format.
- Compute normalization stats cho robot/action space.
- SFT π0.5 bằng LoRA/task checkpoint.
- Chạy EXPO-FT online, cho phép operator can thiệp ở trạng thái dễ fail.
- Evaluate bằng 30 trial hoặc số trial đủ nghiêm túc cho use case.
Điểm quan trọng là reward trong paper chủ yếu là sparse binary reward: thành công thì 1, chưa thành công thì 0. Nhóm tác giả tránh reward shaping phức tạp bằng success detector rule-based cho từng task. Ví dụ Candy Scoop kiểm tra kẹo trong muỗng, độ cao, và số pixel màu trong vùng target; Pool Shot kiểm tra bóng đen vào lỗ, bi trắng không rơi lỗ, cue stick không chạm trực tiếp bóng đen. Success detector đạt trên 95% accuracy và evaluation cuối cùng do người quan sát xác nhận.
Cài đặt repo EXPO-FT
Repo có hai Python environment độc lập. Đây là chi tiết dễ sai nếu bạn mới bắt đầu.
# Cần Python 3.11+ và uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# Clone repo chính và hai fork phụ theo README
git clone https://github.com/pd-perry/expo-ft.git
cd expo-ft
git clone -b expo_ft https://github.com/pd-perry/openpi.git expo_ft/agents/vla/openpi
git clone https://github.com/pd-perry/droid.git client/droid
Server environment nằm ở root:
# Server / learner
uv sync
Client environment nằm trong client/:
# Client / actor
cd client
uv sync
cd ..
# Nếu dùng ZED camera
bash client/install_pyzed.sh
Bạn cần cấu hình phần cứng trước khi chạy thật. Trong DROID fork, chỉnh client/droid/droid/misc/parameters.py cho nuc_ip. Trong task config như configs/task/real_base.py hoặc configs/task/pick.py, chỉnh side_camera_id, wrist_camera_id, reset joints, workspace bounds và language instruction. Trên NUC điều khiển robot, DROID cần đúng robot_type, robot_serial_number, robot_ip và Polymetis/hardware config.
Với beginner, hãy chạy theo task pick có sẵn trước. README nói rõ chỉ scripts/pick/ được wire đầy đủ như example. Với task mới, copy folder script này rồi thay path, task config, dataset id và checkpoint.
Tạo task mới
Một task EXPO-FT tối thiểu có ba phần:
client/envs/droid_env.py
- reset()
- step(action)
- observation gồm image + proprio
- detect() gọi success detector
configs/task/my_task.py
- language instruction
- camera ids
- action bounds
- reset pose
- episode horizon
client/real_utils/detector.py
- rule-based hoặc learned binary success detector
Ví dụ task "insert cable" có thể dùng detector rule-based từ pose connector, trạng thái đèn, hoặc pixel threshold vùng LED. Task "pick cube" có thể dùng gripper height và object visibility. Task "scoop candy" cần detector thị giác phức tạp hơn. Đừng cố viết reward dense ngay từ đầu nếu bạn chưa kiểm soát được detector binary; sparse reward dễ debug hơn vì nó buộc bạn xác định rõ điều kiện "done".
Checklist trước khi thu data:
| Hạng mục | Câu hỏi kiểm tra |
|---|---|
| Camera | Side và wrist view có thấy vùng thao tác không? |
| Action scale | Cartesian velocity có quá lớn hoặc quá nhỏ không? |
| Reset | Robot có trở lại trạng thái an toàn sau mỗi episode không? |
| Detector | Success detector có ít false positive không? |
| Intervention | SpaceMouse có override policy mượt không? |
| Network | Server có kết nối được client port không? |
Thu demo và convert sang LeRobot
Trên NUC, chạy DROID server:
# On the NUC
python scripts/server/run_server.py
Trên robot client/laptop, thu demonstration:
# On the client / robot machine
bash scripts/${TASK_NAME}/collect_data.sh
Các tham số cần chỉnh trong script:
--save_root # nơi lưu raw episodes
--num_episodes # số demonstration cần thu
--task_config # task config đúng với robot
Sau khi có raw data, convert sang LeRobot format trên server/GPU machine:
bash scripts/${TASK_NAME}/convert_data.sh
Bạn cần chỉnh MAX_EPISODES, TASK_CONFIG, DATA_DIR và REPO_NAME. Nếu client và server là hai filesystem khác nhau, copy hoặc sync data sang server trước khi convert, compute norm stats, SFT và RL. Đây không phải chi tiết phụ: nhiều lỗi training thực tế đến từ path dataset không khớp giữa máy robot và máy GPU.
SFT π0.5 trước khi RL
Trước EXPO-FT, bạn cần supervised fine-tuning. Repo gọi script OpenPI trong fork đã chỉnh:
# Tính normalization stats lần đầu cho task
bash scripts/${TASK_NAME}/calculate_norm.sh
# Fine-tune π0.5 bằng LoRA/SFT
bash scripts/${TASK_NAME}/finetune_droid.sh
Trong example pick, finetune_droid.sh chạy khoảng 4001 train steps và save mỗi 2000 steps:
uv run expo_ft/agents/vla/openpi/scripts/train.py \
expo_pi05_droid_lora_finetune_sft_cartesian_state \
--exp-name="${DATA_ID}_lora_sft" \
--resume \
--data.repo_id="$REPO_ID" \
--data.assets.assets_dir="$ASSETS_DIR" \
--data.assets.asset_id="$ASSET_ID" \
--num_train_steps=4001 \
--save_interval=2000 \
--fsdp_devices=1
Mục tiêu của SFT không nhất thiết là 100%. Paper mô tả nếu zero-shot chưa đủ tốt, nhóm tác giả dùng demo để đưa policy lên khoảng 40% success trở lên, sau đó để RL cải thiện. Đây là mindset quan trọng: SFT tạo policy đủ an toàn và có hướng; RL tối ưu reliability.
Chạy EXPO-FT online
Khởi động DROID server trên NUC:
python scripts/server/run_server.py
Khởi động rollout client:
bash scripts/${TASK_NAME}/run_policy.sh
Nếu server và client khác máy:
bash scripts/set_server.sh <server-hostname> 8102 <your-username>
Sau đó chạy learner trên GPU server:
# Synchronous
bash scripts/${TASK_NAME}/run_server.sh
# Asynchronous, cần ít nhất 2 GPU
bash scripts/${TASK_NAME}/run_server_async.sh
Example run_server.sh cho pick cho thấy các tham số quan trọng:
python train_pi_robo.py \
--config_task=configs/task/pick.py \
--dataset_path=./data/pick_cube_balance/success \
--num_data=10 \
--update_type=episode \
--num_updates=3 \
--offline_ratio=0 \
--config=configs/model/expo_ft_pi_config.py \
--config.N=8 \
--config.n_edit_samples=8 \
--config.edit_scale=0.2 \
--config.pi05_weight_loader_path="./checkpoints/.../params" \
--config.pi05_assets_dir="./assets/expo_pi05_droid_lora_finetune_sft_cartesian_state" \
--config.pi05_asset_id="expo_ft/droid_pick_cube_10" \
--client_host=localhost \
--client_port=8102 \
--checkpoint_model \
--checkpoint_buffer
N=8 nghĩa là sample 8 base chunks. n_edit_samples=8 tạo 8 edited chunks. edit_scale=0.2 là mức residual edit khởi đầu tốt theo README, nhưng task precision có thể cần nhỏ hơn. update_type=episode an toàn hơn cho robot vì update sau episode; update per step có thể sample-efficient hơn nếu compute đủ và safety loop ổn.
Human-in-the-loop hoạt động theo kiểu operator quan sát robot. Khi thấy robot sắp fail, operator dùng SpaceMouse override action trong một hoặc nhiều timestep của action chunk. Các action đã sửa được ghi vào replay buffer. Trong paper, intervention rate cao ở đầu training và giảm dần về 0 khi policy học ổn. Đây là tín hiệu tốt: nếu sau nhiều episode intervention vẫn cao, có thể reward detector sai, action scale sai, SFT checkpoint yếu, hoặc initial randomization quá rộng.
Inference và evaluation
Sau training, chạy evaluation với cùng DROID server và client rollout server:
bash scripts/${TASK_NAME}/eval_policy.sh
Evaluation cần khớp cấu hình với training: task config, checkpoint, assets/norm stats, edit_scale, replan steps và camera setup. Trong paper, mỗi task được đánh giá 30 trials, initial state randomization bằng scripted motion hoặc human reset, và success cuối cùng do người quan sát xác nhận. Bạn nên giữ quy tắc này: đừng chỉ quay một video thành công. Hãy report số trial, randomization range, online data minutes và failure mode còn lại.
Một template log nên có:
Task: cable insertion
Base π0.5 zero-shot: 6/30
SFT after 20 demos: 14/30
EXPO-FT online data: 22 minutes
Final eval: 29/30
Intervention rate: 35% early → 0% final
Main failure: connector yaw > 20 degrees
Kết quả paper
EXPO-FT được test trên 8 real-world manipulation tasks: Egg Flip, String Light Routing Route I, Route II, Insert, Candy Scoop, Cube Pick, Flower Insert và Pool Shot. Các task này bao phủ contact-rich manipulation, precision insertion, deformable/flexible object, dynamic striking và scene randomization lớn.
| Task | Online data | SFT | HG-DAgger | EXPO-FT |
|---|---|---|---|---|
| Egg Flip | 18 min | 16/30 | 18/30 | 30/30 |
| String Light Route I | 18 min | 23/30 | 18/30 | 30/30 |
| String Light Route II | 35 min | 21/30 | 25/30 | 30/30 |
| String Light Insert | 16 min | 23/30 | 24/30 | 30/30 |
| Candy Scoop | 20 min | 22/30 | 28/30 | 30/30 |
| Cube Pick | 14 min | 22/30 | 26/30 | 30/30 |
| Flower Insert | 14 min | 14/30 | 24/30 | 30/30 |
| Pool Shot | 18 min | 23/30 | 14/30 | 30/30 |
| Average | 19.1 min | 20.5/30 | 22.1/30 | 30/30 |
Trên subset 4 task, paper cũng so sánh với DSRL và HIL-SERL. EXPO-FT đạt 30/30 trung bình; DSRL khoảng 19/30; HIL-SERL trong budget chuẩn chỉ khoảng 5.5/30, dù bản thêm sample đạt tốt hơn ở một số task. Diễn giải hợp lý là: HIL-SERL mạnh khi train policy nhỏ từ đầu trong setup phù hợp, nhưng ở task có initial-state distribution rộng hoặc cần prior thị giác/ngữ nghĩa lớn, VLA initialization giúp nhiều. DSRL tận dụng pretrained policy nhưng bị giới hạn trong mode của prior, khó học behavior mới nếu offline data chưa phủ đủ.
Khi nào nên dùng EXPO-FT?
EXPO-FT phù hợp khi bạn có robot thật, camera, teleoperation, một task manipulation có success detector rõ, và bạn cần tăng reliability từ mức "khá ổn" lên gần deployment. Nó không phải lựa chọn đầu tiên nếu bạn chưa có robot stack ổn định, chưa calibrate camera, hoặc task còn mơ hồ đến mức không định nghĩa được success.
Nên dùng:
| Tình huống | Vì sao hợp |
|---|---|
| SFT đã làm được 40-80% nhưng hay fail edge case | RL tối ưu trực tiếp reward thành công |
| Task cần precision/contact/dynamic action | Q-guided edit học correction nhỏ |
| Demo đắt nhưng online robot time có thể kiểm soát | Off-policy replay giúp sample-efficient |
| Có operator can thiệp an toàn | Human intervention giảm exploration vô ích |
Chưa nên dùng:
| Tình huống | Rủi ro |
|---|---|
| Reward detector nhiều false positive | Policy sẽ học "hack" detector |
| Camera không ổn định | Critic và VLA nhận observation nhiễu |
| Reset thủ công quá lâu | 19 phút online data có thể thành nhiều giờ wall-clock |
| Action bounds chưa an toàn | RL có thể thử correction nguy hiểm |
Kết luận
EXPO-FT là một bước quan trọng vì nó biến VLA từ "generalist policy biết làm nhiều thứ" thành "policy có thể được post-train để đáng tin hơn trên robot thật". Công thức của nó khá rõ: SFT π0.5 bằng một ít demo, chạy online off-policy RL với edit residual, dùng Q ensemble để chọn action chunk, cho phép human intervention, và đánh giá bằng trial count nghiêm túc.
Điểm đáng học nhất không chỉ là con số 19.1 phút. Đó là cách hệ thống kết hợp ba nguồn tín hiệu: prior lớn của π0.5, reward thật từ task, và correction của con người đúng lúc policy sắp sai. Với robotics, đây là hướng thực dụng: không bỏ pretraining, không phụ thuộc hoàn toàn vào imitation, và không bắt robot học từ con số 0.
Nguồn tham khảo
- Paper: EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models
- Project page: pd-perry.github.io/expo-ft
- Code: github.com/pd-perry/expo-ft